详细内容请见:
huggingface的github:https://github.com/huggingface/transformers
官方文档:https://huggingface.co/transformers/
目录结构
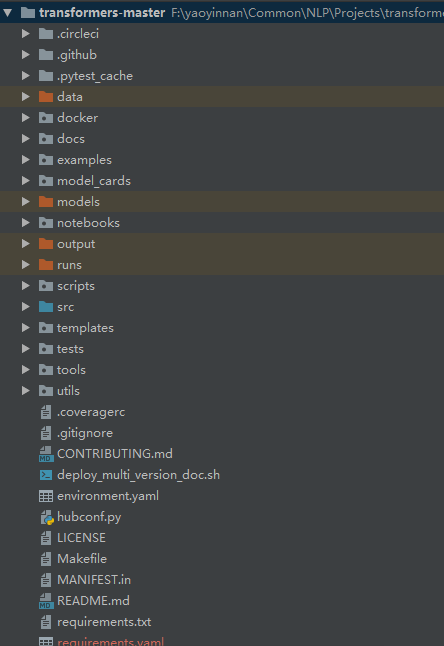
注:原始的目录结构可参照huggingface的github的项目。
核心文件夹:
data:数据集,生成的cache文件也会存放在data_dir的同级文件夹下。
examples:入口文件,包含各类任务的入口文件,如分类回归任务的run_glud.py、多模态任务的mm-imdb、命名实体识别的run_ner.py、问答任务的run_squad.py、多项选择的run_multiple_choice.py、文本生成任务的run_generation.py。详细内容可查看官方github的examples下的README。
models:非官方,自己下载的model,如中文等预训练模型huggingface并未提供,自己下载后可存放在该文件夹下。
output:非官方,模型输出。
scripts:非官方,运行脚本。
src:源包,包含transformers的各个模型的文件,以及读取和评估文件。
如何使用自己的数据集?
配置环境
根据官方提供的requirements.txt安装python虚拟环境。
数据集
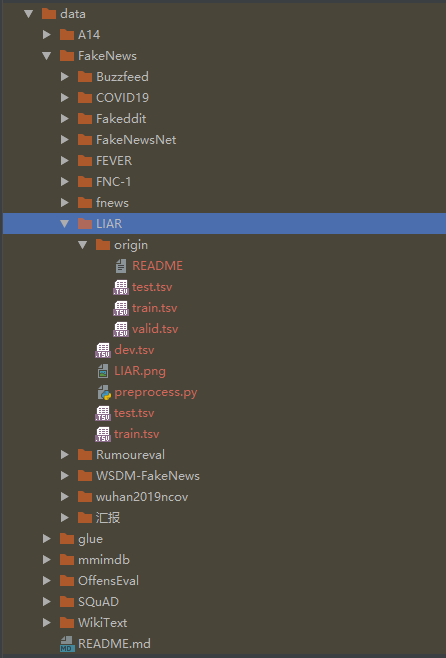
入口文件
选择对应任务入口文件,如run_glue.py,可复制并修改为自己需要使用的文件(如run_classifier.py),以便后续增添自己需要的内容。
运行脚本
可按照如下结构划分各个任务的运行脚本结构,也可自己设计目录结构。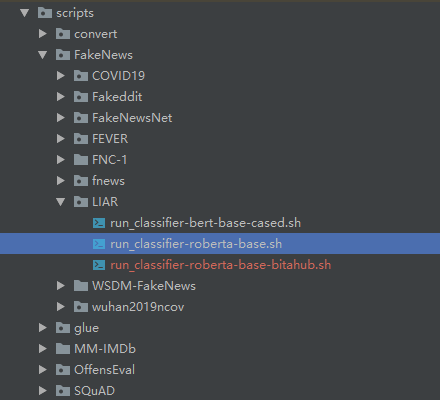
#!/usr/bin/env bashset -euxexport TASK=FakeNews # 任务名export TASK_NAME=LIAR # 子任务名export DATA_DIR=data/${TASK}/${TASK_NAME} # 数据集目录export OUTPUT_NAME=output # 模型输出目录export MODEL=roberta # 模型总称export MODEL_NAME=roberta-base # 模型名称export TRAIN_BATCH_SIZE=4 # 训练批次大小export EVAL_BATCH_SIZE=256 # 评估批次大小export SAVE_STEPS=1000 # 模型输出间隔export MAX_SEQ_LENGTH=64 # 句子最大长度# 用于在前一个输出模型上继续训练export STAGE_NUM=1 # 子模型阶段(可无)export NEXT_STAGE_NUM=3 # 下一个子模型阶段(可无)python ./examples/run_classifier.py \ # 入口文件--model_type ${MODEL} \--model_name_or_path ${MODEL_NAME} \--task_name ${TASK_NAME} \--do_lower_case \--data_dir ${DATA_DIR} \--max_seq_length ${MAX_SEQ_LENGTH} \--per_gpu_train_batch_size ${TRAIN_BATCH_SIZE} \--per_gpu_eval_batch_size ${EVAL_BATCH_SIZE} \--per_gpu_test_batch_size ${EVAL_BATCH_SIZE} \--per_gpu_pred_batch_size ${EVAL_BATCH_SIZE} \--learning_rate 1e-5 \ # 学习率--weight_decay 0.0001 \ # 权重衰减--num_train_epochs 1.0 \ # 轮次输目--output_dir ${OUTPUT_NAME}/${TASK}/${TASK_NAME}-${MODEL_NAME}/stage_${NEXT_STAGE_NUM} \--save_steps ${SAVE_STEPS} \--overwrite_cache \ # 是否覆盖cache,标记则为覆盖,默认读取cache--eval_all_checkpoints \ # 验证所有输出模型--do_test \--do_eval \--do_train \
读取数据
src/transformers/data/processors/glue.py
可复制一份作为自己的读取文件。
包含五个部分,
convert_examples_to_features
XXXXProcessor
各个任务的读取类,以LIAR任务举例。
class LIARProcessor(DataProcessor):"""Processor for the LIAR data set (My version)."""def get_example_from_tensor_dict(self, tensor_dict):"""See base class."""return InputExample(tensor_dict['idx'].numpy(),tensor_dict['sentence'].numpy().decode('utf-8'),None,str(tensor_dict['label'].numpy()))def get_train_examples(self, data_dir):"""See base class."""logger.info("LOOKING AT {}".format(os.path.join(data_dir, "train.tsv")))return self._create_examples(self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")def get_dev_examples(self, data_dir):"""See base class."""return self._create_examples(self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")def get_test_examples(self, data_dir):"""See base class."""return self._create_examples(self._read_tsv(os.path.join(data_dir, "test.tsv")), "dev")def get_pred_examples(self, data_dir):"""See base class."""return self._create_examples(self._read_tsv(os.path.join(data_dir, "test.tsv")), "pred")def get_labels(self):"""See base class."""return ["pants-fire", "false", "barely-true", "half-true", "mostly-true", "true"]def _create_examples(self, lines, set_type):"""Creates examples for the training and dev sets."""examples = []for (i, line) in enumerate(lines):if i == 0:continueguid = line[0]label = line[1]if set_type in ["train", "dev", "test"]:text_a = line[2]text_a = self.preprocess(text_a)examples.append(InputExample(guid=guid, text_a=text_a, text_b=None, label=label))elif set_type == "pred":text_a = line[2]text_a = self.preprocess(text_a)examples.append(InputExample(guid=guid, text_a=text_a, text_b=None, label=None))return examples
tasks_num_labels
类别数。
tasks_num_labels = {"liar": 6,}
processors
指定对应的processor类。
processors = {"liar": LIARProcessor,}
output_modes
任务类型,分类任务(classification)/回归任务(regression)。
评估任务
src/transformers/data/metrics/init.py
评估函数
# micro-F1def acc_and_f1_micro(preds, labels):acc = simple_accuracy(preds, labels)precision = metrics.precision_score(y_true=labels, y_pred=preds, average='micro')recall = metrics.recall_score(y_true=labels, y_pred=preds, average='micro')f1 = metrics.f1_score(y_true=labels, y_pred=preds, average='micro')return {"acc": acc,"precision": precision,"recall": recall,"micro-f1": f1,"acc_and_f1": (acc + f1) / 2,}# macro-F1def acc_and_f1_macro(preds, labels):acc = simple_accuracy(preds, labels)precision = metrics.precision_score(y_true=labels, y_pred=preds, average='macro')recall = metrics.recall_score(y_true=labels, y_pred=preds, average='macro')f1 = metrics.f1_score(y_true=labels, y_pred=preds, average='macro')return {"acc": acc,"precision": precision,"recall": recall,"macro-f1": f1,"acc_and_f1": (acc + f1) / 2,}# classification-reportdef classification_report(preds, labels, target_names=None):f1 = metrics.f1_score(y_true=labels, y_pred=preds, average='macro')report = metrics.classification_report(y_true=labels, y_pred=preds, target_names=target_names, digits=4)return {"report": report,"score_name": "macro-f1","macro-f1": f1,}# 回归任务def pearson_and_spearman(preds, labels):pearson_corr = pearsonr(preds, labels)[0]spearman_corr = spearmanr(preds, labels)[0]return {"pearson": pearson_corr,"spearmanr": spearman_corr,"corr": (pearson_corr + spearman_corr) / 2,"score_name": "spearmanr",}
指定对应任务的评估方法
可自己写一个函数,以替换glue的。
def my_compute_metrics(task_name, preds, labels, target_names=None):assert len(preds) == len(labels)if task_name == "fnews":return {"acc": simple_accuracy(preds, labels)}elif task_name == "liar":return classification_report(preds, labels, target_names)else:raise KeyError(task_name)
运行任务
进入虚拟环境
运行脚本
bash xxxxxxx

若有收获,就点个赞吧
0 人点赞
