范欣欣的博文
产生背景
Google发表的三驾马车论文,被誉为计算机科学进入大数据时代的标志。
- GFS 分布式文件系统【HDFS】
- MapReduce 分布式计算系统【MapReduce】
- BigTable 分布式数据库【Hbase】 — 用HDFS存储
因早期 Hadoop 开发者,只实现了 Hadoop 文件系统和 Hadoop MapReduce,并未实现 BigTable,故而 BigTable 在Hadoop 大数据生态里面,相当一段时间里,一直是缺席的.
直到 PowerSet 公司推出 Hbase 项目,才算是真正实现了 BigTable 的开源版。PowerSet 早期是一家十分著名的创业公司,创业领域为下一代搜索引擎:自然搜索引擎。虽然在2008年发布了自己的正式产品,但结果不尽人意,后期因微软踏足搜索引擎领域而被收购。但是其在开发语义搜索引擎系统过程中,需要用到类似 Googe BigTable 的系统,而研发出来的 Hbase,确对整个大数据开源社区做出了很大贡献。
整个Hbase(架构):HDFS不支持文件随机读写,Hbase还是底层文件存储基于HDFS(hdfs怎么做架构可以支持文件读写)
简介
- Hbase 是 Googe BigTable 的开源实现,是 Apace Hadoop 大数据生态系统中的重要成员。是⼀个构建在 HDFS 上的分布式**列存**储系统。从逻辑上讲,HBase 将数据按照表、⾏和列进⾏存储,它是⼀个分布式的、稀疏的、持久化存储的多维度排序表。
- HBASE是面向列存储(和列存储不是一回事!)
- 能够对海量数据进行随机的实时读写访问,它维护一个超大的表(数十亿行数百万列)。
- HBase 依赖于 HDFS 做底层的数据存储
HBase 依赖于 MapReduce 做数据计算
HBase 依赖于 ZooKeeper 做服务协调
- HBASE是nosql型的数据库(hbase, redis, mongodb)
- NoSQL = NO SQL —> 不支持SQL语句
- NoSQL = Not Only SQL —>会有一些把 NoSQL 数据的原生查询语句封装成 SQL,比如 HBase 就有 Phoenix 工具
设计特点
近实时查询
- 案例:有一个超大文件,记录的是url(1000w条记录:最大的是102.4kb),用户想做一个操作—想快速定位一个url是否存在(补充:判断可以有误差率,但误差率不要超过千分之一)
- 原:1m(1024kb)可以存储10个数据,总共需要100wMB~需要1000G内存(大约1T)
- 题
- 1)确定数据长度
- 2)每个单元格数据存储类型
- 3)确认空间使用率(暂时不考虑稀疏数组/矩阵(浪费空间))
- 解决办法:跳表(索引)— ZK / 布隆过滤器**
- 布隆过滤器(数学推导)——快速从海量数据中检索一个文件是否存在
- 需要一个数组的空间大小为1亿
- 数据量大小为1000万
- hash的个数为7个
- 冲突的概率(误判的概率):0.009*0.009=0.000081
- 存储容量
- 1kb=1000byte
- 1mb=1000kb
- 1G=1000mb=10byte(10亿个数据)
跳表(如图)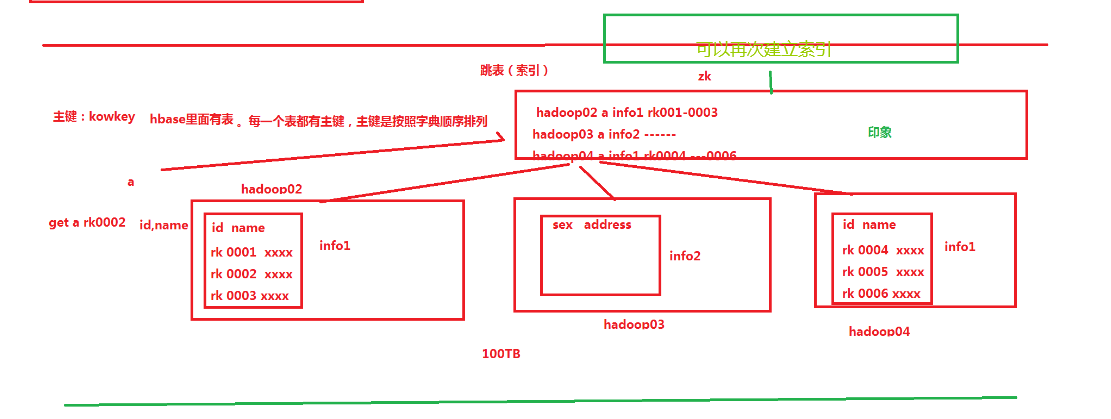
补充(Java集合的hash冲突):hash-equals 数组+链表 Java8?哈希冲突
逻辑数据模型
基本概述
Hbase 中的 namespace (命名空间)和 table,类似与数据库中的 database 和 table 逻辑概念,一个 namespace 中包含了一组 table。
Hbase 内置了两个缺省 namespace:
hbase:系统内建表,包括namespace和meta表
default:用户建表时未指定namespace的表都创建在此。
Hbase 表由一系列行构成,每行数据有一个 rowkey,以及若干 column family 构成,每个 column family 可包含无限列。
HBASE表的逻辑结构
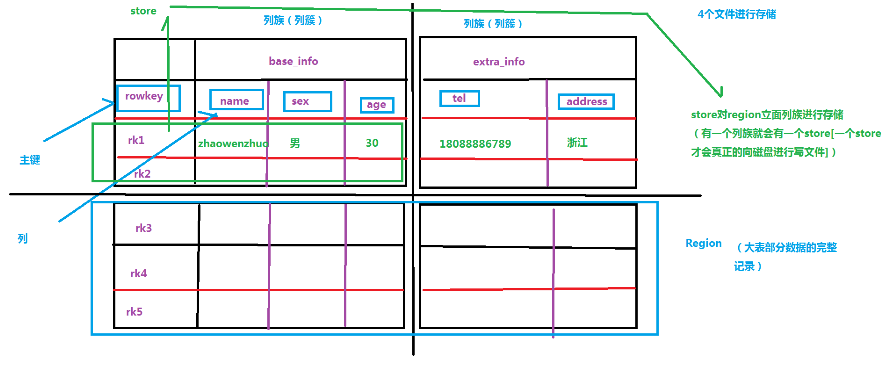
HBASE表的物理结构

名词解释
学习HBase有几个重要的名词需要我们详细说明,如下所示是一个简单的数据表:

4.1 Region#
Region的概念和关系型数据库的分区或者分片差不多。
Hbase会将一个大表的数据基于Rowkey的不同范围分配到不通的Region中,每个Region负责一定范围的数据访问和存储。这样即使是一张巨大的表,由于被切割到不通的region,访问起来的时延也很低。
数据量达到一定的时候(一般10G),表会自动进行切分—>均衡每个regionserver的压力,防止造成数据热点
4.2 Rowkey#
Rowkey又叫行键,概念和mysql中的主键是完全一样的,Hbase使用Rowkey来唯一的区分某一行的数据。
由于Hbase只支持3中查询方式:
1),基于Rowkey的单行查询
2),基于Rowkey的范围扫描
3),全表扫描
因此,Rowkey对Hbase的性能影响非常大,Rowkey的设计就显得尤为的重要。设计的时候要兼顾基于Rowkey的单行查询也要键入Rowkey的范围扫描。具体Rowkey要如何设计后续会整理相关的文章做进一步的描述。这里大家只要有一个概念就是Rowkey的设计极为重要。
4.3 Column Family#
Column Family又叫列族,Hbase通过列族划分数据的存储,列族下面可以包含任意多的列,实现灵活的数据存取。就像是家族的概念,我们知道一个家族是由于很多个的家庭组成的。列族也类似,列族是由一个一个的列组成(任意多)。
Hbase表的创建的时候就必须指定列族。就像关系型数据库创建的时候必须指定具体的列是一样的。
Hbase的列族不是越多越好,官方推荐的是列族最好小于或者等于3。我们使用的场景一般是1个列族。
列族是落地磁盘划分文件的最小单位
一般:经常查询的字段放到一个列族里,不常用的放到另外的列族
4.4 Colmn#
4.5 TimeStamp#
TimeStamp对Hbase来说至关重要,因为它是实现Hbase多版本的关键。在Hbase中使用不同的timestame来标识相同rowkey行对应的不同版本的数据。
在写入数据的时候,如果用户没有指定对应的timestamp,Hbase会自动添加一个timestamp,timestamp和服务器时间保持一致。
在Hbase中,相同rowkey的数据按照timestamp倒序排列。默认查询的是最新的版本,用户可同指定timestamp的值来读取旧版本的数据。
4.6 Cell#
单元格:某一个列对应的具体的值
由{rowkey, column( = + ), version} 唯一确定的单元。
Cell 中的数据是没有类型的,全部是字节码形式存贮
总结:如何能定位到一个单元格?
—- 表名—>列族—>列—>行键—>时间戳
HBASE特点
- HBASE介于nosql和RDBMS之间的分布式数据库、只能通过rowkey索引数据
- 缺点:不支持复杂的join、不支持复杂事物
- 能存储ALL(底层是字节数组)
- 结构化
- 半结构化
- 非结构化
- HBASE对空的列不进行存储

若有收获,就点个赞吧
0 人点赞
