表达式常用在查询列表和WHERE后面的搜索条件中,函数常用在一些小需求中,将数据小写转大写,统计一列中数据的最大值平均值等。
1、表达式
1.1 操作数
常见的操作数有以下几种:
- 常数
- 数字、字符串、时间值等;
- 列名
- 列名也可以当做表达式,比如查询列表里的列名也是表达式;
- 函数调用
- 函数调用返回的值可能是常数,也可以作为表达式;
- 标量子查询或行子查询
- 后面补充;
- 其他表达式
1.2.1 算数操作符
| 操作符 | 示例 | 说明 |
|---|---|---|
+ |
a + b |
加法 |
- |
a - b |
减法 |
* |
a * b |
乘法 |
/ |
a / b |
除法 |
DIV |
a DIV b |
除法,取商的整数部分 |
% |
a % b |
取余 |
- |
-a |
负号 |
1.2.2 比较操作符
比较操作符连接而成的表达式也叫布尔表达式,表达式表示True或者False,这部分在带搜索条件的查询中已经介绍了,这里汇总一下常用的比较操作符。
| 操作符 | 示例 | 说明 |
|---|---|---|
= |
a = b |
a等于b |
!= 或者 <> |
a != b |
a不等于b |
< |
a < b |
a小于b |
<= |
a <= b |
a小于或者等于b |
> |
a > b |
a大于b |
| >= | a >= b |
a大于等于b |
BETWEEN |
a BETWEEN b AND c |
满足 b <= a <= c |
NOT BETWEEN |
a NOT BETWEEN b AND c |
不满足 b <= a <= c |
IN |
a IN (b1, b2 ...) |
a是b1,b2,…中的某一个 |
NOT IN |
a NOT IN (b1, b2 ...) |
a不是b1,b2,…中的某一个 |
IS NULL |
a IS NULL |
a的值是NULL |
IS NOT NULL |
a IS NOT NULL |
a的值不是NULL |
LIKE |
a LIKE b |
a匹配b |
NOT LIKE |
a NOT LIKE b |
a不匹配b |
1.2.3 逻辑操作符
逻辑操作符是将多个布尔表达式连接起来,常用的逻辑操作符有以下几个:
| 操作符 | 示例 | 说明 |
|---|---|---|
AND |
express1 AND express2 |
只有表达式1和表达式2同时为真,表达式才为真 |
OR |
express1 OR express2 |
只要表达式1或者表达式2任意一个为真,表达式为真 |
XOR |
express1 XOR express2 |
表达式1和表达式2有且仅有1个为真,表达式为真 |
第三个XOR不是异或,这个概念应该是MySQL区别于其他的。
2、函数
MySQL中函数名约定用大写的形式,在()里传入参数,格式如下:
函数名(入参1, 入参2, ...);
2.1 文本处理函数
| 名称 | 调用示例 | 示例结果 | 描述 |
|---|---|---|---|
LEFT |
LEFT('abc123', 3) |
abc |
给定字符串从左边取指定长度的子串 |
RIGHT |
RIGHT('abc123', 3) |
123 |
给定字符串从右边取指定长度的子串 |
LENGTH |
LENGTH('abc') |
3 |
给定字符串的长度 |
LOWER |
LOWER('ABC') |
abc |
给定字符串的小写格式 |
UPPER |
UPPER('abc') |
ABC |
给定字符串的大写格式 |
LTRIM |
LTRIM(' abc') |
abc |
给定字符串左边空格去除后的格式 |
RTRIM |
RTRIM('abc ') |
abc |
给定字符串右边空格去除后的格式 |
SUBSTRING |
SUBSTRING('abc123', 2, 3) |
bc1 |
给定字符串从指定位置截取指定长度的子串 |
CONCAT |
CONCAT('abc', '123', 'xyz') |
abc123xyz |
将给定的各个字符串拼接成一个新字符串 |
注意:
- SUBSTRING函数中,计算索引下标是从1开始,而不是0;
- sql语句中字符串要有两个打印号括起来。
2.2 日期和时间处理函数
| 名称 | 调用示例 | 示例结果 | 描述 | | —- | —- | —- | —- | |NOW|NOW()|2019-08-16 17:10:43| 返回当前日期和时间 | |CURDATE|CURDATE()|2019-08-16| 返回当前日期 | |CURTIME|CURTIME()|17:10:43| 返回当前时间 | |DATE|DATE('2019-08-16 17:10:43')|2019-08-16| 将给定日期和时间值的日期提取出来 | |DATE_ADD|DATE_ADD('2019-08-16 17:10:43', INTERVAL 2 DAY)|2019-08-18 17:10:43| 将给定的日期和时间值添加指定的时间间隔 | |DATE_SUB|DATE_SUB('2019-08-16 17:10:43', INTERVAL 2 DAY)|2019-08-14 17:10:43| 将给定的日期和时间值减去指定的时间间隔 | |DATEDIFF|DATEDIFF('2019-08-16', '2019-08-17');|-1| 返回两个日期之间的天数(负数代表前一个参数代表的日期比较小) | |DATE_FORMAT|DATE_FORMAT(NOW(),'%m-%d-%Y')|08-16-2019| 用给定的格式显示日期和时间 |
注意:
在使用
DATE_ADD和DATE_SUB这两个函数时需要注意,增加或减去的时间间隔单位可以自己定义,下边是MySQL支持的一些时间单位: | 时间单位 | 描述 | | —- | —- | |MICROSECOND| 毫秒 | |SECOND| 秒 | |MINUTE| 分钟 | |HOUR| 小时 | |DAY| 天 | |WEEK| 星期 | |MONTH| 月 | |QUARTER| 季度 | |YEAR| 年 |在使用
DATE_FORMAT函数时需要注意,我们可以通过一些所谓的格式符来自定义日期和时间的显示格式,下边是MySQL中常用的一些日期和时间的格式符以及它们对应的含义: | 格式符 | 描述 | | —- | —- | |%b| 简写的月份名称(Jan、Feb、…、Dec) | |%D| 带有英文后缀的月份中的日期(0th、1st、2nd、…、31st)) | |%d| 数字格式的月份中的日期(00、01、02、…、31) | |%f| 微秒(000000-999999) | |%H| 二十四小时制的小时 (00-23) | |%h| 十二小时制的小时 (01-12) | |%i| 数值格式的分钟(00-59) | |%M| 月份名(January、February、…、December) | |%m| 数值形式的月份(00-12) | |%p| 上午或下午(AM代表上午、PM代表下午) | |%S| 秒(00-59) | |%s| 秒(00-59) | |%W| 星期名(Sunday、Monday、…、Saturday) | |%w| 周内第几天 (0=星期日、1=星期一、 6=星期六) | |%Y| 4位数字形式的年(例如2019) | |%y| 2位数字形式的年(例如19) |
比如”DATE_FORMAT(date,’%Y-%m’)”,比如date是”2021-06-11”,DATE_FORMAT转换后就是”2021-06”。
注意:
- 日期比较大小,同样可以用<、>、<、=、>、= 、between 、not between这些比较操作符;
- 日期字符串在sql语句中需要用两个单引号括起来。
2.3 数值处理函数
2.3.1 基本数值函数
| 名称 | 调用示例 | 示例结果 | 描述 | | —- | —- | —- | —- | |ABS|ABS(-1)|1| 取绝对值 | |Pi|PI()|3.141593| 返回圆周率 | |COS|COS(PI())|-1| 返回一个角度的余弦 | |EXP|EXP(1)|2.718281828459045| 返回e的指定次方 | |MOD|MOD(5,2)|1| 返回除法的余数 | |RAND|RAND()|0.7537623539136372| 返回一个随机数 | |SIN|SIN(PI()/2)|1| 返回一个角度的正弦 | |SQRT|SQRT(9)|3| 返回一个数的平方根 | |TAN|TAN(0)|0| 返回一个角度的正切 |
2.3.2 取整函数
ROUND(): 四舍五入;CEILING(): 向上取整;FLOOR(): 向下取整。
举例:
SELECT round('123.1'), round('123.4'), round('123.49'), round('123.5');
结果:
SELECT CEILING('123.1'), CEILING('123.4'), CEILING('123.49'), CEILING('123.5');
结果:
SELECT FLOOR('123.1'), FLOOR('123.4'), FLOOR('123.49'), FLOOR('123.5');

2.3.3 取小数后固定几位
ROUND(x,y)函数在截取值的时候会四舍五入,而TRUNCATE(x,y)函数直接截取值,并不进行四舍五入。y是保留小数点后多少位。
举例:
SELECT ROUND(3.456,0), ROUND(3.456,1),ROUND(3.456,2);
结果:
SELECT TRUNCATE(3.456,0), TRUNCATE(3.456,1),TRUNCATE(3.456,2);

2.4 内聚函数
内聚函数的定义:用来统计数据的函数,比如统计表中的行数,每一列的最大值、平均值等,这些统计相关的函数称为聚集函数,常见的聚集函数有:
格式:
# 对表中行的数目进行计数,不管列的值是不是NULLCOUNT(*)# 对特定的列进行计数,会忽略掉该列为NULL的行COUNT(列名)
2.4.2 MAX函数
格式:
SELECT MAX(列名) FROM 表名;
2.4.3 MIN函数
格式:
SELECT MIN(列名) FROM 表名;
2.4.4 SUM函数
格式:
SELECT SUM(列名) FROM 表名;
2.4.5 AVG函数
格式:
SELECT AVG(列名) FROM 表名;
使用聚集函数注意以下几点:
聚集函数可以搭配搜索条件
WHERE使用,但是WHERE子句里不能使用聚集函数,比如:SELECT AVG(score) FROM student_score WHERE subject = '母猪的产后护理';
如果我们指定的列中有重复数据的话,可以选择使用
DISTINCT来过滤掉这些重复数据,并与聚集函数搭配使用,比如:SELECT COUNT(DISTINCT major) FROM student_info;
可以多个聚集函数组合使用,比如:
SELECT COUNT(*) AS 成绩记录总数, MAX(score) AS 最高成绩, MIN(score) AS 最低成绩, AVG(score) AS 平均成绩 FROM student_score;
2.5 窗口函数over
窗口函数是在满足某种条件的记录集合上执行的特殊函数,对于每条记录都要在此窗口内执行函数。按照功能划分,可以把MySQL支持的窗口函数分为如下几类:
序号函数:row_number() / rank() / dense_rank();
- 分布函数:percent_rank() / cume_dist();
- 前后函数:lag() / lead();
- 头尾函数:first_val() / last_val();
- 其他函数:nth_value() / nfile()。
2.5.1 序号函数
序号函数主要是给列加上序号,序号可以连续也可以不连续。
建表:
CREATE TABLE `tb_score` (`id` int NOT NULL AUTO_INCREMENT,`stu_no` varchar(10) DEFAULT NULL,`course` varchar(50) DEFAULT NULL,`score` decimal(4,1) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=37 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
插入数据:
INSERT INTO `tb_score` VALUES (1, '2020001', 'mysql', 90.0);INSERT INTO `tb_score` VALUES (2, '2020001', 'C++', 85.0);INSERT INTO `tb_score` VALUES (3, '2020003', 'English', 100.0);INSERT INTO `tb_score` VALUES (4, '2020002', 'mysql', 50.0);INSERT INTO `tb_score` VALUES (5, '2020002', 'C++', 70.0);INSERT INTO `tb_score` VALUES (6, '2020002', 'English', 99.0);INSERT INTO `tb_score` VALUES (7, '2020003', 'mysql', 78.0);INSERT INTO `tb_score` VALUES (8, '2020003', 'C++', 81.0);INSERT INTO `tb_score` VALUES (9, '2020003', 'English', 80.0);INSERT INTO `tb_score` VALUES (10, '2020004', 'mysql', 80.0);INSERT INTO `tb_score` VALUES (11, '2020004', 'C++', 60.0);INSERT INTO `tb_score` VALUES (12, '2020004', 'English', 100.0);INSERT INTO `tb_score` VALUES (13, '2020005', 'mysql', 98.0);INSERT INTO `tb_score` VALUES (14, '2020005', 'C++', 96.0);INSERT INTO `tb_score` VALUES (15, '2020005', 'English', 70.0);INSERT INTO `tb_score` VALUES (16, '2020006', 'mysql', 60.0);INSERT INTO `tb_score` VALUES (17, '2020006', 'C++', 90.0);INSERT INTO `tb_score` VALUES (18, '2020006', 'English', 70.0);INSERT INTO `tb_score` VALUES (19, '2020007', 'mysql', 50.0);INSERT INTO `tb_score` VALUES (20, '2020007', 'C++', 66.0);INSERT INTO `tb_score` VALUES (21, '2020007', 'English', 76.0);INSERT INTO `tb_score` VALUES (22, '2020008', 'mysql', 90.0);INSERT INTO `tb_score` VALUES (23, '2020008', 'C++', 69.0);INSERT INTO `tb_score` VALUES (24, '2020008', 'English', 86.0);INSERT INTO `tb_score` VALUES (25, '2020009', 'mysql', 70.0);INSERT INTO `tb_score` VALUES (26, '2020009', 'C++', 66.0);INSERT INTO `tb_score` VALUES (27, '2020009', 'English', 86.0);INSERT INTO `tb_score` VALUES (28, '2020010', 'mysql', 75.0);INSERT INTO `tb_score` VALUES (29, '2020010', 'C++', 76.0);INSERT INTO `tb_score` VALUES (30, '2020010', 'English', 81.0);INSERT INTO `tb_score` VALUES (31, '2020011', 'mysql', 90.0);INSERT INTO `tb_score` VALUES (32, '2020012', 'C++', 85.0);INSERT INTO `tb_score` VALUES (33, '2020011', 'English', 84.0);INSERT INTO `tb_score` VALUES (34, '2020012', 'English', 75.0);INSERT INTO `tb_score` VALUES (35, '2020013', 'C++', 96.0);INSERT INTO `tb_score` VALUES (36, '2020013', 'English', 88.0);
表中数据: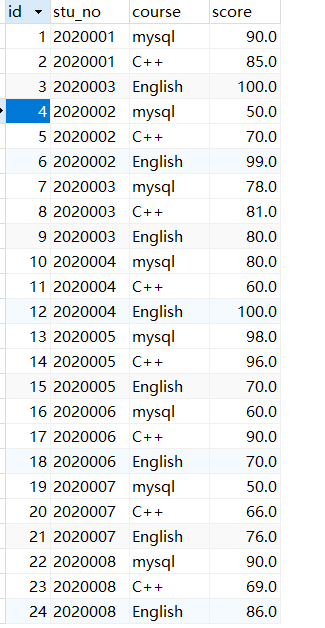
(1)ROW_NUMBER()ROW_NUMBER()函数,当两条记录ORDER BY的列的值相等时,序号也不是相等的,举例:
SELECT stu_no, course, score, row_number() over (PARTITION by course ORDER BY score DESC) as rn FROM tb_score;
结果: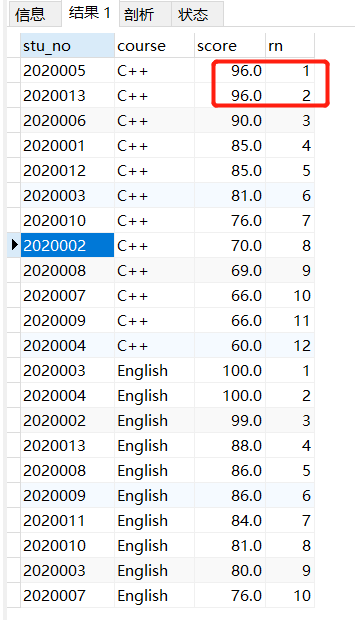
说明:
- row_number()函数后要跟over子句,且over后的子句最好加上括号;
PARTITION BY子句是根据那一列分类,类似GROUP BY;ORDER BY子句是在分类后,根据哪一列排序;- 注意整个子句:row_number() over (PARTITION by course ORDER BY score DESC)都是在列名的位置,后面跟
as列别名。
(2)DENSE_RANKDENSE_RANK()函数,当两条记录ORDER BY的列的值相等时,序号也是相等的,且下一个不相等的序号是连续的,举例:
SELECT stu_no, course, score, DENSE_RANK() over (PARTITION by course ORDER BY score DESC) as rn FROM tb_score;
结果: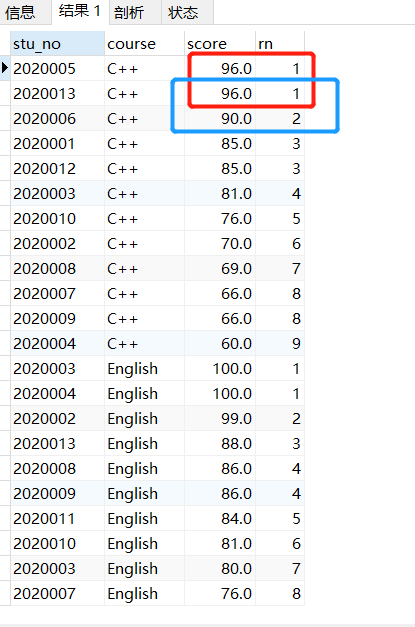
(3)RANKRANK()函数,当两条记录ORDER BY的列的值相等时,序号也是相等的,但下一个不相等的序号不是连续的,举例:
SELECT stu_no, course, score, RANK() over (PARTITION by course ORDER BY score DESC) as rn FROM tb_score;
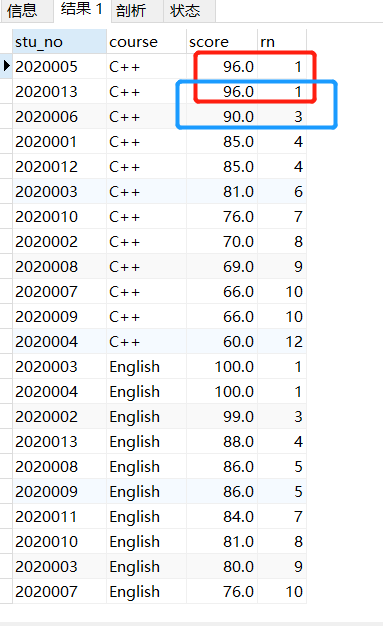
2.5.2 窗口函数和聚集函数的组合使用
**sum() over (order by ...)**
比如有以下表:
| a | b |
|---|---|
| 1 | 2 |
| 3 | 4 |
| 5 | 6 |
按照b排列,将a的值依次相加,则sql语句如下:
select a, b, sum(a) over (order by b) as sum from table;
结果:
| a | b | sum |
|---|---|---|
| 1 | 2 | 1 |
| 3 | 4 | 1 + 3 |
| 5 | 6 | 1 + 3 + 5 |
参考

若有收获,就点个赞吧
0 人点赞
