join
- hive 不支持非等值的 join 连接
- inner join
- left join
- right join
- full join
-
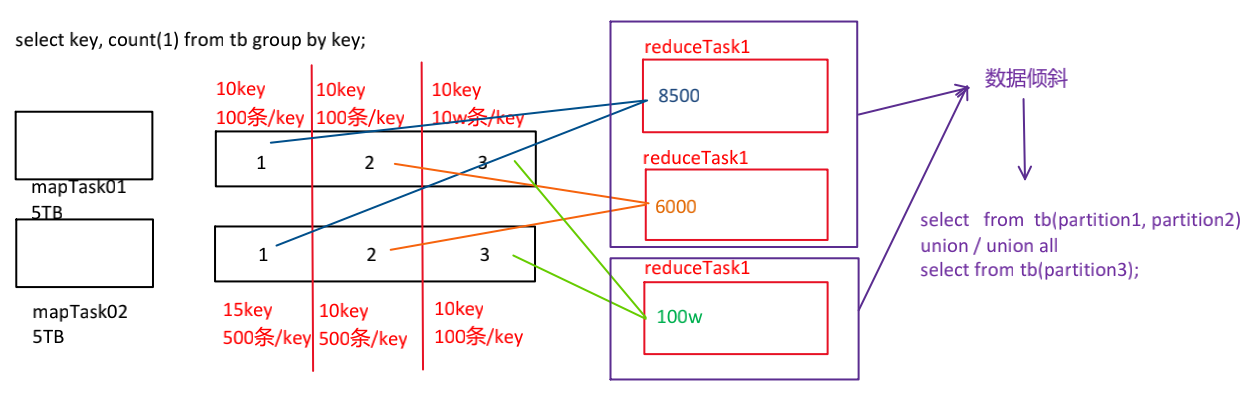
group by [having]
Reduce端执行,受限于reduce数量
selectdept , count(*) as totalcountfromstu_managedwhere age > 0group by depthaving totalcount>5 ;
distribute by
数据:dept : IS / CS / MA
操作:按照dept分区distribute by (dept) ,设置3个reduceTask,产生3个文件;
结果:IS, CS ——> 进入同一分区
MA ——> 进入同一分区
问题:一个桶文件,为什么会有两个部门的数据?
HashPartitioner
int getPartitioner(K key, V value, int numsReduceTasks) {
return (key.hashcode() & Interger[Long].MAX_VALUE)%numsReduceTasks;
// IS, CS ——> 取余相同 ——> 进入同一文件
}
}distribute by与group by对比
相同:都是按key值划分数据,都使用reduce操作
不同:distribute by只是单纯的分散数据;而group by把相同key的数据聚集到一起,后续必须是聚合操作。order by
order by后面可以有多列进行排序;
- 默认按字典排序;
- order by为全局排序;
- order by需要reduce操作,且只有一个reduce,与配置无关;
-
sort by
与distribute by结合出现,确保每个reduce的输出都是有序的。
order by与sort by 对比
order by:全局排序;
sort by:局部排序;如果只有一个reduce时,和order by作用一样
clusrer by
cluster by = distribute by sort by
总结:
分区规则和排序规则一致 且 排序规则是升序规则:cluster by
分区规则和排序规则不一致:distribute by + sort by
分区规则和排序规则一致 且 排序规则是降序规则:distribute by + sort by
建表期望:
create table stu_buk(id int , name string , sex string , age int , dept string)clustered by (dept)sorted by (age desc)into 3 bucketsrow format delimitedfields terminated by ',' ;
实际需要设置:
set mapreduce.job.reduces = 3 ;set hive.enforce.bucketing = true ;insert into stu_bukselect id, name, sex, age, deptfrom stu_managerdistribute by (dept)sort by (age desc);
union [all]
- union:去重
- union all:不去重

若有收获,就点个赞吧
0 人点赞
