有时在查询时需要按照某一列的名称去将查询结果分为若干部分,比如老师想根据成绩表分别统计出'母猪的产后护理'和'论萨达姆的战争准备'这两门课的平均分,则可以使用分组查询(**GROUP BY**)达到上述效果:
SELECT subject, AVG(score) AS '平均分' FROM student_score GROUP BY subject;
1、简单的分组查询
简答的分组查询就是只用**GROUP BY**按照要分组的列将查询结果分为若干个组,将该列值相同的记录分到一个组,分组依据的列称为分组列。
格式:
SELECT 查询列表 FROM 表名 GROUP BY 分组表达式;
上面的查询列表,可以是普通的列名,也可以是内聚函数以及AS列的别名等。
举例:
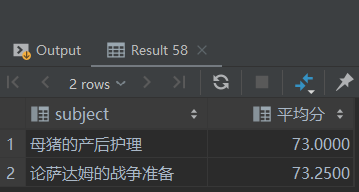
SELECT subject, AVG(score) FROM student_score GROUP BY subject;
上面的例子中,根据科目将学生分数表分为两个组,显示两个列,一个是科目,一个是科目的平均分。
2、带WHERE子句的分组查询
我们也可以在划分分组的时候就将某些记录过滤掉,这时就需要使用WHERE子句的分组查询了,比如想要统计学生分数表里分数大于等于60分的两个科目的平均分,就可以先用WHER`` score >= 60把符合条件的记录过滤出来,再进行分组。
格式:
SELECT 查询列表 FROM 表名 WHERE 表达式 GROUP BY 分组表达式;
举例:
SELECT subject, AVG(score) AS '平均分' FROM student_score WHERE score >= 60 GROUP BY subject;
3、带HAVING子句的分组查询
上面的WHERE子句是对表中的每一条记录进行过滤,HAVING子句可以对GROUP BY分好的分组进行过滤。其实WHERE和HAVING做的是同一个事情:对表中的数据进行过滤,WHERE是先过滤再分组,HAVING是先分组再过滤。
格式:
SELECT 查询列表 FROM 表名 GROUP BY 分组表达式 HAVING 过滤条件表达式;
这里HAVING后的过滤条件表达式有以下两种:
可以把分组的列作为过滤条件表达式,比如:
SELECT subject, AVG(score) FROM student_score GROUP BY subject HAVING subject = '论萨达姆的战争准备';
可以把聚集函数作为过滤条件表达式,比如:
SELECT subject, AVG(score) FROM student_score GROUP BY subject HAVING MIN(score) > 50;
where子句和having子句的区别:
where子句是用在生成分组时的过滤条件;
- having子句是已经生成分组之后的过滤条件,having子句是对已经生成的分组再进行过滤;
- where子句在group by子句之前,having子句在group by子句之后。
4、带ORDER BY子句的分组查询
如果我们想对各个分组查询出来的统计数据进行排序,需要为查询列表中有聚集函数的表达式添加别名。
格式:
SELECT 聚集函数(列名) AS 列的别名 FROM 表名 GROUP BY 分组表达式 ORDER BY 列的别名 DESC/ASC;
举例:
SELECT subject, AVG(score) AS 'avg_score' FROM student_score GROUP BY subject ORDER BY avg_score DESC;
上面例子中,先按subject对学生信息表进行分组,再给分数的平均分这一显示的列添加一个列的别名,最后通过ORDER BY根据不同科目的平均分降序排列。
5、嵌套分组
有时仅根据一列对表进行分组粒度太粗了,想要进行更加细粒度的分组,此时可以用嵌套分组。举个例子,在学生信息表student_info表中,可以先根据department列对表进行分组,再在此基础上对每个分组根据major列再进行一次分组。
格式:
SELECT 查询列表 FROM 表名 GROUP BY 分组表达式1, 分组表达式2,...;
举例:
SELECT department, major, COUNT(*) FROM student_info GROUP BY department, major;
注意:
- 在嵌套分组里,越排在后面的表达式粒度越细;
在嵌套分组里,查询列表中如果有聚集函数,则聚集函数式作用在最后一个分组列上。
6、分组查询的注意事项
如果分组列中有
NULL值,则NULL值也会作为单独的一个分组;- 嵌套分组中,聚集函数作用在最后那个分组上;
WHERE、GROUP BY和HAVING等子句要严格遵循次序书写,具体次序见第七小节。7、简单查询中各子句的顺序
查询语句的各个子句,除了SELECT之外其他的子句都可以省略。这些子句要严格遵循以下次序书写:
在书写查询语句的时候各个子句必须严格遵守这个顺序,不然会报错!SELECT [DISTINCT] 查询列表[FROM 表名][WHERE 布尔表达式][GROUP BY 分组列表 ][HAVING 分组过滤条件][ORDER BY 排序列表][LIMIT 开始行, 限制条数]

若有收获,就点个赞吧
0 人点赞
