本篇文章为卡昂AIGC内容分享的第二篇,之前的文章可以在主页找到。虽然时隔一年之久,但思路是依然通用的,可配合食用(:

大家好,我是卡昂,很高兴为大家分享我自己个人的一些AIGC工作流经验,以下的内容源于我前几个月来跑通的一些实验结果,本篇文章主要目的在于把复杂难懂的AI知识转化为口语化易理解的专业内容,从AI发展/思维扩散/案例解析等方面系统的整合了AI在我们工作中的应用流程。或许会为想了解AIGC,但面对碎片化知识无从下手的朋友有所帮助。(本文非软件技巧教学,此部分内容可在b站搜索confyui相关UP主获取,推荐:惫懒の欧阳川/Nenly同学等)


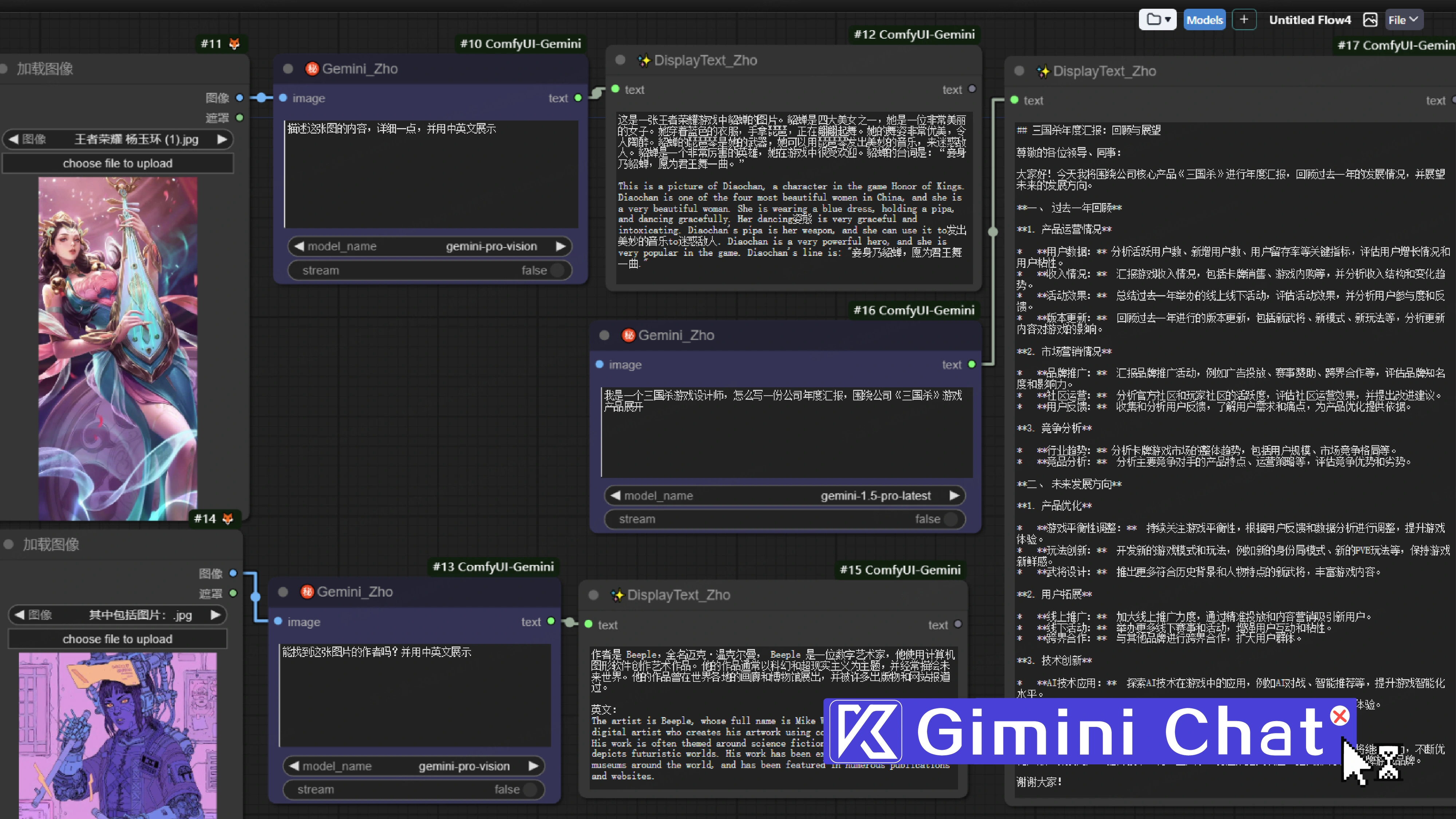
通过giminichat节点可以为我们的图片写出更精准的提示词
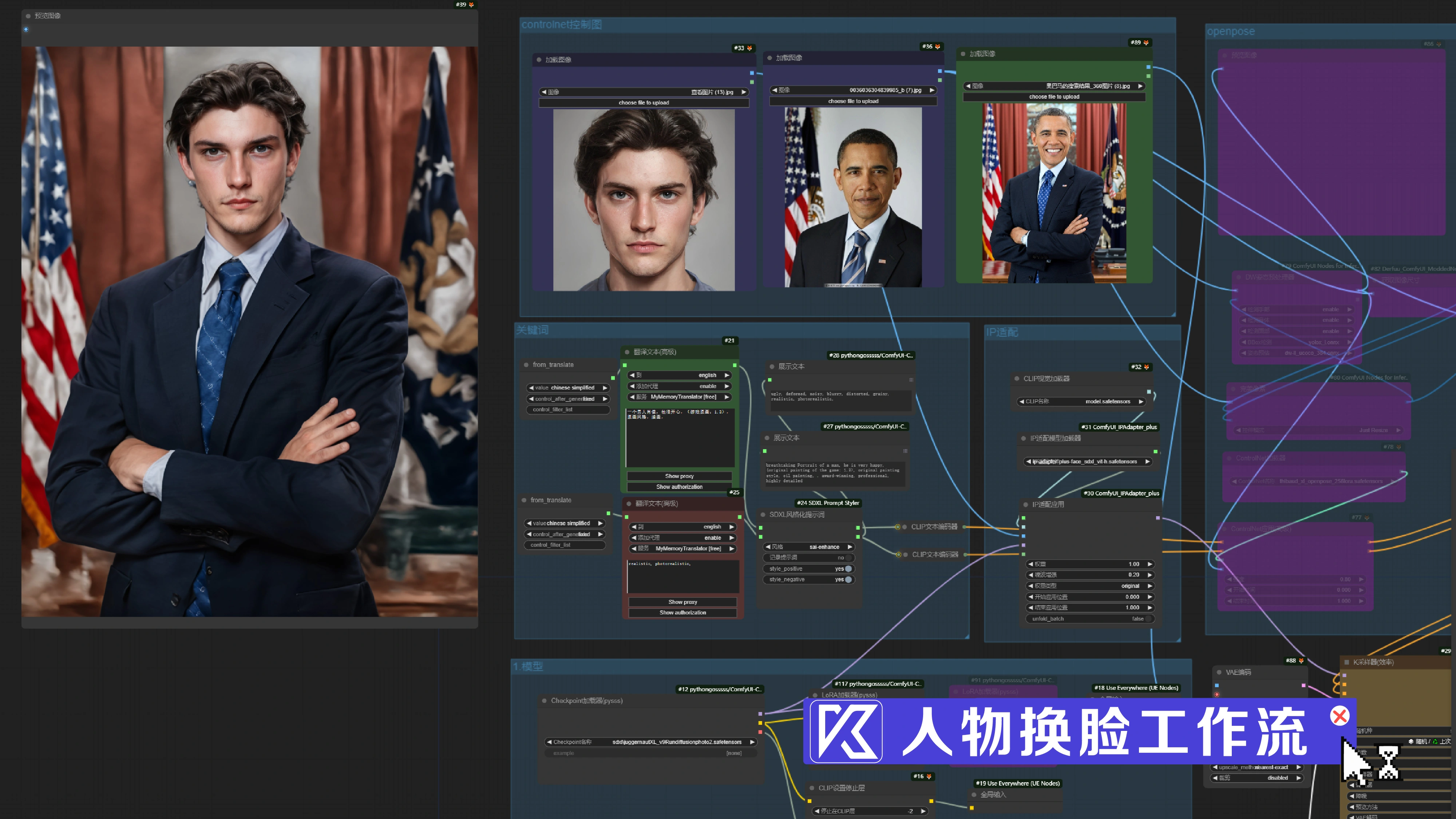
通过comfui用ipadepter或InstantID实现人物换脸

在插画转3D之后加一个抠图节点即可 一键出png透明素材
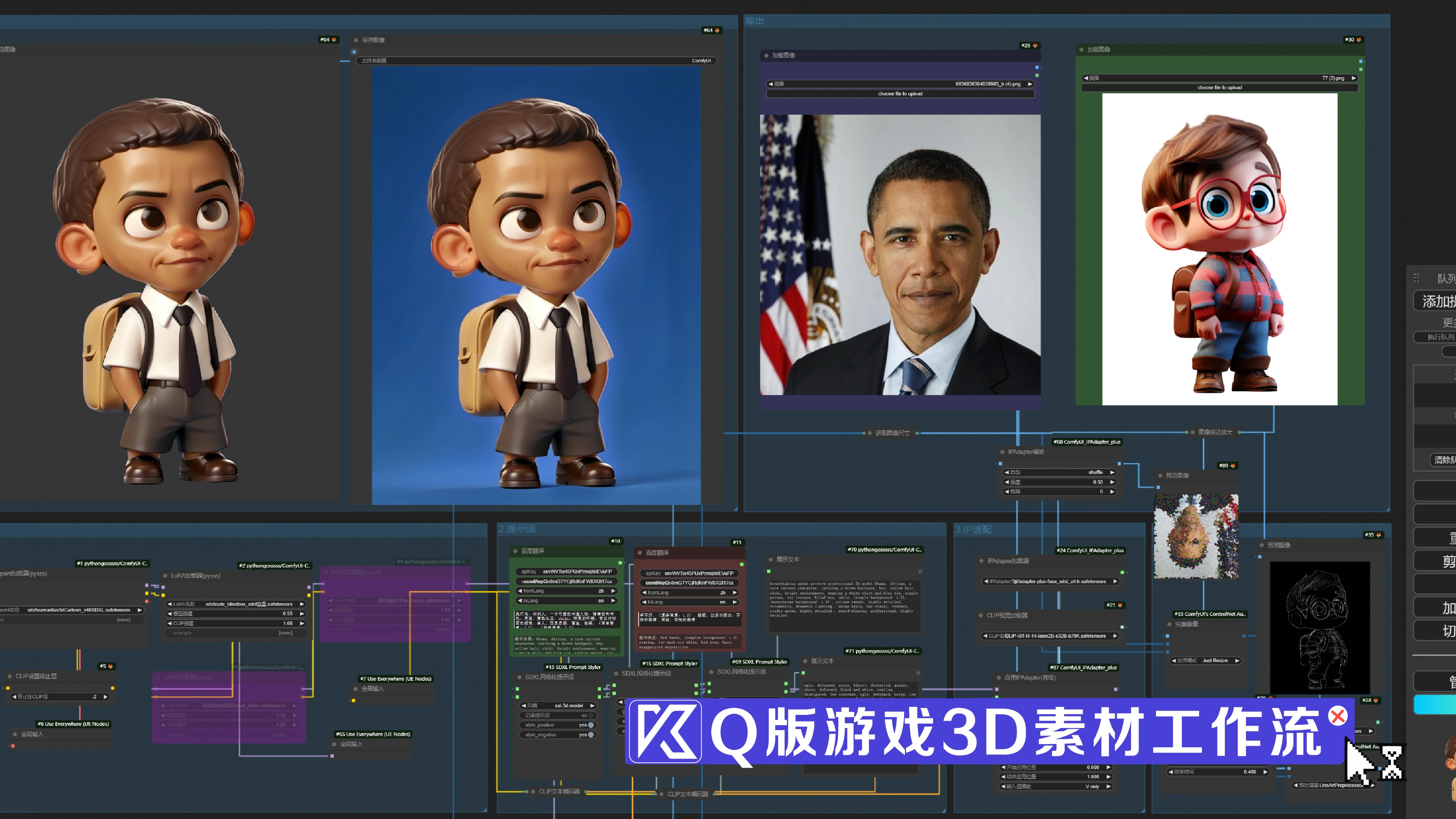
使用comfyui工作流一键生成人物IP形象,详细内容请点击播放视频

使用工作流一键转绘水墨插画,详细内容请点击播放视频
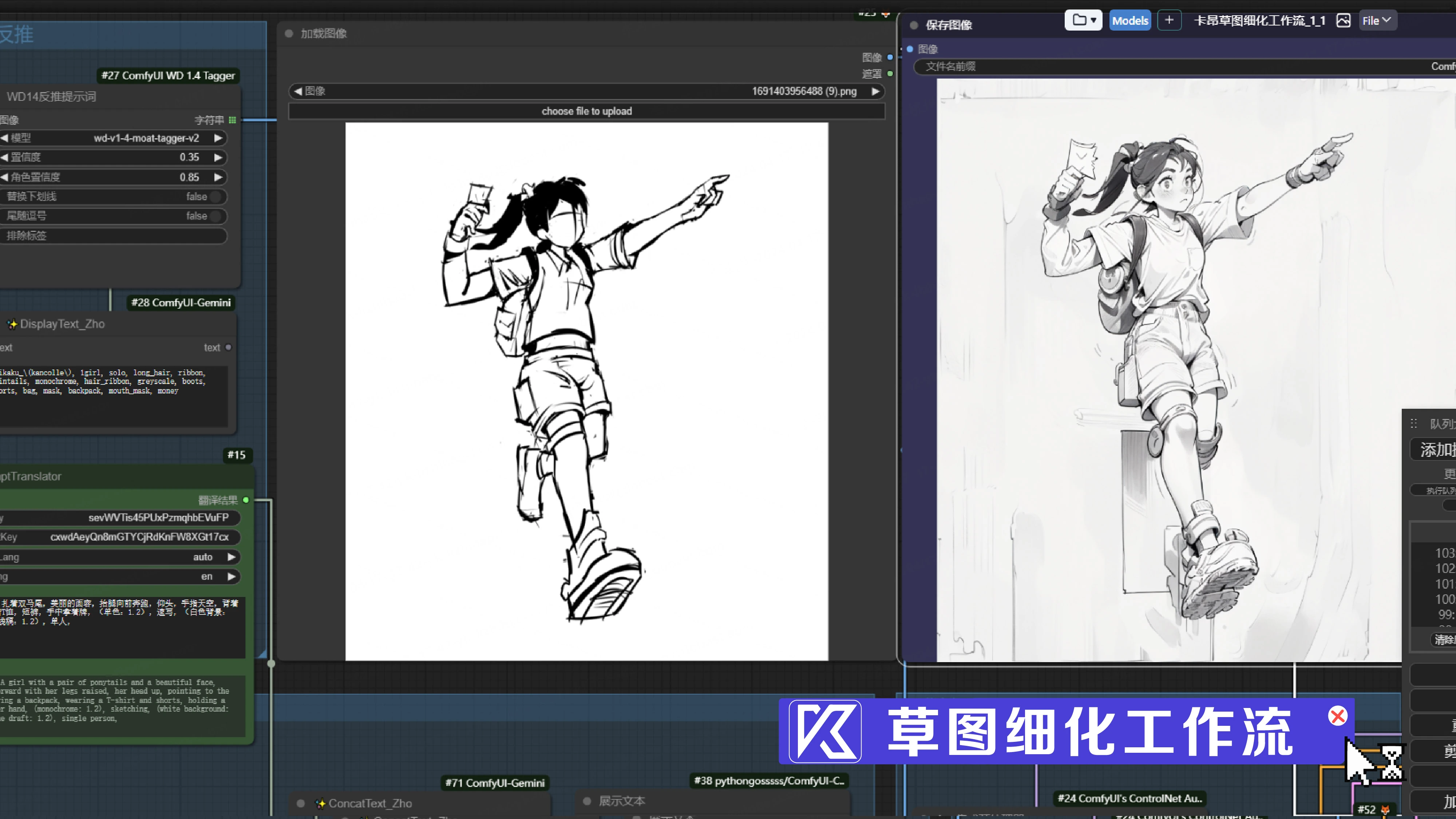
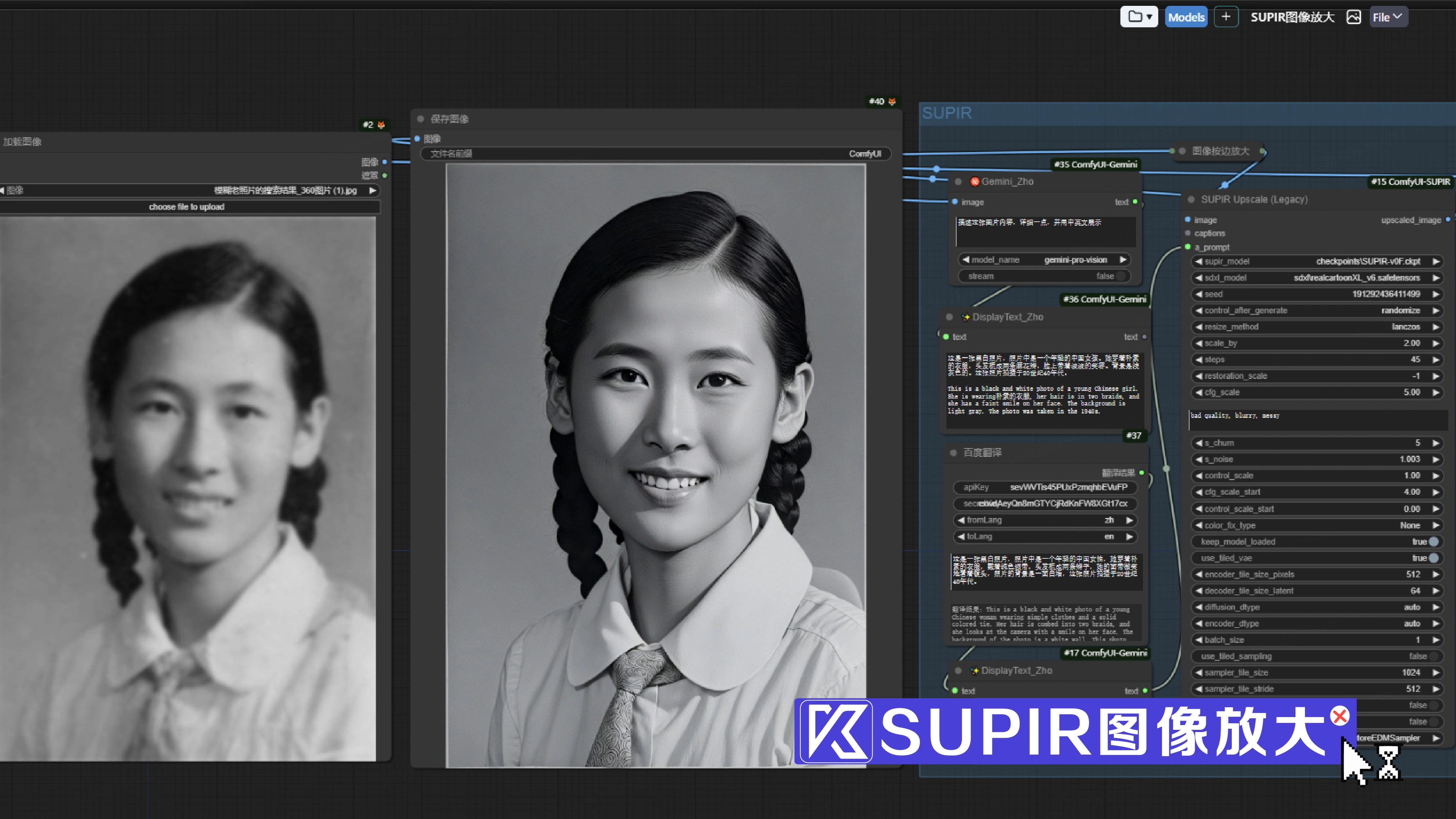
通过comfyui-supir节点对模糊图像进行高清放大







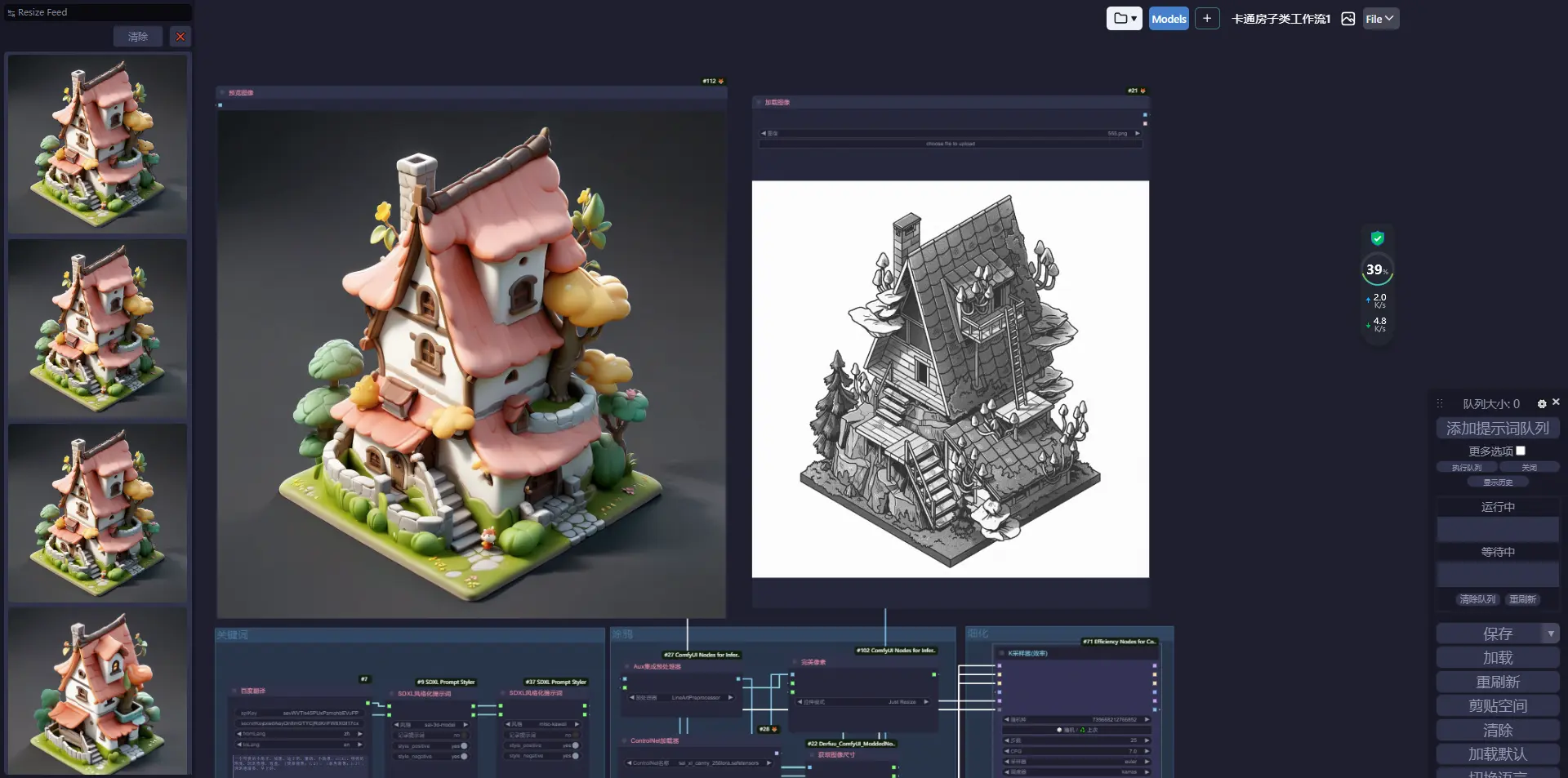


设计是一个从定义目标到落地工程并且不断运营的持续过程,而非仅进行外形的绘制。AI可以把自己从某部分重复劳动里解脱出来,提高设计师的效率以及突破风和格技能上的限制,把更多的时间留给思考。

1.经常被问到的问题:MJ和SD(包含webui和comfyui)哪个更好?这个看你的项目要求,
MJ适合从无到有0-1
(跑图出概念或素材)
sd更适合内容细化1-2
(细化素材)。如果你需求方只是要某个风格非具体的内容,那可以用mj出概念给他选,然后再修改细节。如果需求方指定要什么角度什么人物,长什么样,什么表情,什么衣服,什么动作,什么角度等等,那就sd适合。总的来说,软件不是选墙头站队,我选择用mj跑概念,用sd细化,如果需要输出视频,那就再加runway等,实现1+1必定大于1的效果。
2.sd的模型细分化很严重,导致知识量过多,或者说目前有些乱,1.5/xr/lcm/xrturbo/lightning等,每个模型品类的效果和参数设定都不太一样,如果只用一个品类里的某个模型跑万能效果,那是不可能的。mj就很方便,输入关键词风格就可以调用任何(大方向来说)风格内容。但不是说“谁更好”,这个要看具体的工作需求去搭建对应工作流程。
3.一般商业需求来说,不是给画爽图,修改和需求指定是必备过程,这时候高标准的指定需求,mj就无法推进了。但sd做大场景/小众风格很难找到合适的模型,这时候就可以结合mj出图sd细化的流程,mj理论上可以看做一个sd的无限大模型,因为他什么风格都能出,而sd的工作流画风往往局限于某个模型自身,但这个是互为优缺点,因为风格高统一性又是业务需求必备的,总之这是工具,结果还是看人。

1.SD1.5:
普遍大小:2-6G,优点:低配置运行/模型切换速度快,风格稳定,配置环境完善,模型库丰富。缺点:风格单一,底图尺寸小。出图精致度偏低,语义理解度低。GPU推荐:4-8G+
2.SDXL:
普遍大小:6.4G以上,优点:风格多样化,通过提示词可以调用不同风格而不用来回切换大模型,底图尺寸大,出图精致度高,语义理解度高,模型库丰富。缺点:运行/模型切换速度慢,风格不稳定,配置环境完善度相对低,配置需求高。GPU推荐:12G+
3.SDXLturbo:
普遍大小6.4G以上,优点:在调低CFG(1-3)值和采样步数(5-10)后,出图速度提高3-5倍依然能得到不错的画质。缺点:质量有损失/无法识别反向提示词/图生图不适合,配置需求高,模型少。GPU推荐:8G+
4.XLlightning:
普遍大小6.4G以上,优点:在调低CFG(1-2)值和采样步数(4-12)后,出图速度提高5-10倍依然能得到不错的画质。缺点:质量有损失/无法识别反向提示词/图生图不适合,配置需求高,模型更少。GPU推荐:8G+
5.SD3:
目前未开源,根据官方的API试用来得出“更大的模型,更好的图形质量,更丰富的效果,更智能的语义解析…以及更高的配置需求,”未来可期。
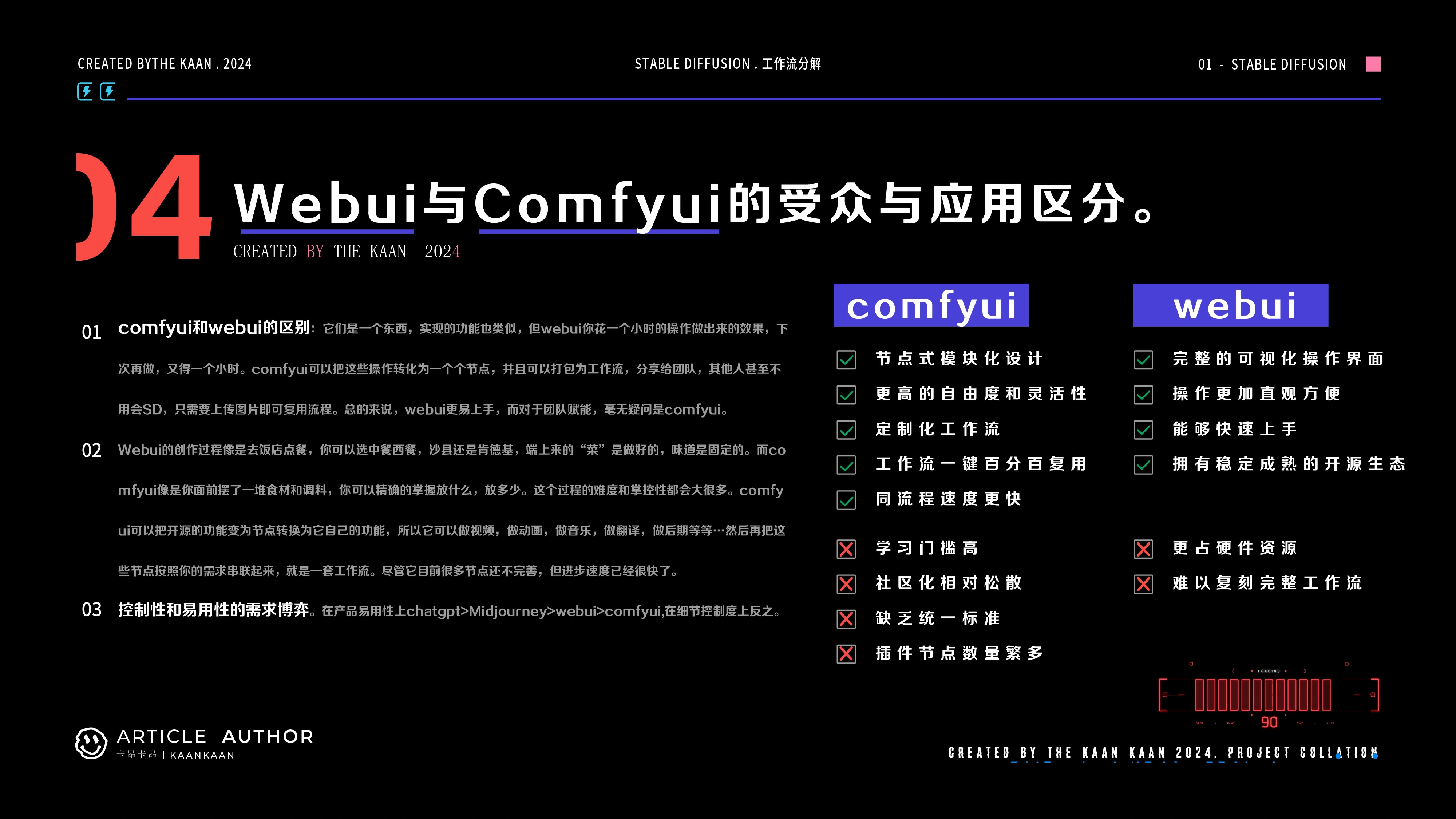
comfyui和webui的区别:它们的内核是一个东西,
实现的功能也类似,但webui你花一个小时的操作做出来的效果,下次再做,又得一个小时。comfyui可以把这些操作转化为一个个节点,并且可以打包为工作流,分享给团队,其他人甚至不用会SD,只需要上传图片即可复用流程。总的来说,
webui更易上手,而对于团队赋能,毫无疑问是comfyui。
Webui的创作过程像是去饭店点餐,你可以选中餐西餐,沙县还是肯德基,端上来的“菜”是做好的,味道是固定的。而comfyui像是你面前摆了一堆食材和调料,你可以精确的掌握放什么,放多少。这个过程的难度和掌控性都会大很多。
comfyui可以把开源的功能变为节点转换为它自己的功能,
所以它可以做视频,做动画,做音乐,做翻译,做后期等等…然后再把这些节点按照你的需求串联起来,就是一套工作流。尽管它目前很多节点还不完善。
控制性和易用性的需求博弈:
在产品易用性上chatgpt>
webui>comfyui,在细节控制度上反之。

stable diffusion核心团队集体辞职:一流的技术人员,二流的运营,三流的内部管理。
SAI团队拥有最好的科研人员,但差劲的营销水平,混乱的内部管理,产品的开源属性造成的投资人的担忧,致使产品内核更新的延期,核心人员的离职。
在忧虑AI强大到改变世界之前,其实“AI”比我们想象的更脆弱。
好的产品也需要好的营销,在这方面openAI的ceo奥特曼就在行多了。即使在sora公开几个月后依然没有对大众开放,但它所造成的噱头让openAI在短期内融资价值越来越高。

Ai淘金时代:买铲子的老黄吃掉了大部分的市场收益
,没有规模效应带来的成本下降,而卖力研发人工智能的企业还没找到合适的商业化模式。此外,AI产品目前本身不完善,处于发展期,没有像Adobe一样形成完整的稳定的提效流程。


应用级工作流都是有针对性的,非万能,
例如我搭建的【插画 一键转3D工作流】受限于模型节点等问题一般只能解决卡通人物/动物/常见物品类内容的生成需求。其他非涵盖的内容就需要针对性的开发另一种工作流,但这已经为我们提供了思路,针对某个需求去攻克一套完善的工作流程,第一张能落地的图可能需要1天/周/月去实验,但后面的一百张每张只需要10秒。举一反三,如果我们根据产品需要去定制50个风格元素类能跑通的完善工作流程,那么这就形成了一套数字资产库。给每个工作流配上封面与说明书,并且定期系统的更新搭建和维护,那么就可以在后续的不同产品需求上选择这1/50中适合的风格方向,在美术产出效率和效果实现范围上都能得到很大提升。
关于开源与闭源:为什么市面上公开的AI工作流大多都不怎么实用?
- 工作流都是有针对性的,别人针对自己的项目所开发的工作流不一定适合你的需求。
- 很多优秀的商业级工作流并不公开,因为这属于个人/公司资产,是开发者付出了很多时间和心血在里面,无论是定制的模型/lora训练,或是工作流节点搭建,都会有很多私域的,我们看不到的内容。当然,我们也能看到很多优秀的工作流,模型节点被创作者无偿开源,“但这是他们的善良而不是职责”。
- 一套好的工作流必须有适配的模型,最合适的模型必然是根据项目而定制的。
- 目前AI的发展环境和配置还不完善/很多产品并没有他们所营销宣传的那么好。

在很多公司,会强制员工去都学会SD等AI软件,这是不太现实的。按以上思路,其实我们可以分出两批受众,1-成立专业团队研发工作流的人,2-使用和应用工作流的人,让少量专业的人按照项目需求开发相应工作流,再教给设计师无门槛复用并修缮bug即可应用在工作中。即效率和效果上可以有无限可能。
这对工作流的研发人员的要求是很高的。例如一套工作流只能能复现百分之三十的质量效果,剩下百分之七十都是bug(人物造型良品率/画面质感/细节还原度等),那么设计师会选择不用这套工作流。因为修缮bug的时间已经超过自己手k的效率了,我们不能为了AI而AI。所以好的工作流一定是能复现百分之七十以上的质量效果。它才值得专业团队去使用。特别是对于高阶需求,这需要开发工作流的团队有极强的专业能力和知识量。这与大众所理解的面向C端的娱乐级AI是两个路线。

我是怎么实验工作流的:人对非自己专业的内容总是用旧常识判断,无法深入了解。因自己本身不通3D技能,就经常给不同的3D设计师朋友发我的工作流结果让他给挑bug,然后根据反馈优化节点/模型和不同参数,争取达到目前认知的最优解,也就是工作流的开发要依据实验而非想象。
目前的情况是
懂技术的人不懂美术,懂美术的人不懂技术,
工作流的作者大多是程序员出身,造成工作流的研发无法根据美术项目很好的落地,而提需求的老板对AI技术的不了解和被营销短视频轰炸下产生了一些不合实际的幻想,从而造成种种问题,但这也形成了一个对应的市场缺口。

游戏公司的AI工作流是最难攻克的,这个也是我认为未来最好的AI工作流会出现在游戏公司的原因。
偏活动营销类的内容,观众不需要付费。
出现画面bug没风险,甚至有些互联网公司以AI产出为宣传点去出内容。但是游戏公司不行,因为玩家是需要花钱买皮肤/道具/内容,他们对AI味AI感很抵制,这个风险很大。
所以如果攻克应用级的工作流就必须完全达到百分百还原手k效果的级别,AI工作流在里面能起到百分之七十以上的质量还原才值得使用,从而完善一套应用级的工作流,那是相当庞大的过程。需要环境和人的共同进步。
以上是一些经验和心得分享,欢迎大家共同探讨,如果本篇内容对你有帮助,请给我点赞支持一下吧~


若有收获,就点个赞吧
0 人点赞
