MapReduce on Yarn
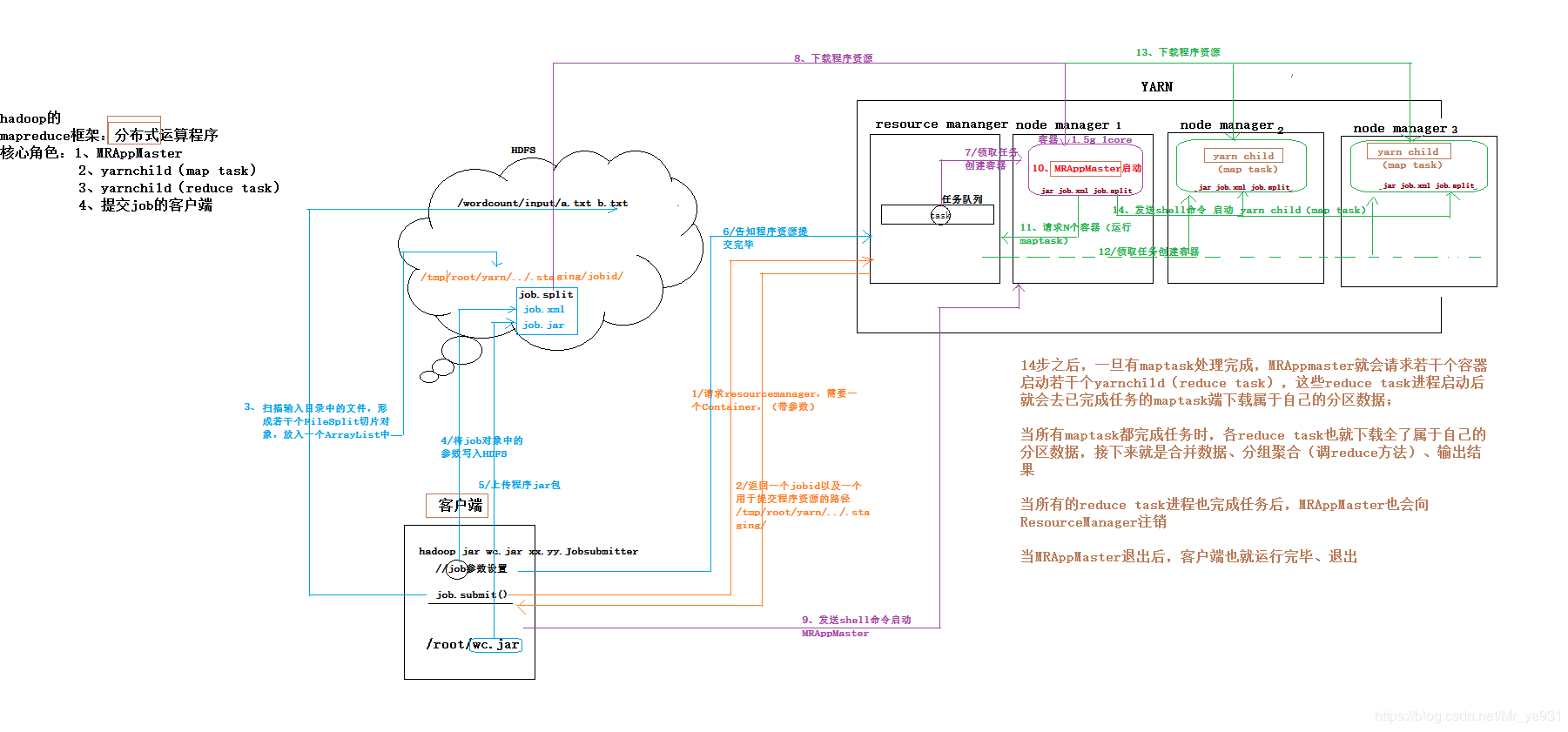
*客户端提交mr程序job的流程:
- 客户端提交job后
job.submit(),Yarn的ResourceManager会返回本次所提交的job的提交路径(hdfs://xxx../staging)和jobid,然后拼接为一个job的资源提交路径 (hdfs://…./staging/jobid) 然后会将👇拷贝到刚才拼接成的资源提交路径
客户端提交job后,通过客户端所在节点的YRANRUNNER向resource manager(之后简称rm)申请提交一个application
- rm会返回任务的资源提交路径hdfs://xxx…/..和application_id(不会立马提交)
- 客户端所在节点的YRANRUNNER提交job运行所需要的资源(job.split、job.xml、job.jar)到前面提到的拼接的资源提交路径
- 资源提交完毕后申请运行mrAppMaster,RM先挑一台node manager创建容器container(cpu+ram)运行mrAppMaster
- RM能够感知NM每台节点资源利用率;此时会找一个资源利用率比较低的节点
- rm将用户的请求封装成一个个的job,放入队列中(YARN的三种调度器,FIFO(默认)、Fair、Capacity),mrAppMaster领取到任务后先下载job资源到本地,然后根据任务描述,向rm申请运行maptask的容器,rm在分配容器给node manager来启动maptask和reducetask分发jar包
- maptask执行结束向mrapplicationmaster进行汇报
- 如果其中一台节点挂掉,mrapplicationmaster心跳机制
- 重启,重启向MR申请资源
- mrapplicationmaster知道切片规划有多少个block块,收到maptask运行成功的通知,如果这两个值一样,会去找RM要reduceask运行的资源(配置文件)
- job.setreduces类似(配置文件)默认1
- reuducetask阶段还是要和mrapplicationmaster通信,失败重启reducetask,成功的话,和配置文件对比,一致,整个程序执行结束了
最终:mrapplicationmaster找RM说整个程序运行结束,把我的资源释放掉
*注意点
程序运行时,只有mrAppMaster知道运行信息,rm和node manager都不知道,YARN只负责资源的分配。从这一点可以看出YARN和mr程序是解耦的。
- maptask执行完毕后,相应的资源会被回收,那之后启动的reduce拿到maptask生成的数据呢?maptask虽然不在了,但是有文件,它们被node manager管理,reduce可以找node manager 要,搭建环境时配过一个参数(mapreduced_shuffle)就是配合管理这些文件。
- Hadoop1.x版本中角色分为JobTracker和TaskTracker,JobTracker既要监控运算流程,又要负责资源调度,耦合度高,导致负载过大。
- RM管理整个集群资源,为什么不去自己管理整个集群的每个job两阶段运行情况?
- —-内存和CPU核都是有限的,RM只是一个进程,RM既要做资源分配,又要做程序管理,管理的东西太多了,很多有可能造成宕机
MapReduce的整体流程
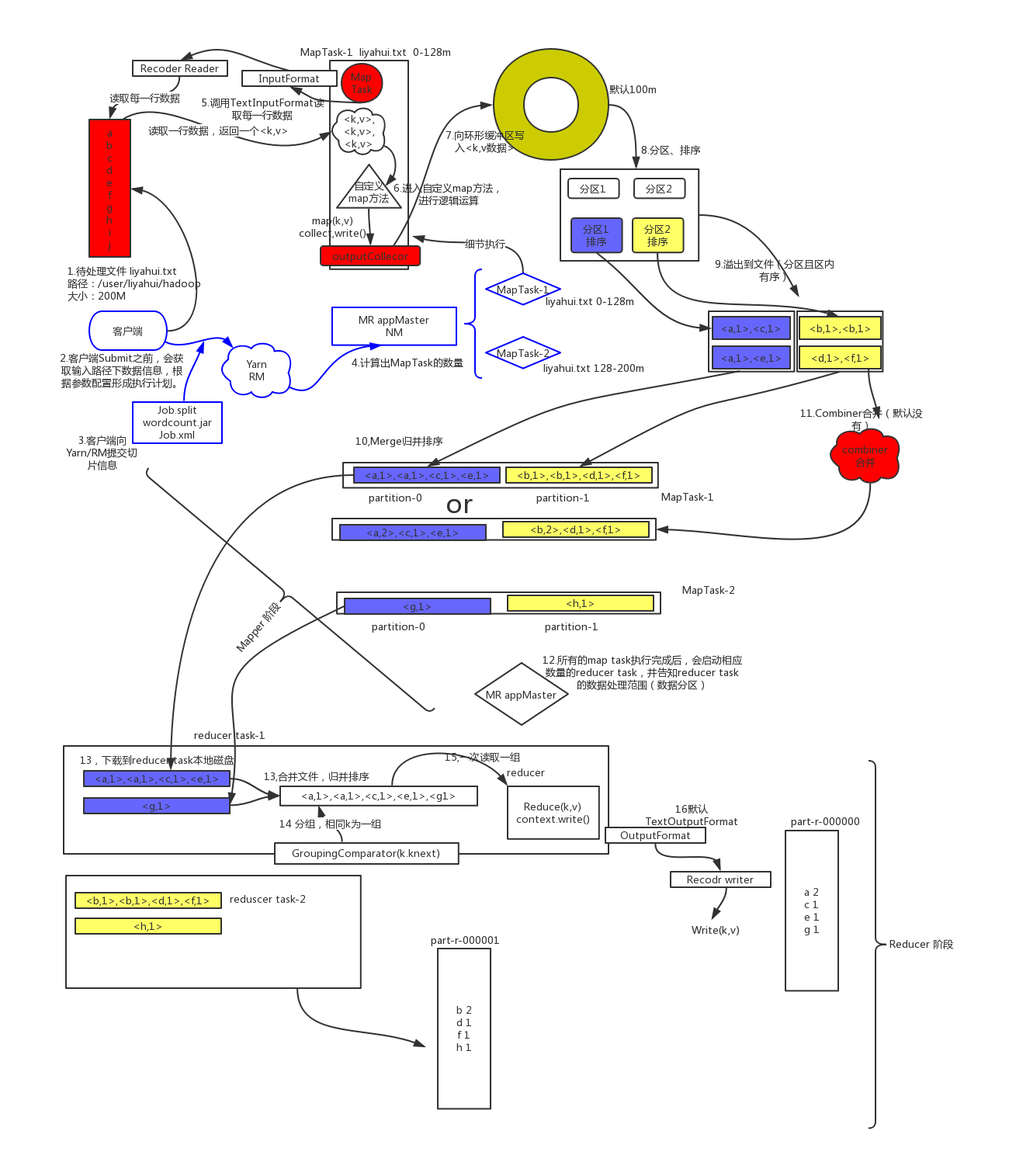
MapReduce即将一个计算任务分为两个阶段:Map、Reduce。为什么要这么分解?
*wordCount案例分析
- 为了理解其含义,我们先不管MapReduce这一套框架,从一个简单的问题来看,如果对于100T的日志文件,需要统计其中出现的”ERROR”这个单词的次数,怎么办?
- 最简单的方法:单机处理,逐行读入每一行文本,统计并累加,则得到其值。问题是:因为数据量太大,速度太慢,怎么办?自然,多机并行处理就是一个自然的选择。
- 那么,这个文件怎么切分到多个机器呢?假定有100台机器,可以写一个主程序,将这个100T大文件按照每个机器存储1T的原则,在100台机器上分布存储,再把原来单机上的程序拷贝100份(无需修改)至100台机器上运行得到结果,此时得到的结果只是一个中间结果,最后需要写一个汇总程序,将统计结果进行累加,则完成计算。
- 将大文件分解后,对单机1T文件计算的过程就相当于Map,而Map的结果就相当于”ERROR”这个单词在本机1T文件中出现的次数,而最后的汇总程序就相当于Reduce,Reduce的输入来源于100台机器。在这个简单的例子中,有100个Map任务,1个Reduce任务。
- 100台机器计算后的中间结果需要传递到Reduce任务所在机器上,这个过程就是Shuffle,Shuffle这个单词的含义是”洗牌“,也就是将中间结果从Map所在机器传输到Reduce所在机器,在这个过程中,存在网络传输。
- 此时,我们利用上面的例子已经理解了Map-Shuffle-Reduce的基本含义,在上面的例子中,如果还需要对”WARNING“这个单词进行统计,那么怎么办呢?此时,每个Map任务就不仅需要统计本机1T文件中ERROR的个数,还需要统计WARNING的次数,然后在Reduce程序中分别进行统计。如果需要对所有单词进行统计呢?一个道理,每个Map任务对1T文件中所有单词进行统计计数,然后 Reduce对所有结果进行汇总,得到所有单词在100T大文件中出现的次数。此时,问题可能出现了,因为单词数量可能很多,Reduce用单机处理也可能存在瓶颈了,于是我们需要考虑用多台机器并行计算Reduce,假如用2台机器,因为Reduce只是对单词进行计数累加,所有可以按照这样简单的规则进行:大写字母A-Z开头的单词由Reduce 1累加;小写字母a-z开头的单词由Reduce 2累加。
- 在这种情况下,100个Map任务执行后的结果,都需要分为两部分,一部分准备送到Reduce 1统计,一部分准备送到Reduce 2统计,这个功能称为Partitioner,即将Map后的结果(比如一个文本文件,记录了各个单词在本机文件出现的次数)分解为两部分(比如两个文本 文件),准备送到两个Reduce任务。
- 因此,Shuffle在这里就是从100个Map任务和2个Reduce任务之间传输中间结果的过程。
*MR典型步骤
- 如果Map后的中间结果数据量较大,Shuffle过程对网络带宽要求较高,因此需要将Map后的结果尽可能减小,这个功能当然可以在Map内自己搞 定,不过MapReduce将这个功能单独拎出来,称为Combiner,即合并,这个Combiner,指的是Map任务后中间结果的合并,相比于 Reduce的最终合并,这里相当于先进行一下局部聚合,减小中间结果,进而减小网络传输量。所以,在上面的例子中,假如Map并不计数,只是记录单词出现这个信息,输出结果是
, , …..这样一个Key-Value序列,Combiner可以进行局部汇总,将Key相同的Value进行累加,形成一个新的Key-Value序列: , ,…..,这样就大大减小了Shuffle需要的网络带宽,要知道现在数据中心一般使用千兆以太网,好些的使用万兆以太网,TCP/IP传输的效率不太高。这里Combiner汇总函数实际上可以与Reduce的汇总函数一致,只是输入数据不同。 - 来自100个Map任务后的结果分别送到两个Reduce任务处理。对于任何一个Reduce任务,输入是一堆
这样的 Key-Value序列,因为100个Map任务都有可能统计到ERROR的次数,因此这里会先进行一个归并,即将相同单词的归并到一起,形 成 - 如果要求最后的单词统计结果还要形成字典序怎么办呢?可以自己在 Reduce中进行全排序,也可以100个Map任务中分别进行局部排序,然后将结果发到Reduce任务时,再进行归并排序。这个过程 MapReduce也内建支持,因此不需要用户自己去写排序程序,这个过程在MapReduce中称为Sort。
到这里,我们理解了MapReduce中的几个典型步骤:Map、Sort、Partitioner、 Combiner、Shuffle、Merge、Reduce。MapReduce程序之所以称为MapReduce,就说明Map、Reduce这两个 步骤对于一个并行计算来说几乎是必须的,你总得先分开算吧,所以必须有Map;你总得汇总吧,所以有Reduce。当然,理论上也可以不需要 Reduce,如果Map后就得到你要的结果的话。Sort对于不需要顺序的程序里没意义(但MapReduce默认做了排序);Partitioner对于Reduce只有一个的时候没意义,如果有多个Reduce,则需要,至于怎么分,用户可以继承Partitioner标准类,自己实现分解函数。控制中间结果如何传输。MapReduce提供的标准的Partitioner是 一个接口,用户可以自己实现getPartition()函数,MapReduce也提供了几个基本的实现,最典型的HashPartitioner是根 据用户设定的Reduce任务数量(注意,MapReduce中,Map任务的个数最终取决于数据分布,Reduce则是用户直接指定),按照哈希进行计算的
一个MapReduce运行流程称为一个Job,中文称“作业”。在传统的分布式计算领域,一个Job分为多个Task运行。Task中文一般称为任务,在Hadoop中,这种任务有两种:Map和Reduce所以下面说到Map和Reduce时,指的是任务;说到整个流程时,指的是作业。
代码编写步骤
- 创建一个Job对象,Job是MapReduce中提供的一个作业类
- 设置该作业的运行类,也就是MyWordCount这个类;
- 设置Map、Combiner、Reduce三个实现类;
- 设置输出Key和Value的类,这两个类表明了MapReduce作业完毕后的结果。
- Key即单词,为一个Text对象,Text是Hadoop提供的一个可以序列化的文本类;
- Value为计数,为一个IntWritable对象,IntWritable是Hadoop提供的一个可以序列化的整数类。
- 之所以不用普通的String和int,是因为输出Key、 Value需要写入HDFS,因此Key和Value都要可写,这种可写能力在Hadoop中使用一个接口Writable表示,其实就相当于序列化,换句话说,Key、Value必须得有可序列化的能力。
- 设置了要计算的文件在HDFS中的路径,设定好这些配置和参数后,执行作业提交:
job.waitForCompletion(true)
MapReduce流程特点
- Map任务之间是不通信的,这与传统的MPI(Message Passing Interface)存在本质区别,这就要求划分后的任务具有独立性。这个要求一方面限制了MapReduce的应用场合,但另一方面对于任务执行出错后的处理十分方便,比如执行某个Map任务的机器挂掉了,可以不管其他Map任务,重新在另一台机器上执行一遍即可。因为底层的数据在HDFS里面,有3 份备份,所以数据冗余搭配上Map的重执行这一能力,可以将集群计算的容错性相比MPI而言大大增强。后续博文会对MPI进行剖析,也会对 MapReduce与传统高性能计算中的并行计算框架进行比较。
- Map任务的分配与数据的分布关系十分密切,对于上面的例子,这个100T的大文件分布在多台机器上,MapReduce框架会根据文件的实际存储位置分配Map任务,这一过程需要对HDFS有好的理解,在后续博文中会对HDFS中进行剖析。到时候,能更好滴理解MapReduce框架。因为两者是搭配起来使用的。
- MapReduce的输入数据来自于HDFS,输出结果也写到HDFS。如果一个事情很复杂,需要分成很多个MapReduce作业反复运行,那么就需要来来回回地从磁盘中搬移数据的过程,速度很慢,后续博文会对Spark这一内存计算框架进行剖析,到时候,能更好滴理解MapReduce性能。
- MapReduce的输入数据和输出结果也可以来自于HBase,HBase本身搭建于HDFS之上(理论上也可以搭建于其他文件系统),这种应用场合大多需要MapReduce处理一些海量结构化数据。后续博文会对HBase进行剖析。
- 一个MapReduce作业在Hadoop中称为Job,而JobTracker顾名思义就是对Job进行管理的节点,一个Job包含多个Map和Reduce任务,在Hadoop里Map和Reduce任务称为Task,而Job指的是Map-Reduce流程的称呼。一个Job包含多个Map Task和Reduce Task,在看作业提交代码之前,需要有一些基本的认识:
- 1、Job所需要的输入数据、资源(数据分布信息、参数配置等等)都存放于HDFS之上,其中资源信息需要Job客户端先提交至HDFS之上,这些资源信息并不传输至JobTracker,因为JobTracker本身也能随便访问HDFS,所以JobTracker是去HDFS中获得相应信息后再进行Map和Reduce Task分配;
- 2、JobClient和JobTracker可以看作CS结构,JobClient往HDFS中存入资源后,会朝JobTracker提交作业,至于到底传输给JobTracker些什么内容,实际上只是一个Job ID以及Job所在的HDFS文件目录等基本信息,需要注意的是,他们之间并不直接传递任何计算数据和资源数据,因为他们都是HDFS的客户端,都可以访问HDFS系统。
- 3、JobTracker的主要任务就是分配作业,所谓分配作业,说白了,就是将一个Job分为多个Map和Reduce任务,然后指定这些任务到底由哪些机器执行,执行任务的机器即为TaskTracker,作业到底分为多少个任务,这在传统的MPI编程中是由程序员指定的,分好任务后,任务到底在哪些机器上执行,这也是需要程序员指定的;MapReduce的不同在于,这个作业切分的过程,以及任务在哪些机器上执行的问题,是由Hadoop自己搞定的,程序员需要做的就是先将要计算的数据放到HDFS上,把Map和Reduce任务执行的(1份!)代码编写好,然后启动即可,数据到底放在了哪些机器,程序员可以不关心(查看HDFS管理信息才知道),编写的代码到底在哪些机器上(被自动拷贝多份!)执行,程序员也不关心(当然,非要去查看也是可以看到的)。
- 4、JobTracker分配好任务后,并不是直接通知TaskTracker,而是等着TaskTracker自己来取,这种设计可能是考虑MapReduce作业一般执行时间较长,比如几十分钟以上;而且JobTracker的压力不宜过大,趁着心跳时一起把任务信息获取了,否则单点容易形成瓶颈。JobTracker和TaskTracker之间存在心跳机制,可以配置,比如5秒(心跳频繁又会带来集群单点瓶颈难以扩展的问题,因为大家都跟JobTracker心跳,压力山大啊),因此,在JobClient向HDFS提交资源信息,并向JobTracker提交作业后Job进入作业队列,JobTracker从队列中取出Job并分配好Map/Reduce任务后的几秒后,TaskTracker可能才知道自己应该执行任务。这一作业启动过程时间一般都要几秒,延时较大,无法支持实时处理,这一点经常被Spark拿来鄙视,但Spark集群规模扩展后难道不存在单点瓶颈?但凡是单点分配任务的集群,不可避免都会遇到这个问题。除非分配任务的节点也可以扩展。
- 5、Map Task和Reduce Task最终运行于TaskTracker之上,TaskTracker一般是一台安装了JAVA虚拟机的Linux服务器,启动Map Task和Reduce Task时会启动JAVA虚拟机,执行Map或Reduce任务(因此Map、Reduce都是一个个JAVA进程),JAVA虚拟机启动的速度本身还是比较快,运行完毕后通知JobTracker,关闭JAVA虚拟机。一个TaskTracker可以启动很多个JAVA进程执行很多Map和Reduce任务,在YARN(Hadoop 2.0的分布式资源管理系统)中,可以指定一个Map、Reduce任务需要多少CPU核和内存,目前PC服务器一般有几十个核,和64GB以上内存,所以执行几十个Map/Reduce任务也是正常的;在YARN之前,可以配置一台服务器可以执行多少个Map/Reduce任务,但并不考虑各个Map/Reduce任务消耗资源的区别。
- 6、JobClient利用RPC机制请求JobTracker的服务,比如分配Job ID、启动作业、停止作业、查看Job进展等等。RPC机制是Hadoop里面一个很核心的部分,理解RPC机制是理解Hadoop的前提。JobTracker是MapReduce中最重要的一个类,实现了很多接口:

若有收获,就点个赞吧
0 人点赞
