TF/IDF算法:词频—逆文档频次算法是一种基于统计的计算方法,常用于评估在一个文档集中一个词对某份文档的重要程度。一个词对文档越重要,那就越可能是文档的关键词。
基本原理
TF-IDF算法由两部分算法构成:TF算法 & IDF算法。
TF算法:统计一个词在一篇文档中出现的频次。
思想是:一个词在文档中出现的次数越多,则其对文档的表达能力也越强。
IDF算法:统计一个词在文档集的多少个文档中出现。
思想是:如果一个词在越少的文档中出现,则其对文档的区分能力也就越强。
数学基础

代码实现
`import math
import jieba
# 语料分词
_def fenci(path):
fcrs = []
# 读取停用词
with open(“baidu_stopwords.txt”,’r’,encoding=”UTF-8”) as sf:
stopwords = [row.strip(“\n”) for row in sf]
with open(path,’r’,encoding=”utf-8”) as f:
# 遍历每行
for line in f:
line.strip(“\r\n\t”) # 去除每行的分隔符
content = jieba.lcut(line) # 对每一行进行分词
content2 = [c for c in content if c not in stopwords] # 去除停用词
fcrs.append(content2) # 每一行都进行分词且去除停用词,添加到fcrs
_return fcrs
# 计算IDF
_def train_idf():
fcrs = fenci(“corpus.txt”)
idf_dic = {}
total = len(fcrs)
# 计算词频
for row in fcrs: # 读每行
for word in set(row): # 读每个词
idf_dic[word] = idf_dic.get(word,0) + 1 # 此时idfdic中键为词,值为频次
# 计算idf的值,分母+1进行平滑处理
_for k,v in idf_dic.items():
idf_dic[k] = math.log(total/(1+v)) # 此时idfdict中键为词,值为idf值
_default_idf = math.log(total/1) # 默认值(不包含词的idf值)
return idf_dic,default_idf # 返回词idf值字典,默认idf
class Tfidf():
# idf值字典,默认idf值,词表,关键词数量
def _init(self,idf_dic,default_idf,word_list,kw_num):
self.word_list = word_list
self.idf_dic = idf_dic
self.default_idf = default_idf
self.kw_num = kw_num
self.tf_dic = self.get_tf_dic()
_# 计算TF<br /> _def get_tf_dic(self):<br /> tf_dic = {}<br /> for row in self.word_list:<br /> for word in row: _# 遍历每一个词<br /> _tf_dic[word] = tf_dic.get(word, 0) + 1 _# 键为词,值为词的频次<br /> _total = len(self.word_list) _# 统计总词数<br /> _for k,v in tf_dic.items():<br /> tf_dic[k] = v/total _# 键为词,值为tf值<br /> _return tf_dic _# 返回词tf值字典<br /> # 计算TF/IDF值<br /> _def get_tfidf(self):<br /> tfidf_dic = {}<br /> _# 计算待检测数据中每个词的tf/idf值<br /> _for row in self.word_list:<br /> for word in row: _# 遍历每一个词<br /> _idf = self.idf_dic.get(word, self.default_idf) _# 从idf值字典获取该词的idf值,若该词在idf值字典中不存在,则返回默认值<br /> _tf = self.tf_dic.get(word, 0)<br /> tfidf = tf * idf<br /> tfidf_dic[word] = tfidf<br /> _# 排序<br /> _rs = sorted(tfidf_dic.items(),key=lambda x:x[1],reverse=True)[:self.kw_num]<br /> print(rs)
if name == ‘main‘:
new = fenci(“news.txt”)
idf_dic,default_idf = train_idf()
model = Tfidf(idf_dic,default_idf,new,5)
model.get_tfidf()`
运行及结果
训练数据:
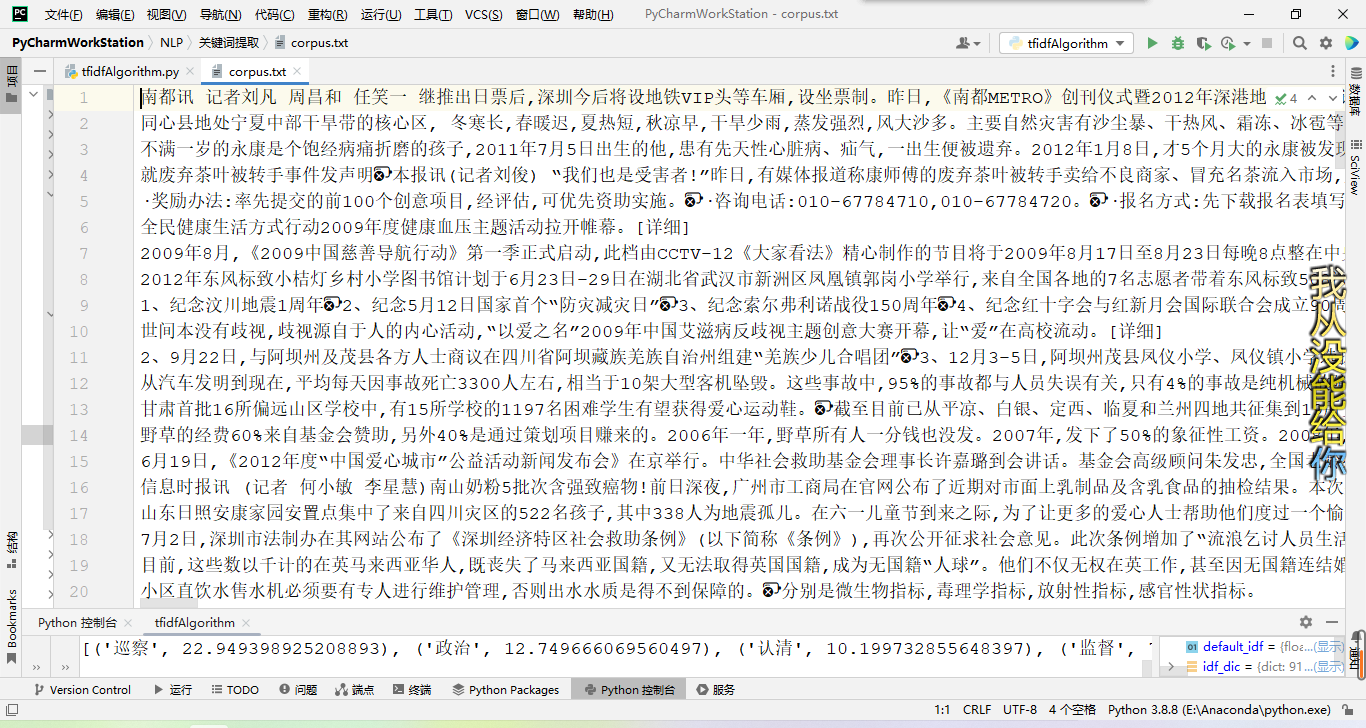
停用词词典:
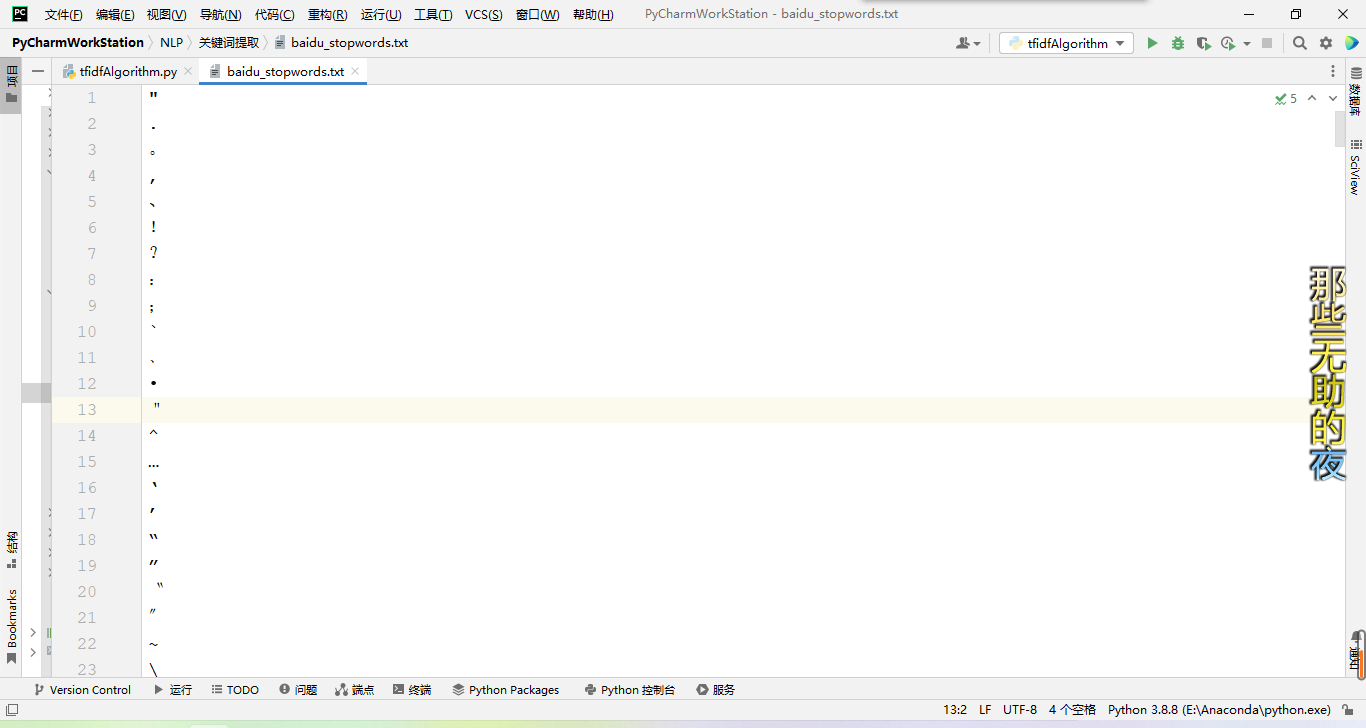
测试数据:
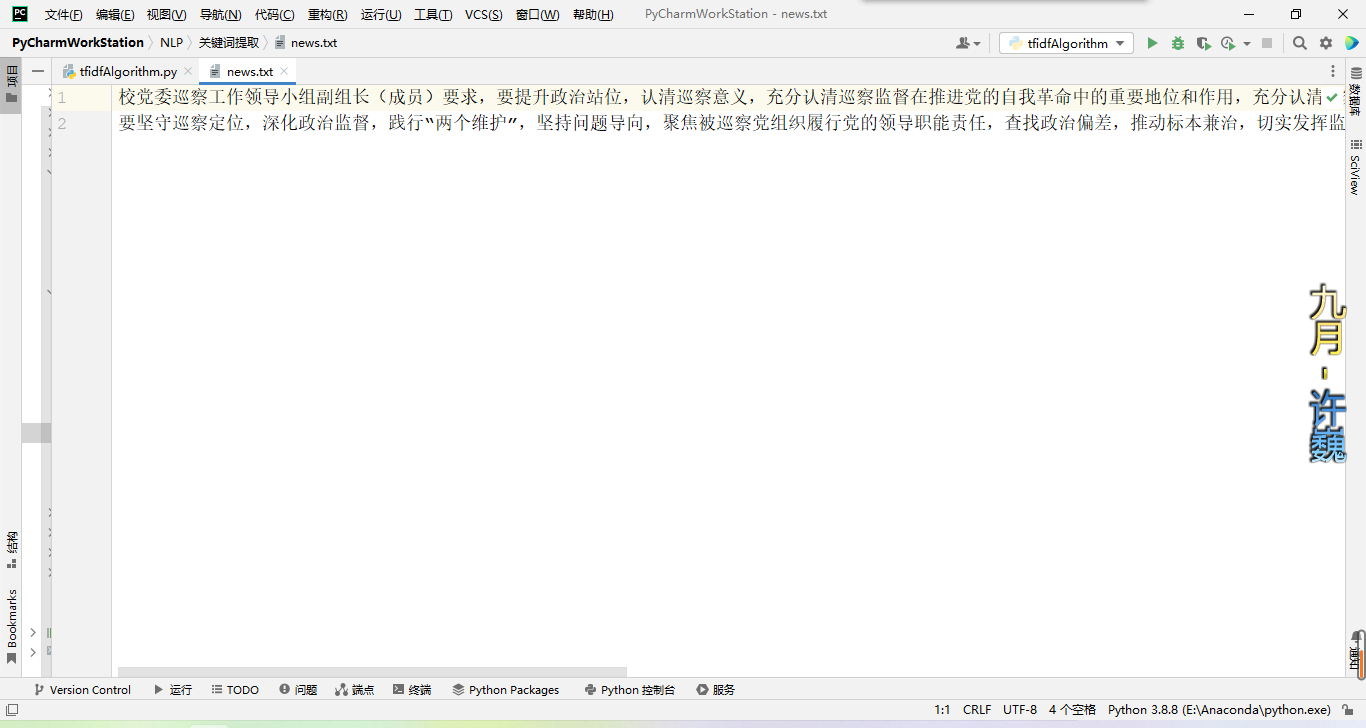
运行结果:

所用文件&数据集
训练数据:corpus.txt
停用词词典:baidu_stopwords.txt
测试数据:news.txt

若有收获,就点个赞吧
0 人点赞
