edu挖洞经验分享 · 语雀 On W X W W PP XX
Adblocker

edu 挖洞经验分享
edu 挖洞经验分享
返回文档
实战更多是信息收集,有大佬说渗透的本质是信息收集,这里是我自己的笔记有点乱但实战效果的记录
https://amused-run-b56.notion.site/70d0bba69fad48878d699fbea19618dc
挖到洞可以提交 360有钱(推荐) 补天有库币 edusrc有证书(得挖特定学校比较难,一般 vpn 进内网的洞交它)
nday 刷
(重复率高,学不到啥,但如果能第一手 nday 可以很快上分)
http://wiki.peiqi.tech/ fofa 找特征 文库 poc 打
fofa 关键字批量打或者挑系统用户多的打:(常用)
(不用收集子域名时间效率高一点,但不能练定向打点)
比如我的脚本(限制 1w 条),也可以https://github.com/samshuai/fofa_view 收集(限制 1000 条)
org=\”China Education and Research Network Center\” 是教育归属的
收集到的放到批量识别指纹和爆破路径的https://github.com/broken5/WebAliveScan 进行指纹识别对 shiro 这些打一波
比如我搜集:忘了密码关键词
- 我会先尝试 找重置密码的洞 再简单爆破(先密码 12346 爆破常用用户名,当然收集该学校学号和工号最好) 爆破子典推荐https://github.com/TheKingOfDuck/fuzzDicts
- 一旦爆破出弱口令 就进后台找文件上传 没有就联动xray(无 waf) 【进了后台一般很多洞】
3.(无法爆出可以爆破路径推荐dirsearch 和看 js 和尝试改包登录绕过或者更细的信息收集,实在不行换一个别死磕 )
Shell
复制代码
import json import time import requests import pandas as pd import base64 from urllib.parse import quote,unquote header \= {“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36”} def spider(SearchKEY): # APIkey 和邮箱 FOFAEMAIL \= “1412673980@qq.com“ FOFAKEY \= “2ba9cd7cbef4f1749aa5da48621334c4” searchbs64 \= quote(str(base64.b64encode(SearchKEY.encode()), encoding\=’utf-8’)) # searchbs64 = (str(base64.b64encode(config.SearchKEY.encode(‘utf-8’)), ‘utf-8’)) html \= requests.get(url\=”https://fofa.so/api/v1/search/all?email=”+FOFA_EMAIL+”&key=”+FOFA_KEY+”&qbase64=“+ searchbs64+”&fields=host,ip,port,title,baseprotoco”+”&size=10000”, headers\=header).json() strhtml\=json.dumps(html) loaddata \= json.loads(strhtml) data \= load_data.get(“results”) return data #print(data[0]) #print(type(data)) def ip_read(): try: listInfo\=[] SearchKEY \= “org=\”China Education and Research Network Center\” && country=\”CN\” && body=\” 找回密码\””#<================== 要改的地方,建一个 / result / 文件夹 if len(spider(SearchKEY)) !\= 0: data\=spider(SearchKEY) for i in data: if i not in listInfo: listInfo.append(i) return listInfo except Exception as e: print(e +”\n”) print(“Read person_information error!”) def save(lists): host\=[] ip\=[] port\=[] title\=[] for list1 in lists: host.append(list1[0]) ip.append(list1[1]) port.append(list1[2]) title.append(list1[3]) dataframe \= pd.DataFrame({‘host’: host, ‘ip’: ip,’port’:port,”title”:title}) # 将 DataFrame 存储为 csv,index 表示是否显示行名,default=True dataframe.to_csv(“./result/“ + str(time.time())+ “.csv”, index\=False, sep\=’,’) print(“it save ok”) def main(): #file_path = str(input(“请输入批量读取 ip 的文件路径:”)) lists\=ip_read() save(lists) #ip_read() if __name \=\= ‘__main‘: main()
定点打(推荐)
对于选目标
(我是比较随便,听说 360 职业中学不收,我一般不打职业中学,但好打)
1 谷歌收集关键词职业学校 大学 等
2 直接 edusrc 挑,出洞多(可能重复) 出洞少(可能资产少)
3 额或者文库批量 nday 打中的学校 当 nday 突破口打
信息收集
这些看看这篇和我的
个人步骤:
企业查查(知识产权网站备案获取根域名)—>oneforall 收集子域名 —>WebAliveScan 批量扫存活和简单爆破路径 (识别到 shiro 打一下或者扫到登录的爆破一下)——>goby 批量扫端口(cdn 识别文哥小脚本)——>fofa 批量收集 title 或者批量获取 ip 端口 title 的脚本等—> 谷歌语法收集后台—> 打小程序—> 打子公司—> 打公众号—> 打 app—>
边缘资产类似的秒出子域名网站:
https://securitytrails.com/list/apex_domain/
https://www.virustotal.com/gui/domain/baidu.com.cn/relations
当然还有很多方法以下个人用比较杂
https://amused-run-b56.notion.site/70d0bba69fad48878d699fbea19618dc
https://www.yuque.com/ee/nangod/bh75w2
单个网站
一般得进后台(文件上传、sql 注入、历史漏洞、越权、shiro 有的得进后台才出现特征)getshell 有前台交互除外
收集方法: 忘了密码尝试绕过—>爆破口令 (试 sql 注入,改返回包登录绕过)—> 爆破路径—>谷歌浏览器看 js(pycharm Ctrl+Alt+Shift+L 优化格式好看些)【字典很重要,社工库 + 谷歌收集提高准确率,手机可以用老毛桃电话字典分地区生成, 必要时社工这对学校很好用】——>找真实 ip 扫端口—>打 c 段
小技巧:
谷歌收集
site:xx.edu.cn 使用指南 | 工号 | 学号 | 系统 | vpn | 手册 | 默认密码
找一些系统使用手册有默认密码和账号,然后猜解进 vpn
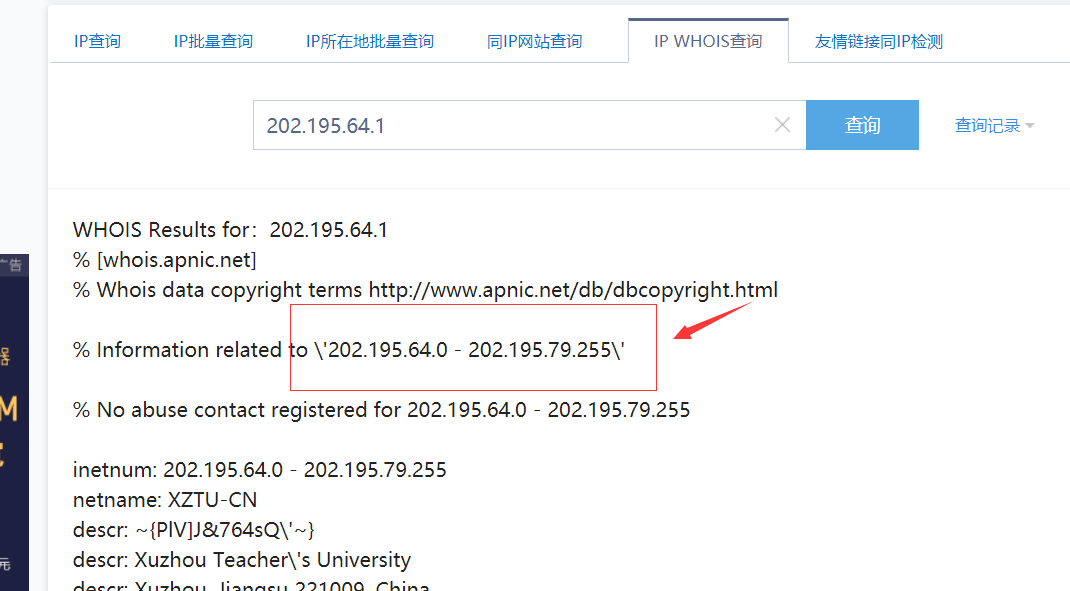
批量 b 段 比如:http://tool.chinaz.com/ipwhois?q=202.195.64.1 为该学校 b 段范围 64-79
IPWHOIS 查询
友情链接同 IP 检测
IP 批量查询
IP 查询
同 IP 网站查询
IP 所在地批量查询
查询
查询记录
202.195.64.1
WHOISResultsfor:202.195.64.1
%[whois.apnicnet]
%Whoisdatacopyighttermshttp:/www.aicd/bcopyrighthtl
\202.195.64.0-202.195.79.2551
%InformationrelatedtoW
M
%Noabusecontactregisteredfor202.195.64.0-202.195.79.255
inethum:202.195.64.0-202.195.79.255
netname:XZTU-CN
descr:PlVjJ8764sQPy
descr:XuzhouTeacherl’sUniversity
元
Shell
复制代码
import json import time import requests import pandas as pd import base64 from urllib.parse import quote,unquote header \= {“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36”} def spider(SearchKEY): # APIkey 和邮箱 <================== 要改的地方 FOFAEMAIL \= “1412673980@qq.com“ FOFAKEY \= “2ba9cd7cbef4f1749aa5da48621334c4” searchbs64 \= quote(str(base64.b64encode(SearchKEY.encode()), encoding\=’utf-8’)) # searchbs64 = (str(base64.b64encode(config.SearchKEY.encode(‘utf-8’)), ‘utf-8’)) html \= requests.get(url\=”https://fofa.so/api/v1/search/all?email=”+FOFA_EMAIL+”&key=”+FOFA_KEY+”&qbase64=“+ searchbs64+”&fields=host,ip,port,title,baseprotoco”, headers\=header).json() strhtml\=json.dumps(html) loaddata \= json.loads(strhtml) data \= load_data.get(“results”) return data #print(data[0]) #print(type(data)) def ip_read(): try: ip \= “202.195.”# 开头 <================== 要改的地方 listInfo \= [] for line in range(64, 80):# 范围 <================== 要改的地方 # 关键词 SearchKEY \= “ip=\””+ ip + str(line) +”.0/24\””print(SearchKEY) try: if len(spider(SearchKEY)) !\= 0: data\=spider(SearchKEY) for i in data: if i not in listInfo: listInfo.append(i) except Exception: print(“ 查 “+line+” 时出错 “) #print(listInfo) return listInfo except Exception as e: print(e +”\n”) print(“Read person_information error!”) def save(lists): host\=[] ip\=[] port\=[] title\=[] for list1 in lists: host.append(list1[0]) ip.append(list1[1]) port.append(list1[2]) title.append(list1[3]) dataframe \= pd.DataFrame({‘host’: host, ‘ip’: ip,’port’:port,”title”:title}) # 将 DataFrame 存储为 csv,index 表示是否显示行名,default=True dataframe.to_csv(“./result/“ + str(time.time())+ “.csv”, index\=False, sep\=’,’) print(“it save ok”) def main(): #file_path = str(input(“请输入批量读取 ip 的文件路径:”)) lists\=ip_read() save(lists) #ip_read() if __name \=\= ‘__main‘: main()
例子:
找到弱口令就可以
本机挂 vpn 进内网,https://github.com/shadow1ng/fscan可以扫一下该学校 b 段(上面说的)就可以内网一堆洞了
漏扫自动挖洞:
https://github.com/test502git/awvs13_batch_py3
awvs 爬虫联动 xray
edu 第一名打法
远海:https://www.websecuritys.cn/
自己看(有点难学得来,得代码审计好)
先挑多人用的系统 批量扫备份 代码审计 批量刷
我朋友核心白帽打法
一般摸那种使用多的那种系统比如正方 我就会从外面探点,按系统分类去探点,这种只要外网能进去 就直接通杀杀一堆, 还有就是从内网往外打,有的时候能进统一门户 vpn 里面进去内网 然后想办法摸里面系统的 day 拿这些 day 去打其他学校的就好了 滚雪球 越滚越大
1 人点赞

08-15 21:26
52
0
投诉
回复

返回文档
正文
14px
color-fontCreated with Sketch.
highlightCreated with Sketch.
素材库
正文
⌘ + K 链接
回复


若有收获,就点个赞吧
0 人点赞
