`from wordcloud import WordCloud
import jieba
from jieba.analyse import textrank
from PIL import Image
import numpy as np
# 对英文句子
_def a1():
# s = “I from china,you from usa”
_s = “Connect with developers from around the world for thoughtful discussions, learn from Google experts, and get a first look at our latest developer products.”
wd = WordCloud()
wd.generate(s)
img = wd.to_image()
img.show()
# 对中文句子
_def a2():
s = “这些现代工具和资源可协助您在各种 Android 设备上打造深受用户喜爱的更快捷、轻松的体验。”
fs = textrank(s) # 通过jieba提供的已训练完成的模型提取关键词
print(“fs = “,fs)
with open(“baidu_stopwords.txt”,’r’,encoding=’utf-8’) as f:
stopwords = [word.strip() for word in f] # 过滤停用词
fs = [w for w in fs if w not in stopwords and len(w) > 1] # 过滤单个字的词
bg = Image.open(‘wkong.png’) # 导入背景图(不添加背景图生成的词云图默认为方形)
bg = np.array(bg) # 背景图矩阵化
_wd = WordCloud(font_path=’simhei’,mask=bg,background_color=’white’)
wd.generate(str(fs))
img = wd.to_image()
img.show()`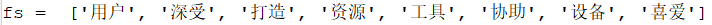


若有收获,就点个赞吧
0 人点赞
