本章内容哈,已经是咱们研究AIGC技术结合实践工作需求的第三章了
大家看过前两章节的,应该都对AIGC有了一个比较模糊的概念
这次咱们就做模拟设计一个大型KV的主视觉内容
无论是难度系数还是设计强度都远比之前大很多
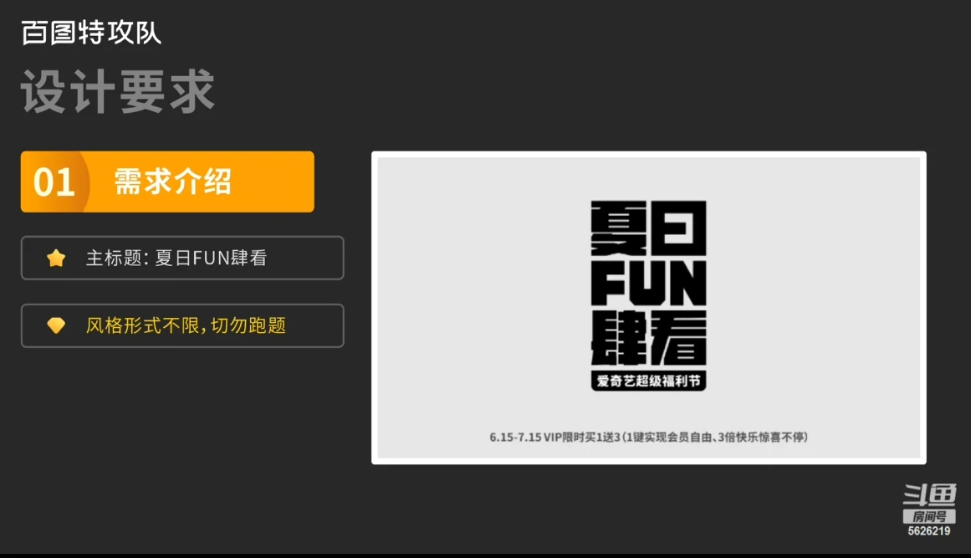
设计需求如图所示
活动目的:
爱奇艺超级福利节的重点在于福利节
目的是通过福利活动来提高拉新转化率
因此根据爱奇艺产品特点及会员权益特点来构思画面
这次内容,之前喵喵同学就已经做过一个比较高质量的结课作业了

当时给她的评分是80-85分之间的水平档次
属于不算特别出众,创意也很平庸
但是视觉质量和整体画面效果都还是说的过去,中规中矩
本次尝试是希望在AI辅助的情况下
提升设计创意与视觉效果,将原版的80分创作提高到90分的水平档次
就是同一个设计师,同技术段位的情况下,AIGC能不能赋能
这就是见真章的时候了
首先在场景构思这个方面
以下图为参考,用辐射构图作为画面构图形式

为什么这么说了
因为很多设计师都有一个比较明显的习惯
这种习惯类似于集邮的概念
比较喜欢尝试之前自己没有做过的构图和设计方向
但是自身能力上往往水平不足,对参考图的分析理解是有很大误区的
这次选择这张强透视的图
其实喵喵同学就是这个习惯
因为之前不会做,不敢做,这次有了AIGC技术加持的情况下
胆子就大了,就想挑战一下自己的软肋
整体画面的视觉聚集性比较强,强透视结构
这张图已经超出她水平120%了
就这,还要再加入一个新的创意概念
用舞台剧为载体,让元素从单独场景汇入画面中心

将每个场景与整个画面融合并互动起来
大致的草图思路是这样:四周为不规则摆放的手机载体,将人物场景放置在手机上,汇聚到画面中心;
画面中心是标题及爱奇艺播放器,向外飞出拟人化 VIP 精灵与场景互动

你们细品一下,这意思是我和科比合砍81分的节奏了
AIGC不是哆啦A梦,你也不是大熊,是没办法做出超出自身认知的设计图的
单独场景以手手机轮廓为载体+舞台剧的形式




在进一步的构思过程中
中心元素:以爱奇艺播放器为核心,高亮突出
影视场景:选取热门影视资源场景,以由远及近、细节饱满到细节模糊的效果向中心聚拢
会员拟人化:将普通、黄金、白金、体育、FUN、星钻会员拟人化,将VIP精灵从中心飞出,与各场景互动
权益展示:以红包、金币等形式强调爱奇艺超级福利节
展示卖点:VIP限时买1送3,一键实现会员自由,三倍快乐惊喜不停,突出活动福利内容
配色:以夏日清爽配色蓝色、黄色为主,以同色系颜色作为辅助色,以爱奇艺品牌色绿色强调活动主题
整体的构思上面还是挺有想法的
但是到这一步哈,思路一直停留在一个抽象的概念上
不够具体,脑海里面的画面感也比较弱
这就是我们俗称的“思路不清晰”
在具体的构成过程中,选择的素材内容包括
从爱奇艺的热门影视中挑选出经典剧照或标志性造型来作单独场景




《周处除三害》、《狐妖小红娘》、《种地吧少年》、《青春环游记》等热门影视及综艺
视觉风格上,选择妖怪屋的卡通剪纸造型作为插画的设计风格



走到这一步,其实你们也感受到了把
设计者依旧没有解决一个硬伤问题
就是自己到底要画成什么样子的图,是完全没有概念的,把握不住的
在这种情况下,急于求成的开始用MJ抽卡,风险就非常的高
使用describe直接描述画面


通过参考图,可以直接得到一下几组词缀


可以看出,这些关键词没什么实际帮助,因为画面的元素内容是不可用的,不需要画面中元素的prompt提示
因此挑战了一下思路,改为询问ChatGPT 来获取参考图中的构成形式的描述


这个高清大图,大家应该能看清楚了,可以看出,由于问题的指向性不够明确,ChatGPT从多个角度进行了全面分析,但是又没什么重点
需要提高问题的指向性,提供更精准的描述
继续提问“请帮我只从构图布局上来详细分析

在这一步,ChatGPT虽然提供了构图分析
但这些分析基于图例,无法直接帮助我生成新图片的prompt
意思就是,AI工具只能被动按照你的思路来阐述结果内容
不能产生破局的新方向
这对于创意设计就非常的致命
由于设计者本身也有点思路不清晰,仍在构思阶段对具体画面没有确定想法
也无法提供详细信息,因此需要ChatGPT直接给出一个可以尝试的prompt
从这一步开始,整个设计的走向,就完全随机化了
这一步,我按照历史性的角度给你们解析一下,就是签了一个丧权辱国的辛丑条约了
设计的主动权完全不在设计师手里了,全凭AI去掌握设计节奏了,也为后续的发展埋下了伏笔
问题:如果我想用Midjourney生成一张这样构图布局的画面,我应当怎么写prompt?
图片参考

生成结果


可以看到ChatGPT生成了一段详细的prompt,并从整体、布局、前景、中景、背景、色彩、风格、细节等方面分析了画面构成
这段prompt过长,不符合Midjourney的prompt书写规范
包含了许多无效词汇
因此,需要对这段prompt进行精简,并用更专业的词组进行优化
这个过程,真的非常耗时,也需要设计者不断地纠正词缀
可不比直接做设计轻松哦
继续追问ChatGPT:请帮我将这段prompt用更精简、更专业的词组优化
这里GPT的模型迭代中,已经能高度适配MJ的书写规范了
所以直接这么说,GPT是能懂你意思的

可以看到,虽然prompt经过精简,但仍不符合书写规范
且存在很多无效词汇,仍需进一步优化
问题:
请帮我将这段prompt用更精简、更专业的词组优化
你看看设计者像不像大熊,AIGC像不像哆啦A梦

这一次结果已有显著优化,prompt结构大为精简
但仍需进一步去掉其中不需要的具体元素描述
将prompt中的符号替换为“,”分解长句,优化结构

去掉不需要的描述,并替换需要的元素

由于在Midjourney的prompt书写规范中,冒号通常不具备特殊作用
Midjourney的prompt书写主要依靠简洁明了的描述和关键词来定义图像内容
使用冒号可能不会对生成结果产生实际影响
因此最好使用简洁的描述来明确表达需求,所以再次进行替换

最终调整之后的可行性词缀是这样
Dramatic, intricate illustration, Central stage, radial composition, characters, Gold coin and Red packet decorations, decorations, contrast for tension, vintage Style, fantasy Style, mystery, balance, dynamic elements floating elf, cohesive, engaging, surrealism, Symmetry
风险警告哈,以上词缀表面上是设计者的思路想法,实际上全是AIGC产出的想法结果,过程中设计者只是不断完善了词缀的语法问题,直接使用/imagine生成

可以看到画面好看是好看,但与爱奇艺的创意KV毫不相干
使用/imagine的垫图功能
参考垫图

生成结果

从生成结果来看
还是好看没什么实际用途
使用—sref风格参考指令,并添加—ar 16:9

越来越离谱了,场面完全失控了
如果这是一个工作需求,这个时候已经是无法挽救的地步了
要么扣工资,要么准备打辞职报告了
设计者还想试一下,重新调整prompt并使用sref
由于不知道是哪些词造成了画面偏差,因此尝试去掉几个可能影响画面的prompt
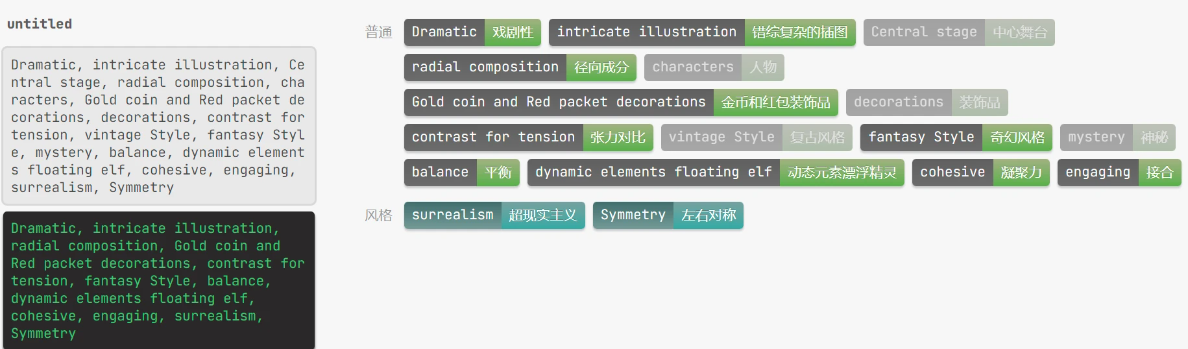
这一步,就完全是英语考试 猜ABCD选择题了

结果基本没多大变化
再次使用垫图功能:参考图


事已至此,已成艺术,越来越抽象了
使用prompt直接生成图片

不能说是跟本次需求毫无关系吧,至少是八竿子打不着了
可以看出,过度依赖ChatGPT和Midjourney是无法生成,设计者自己也不清楚的画面效果的
无法根据经验调整prompt的准确性,也难以把控最终的画面效果
那么调整一下思路
这一次以生成单独场景为目标,从局部去描述prompt
本次选取乐队节目作为画面元素

A square frame, There’s a band singing up there, Paper-cut wind, Flat illustration, Simple modeling, Bright color, Lively atmosphere, White background —ar 16:9
这组词,也是一拍脑袋搞的东西
根本禁不起推敲,也没有好好构思
生成的结果也很随机

又进行了垫图处理
参考图是

结果稍微看得过去了

右上人物清晰,造型稳定,但风格偏向二次元漫画
左下人物风格更偏3D
右下生成了多个人物,但比例不一致,风格也偏向二次元漫画
综合来看,左上图更符合剪纸风格的简单造型,因此选择左上图来生成变体

生成结果

这一步的四个生成结果没有差别
人物造型过于复杂,头发和衣服不稳定
虽然这些结果较为符合剪纸风格的造型,但可用性很差,调整难度颇大
进一步调整尺寸,生成单一人物造型
上图中的四个画面,人物形象较符合剪纸风格
但画面中存在很多无用的辅助图形
因此,尝试去掉尺寸限制,使用1:1比例
希望在这种情况下,画面重点能更集中在人物造型上

生成的人物造型受到《阴阳师》妖怪屋的影响较大
右上和左下的造型过于接近妖怪屋人物造型
左上的人物头部兽化,四肢生成比较混乱
右下人物造型较为稳定,与乐器互动良好,因此选择右下图进行进一步变体

加入Guitarist, vocalist, bass player, drums乐队人员描述
由于尺寸大小对画面没有改善,这里重新加入16:9的尺寸参数
A square frame, There’s a band singing up there, Guitarist, vocalist, bass player, drums,Paper-cut wind, Flat illustration, Simple modeling, Bright color, Lively atmosphere, White background —ar 16:9

生成的图像质量不如上一张,人物造型较复杂且图像效果不佳
这好不容易看到点希望,又瞬间打回原形了
到这里,设计者的心态就完全炸裂了
开始病急乱投医了,盲目生图
在调整思路的过程中,由于无法明确预期效果
因此难以提供具体的调整和优化方向
只能依赖Midjourney生成图片,希望能随机抽卡获得符合预期的作品
找了各种风格的参考图


生成结果



陷入了不断生成图片的死循环,产生了很强烈的赌徒心理,导致思路更加混乱
然后这个方向就彻底放弃了

尽管通过生成的变体作为参考,可以精确描述人物形象以获得准确的素材并组合场景完成绘制
但是这种情况下哈,是在有具体构思和画面草图时才需要的步骤
单纯生成某个局部画面并不能帮助设计者构思全局,仍然无法解决问题
另一次调整思路
describe电影经典场景
这一次选取《周处除三害》的名场面进行describe描述

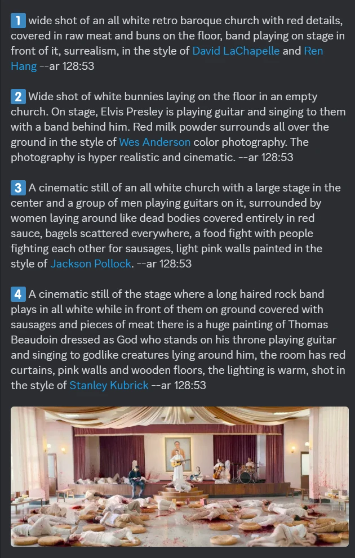

这一步生成了非常不准确的描述
但是相比之下,第四条的描述略显精准,因此选取第四条作为修改的基础prompt
A cinematic still of the stage where a long haired rock band plays in all white while in front of them on ground covered with sausages and pieces of meat there is a huge painting of Thomas Beaudoin dressed as God who stands on his throne playing guitar and singing to godlike creatures lying around him, the room has red curtains, pink walls and wooden floors, the lighting is warm, shot in the style of Stanley Kubrick
Stanley Kubrick是20世纪最著名的导演之一
他的作品视觉独特,非常具有美感

这是优化前的词缀
将prompt按照分句、去除无效词、调整结构、替换词组的方式修改,获得更贴近画面的prompt

尝试直接使用/imagine 生图

这时候设计者的心情是这样
安慰自己,还可以抢救一下
调整prompt
由于画面太过写实,我加入了vector art style, simple shapes的描述,希望调整为矢量艺术风格,造型简单,但画面没有改变

再次调整prompt
考虑后去掉部分可能影响画面的prompt,例如舞台电影效果,可能造成图片过于写实

生图结果

画面没有改善,且过于血腥暴力,完全不符合需求
到这一步,设计者内心逐渐强大起来,加入风格参考
—sref https://s.mj.run/_DzSoGxCi6o
这是一张风格比较低幼童趣的剪纸风图片,造型和细节简单

希望能够去中和生成图片的血腥暴力,简称“去腥”
生图结果


画面效果依然没有改善
可能参考图的引导效果更强烈一些
随后尝试了使用电影原截图来垫图,但画面过于血腥暴力,所以就不放了
问题汇总:
1)无法给出精准的、具体的prompt描述来控制Midjourney
2)不清楚自己需要什么效果,没有找到符合需求辅助的参考图
3)无法确定生图步骤,反复尝试导致思路更加混乱
4)认为Midjourney在没有人工干预的情况下,可以生成符合预期的图片
5)试图让Midjourney生成我未掌握的技法
本次用时2天完全失败的生图过程
看到没,AIGC的使用风险高不高
就算是一个有一定视觉能力的设计师,在对AI工具有比较熟练的掌握度的情况下
做创意类的大型活动设计,还是有很高的视觉风险
真实情况哈
就拿之前可口可乐的设计项目来讲哈
AIGC到这一步,已经很浪费时间了

最终完成效果

基本上是需要设计师,有远大于AIGC绘图能力的技术,才能驾驭得了的
哪怕是你之前能打到80分的水平线
用AIGC都是一个高风险低收益的方法
AIGC的随机组合,是能给设计师提供很多视觉灵感的
尤其是水平越高,对视觉效果越敏锐的设计师,加成越高

若有收获,就点个赞吧
0 人点赞
