- 构建流程
- 生成并训练模型
def a1():
with open(“诗词库.txt”,”r”,encoding=”utf-8”) as f:
words = [list(line.strip()) for line in f]
# 向量化
model = Word2Vec(
sentences = words,
min_count = 1,
vector_size = 200,
window = 5
)
model.save(“poemModel.m”) # 保存模型 - 通过模型,基于给出的关键字和格式生成诗词
def a2(keywords,type):
# 读取模型
model = Word2Vec.load(“poemModel.m”)
poemList = list(keywords)
for row in range(type[0]):
for col in range(type[1]):
# 查找与keywords相关度最高的字
pred = model.predict_output_word(context_words_list=poemList, topn=100)
# 去除标点符号
rs = [w[0] for w in pred if w[0] not in [“,”, “。”]]
# 随机选取
char = choice([c for c in rs if c not in keywords])
poemList.append(char)
poemList.append(“,” if row %2 == 0 else “。”)
print(poemList)
sclen = type[0] * (type[1] + 1)
last = “<%s>” % “”.join(poemList[:-sclen]) + “\n” + “”.join(poemList[-sclen:]) # 添加题目 - ">主程序
def run():
# 定义诗词的类型和格式
types = {“五言绝句”:(4,5),”七言绝句”:(4,7),”对联”:(2,9)}
# 调用a2()生成指定格式的诗词
a2(“雨”,types[“五言绝句”])`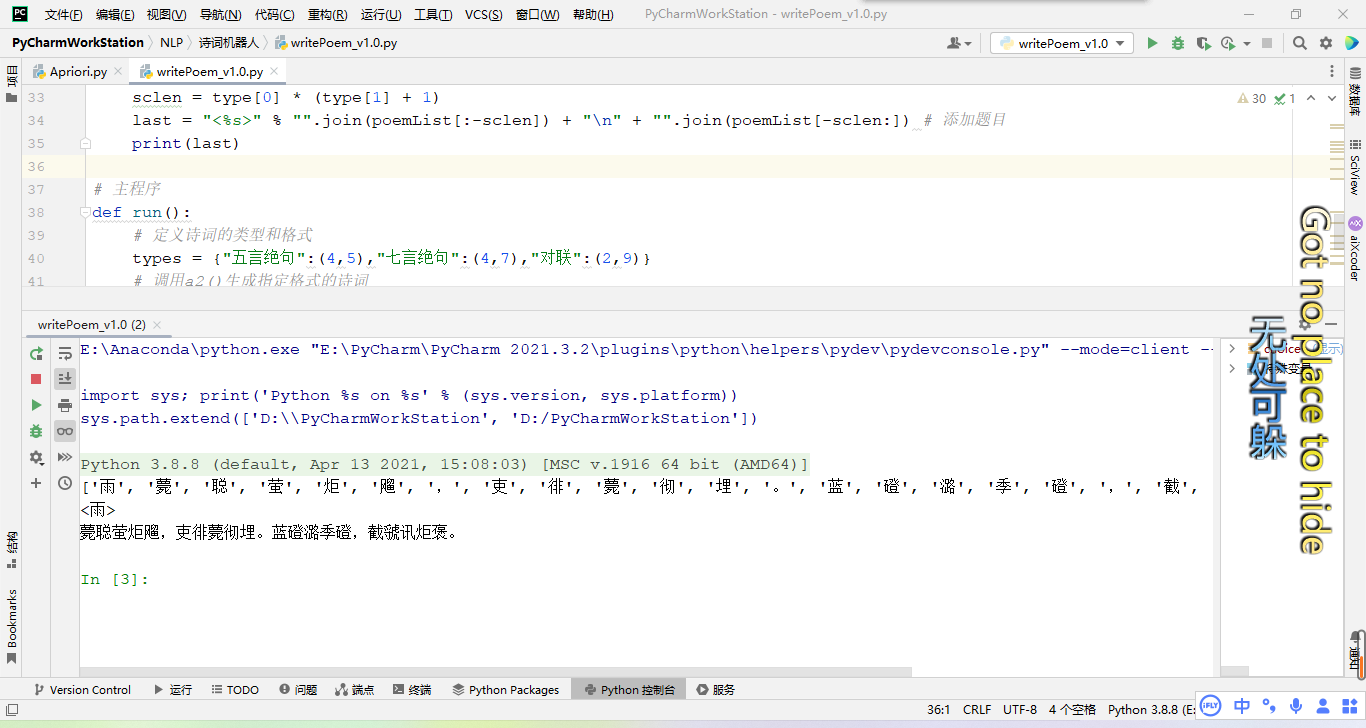
构建流程
1、创建训练数据集
2、向量化
3、查找和目标字词最相似的字词(指定个数)
4、随机挑选,将其组装成要求格式的诗。
`from random import choice
from gensim.models.word2vec import Word2Vec
生成并训练模型
def a1():
with open(“诗词库.txt”,”r”,encoding=”utf-8”) as f:
words = [list(line.strip()) for line in f]
# 向量化
model = Word2Vec(
sentences = words,
min_count = 1,
vector_size = 200,
window = 5
)
model.save(“poemModel.m”) # 保存模型
通过模型,基于给出的关键字和格式生成诗词
def a2(keywords,type):
# 读取模型
model = Word2Vec.load(“poemModel.m”)
poemList = list(keywords)
for row in range(type[0]):
for col in range(type[1]):
# 查找与keywords相关度最高的字
pred = model.predict_output_word(context_words_list=poemList, topn=100)
# 去除标点符号
rs = [w[0] for w in pred if w[0] not in [“,”, “。”]]
# 随机选取
char = choice([c for c in rs if c not in keywords])
poemList.append(char)
poemList.append(“,” if row %2 == 0 else “。”)
print(poemList)
sclen = type[0] * (type[1] + 1)
last = “<%s>” % “”.join(poemList[:-sclen]) + “\n” + “”.join(poemList[-sclen:]) # 添加题目
主程序
def run():
# 定义诗词的类型和格式
types = {“五言绝句”:(4,5),”七言绝句”:(4,7),”对联”:(2,9)}
# 调用a2()生成指定格式的诗词
a2(“雨”,types[“五言绝句”])`
训练数据:诗词库.txt

若有收获,就点个赞吧
0 人点赞
