对英文句子来说,因为在书写的时候就会将每个单词用空格进行间隔,因此对于英文句子、文章来说分词相对比较简单。但由于中文的一条句子往往是由单个的字组成的,由字组成的词不但数目庞大,有时还会因为语境的的问题出现不同含义的现象。因此中文分词技术在自然语言处理的地位非常重要!只有将词确定下来是理解自然语言的第一步,也是至关重要的一步;只有跨越了这一步,中文才能向英文一样由句子过渡到短语划分、概念抽取及主题分析,再到自然语言理解。
规则分词
通过构建和维护“词典”,在切分语句时,将语句的每个字符与表中的词进行逐一匹配,找到则切分,否则不予切分。
正向最大匹配法(MM):
基本思想:
假设构建好的分词词典中的最长词有i个汉字字符,则用被处理文档的当前字符串中的前i个字作为匹配字段,查找词典,若词典中存在这样的一个i字词,则匹配成功,匹配字段作为一个词被切分出来。若在词典中查找不到这个词,则匹配失败,将匹配字段中的最后一个字去掉,对剩下的字符串重新进行匹配检测,直到匹配成功,即且分出一个词或剩余字符串长度为0。然后再从剩下的字符中重新取出一个i字长的字符串进行匹配。
算法原理:
1> 从左向右取待切分汉语句子的m个字符作为匹配字段,m为机器词典中最长词条的字符数。
2>查找机器词典进行匹配。若匹配成功,则将这个匹配字段作为一个词切分出来。若匹配不成功,则将这个匹配字段的最后一个字去掉,剩下的字符串作为新的匹配字段,进行再次匹配,重复以上操作,直到切分出所有词。
`class MM(object):
def init(self):
self.windowSize = 3 # 词典中最长的词的词长
self.dic = [“研究”,”研究生”,”生命”,”命”,”的”,”起源”] # 词典
def cut(self,text):
result = [] # 存放分割出的词
index = 0 # 初始化进行要分割的词的初始索引
text_length = len(text)
while text_length > index:<br /> for size in range(self.windowSize+index,index,-1):<br /> piece = text[index:size]<br /> if piece in self.dic:<br /> index = size -1<br /> break<br /> index = index + 1<br /> result.append(piece+"---")<br /> print(result)`
运行和结果:
text = "研究生命的起源"<br />tokenizer = MM()<br />tokenizer.cut(text)
逆向最大匹配法(RMM)
由于汉语中偏正结构较多,采用从后往前匹配,可以适当提高精确度。
基本思想:
基本原理与MM相同,不同之处在于分词切分的方向与MM法相反。逆向最大匹配法从被处理文档的末端开始匹配扫描,每次取最末端的i个字符(词典中最长词的长度)作为匹配字段。若匹配失败,则去掉匹配字段前面的一个字,继续匹配。相应的,RMM使用的分词词典是逆序词典,其中每个词条都将按照逆序方式存放。在实际处理时,先将文档进行倒放处理,生成逆序文档。然后,根据逆序词典,对逆序文档用正向最大匹配法处理。_# 逆向最大匹配法<br />_class RMM(object):<br /> def __init__(self):<br /> self.windowSize = 3 _# 词典中最长的词的词长<br /> # self.dic = ["研究","研究生","生命","命","的","起源"] # 词典<br /> # 读取已经创建好的词典<br /> _with open("dict.txt","r",encoding="utf-8") as f:<br /> self.dic = [i.split(" ")[0].strip() for i in f.readlines()]<br /> print(self.dic[:50])<br /> def cut(self,text):<br /> result = [] _# 存放分割出的词<br /> _index = len(text) _# 初始化进行要分割的词的初始索引<br /> _while index > 0:<br /> for size in range(index - self.windowSize,index):<br /> piece = text[size:index]<br /> if piece in self.dic:<br /> index = size + 1<br /> break<br /> index = index - 1<br /> result.append(piece+"---")<br /> result.reverse()<br /> print(result)
运行和结果:
text = "研究生命的起源"<br />tokenizer = RMM()<br />tokenizer.cut(text)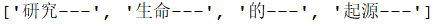
与MM算法的结果相比,RMM算法得到的结果更靠谱。
双向最大匹配法(BMM)
匹配规则:
1>对文本使用MM、RMM算法分别进行分词,得到两种分词结果。
2>如果正反向分词结果的词数不同,则取分词数量较少的结果。
3>如果正反向分词结果的次数相同:
1>分词结果相同,就说明没有歧义,可返回任意一个。
2>分词结果不同,返回其中单字较少的结果。
`# 双向最大匹配法
_class BMM(object):
# 选择分词结果
def chooseResult(self,text):
# 收集两种算法返回的分词结果列表
# 收集到MM算法返回的分词结果
objMM = MM()
objMMresult = objMM.cut(text)
# 收集到RMM算法返回的分词结果
_objRMM = RMM()
objRMMresult = objRMM.cut(text)
_# 获取两个结果列表的长度<br /> _lengthMM = len(objMMresult)<br /> lengthRMM = len(objRMMresult)_# 获取两个结果中单字符的数目<br /> _sizeMM = 0<br /> sizeRMM = 0<br /> for char in objMMresult:<br /> if len(char) == 1:<br /> sizeMM += 1<br /> for char in objRMMresult:<br /> if len(char) == 1:<br /> sizeRMM += 1_# 判断两种分词结果得到的词数是否相等<br /> # 词数不相同<br /> _if lengthMM != lengthRMM:<br /> if lengthMM < lengthRMM:<br /> return objMMresult<br /> else:<br /> return objRMMresult<br /> _# 次数相同<br /> _else:<br /> if objMMresult == objRMMresult:<br /> return objMMresult<br /> else:<br /> if sizeMM < sizeRMM:<br /> return objMMresult<br /> else:<br /> return objRMMresult`
运行和结果:
text = "研究生命的起源"<br />tokenizer = BMM()<br />resultFromBMM = tokenizer.chooseResult(text)<br />print("来自BMM算法选择的分词结果:",resultFromBMM)
统计分词
基于大规模语料库中的词频,统计预料中相邻共现的各个字的组合频度,当组合频度高于某一个临界值时,可认为此字组可能会构成一个词语。
操作流程:
1>建立语言统计模型
2>对句子进行单词划分,对划分结果进行概率计算,获得概率最大的分词方式。通过统计学习算法,如隐含马尔可夫HMM、条件随机场CRF等。
混合分词
jieba分词工具库基于该种方法。

若有收获,就点个赞吧
0 人点赞
