Redis 缓冲区的存在是为了避免在数据和命令的处理速度慢于命令的发送速度时导致的数据丢失和性能问题。
面向客户端
为了避免客户端与服务端之间命令的发送和处理速度不匹配,服务端会为每个连接的客户端设置一个单独的输入、输出缓冲区。
- 收到客户端的请求后,将命令写入输入缓冲区
- Redis 主线程从输入缓冲区中读取命令并执行
- 命令执行完毕后,将结果写入输出缓冲区
- 通过输出缓冲区返回执行结果
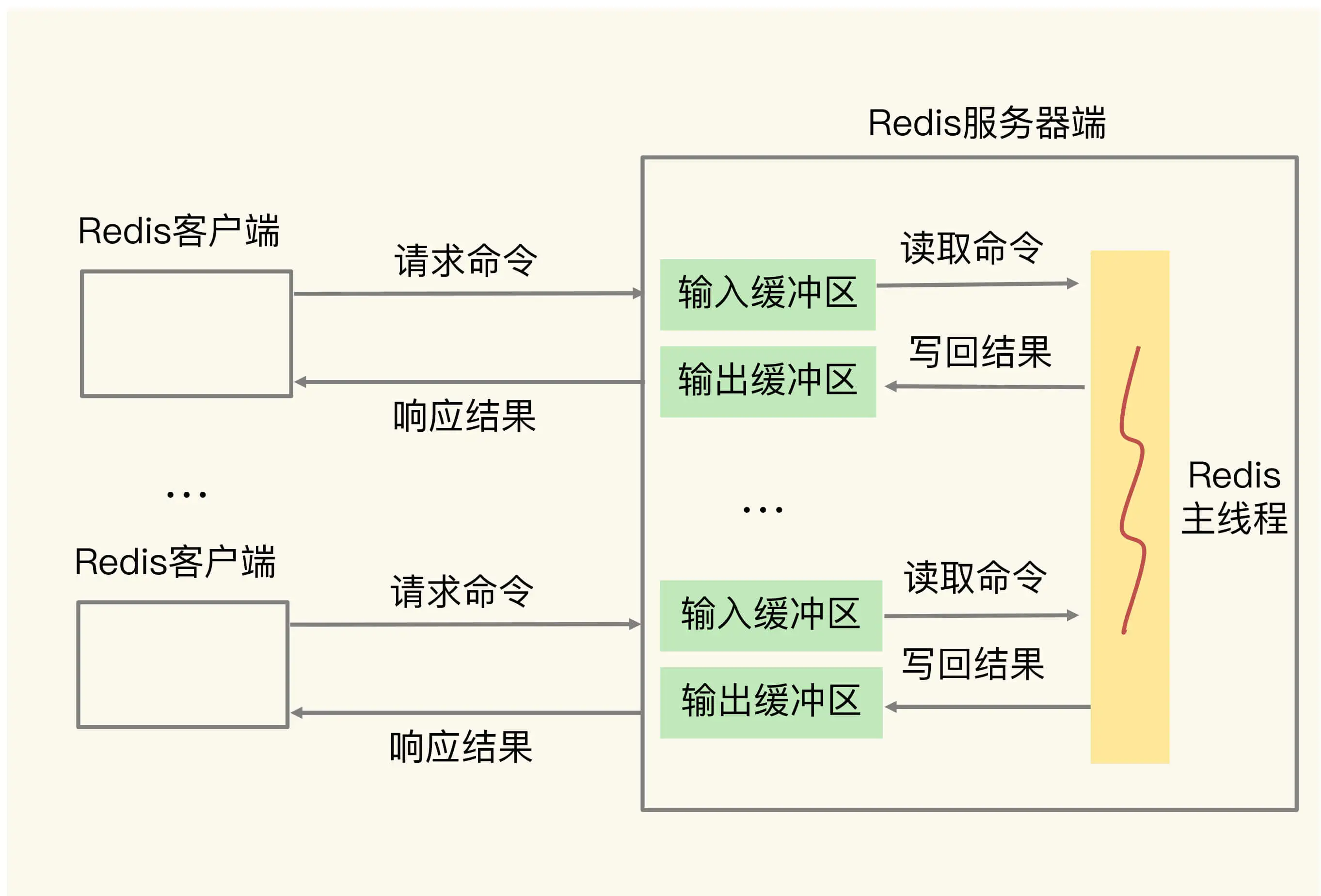
输入缓冲区
用来暂存客户端请求命令的缓冲区,硬编码最大容量为 1G。
在缓冲区溢出时服务端会断开于客户端的连接,可能导致缓冲区溢出的原因如下:
- 写入 Bigkey。如:写入百万级别的集合类型数据
- 服务端处理请求过慢时。如:主线程出现间歇性阻塞、数据库内数据过多导致在 AOF 重写或 RDB 时 fork 子线程过慢等
输出缓冲区
用来暂存服务端执行结果或服务端 pub 的消息。由 “固定缓冲空间” 和 “动态缓冲空间” 两部分组成。
- 固定缓冲空间:16kb 大小,存储 OK 响应以及错误信息。
- 动态缓冲空间:存储响应结果
动态缓冲空间大小可通过 client-output-buffer-limit 设置,如:
# 表示:普通客户端的缓冲区大小为 8mb 且在 60s 内对缓冲区写出的内容不可超过 2mbconfig set client-output-buffer-limit normal 8mb 2mb 60# 表示:订阅客户端的缓冲区大小为 8mb 且在 60s 内对缓冲区写入的内容不可超过 2mbconfig set client-output-buffer-limit pubsub 8mb 2mb 60
在缓冲区溢出时服务端会断开于客户端的连接,可能导致缓冲区溢出的原因如下:
- 返回 Bigkey 的大量结果
- 执行
MONITOR命令 - 缓冲区大小设置不合理
面向从库集群
主从间数据同步分为 “全量同步” 以及 “增量同步” 两种。为了保证主从节点的数据一致性,两种同步方式都会使用缓冲区。复制缓冲区
在 “全量同步” 的过程中,主线程会 fork 一个子线程 RDB 并将其传输给从库,RDB 和传输均由子线程完成。此时主线程依旧会执行客户端发来的命令,并在命令执行完毕后将其写入 “复制缓冲区”,待从库将 RDB 加载完毕后将其发送给从库执行。
如果从节点在接收、加载 RDB 过慢的同时,主节点又执行了大量的命令导致复制缓冲区内积压的命令越来越多,最终造成缓冲区溢出、主从连接断开、RDB 失败。
可通过client-output-buffer-limit设置缓冲区大小,如:# 表示:复制缓冲区大小为 512mb 且在 60s 内对缓冲区写出的内容不可超过 128mbconfig set client-output-buffer-limit slave 512mb 128mb 60
复制积压缓冲区
为防止从库在断网重连后造成数据丢失,主节点会维护一个环形列表结构的缓冲区,并通过主从节点各自记录的 offset 确定需同步的数据。
与其它缓冲区不同的是,由于使用的是环形结构所以不会造成溢出,而是在缓冲区写满后使用新数据覆盖旧数据。如果从节点还没有同步这些旧数据,就会造成数据丢失的问题,从而导致主从节点重新进行 “全量同步”。
缓冲区大小可使用repl-backlog-size设置缓冲区大小。

若有收获,就点个赞吧
0 人点赞
