Redis是单线程的么❓
我们通常说Redis是单线程,是指Redis的网络IO和健值对的读写是由一个线程来完成的,这也是Redis对外提供健值存储服务的主要流程。但Redis但其它功能,比如:持久化、异步删除、集群数据同步等都是由额外的线程执行的。所以严格来说,Redis并不是单线程。
为什么Redis要用单线程❓
在合理的资源分配的情况下,使用多线程可以增加系统中处理请求操作的资源实体,进而提升系统能够同时处理的请求数,即吞吐量。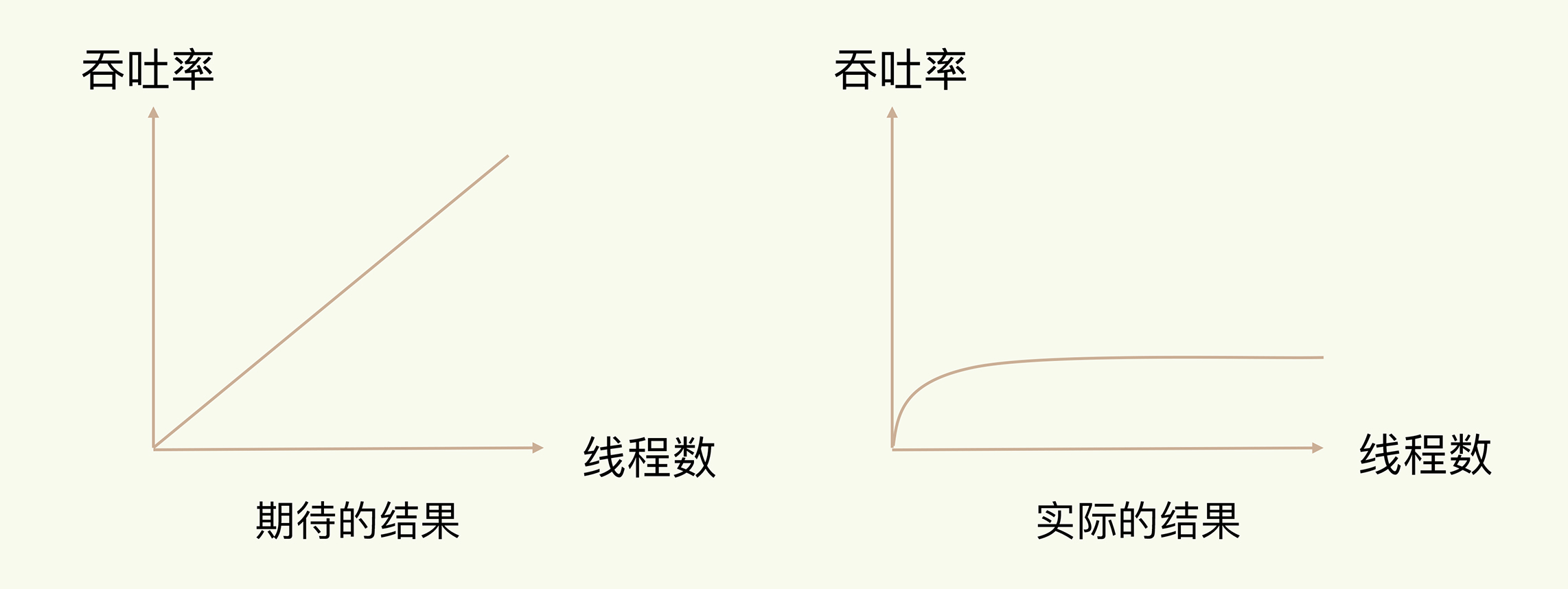
但请注意,通常情况下,在我们使用了多线程后,如果没有良好但系统设计,实际得到但结果是上图所展示的那样。刚开始增加线程数时,会增加系统但吞吐量。但再进一步增加线程时,系统吞吐量就增长迟缓了,甚至还会出现下降的情况。
为什么会出现这种情况呢?一个关键的瓶颈在于,系统中通常会存在被多线程同时访问的共享资源,比如一个共享的数据结构。当有多个线程要修改这个共享资源时,为了保证共享资源的正确性,就需要有额外的机制进行保证,而这个额外的机制,就会带来额外的开销。
并发访问控制一直是多线程开发中的一个难点问题,如果没有精细的设计,比如说,只是简单地采用一个粗粒度互斥锁,就会出现不理想的结果:即使增加了线程,大部分线程也在等待获取访问共享资源的互斥锁,并行变串行,系统吞吐率并没有随着线程的增加而增加。而且,采用多线程开发一般会引入同步原语来保护共享资源的并发访问,这也会降低系统代码的易调试性和可维护性。
为了避免这些问题,Redis 直接采用了单线程模式。
为什么单线程的Redis能那么快❓
- Redis的大部分操作实在系统内存上完成的;
- Redis采用了单线程操作,避免了频繁的上下文切换;
- Redis采用了非阻塞I/O多路复用机制,使其在网络IO操作中能并发处理大量的客户端请求,实现高吞吐率;
Redis基本IO模型中存在哪些潜在的性能瓶颈❓
- 任意一个请求在server中一旦发生耗时,都会影响整个server的性能,也就是说后面的请求都要等前面这个耗时请求处理完成,自己才能被处理到。耗时的操作包括以下几种:
- 操作bigkey:写入一个bigkey在分配内存时需要消耗更多的时间,同样,删除bigkey释放内存同样会产生耗时;
- 使用复杂度过高的命令:例如SORT/SUNION/ZUNIONSTORE,或者O(N)命令,但是N很大,例如lrange key 0 -1一次查询全量数据;
- 大量key集中过期:Redis的过期机制也是在主线程中执行的,大量key集中过期会导致处理一个请求时,耗时都在删除过期key,耗时变长;
- 淘汰策略:淘汰策略也是在主线程执行的,当内存超过Redis内存上限后,每次写入都需要淘汰一些key,也会造成耗时变长;
- AOF刷盘开启always机制:每次写入都需要把这个操作刷到磁盘,写磁盘的速度远比写内存慢,会拖慢Redis的性能;
- 主从全量同步生成RDB:虽然采用fork子进程生成数据快照,但fork这一瞬间也是会阻塞整个线程的,实例越大,阻塞时间越久;
- 并发量非常大时,单线程读写客户端IO数据存在性能瓶颈,虽然采用IO多路复用机制,但是读写客户端数据依旧是同步IO,只能单线程依次读取客户端的数据,无法利用到CPU多核。
针对问题1:一方面需要业务人员去规避,一方面Redis在4.0推出了lazy-free机制,把bigkey释放内存的耗时操作放在了异步线程中执行,降低对主线程的影响。
针对问题2:Redis在6.0推出了多线程,可以在高并发场景下利用CPU多核多线程读写客户端数据,进一步提升server性能,当然,只是针对客户端的读写是并行的,每个命令的真正操作依旧是单线程的。
Redis有哪些慢操作❓
- 操作 bigkey
- 使用复杂度过高的命令,如:SORT、SUNION、ZUNIONSTORE
- 大量 key 集中过期
- 淘汰策略
- AOF 刷盘开启 always 机制
- 主从全量同步生成 RDB
整数数组和压缩列表的查询操作在时间复杂度方面没有很大优势,为什么Redis还会把它们作为底层数据结构呢❓
- 内存利用率,数组和压缩列表都是非常紧凑的数据结构,它比链表占用的内存要更少。Redis是内存数据库,大量数据存到内存中,此时需要做尽可能的优化,提高内存的利用率。
- 数组对CPU高速缓存支持更友好,所以Redis在设计时,集合数据元素较少情况下,默认采用内存紧凑排列的方式存储,同时利用CPU高速缓存不会降低访问速度。当数据元素超过设定阈值后,避免查询时间复杂度太高,转为哈希和跳表数据结构存储,保证查询效率。
什么是缓存雪崩❓
缓存雪崩是指大部分的缓存过期时间相同,导致在同一时刻出现大面积的缓存过期,从而使原本访问缓存的请求都去访问数据库了,对数据库、CPU和内存造成巨大的压力。
解决方案:
- 缓存过期时间随机分配;
- 熔断、服务降级、限流;
什么是缓存穿透❓
缓存穿透是指用户在查询数据时,缓存和数据库中都不存在,导致每次请求都做了两次无用的查询操作。
解决方案:
- 增加布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中。如果在布隆过滤器中不存在,则改请求会被拦截掉;
- 数据库中不存在该数据时,在缓存中缓存一个空值,使下次请求直接命中缓存中的空值;
什么是缓存击穿❓
缓存击穿是指,在Redis中存在一个非常热门的key,当这个key失效的瞬间,依然存在多个访问,该访问就穿破缓存,转而直接请求数据库。
解决方案:
- 热点数据设置永不过期;
- 熔断、服务降级、限流;
什么是缓存预热❓
系统上线后,将相关的数据直接加载到缓存中。
解决方案:
- 定时刷新缓存;
- 项目启动时自动加载;
Memcache与Redis的区别
| Memcache | Redis | |
|---|---|---|
| 数据持久化 | 不支持 | 支持 |
| 数据类型 | string | string、hash、list、set、zset |
| 数据大小 | 1MB | 512MB |
| 数据备份 | 不支持 | 支持,master-slave |

若有收获,就点个赞吧
0 人点赞
