hive由facebook开源的
基于hadoop的数据仓库工具
将结构化文件(HDFS)映射为一张数据库的表,并且提供HQL功能,底层数据存储在HDFS上。
Hive本质
将HQL翻译成MR,进行运行,使部署需MR的用户,可以快速进行数据分析。
问题: 不能直接基于HDFS写sql呀
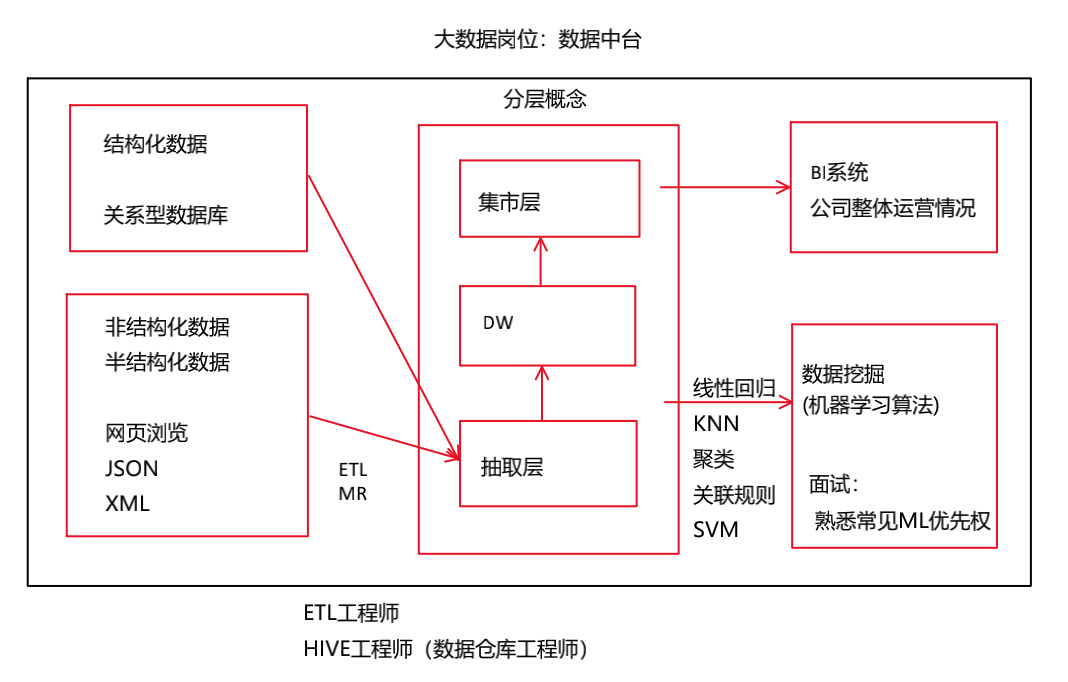
MR数据源—-HDFS (不支持)【map(),reduce()】
Hive数据源—-HDFS (hql)【给hdfs添加了字段说明】
为什么使用Hive?
- 数据分析方便
- Hive开箱即用【配置比较简单】
更好的扩展性
Hive : 自定义函数(java程序自定函数)
补充:mysql 支持自定义函数
【python - 加分项】
java自定义内置函数:局限性 —— 一个函数只能处理一个字段
大数据工作:会python
Hive - Python 整合
Python:对HDFS Block块的所有的字段进行统一处理(处理所有字段)高级特性
存储数据可以压缩,序列化机制(网络传输)
不支持记录级别的删除和修改
不支持事务
离线分析,不能做和用户交互
- 离线(工作流:Run)
延时时间才能看到结果:离线批处理
数据库数据表一定联系的,具有一定相似性
-
数据集成的
数据来源:
MySql数据库:工作人员手动录入
数据仓库:数据库中的数据 ,网页浏览(用户行为日志),nosql ;数据仓库中的数据源具有广泛性相对稳定的
数据仓库不会删除、更改数据
-
反应历史变化的
数据仓库数据随着时间流逝,对数据进行累计,一般不会进行删除
支持管理决策的

若有收获,就点个赞吧
0 人点赞
