定义:文本 —> 数值矩阵
作用:提取文本特征
方法:
1> 词袋模型 BOW
2> 词嵌入模型 WE
词袋模型-BOW
导入库:
from sklearn.feature_extraction.text import CountVectorizer<br />import jieba
_# 对英文<br />_def a1():<br /> s = ["I from china","you from usa"]<br /> cv = CountVectorizer()<br /> rs = cv.fit_transform(s)<br /> ciku = cv.get_feature_names()<br /> ciMat = rs.toarray()<br /> print("词库:",ciku)<br /> print("词向量矩阵:",ciMat)
_# 对中文<br />_def a2():<br /> s = ["我在黄淮,你在未来","我在西游,你在红楼","未来在黄淮的未来餐厅吃饭"]<br /> a = [jieba.lcut(row) for row in s]<br /> a = [" ".join(line) for line in a] _# 降维<br /> _print("a = ",a)<br /> cv = CountVectorizer()<br /> rs = cv.fit_transform(a)<br /> ciku = cv.get_feature_names()<br /> ciMat = rs.toarray()<br /> print("词库:", ciku)<br /> print("词向量矩阵:", ciMat)
可见构建的词向量矩阵中数字代表其索引在词库的对应位置的的词在该句子中出现的次数,即词频。
词嵌入模型—WE
向量化算法—word2vec(词—>向量)
实现模型:
1> CBOW连续词袋模型
2> Skip-gram模型_# word2vec<br />_def a1():<br /> s = ["I from china , i love china","you from usa"]<br /> _# 分词<br /> _s = [line.split() for line in s]<br /> _# 数据,最小词频(为1表示只要出现的词都取),维度(为词库中的每个词生成的特征数量)<br /> _model = Word2Vec(sentences=s,min_count=1,vector_size=3)<br /> ciku = model.wv.index_to_key<br /> ciMat = model.wv.vectors<br /> print("词库:",ciku)<br /> print("词向量矩阵:",ciMat)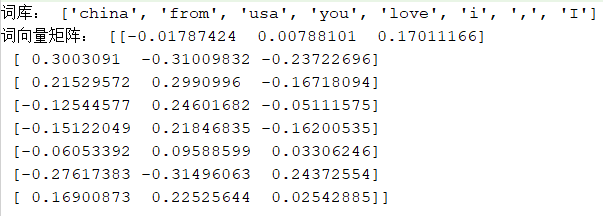
向量化算法—doc2vec(文档—>向量)
在word2vec的基础上,添加了段落向量用于记录词的顺序。
`# doc2vec
_def a2():
# 文档集,在实际项目中此处是真实的一篇篇文档用于训练模型
# 但对于个人电脑的性能来说,处理的数据集过大将会耗费很长时间
# 故此处用两句话表示两篇文档,便于演示
s = [“I from china , i love china”, “you from usa”]
tags = []
# 对文档赋标签
for i,doc in enumerate(s):
t = TaggedDocument(doc.split(“ “),[f”文档{i}”])
tags.append(t)
print(“tags = “,tags)
model = Doc2Vec(
documents=tags,
min_count=1,
vector_size=3,
window=1
)
ciku = model.wv.index_to_key
ciMat = model.wv.vectors
print(“词库 = “,ciku)
print(“词向量矩阵 = “,ciMat)
# 看起来结果与word2vec并没有什么不同,但通过doc2vec算法得到的词向量矩阵可以用于计算
# 1、计算两篇文档的相似度<br /> _test1 = "i from china".split(" ")<br /> test2 = "i have a apple".split(" ")<br /> similarity = model.similarity_unseen_docs(test1, test2)<br /> print("相似度 = ", similarity)_# 2、用于计算获得输入的文档与哪一篇训练模型的数据文档相似<br /> _test3 = "i from henan"<br /> v = model.infer_vector(test3.split(" "))<br /> e = model.dv.most_similar(v)<br /> print("与之相似的文档:",e)`<br />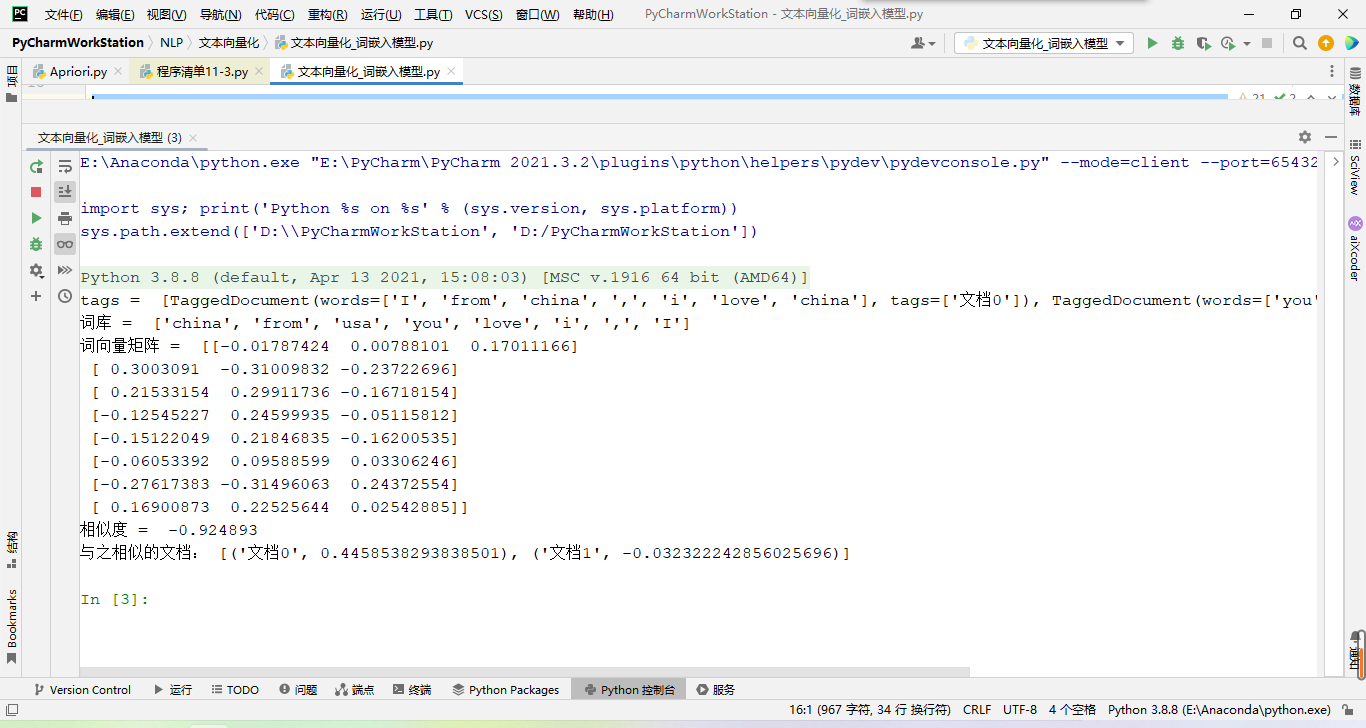

若有收获,就点个赞吧
0 人点赞
