- 通过聚类对各个国家的足球水平进行分类
- 通过聚类对影评的正面负面进行分类
- 分词
def participle(train):
# 加载停用词表
with open(“../关键词提取/baidu_stopwords.txt”,”r”,encoding=”utf-8”) as sf:
stopwords = [word.strip(“\r\t\n”) for word in sf]
rs = []
# 分词
for line in train:
content = jieba.lcut(line)
tmp = [c.strip() for c in content if c not in stopwords]
rs.append(“ “.join(tmp))
return rs
通过聚类对各个国家的足球水平进行分类
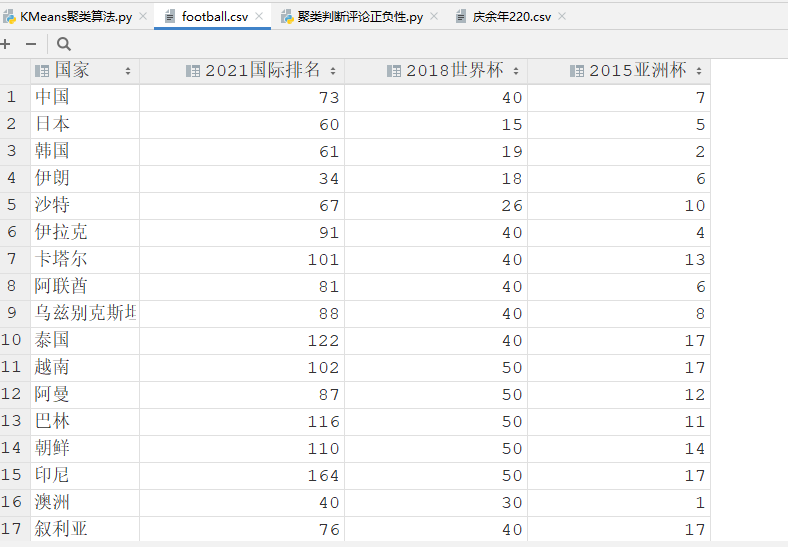
`def KMeans_Example():
data = pd.read_csv(“football.csv”,encoding=”utf-8”)
print(“原数据 = “,data)
# 将读取到的数据转换为数据框格式
df = pd.DataFrame(data)
# 取出所需数据
train = df[[“2021国际排名”,”2018世界杯”,”2015亚洲杯”]]
print(“train = “,train)
# 归一化<br /> mm = MinMaxScaler()<br /> train = mm.fit_transform(train)<br /> # 创建KMeans模型<br /> model = KMeans(n_clusters=3)<br /> # 训练模型<br /> model.fit(train)<br /> label = model.predict(train) # 聚类类别列表<br /> print("预测的类别列表 :",label)<br /> # 将聚类结果添加到原始文件中<br /> rs = pd.concat((data,pd.DataFrame(label)),axis=1)<br /> rs.rename({0:"足球水平类别"},axis=1,inplace=True)<br /> print("rs = ",rs)<br /> # 写入到源文件<br /> rs.to_csv("fb.csv",index=False,encoding="gbk")print("结束")
if name == ‘main‘:
KMeans_Example()`
运行结果: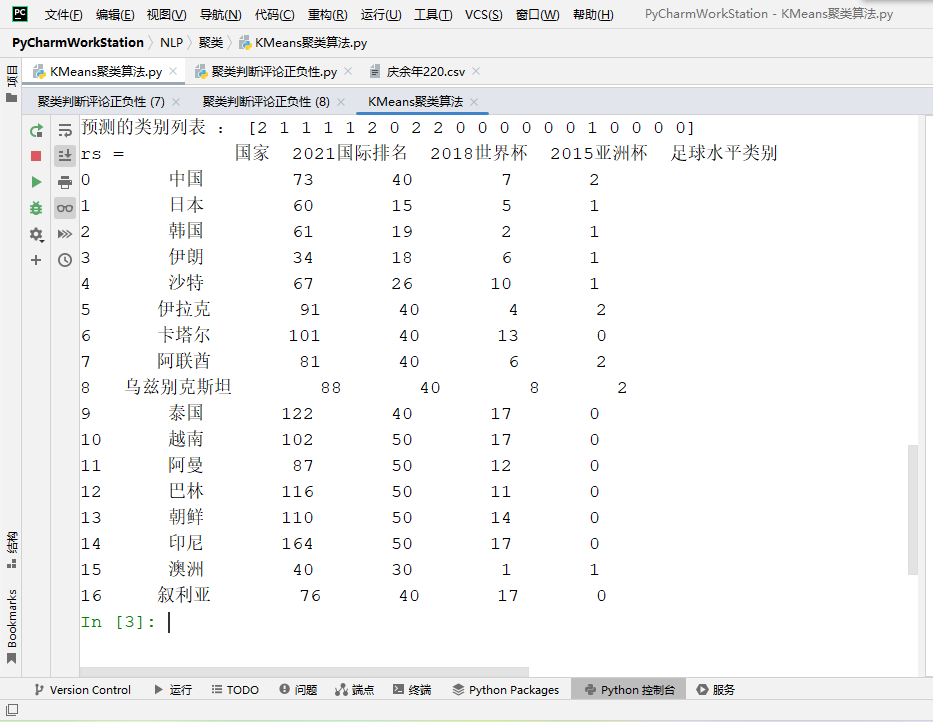
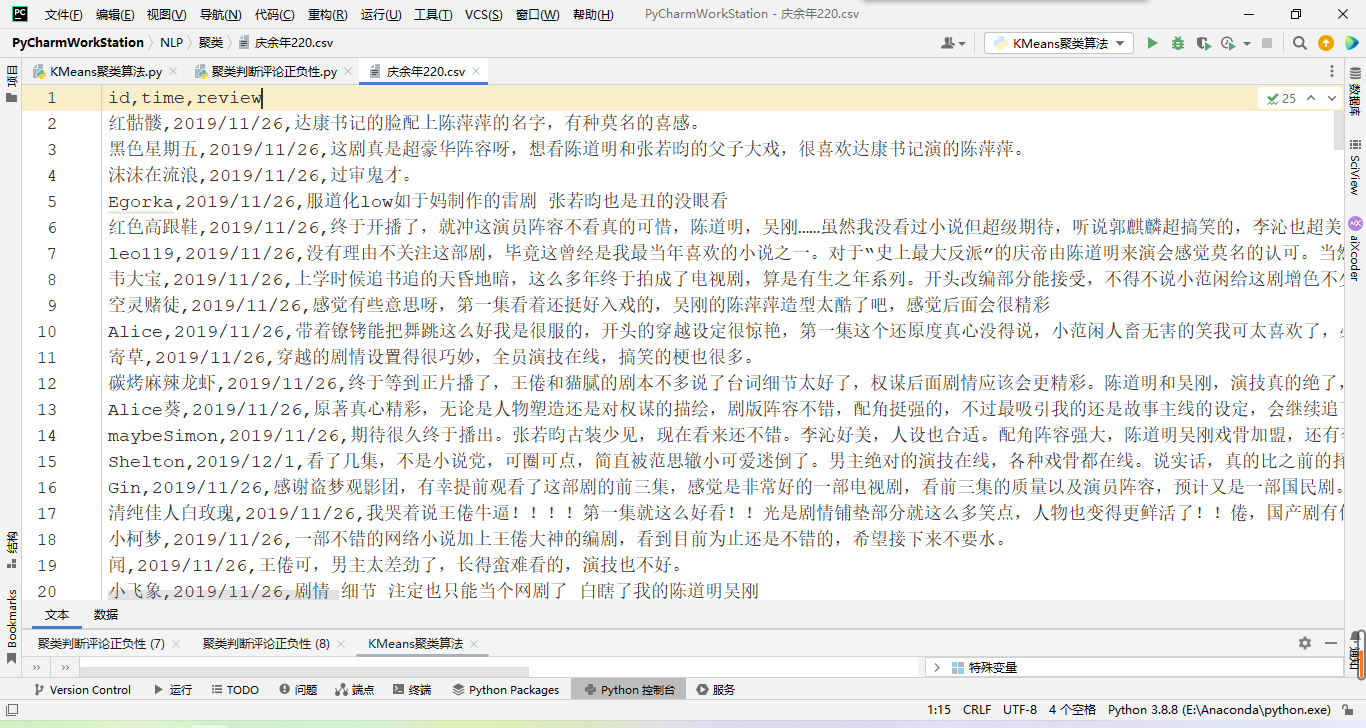
通过聚类对影评的正面负面进行分类
`import pandas as pd
import jieba
from sklearn.cluster import KMeans
from sklearn.feature_extraction.text import TfidfVectorizer
分词
def participle(train):
# 加载停用词表
with open(“../关键词提取/baidu_stopwords.txt”,”r”,encoding=”utf-8”) as sf:
stopwords = [word.strip(“\r\t\n”) for word in sf]
rs = []
# 分词
for line in train:
content = jieba.lcut(line)
tmp = [c.strip() for c in content if c not in stopwords]
rs.append(“ “.join(tmp))
return rs
def main():
data = pd.readcsv(“庆余年220.csv”,encoding=”utf-8”) # 读取文件
train = data[“review”].values.tolist() # 将读取到的文件中的review列的数据放到一个列表中
print(“train_old = “,train)
# 对文本进行分词
train = participle(train)
print(“train = “, train)
# 矩阵化
tfidf = TfidfVectorizer()
mrt = tfidf.fit_transform(train) # 包含tfidf值的矩阵
print(“mrt = “,mrt)
# 创建模型
model = KMeans(n_clusters=2) # n_clusters:要聚类的类别个数
# 为模型导入数据,训练模型
model.fit(mrt)
# 得到聚类结果
clusters = model.labels
print(“类别列表:”,clusters)
if name == ‘main‘:
main()`
运行结果: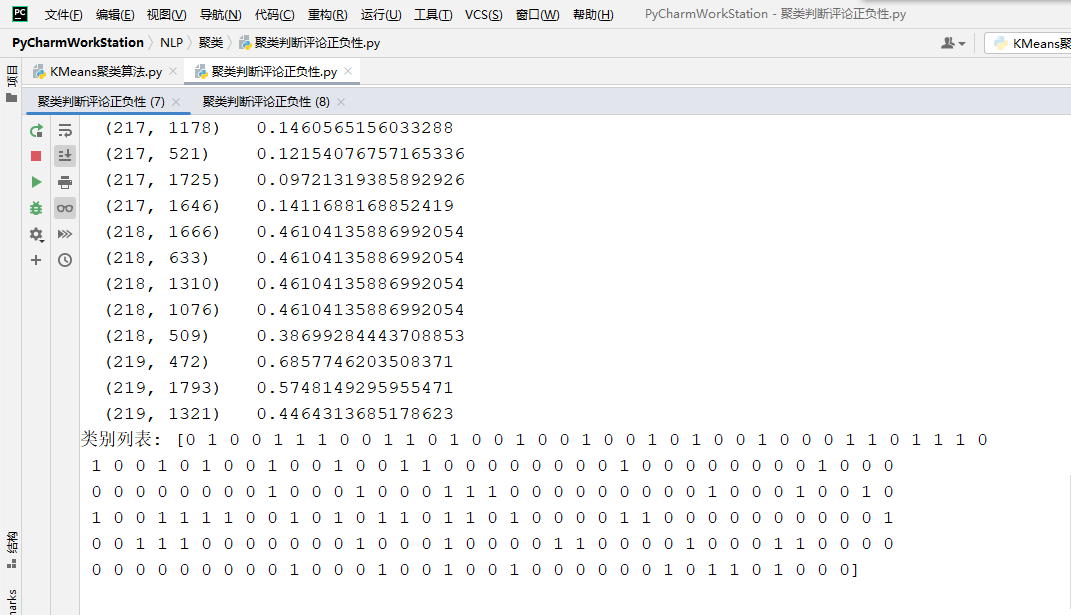
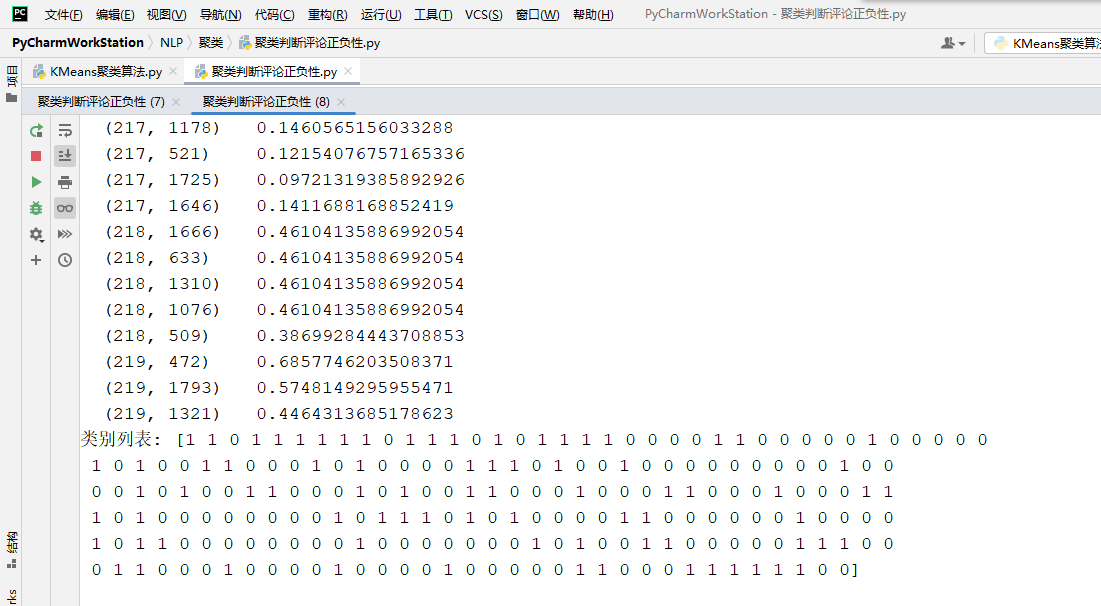
由图所示的两次运行结果来看,由于数据量小,结果并不准确且两次的聚类结果并不相同。可以通过增大数据量或改变K值来改善。

若有收获,就点个赞吧
0 人点赞
