1、连接查询概念
1.1 为什么需要连接查询
前面我们举例时总是拿学生信息表和学生成绩表举例,这两个表通过外键学号连接,为什么不能把这两张表合成一张表,查询的时候直接针对单表查询,而不是搞什么子查询和连接查询呢?将两张表合为一张表,表中记录学生的每一门课程和对应的得分,合并后的表如下:
student_merge表
| number | name | sex | id_number | department | major | enrollment_time | subject | score |
|---|---|---|---|---|---|---|---|---|
| 20180101 | 杜子腾 | 男 | 158177199901044792 | 计算机学院 | 计算机科学与工程 | 2018-09-01 | 母猪的产后护理 | 78 |
| 20180101 | 杜子腾 | 男 | 158177199901044792 | 计算机学院 | 计算机科学与工程 | 2018-09-01 | 论萨达姆的战争准备 | 88 |
| 20180102 | 杜琦燕 | 女 | 151008199801178529 | 计算机学院 | 计算机科学与工程 | 2018-09-01 | 母猪的产后护理 | 100 |
| 20180102 | 杜琦燕 | 女 | 151008199801178529 | 计算机学院 | 计算机科学与工程 | 2018-09-01 | 论萨达姆的战争准备 | 98 |
| 20180103 | 范统 | 男 | 17156319980116959X | 计算机学院 | 软件工程 | 2018-09-01 | 母猪的产后护理 | 59 |
| 20180103 | 范统 | 男 | 17156319980116959X | 计算机学院 | 软件工程 | 2018-09-01 | 论萨达姆的战争准备 | 61 |
| 20180104 | 史珍香 | 女 | 141992199701078600 | 计算机学院 | 软件工程 | 2018-09-01 | 母猪的产后护理 | 55 |
| 20180104 | 史珍香 | 女 | 141992199701078600 | 计算机学院 | 软件工程 | 2018-09-01 | 论萨达姆的战争准备 | 46 |
| 20180105 | 范剑 | 男 | 181048200008156368 | 航天学院 | 飞行器设计 | 2018-09-01 | NULL | NULL |
| 20180106 | 朱逸群 | 男 | 197995199801078445 | 航天学院 | 电子信息 | 2018-09-01 | NULL | NULL |
以为合并成一张表,单表查询会更方便,其实不然,由于一个学生会有多门课程,每一个课程占用一条记录,而且添加一个学生的课程成绩时,需要把这个学生的基本信息再重复写一遍,因此合并后的单表查询会有以下问题:
- 浪费存储空间;
- 由于新增一条记录需要重复录入学生的基本信息,后期维护困难。
其实这里更多的是要分库分表的原因的逆向解释,正因为如此才会把student_merge表拆分成两张表,减少存储冗余信息,提高查询效率,降低维护成本,分库分表在MySQL性能调优专栏再介绍。
1.2 连接的概念
多表查询,我们可以使用子查询和连接查询。
连接查询的定义:连接查询就是将多张表的记录取出来进行全排列组合,然后将全排列后的记录根据过滤条件进行筛选,筛选后的记录放入结果集中,连接查询后的表自然拥有所有表的列。
为了介绍连接查询的概念,这里新增两张表:t1和t2进行举例说明:
表t1
| t1_col1 | t1_col2 |
|---|---|
| 1 | a |
| 2 | b |
| 3 | c |
表t2
| t2_col1 | t2_col2 |
|---|---|
| 2 | b |
| 3 | c |
| 4 | d |
将t1和t2进行连接,意思就是t1和t2的每条记录拿出来进行全排列,全排列后的表包含t1和t2里所有的列,示意图如下: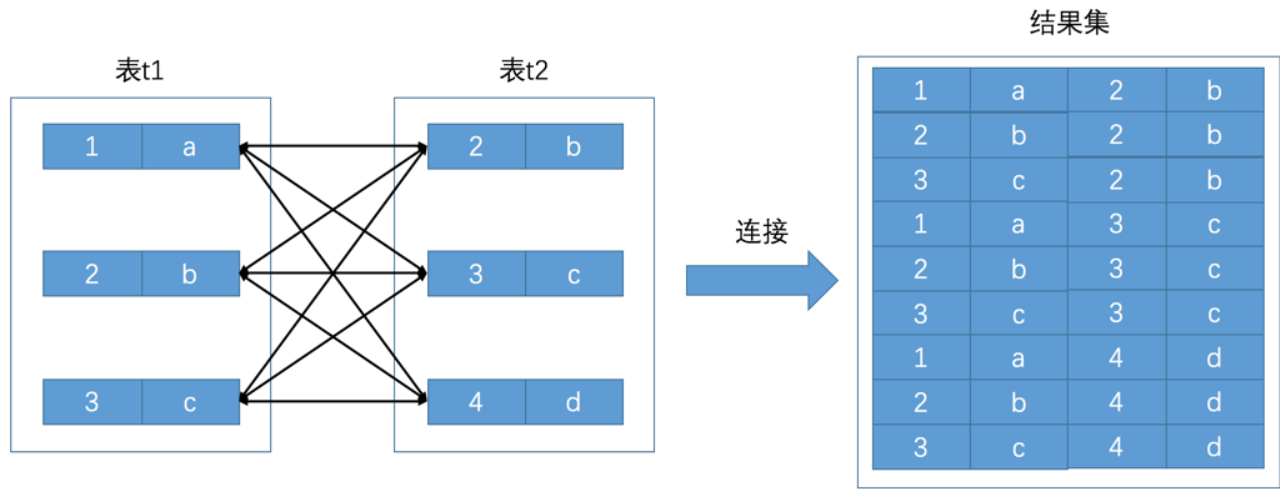
连接查询的SQL语句有以下几种写法,推荐第一种写法:
# 连接查询写法1SELECT * FROM t1, t2;# 连接查询写法2SELECT t1.t1_col1, t1.t1_col2, t2.t2_col1, t2.t2_col2 FROM t1, t2;# 连接查询写法3SELECT t1_col1, t1_col2, t2_col1, t2_col2 FROM t1, t2;# 连接查询写法4SELECT t1.*, t2.* FROM t1, t2;
注意:表名.列名这种写法是当遇到两张表有相同列名时加以区分的写法。
1.3 连接的过程
上面介绍连接查询会根据查询条件将全排列的记录进行过滤,下面举个连接查询的例子说明连接查询的过程:
SELECT * FROM t1, t2 WHERE t1.t1_col1 > 1 AND t1.t1_col1 = t2.t2_col1 AND t2.t2_col2 < 'd';
过滤条件有三个:
- t1.t1_col1 > 1;
- t1.t1_col1 = t2.t2_col1;
- t2.t2_col2 < ‘d’;
上面的连接查询的具体过程如下:
(1)t1表的查询
首先确定第一个要查询的表,这个表称为驱动表,t1表就是我们上面例子的驱动表。在t1表,结合过滤条件中的第一条是仅针对t1表的,根据t1.t1_col1 > 1,t1表满足过滤条件的记录仅有两条:
| t1_col1 | t1_col2 |
|---|---|
| 2 | b |
| 3 | c |
(2)t2表的查询
上面驱动表t1经过筛选后的每一条记录,都要结合过滤条件与t2表的每一条记录进行全排列,因此要在t2表中进行2次查询,t2表也称为被驱动表。
- 第一次查询
即t1表中的第一行记录,结合两个过滤条件,t1.t1_col1 = t2.t2_col1即 t2.t2_col1=2,t2.t2_col2 < 'd',t2表中满足条件的仅是t2表中的第二行记录,因此将t1表中的第一行记录与t2表中的第二行记录匹配,结果如下:
| t1_col1 | t1_col2 | t2_col1 | t2_col2 |
|---|---|---|---|
| 2 | b | 2 | b |
- 第二次查询
即t1表中的第二行记录,结合两个过滤条件,t1.t1_col1 = t2.t2_col1即 t2.t2_col1=3,t2.t2_col2 < 'd',t2表中满足条件的仅是t2表中的第三行记录,因此将t1表中的第一行记录与t2表中的第三行记录匹配,结果如下:
| t1_col1 | t1_col2 | t2_col1 | t2_col2 |
|---|---|---|---|
| 3 | c | 3 | c |
将两次查询的结果全部放到结果集中,例子中的连接查询的结果如下: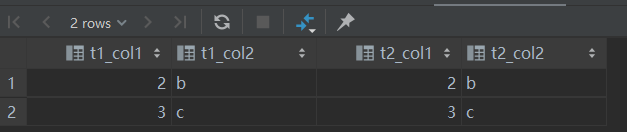
注意:
- 要理解驱动表和被驱动表这组概念;
在两表的连接查询中,驱动表仅查询一次,被驱动表查询多次,被驱动表查询的次数等于在驱动表查询的结果集里记录的数目。
2、内连接和外连接
2.1 内连接和外连接的概念
内连接:驱动表中的记录在被驱动表中找不到匹配记录时,该记录不添加到结果集;
- 外连接:驱动表中的记录在被驱动表中找不到匹配记录时,该记录仍要添加到结果集。
在连接查询中会涉及到过滤条件,连接查询中过滤条件有两种:**WHERE**子句和**ON**子句。
**WHERE**子句:- 就是前面介绍过的带搜索条件的查询时用的
WHERE子句,WHERE子句针对的是记录;
- 就是前面介绍过的带搜索条件的查询时用的
**ON**子句:- 当外连接的驱动表里的记录根据
ON子句的过滤条件无法在被驱动表中找到匹配记录时,该记录仍然会加入到结果集,对应的被驱动表中的各个字段用NULL填充; - 内连接中的
WHERE子句和ON子句是等价的。
- 当外连接的驱动表里的记录根据
一般把只涉及单表的过滤条件放到**WHERE**子句中,把涉及两表的过滤条件都放到**ON**子句中,一般把放到**ON**子句中的过滤条件称之为连接条件。
2.2 内连接
格式:
SELECT * FROM t1 [INNER | CROSS] JOIN t2 [ON 连接条件] [WHERE 普通过滤条件];
一般推荐这种写法:
SELECT * FROM t1 INNER JOIN t2 WHERE 普通过滤条件;
内连接中驱动表和被驱动表的位置互换后不影响最终结果,因为内连接是把不匹配的记录直接丢弃。
2.3 外连接
MySQL中外连接还可以细分成两种:左外连接和右外连接,左外连接是选取左侧的表为驱动表,右外连接是选取右侧的表为驱动表。因为外连接中驱动表中的记录根据ON子句的连接条件不匹配时,被驱动表中对应的列的位置会被NULL填充,因此谁做被驱动表决定了最终的结果集,所以外连接要细分为左外连接和右外连接。
2.3.1 左连接
格式:
SELECT * FROM t1 LEFT [OUTER] JOIN t2 ON 连接条件 [WHERE 普通过滤条件];
- 左连接里,放在左边的表是外表或者驱动表,放在右边的表是内标或者被驱动表;
举例:
SELECT student_info.number, name, major, subject, score FROM student_info LEFT JOIN student_score ON student_info.number = student_score.number;
2.3.2 右连接
格式:
SELECT * FROM t1 RIGHT [OUTER] JOIN t2 ON 连接条件 [WHERE 普通过滤条件];
- 右连接里,驱动表在右边,被驱动表在左边;
3、自连接
3.1 表的别名
列可以通过AS获得列的别名,表也可以通过AS指定表的别名,举例:
格式是在SELECT s1.number, s1.name, s1.major, s2.subject, s2.score FROM student_info AS s1 INNER JOIN student_score AS s2 WHERE s1.number = s2.number;
FROM后面的真实表名后面,通过AS再指定表的别名。
通过上面的SQL语句,查询学生信息表和学生成绩表中共同学号的学生的信息。3.2 自连接
上面介绍的连接查询都是多个不同的表连接,同一张表也可以进行连接查询,称为自连接。自连接里相当于对表建立一个副本,并对副本建立一个表的别名。
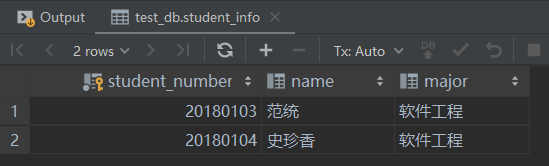
举个例子,想在学生信息表中,查看与“史珍香”同学相同专业的学生信息,可以使用自连接,SQL语句如下:
SELECT s2.student_number, s2.name, s2.major FROM student_info AS s2 INNER JOIN student_info AS s1 WHERE s2.major=s1.major AND s1.name='史珍香';
4、连接查询多张表时如何选择驱动表
参考

若有收获,就点个赞吧
0 人点赞
