数据采集
数据:
- 用户行为日志log文本
- 图像、音频
- 数据源多种多样
- 数据量大,变化快
主要问题:如何保证数据质量(不丢失,不重复)?
产品:
- Chukwa:Apache,Java实现
- Scribe:Facebook,小众
- Fluentd:C、Ruby开发,对json支持好
- LogStash:(ELK) web端
- Flume:大型数据
Flume初识
Flume官方网站 Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.
- 分布式、可靠且可用的服务(可以部署到集群中任意节点进行数据采集)
- 用于高效收集、聚合、移动大量日志(数据处理方式:收集,聚合,移动)
- 基于一个数据流的简单而灵活的架构(流式架构)
- 提供了可靠性机制和许多故障转移机制、恢复机制(容错性强)
- 使用一个简单可扩展的数据模型,允许在线分析(可以整合到实时系统[结合Kafka])
Flume架构
选择什么样的技术栈
1.0之前
web系统 - 收集器:收集速度快 —-> master数据处理(内存,CPU核):处理速度慢 —> 可能存在数据丢失
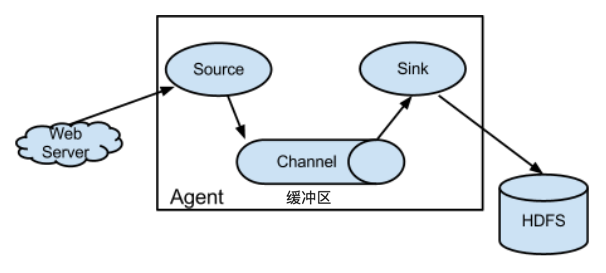
核心概念
- Flume数据流贯穿始终(传输基本单位:事件[Event: 头部信息+数据体])
- Flume采集程序:jvm进程[Agent: sources, channel, sink]
source:从数据源采集
—->channel:数据缓存
—->sink:落地磁盘;把数据传输给另一个source
- Flume以Agent为最小的独立运行单位
Agent:采集程序
Client:模拟产生数据(程序模拟使用)
官方文档学习
- Agent Flume进程
- source:能够采集的数据来源
- Avro Source:监听某个端口的数据
- Exec Source:支持shell命令
- Spooling Directory Source:监控一个文件夹的数据(批量采集)
- channel:
- 接受source传递的数据、缓存、sink
- 首选:内存;其次:磁盘(WAL: HDFS、Hbase);数据库
- sink:
- —-> hdfs()[离线] / hive / hbase / kafka()[实时]
- event:
- header
- body(key-value)

若有收获,就点个赞吧
0 人点赞
