有时候用谷歌hack语言真的会找到新的突破点
谷歌
google hack语法
先来个集成语法
https://www.google.com/advanced_search
site:target.com inurl:admin | administrator | adm | login | wp-login | manage | system | console | pwd | reg | forget | member | admin_login | login_admin | user | main | cms | aspx | jsp | php | asp | file | load | editor | Files | ewebeditor|uploadfile|eweb|edit intext:管理 | 后台 | 登录 | 用户名 | 密码 | 验证码 | 系统 | 账号 | admin | login | sys | managetem | password | username
selenium自动化爬取chrome
用selenium的find_elements_by_xpath可以比较简单的爬去chrome
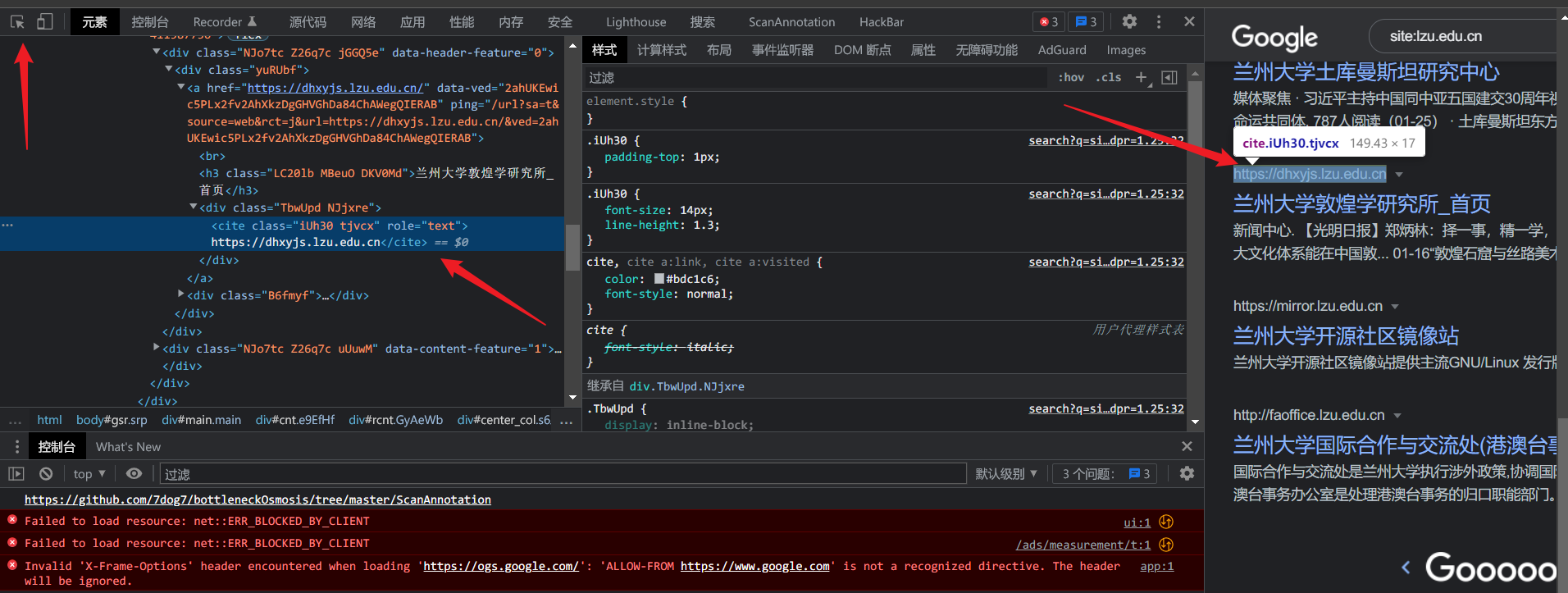
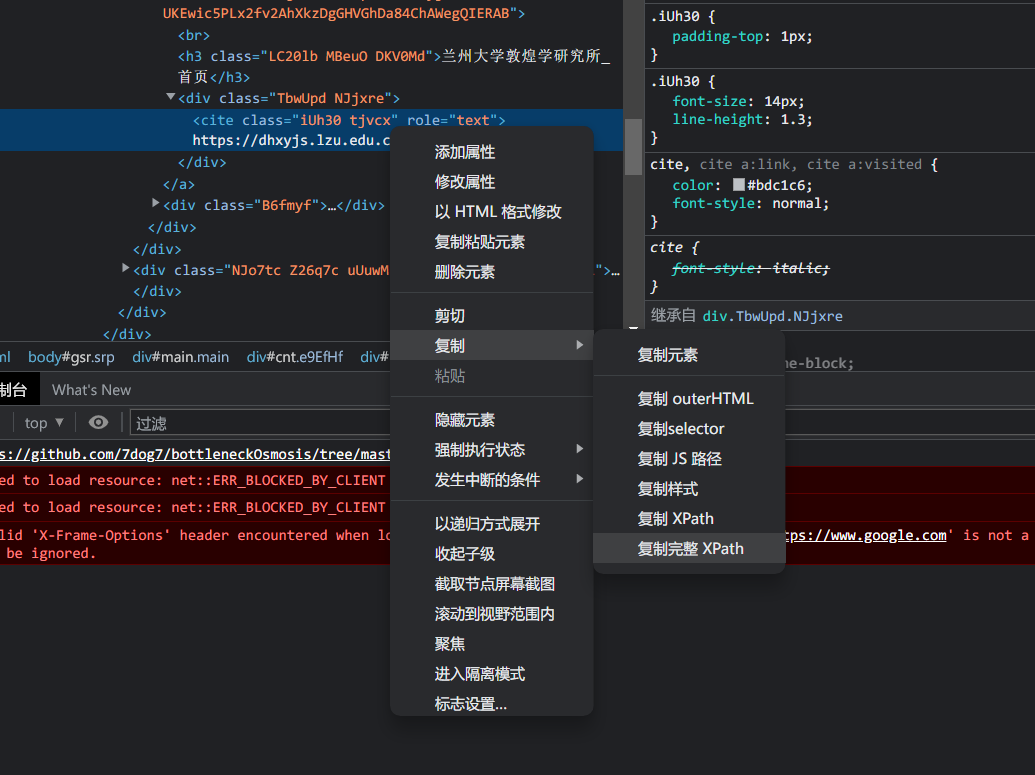
右键复制完整的Xpath,这样省着我们一个一个去查找了
而且如果Xpath换了,也可以很简单的修改源码
- 下载Chrome浏览器,然后去https://npm.taobao.org/mirrors/chromedriver/下载对应之前下载的Chrome浏览器版本的chromedriver.exe
- 将下载好的chromedriver.exe放入python.exe的所在文件夹,然后再放入chrome.exe的所在文件夹。
- 将chrome.exe的所在文件夹设到系统变量中。
python Google_Crawler.py -s "site:lzu.edu.cn" -p 3 -t 5 --gpu
from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.chrome.options import Optionsimport argparseimport timeimport pandas as pdfrom urllib import parseclass ChromeCrawl:def __init__(self,page,timeSleep,Txtname):self.timeSleep=timeSleepself.page=pageself.Txtname=Txtnamepass# 获取页面中出现的链接def getUrl(self):urlList = []#//*[@id="rso"]/div/div/div/div/a/div/cite#//*[@id="rso"]/div[10]/div/div/div[1]/div/a/div/citea = browser.find_elements(By.XPATH,'//*[@id="rso"]/div/div/div/div/a/div/cite')b=browser.find_elements(By.XPATH,'//*[@id="rso"]/div[10]/div/div/div[1]/div/a/div/cite')for i in a:# tmpUrl = i.get_attribute('href')tmpUrl=i.texturlList.append(tmpUrl)print(b)for i in b:urlList.append(i.text)return urlList# 判断传入的元素是否存在def isElementExist(self,by,element):flag=Truetry:browser.find_element(by,element)return flagexcept:flag=Falsereturn flag# 接受爬取页数,开始爬取def allPage(self):page=self.pagetimeSleep=self.timeSleepallUrl = []print("开始爬取")for i in range(page):time.sleep(timeSleep)print("当前为第"+str(i+1)+"页")if self.isElementExist(By.ID,"search"):allUrl.append(self.getUrl())print("第"+str(i+1)+"页爬取完成")if self.isElementExist(By.ID,"pnnext"):browser.find_element(By.ID,"pnnext").click()if i == page - 1:print("全部爬取完成!")return allUrlelse:print("没有下一页,全部爬取完成!")return allUrlelse:print("不存在元素,全部爬取完成!")return allUrl# 处理url并生成csv和txtdef createCsvandTxt(self,aList):with open(self.Txtname.replace(".csv",".txt"),"a+",encoding="utf-8") as f:for i in range(len(aList)):for j in range(len(aList[i])):f.write(aList[i][j].replace(" › ","/")+"\n")csvName=self.Txtnamedomain = []urlL = []for i in range(len(aList)):for j in range(len(aList[i])):parsed_tuple = parse.urlparse(aList[i][j])domain.append(parsed_tuple.netloc)urlL.append(aList[i][j].replace(" › ","/"))urlDict = {"domain":domain, "url":urlL}df = pd.DataFrame(urlDict)df.to_csv(csvName,index=False,encoding="utf-8")class CrawlerConfiguration:def __init__(self):self.TEXT="开始爬取"def ArgumentPars(self):# 传入参数设置TxtName = str(int(time.time())) + ".csv"parser = argparse.ArgumentParser()parser.add_argument('--gpu', action="store_false", help='输入该参数将显示chrome,显示爬取过程,默认为False')parser.add_argument('-s', type=str, default='site:.com', help='请输入你想搜索的google hacking语句,默认为site:.com,以此作为测试')parser.add_argument('-po', type=str, default='127.0.0.1:7890', help='请输入一下谷歌浏览器的代理,默认127.0.0.1:7890')parser.add_argument('-p', type=int, default=1, help='请输入你想搜索的页数,默认1页')parser.add_argument('-t', type=int, default=3, help='请输入翻下一页停顿的时间,默认3秒')parser.add_argument('-r', type=str, default=TxtName, help='请输入你想输出的文件名称,默认为'+TxtName)args = parser.parse_args()return argsdef ChromeInitialization(self):global browserargs=self.ArgumentPars()# 初始化设置chrome_options = Options()chrome_options.add_argument(f"--proxy-server=http://{args.po}")if args.gpu:chrome_options.add_argument('--headless')chrome_options.add_argument('--disable-gpu')chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])browser = webdriver.Chrome(chrome_options=chrome_options)browser.get("https://www.google.com")# 设置爬取目标并开始搜索#/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input是搜索框的XPath,模拟输入点击browser.find_element(By.XPATH,"/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input").send_keys(args.s)browser.find_element(By.XPATH,"/html/body/div[1]/div[3]/form/div[1]/div[1]/div[3]/center/input[1]").click()print(self.TEXT)newChromeCrawl = ChromeCrawl(args.p, args.t, args.r)# url处理newChromeCrawl.createCsvandTxt(newChromeCrawl.allPage())# 结束browser.quit()if __name__ == '__main__':newCrawlerConfiguration=CrawlerConfiguration()newCrawlerConfiguration.ChromeInitialization()
Bing
平常用bing比较多,所以也记录一下他的小技巧
双赢号””
在想要搜索的文字前后加上双引号,搜索结果就会严格按照被引用的内容进行匹配,包括文字内容和字符顺序。
表格
| 关键字 | 定义 | 示例 |
|---|---|---|
| contains: | 确保搜索结果锁定到带有指定文件类型链接的站点。 | 若要搜索包含 Windows Media 音频 (.wma) 文件链接的网站,请键入 music contains:wma。 |
| ext: | 仅返回带有指定文件扩展名的网页。 | 若要查找以 DOCX 格式创建的报告,请键入主题,然后键入 ext:docx。 |
| filetype: | 仅返回以指定文件类型创建的网页。 | 若要查找以 PDF 格式创建的报告,请键入主题,然后键入 filetype:pdf。 |
| inanchor: 或 inbody:或 intitle: | 这些关键字分别返回元数据包含指定术语(如站点的锚点、正文或标题)的网页。每个关键字只能指定一个术语。您可以根据需要串联多个关键字条目。 | 若要查找在锚点中包含“msn”同时正文中包含“spaces”和“magog”术语的网页,请键入 inanchor:msn inbody:spaces inbody:magog。 |
| ip: | 查找指定 IP 地址托管的站点。IP 地址必须由点分隔为四部分。键入 ip: 关键字,后接网站的 IP 地址。 | 键入 IP:207.46.249.252。 |
| language: | 返回指定语言的网页。直接在 language: 关键字之后指定语言代码。 | 若要只查看关于古董的英文网页,请键入 “antiques” language:en。 |
| loc: 或 location: | 返回来自指定国家或地区的网页。直接在 loc: 关键字之后指定国家或地区代码。若要关注两种或更多语言,请使用逻辑 OR 来组织语言。 | 若要查看来自美国或大不列颠有关雕塑的网页,请键入 sculpture (loc:US OR loc:GB)。有关可以在必应中使用的语言代码列表,请参见国家、地区和语言代码 。 |
| prefer: | 为搜索术语或另一家运营商添加重点,以帮助锁定搜索结果。 | 若要查找足球的相关网页,但搜索内容主要限定在某球队,请键入 football prefer:organization。 |
| site: | 返回属于指定站点的网页。若要关注两个或更多个域,请使用逻辑 OR 来组织域。您可以使用 site: 来搜索 Web 域、顶级域和深度不超过两级的目录。您也可以在站点上搜索包含指定搜索词的网页。 | 若要查看 BBC 或 CNN 网站上关于心脏病的网页,请键入 “heart disease” (site:bbc.co.uk OR site:cnn.com)。若要在 微软 网站上查找关于 Halo 的 PC 版本的网页,请键入 site:www.microsoft.com/games/pc halo。 |
| feed: | 为您搜索的术语在网站上查找 RSS 或 Atom 源。 | 若要查找关于足球的 RSS 或 Atom 源,请键入 feed:football。 |
| hasfeed: | 在网站上查找包含有关搜索术语的 RSS 或 Atom 源的网页。 | 若要查找关于纽约时报网站的包含 RSS 或 Atom 源的网页,请键入 site:www.nytimes.com hasfeed:football。 |
| url: | 检查列出的域或网址是否在必应的索引内。 | 若要验证 微软 域是否在索引内,请键入 url:microsoft.com。 |
- 请不要在这些关键字的冒号后面加入空格。
- 此处介绍的某些特性和功能可能在您的国家或地区不可用。
运算符

bing hack语法
filetype:txt 学号filetype:xls 身份证filetype:doc 邮箱 site:xxx.comsite:xxx.cominurl:asp?id=site:xxx.com inurl:admin|back|manage|manager|login|admin_login|login_admin|system|boss|mastersite:xxx.com intitle:管理|登陆|后台site:xxx.com 管理|登陆|后台|用户名|密码|验证码|系统|账号|manage|admin|login|system# 查找上传页面site:xxx.com inurl:filesite:xxx.com inurl:load# 查找编辑器页面site:xxx.com inurl:fckeditorsite:xxx.com inurl:ewebeditorsite:xxx.com inurl:robots.txtsite:xxx.com inurl:txtsite:xxx.com filetype:mdbsite:xxx.com filetype:ini

若有收获,就点个赞吧
0 人点赞
