句法分析的目标:构建语法树。
`import jieba
from nltk.parse import stanford
def a1():
s = “他骑自行车去了教室” # 待分析语句
_fs = jieba.lcut(s) # 对语句进行分词(因为目的是对语句进行分析,故不对其进行关键词提取)
print(fs)
rs = “ “.join(fs) # 对分好的词用空格进行间隔
root = “D:/A—我的所有文件/A-课程文件/自然语言处理/句法分析/“ # 两个jar包存放的路径
parserpath = root + “stanford-parser.jar” # 加载jar包
model = root + “stanford-parser-4.2.0-models.jar” # 加载jar包
pcfg = “edu/stanford/nlp/models/lexparser/chinesePCFG.ser.gz” # 模型
# 设置解析库
parser = stanford.StanfordParser(
path_to_jar=parserpath,
path_to_models_jar=model,
model_path=pcfg
)
# 解析
sentence = parser.raw_parse(rs)
# 取出解析后的词和词性,构建语法树
_for line in sentence:
print(line.leaves())
line.draw()`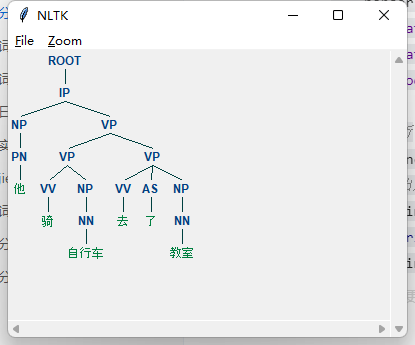

若有收获,就点个赞吧
0 人点赞
