- 1 ClickHouse概述篇
- 2 ClickHouse安装篇
- 2.5 SQL语法
- 2.5.2 SELECT
- 2.5.3 FROM
- 2.5.4 Limit by
- 2.5.5 ORDER BY
- 2.5.6 JOIN
- 2.5.7 INSERT INTO
- 2.5.8 ALTER
- 2.5.9 SHOW
- 2.5.10 DROP
- 2.5.11 TRUNCATE
- 2.6 函数
- 2.6.1 普通函数
- 2.6.1.1 类型转换
- 2.6.1.2 日期函数
- 2.6.1.3 条件函数
- 2.6.1.4 数组函数
- 2.6.1.5 字符串切割
- 2.6.1.6 随机数据和随机字符串
- 2.6.1.7 JSON
- 2.6.1.8 高阶函数
- arrayMap">2.6.1.8.1 arrayMap
- arrayFilter">2.6.1.8.2 arrayFilter
- arrayFill">2.6.1.8.3 arrayFill
- arrayReverseFill">2.6.1.8.4 arrayReverseFill
- arraySplit">2.6.1.8.5 arraySplit
- arrayReverseSplit">2.6.1.8.6 arrayReverseSplit
- 2.6.1.9 行转列
- 2.6.1.10 列转行
- 2.6.2 聚合函数
- 2.6.2.1 min 聚合函数 获取一列在最小值
- 2.6.2.2 max 聚合函数 获取一列在最大值
- 2.6.2.3 sum 集合函数 求一列数据的和
- 2.6.2.4 avg 集合函数 求一列数据的平均值
- 2.6.2.5 count聚合函数 统计非null数据的行数
- 2.6.2.6 grouparray 将一列数据聚合成一个数组
- 2.6.2.7 any 返回第一个符合条件的数据
- 2.6.2.8 argMin(arg1(维度) , arg2(比较))
- 2.6.2.9 argMax
- ">2.6.2.10 avgWeighted
- 2.6.2.11 topK 返回以某个字段为维度出现频次最高的前n条记录
- 2.6.2.12 uniq和uniqExact 去重计数
- 2.6.2.13 uniqCombined 去重计数
- 2.6.2.14 * 链路函数
- 2.6.2.15 sumMap
- 2.6.2.16 minMap(Tuple)和maxMap(Tuple)
- 2.6.3 聚合函数组合
- 2.6.4 表函数
- 2.6.5 UD(A)F
- 2.6.1 普通函数
- 2.7 数据导入
- 2.8 导出数据
- 2.9 JDBC
- 2.10 可视化工具
- 3 ClickHouse原理加强篇
- 4 ClickHouse应用案例篇
1 ClickHouse概述篇
1.1 什么是ClickHouse
ClickHouse是俄罗斯的Yandex于2016年开源的一个用于联机分析(OLAP:Online Analytical Processing)的列式数据库管理系统(DBMS:Database Management System),简称CH , 主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告。
ClickHouse是一个完全的列式数据库管理系统,允许在运行时创建表和数据库,加载数据和运行查询,而无需重新配置和重新启动服务器,支持线性扩展,简单方便,高可靠性,容错。它在大数据领域没有走 Hadoop 生态,而是采用 Local attached storage 作为存储,这样整个 IO 可能就没有 Hadoop 那一套的局限。它的系统在生产环境中可以应用到比较大的规模,因为它的线性扩展能力和可靠性保障能够原生支持 shard + replication 这种解决方案。它还提供了一些 SQL 直接接口,有比较丰富的原生 client。另外就是它比较快。
选择ClickHouse 的首要原因是它比较快,但其实它的技术没有什么新的地方,为什么会快?
主要有四个方面的因素:
- 它的数据剪枝能力比较强,分区剪枝在执行层,而存储格式用局部数据表示,就可以更细粒度地做一些数据的剪枝。它的引擎在实际使用中应用了一种现在比较流行的 LSM 方式。
- 它对整个资源的垂直整合能力做得比较好,并发 MPP+ SMP 这种执行方式可以很充分地利用机器的集成资源。它的实现又做了很多性能相关的优化,它的一个简单的汇聚操作有很多不同的版本,会根据不同 Key 的组合方式有不同的实现。对于高级的计算指令,数据解压时,它也有少量使用。
- ClickHouse 是一套完全由 C++ 模板 Code 写出来的实现,代码还是比较优雅的。
- ClickHouse是一个完全的列式数据库
1.2 什么是OLAP
联机分析处理OLAP是一种软件技术,它使分析人员能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。它具有FASMI(Fast Analysis of Shared Multidimensional Information),即共享多维信息的快速分析的特征。其中F是快速性(Fast),指系统能在数秒内对用户的多数分析要求做出反应;A是可分析性(Analysis),指用户无需编程就可以定义新的专门计算,将其作为分析的一部 分,并以用户所希望的方式给出报告;M是多维性(Multi—dimensional),指提供对数据分析的多维视图和分析;是信息性(Information),指能及时获得信息,并且管理大容量信息!
- OLAP展现在用户面前的是一幅幅多维视图。维(Dimension):是人们观察数据的特定角度,是考虑问题时的一类属性,属性集合构成一个维(时间维、地理维等)。
- 维的层次(Level):人们观察数据的某个特定角度(即某个维)还可以存在细节程度不同的各个描述方面(时间维:日期、月份、季度、年)。
- 维的成员(Member):维的一个取值,是数据项在某维中位置的描述。(“某年某月某日”是在时间维上位置的描述)。
- 度量(Measure):多维数组的取值。(2000年1月,上海,笔记本电脑,0000)。
- OLAP的基本多维分析操作有钻取(Drill-up和Drill-down)、切片(Slice)和切块(Dice)、以及旋转(Pivot)等。
- 钻取:是改变维的层次,变换分析的粒度。它包括向下钻取(Drill-down)和向上钻取(Drill-up)/上卷(Roll-up)。Drill-up是在某一维上将低层次的细节数据概括到高层次的汇总数据,或者减少维数;而Drill-down则相反,它从汇总数据深入到细节数据进行观察或增加新维。
- 切片和切块:是在一部分维上选定值后,关心度量数据在剩余维上的分布。如果剩余的维只有两个,则是切片;如果有三个或以上,则是切块。
- 旋转:是变换维的方向,即在表格中重新安排维的放置(例如行列互换)。
1.3 特征
1.3.1 真正的列式数据库管理系统
在一个真正的列式数据库管理系统中,除了数据本身外不应该存在其他额外的数据。这意味着为了避免在值旁边存储它们的长度«number»,你必须支持固定长度数值类型。例如,10亿个UInt8类型的数据在未压缩的情况下大约消耗1GB左右的空间,如果不是这样的话,这将对CPU的使用产生强烈影响。即使是在未压缩的情况下,紧凑的存储数据也是非常重要的,因为解压缩的速度主要取决于未压缩数据的大小。
这是非常值得注意的,因为在一些其他系统中也可以将不同的列分别进行存储,但由于对其他场景进行的优化,使其无法有效的处理分析查询。例如: HBase,BigTable,Cassandra,HyperTable。在这些系统中,你可以得到每秒数十万的吞吐能力,但是无法得到每秒几亿行的吞吐能力。
需要说明的是,ClickHouse不单单是一个数据库, 它是一个数据库管理系统。因为它允许在运行时创建表和数据库、加载数据和运行查询,而无需重新配置或重启服务。1.3.2 数据压缩
在一些列式数据库管理系统中(例如:InfiniDB CE 和 MonetDB) 并没有使用数据压缩。但是, 若想达到比较优异的性能,数据压缩确实起到了至关重要的作用。1.3.3 数据的磁盘存储
许多的列式数据库(如 SAP HANA, Google PowerDrill)只能在内存中工作,这种方式会造成比实际更多的设备预算。ClickHouse被设计用于工作在传统磁盘上的系统,它提供每GB更低的存储成本,但如果有可以使用SSD和内存,它也会合理的利用这些资源。1.3.4 多核心并行处理
ClickHouse会使用服务器上一切可用的资源,从而以最自然的方式并行处理大型查询。1.3.5 多服务器分布式处理
上面提到的列式数据库管理系统中,几乎没有一个支持分布式的查询处理。
在ClickHouse中,数据可以保存在不同的shard上,每一个shard都由一组用于容错的replica组成,查询可以并行地在所有shard上进行处理。这些对用户来说是透明的1.3.6 支持SQL
ClickHouse支持基于SQL的声明式查询语言,该语言大部分情况下是与SQL标准兼容的。
支持的查询包括 GROUP BY,ORDER BY,IN,JOIN以及非相关子查询。
不支持窗口函数和相关子查询。1.3.7 向量引擎
为了高效的使用CPU,数据不仅仅按列存储,同时还按向量(列的一部分)进行处理,这样可以更加高效地使用CPU。1.3.8 实时的数据更新
ClickHouse支持在表中定义主键。为了使查询能够快速在主键中进行范围查找,数据总是以增量的方式有序的存储在MergeTree中。因此,数据可以持续不断地高效的写入到表中,并且写入的过程中不会存在任何加锁的行为。1.3.9 索引
按照主键对数据进行排序,这将帮助ClickHouse在几十毫秒以内完成对数据特定值或范围的查找。1.3.10 适合在线查询
在线查询意味着在没有对数据做任何预处理的情况下以极低的延迟处理查询并将结果加载到用户的页面中。1.3.11 支持近似计算
ClickHouse提供各种各样在允许牺牲数据精度的情况下对查询进行加速的方法:
- 用于近似计算的各类聚合函数,如:distinct values, medians, quantiles
- 基于数据的部分样本进行近似查询。这时,仅会从磁盘检索少部分比例的数据。
不使用全部的聚合条件,通过随机选择有限个数据聚合条件进行聚合。这在数据聚合条件满足某些分布条件下,在提供相当准确的聚合结果的同时降低了计算资源的使用。
1.3.12 支持数据复制和数据完整性
ClickHouse使用异步的多主复制技术。当数据被写入任何一个可用副本后,系统会在后台将数据分发给其他副本,以保证系统在不同副本上保持相同的数据。在大多数情况下ClickHouse能在故障后自动恢复,在一些少数的复杂情况下需要手动恢复。
1.4 性能
1.4.1 优点
1,为了高效的使用CPU,数据不仅仅按列存储,同时还按向量进行处理;
2,数据压缩空间大,减少IO;处理单查询高吞吐量每台服务器每秒最多数十亿行;
3,索引非B树结构,不需要满足最左原则;只要过滤条件在索引列中包含即可;即使在使用的数据不在索引中,由于各种并行处理机制ClickHouse全表扫描的速度也很快;
4,写入速度非常快,50-200M/s,对于大量的数据更新非常适用。1.4.2 缺点
不支持事务,不支持真正的删除/更新;
- 不支持高并发,官方建议qps为100,可以通过修改配置文件增加连接数,但是在服务器足够好的情况下;
- 不支持真正的删除/更新支持 不支持事务(期待后续版本支持)
- 不支持二级索引
- 有限的SQL支持,join实现与众不同
- 不支持窗口功能
- 元数据管理需要人工干预维护
- SQL满足日常使用80%以上的语法,join写法比较特殊;最新版已支持类似SQL的join,但性能不好;
- 尽量做1000条以上批量的写入,避免逐行insert或小批量的insert,update,delete操作,因为ClickHouse底层会不断的做异步的数据合并,会影响查询性能,这个在做实时数据写入的时候要尽量避开;
- ClickHouse快是因为采用了并行处理机制,即使一个查询,也会用服务器一半的CPU去执行,所以ClickHouse不能支持高并发的使用场景,默认单查询使用CPU核数为服务器核数的一半,安装时会自动识别服务器核数,可以通过配置文件修改该参数。
1.4.3 相关优化
1,关闭虚拟内存,物理内存和虚拟内存的数据交换,会导致查询变慢。
2,为每一个账户添加join_use_nulls配置,左表中的一条记录在右表中不存在,右表的相应字段会返回该字段相应数据类型的默认值,而不是标准SQL中的Null值。
3,JOIN操作时一定要把数据量小的表放在右边,ClickHouse中无论是Left Join 、Right Join还是Inner Join永远都是拿着右表中的每一条记录到左表中查找该记录是否存在,所以右表必须是小表。
4,批量写入数据时,必须控制每个批次的数据中涉及到的分区的数量,在写入之前最好对需要导入的数据进行排序。无序的数据或者涉及的分区太多,会导致ClickHouse无法及时对新导入的数据进行合并,从而影响查询性能。
5,尽量减少JOIN时的左右表的数据量,必要时可以提前对某张表进行聚合操作,减少数据条数。有些时候,先GROUP BY再JOIN比先JOIN再GROUP BY查询时间更短。
6,ClickHouse的分布式表性能性价比不如物理表高,建表分区字段值不宜过多,防止数据导入过程磁盘可能会被打满。
7,CPU一般在50%左右会出现查询波动,达到70%会出现大范围的查询超时,CPU是最关键的指标,要非常关注。
1.4.4 性能情况
1,单个查询吞吐量:如果数据被放置在page cache中,则一个不太复杂的查询在单个服务器上大约能够以2-10GB/s(未压缩)的速度进行处理(对于简单的查询,速度可以达到30GB/s)。如果数据没有在page cache中的话,那么速度将取决于你的磁盘系统和数据的压缩率。例如,如果一个磁盘允许以400MB/s的速度读取数据,并且数据压缩率是3,则数据的处理速度为1.2GB/s。这意味着,如果你是在提取一个10字节的列,那么它的处理速度大约是1-2亿行每秒。对于分布式处理,处理速度几乎是线性扩展的,但这受限于聚合或排序的结果不是那么大的情况下。
2,处理短查询的延时时间:数据被page cache缓存的情况下,它的延迟应该小于50毫秒(最佳情况下应该小于10毫秒)。 否则,延迟取决于数据的查找次数。延迟可以通过以下公式计算得知: 查找时间(10 ms) 查询的列的数量 查询的数据块的数量。
3,处理大量短查询:ClickHouse可以在单个服务器上每秒处理数百个查询(在最佳的情况下最多可以处理数千个)。但是由于这不适用于分析型场景。建议每秒最多查询100次。
4,数据写入性能:建议每次写入不少于1000行的批量写入,或每秒不超过一个写入请求。当使用tab-separated格式将一份数据写入到MergeTree表中时,写入速度大约为50到200MB/s。如果您写入的数据每行为1Kb,那么写入的速度为50,000到200,000行每秒。如果您的行更小,那么写入速度将更高。为了提高写入性能,您可以使用多个INSERT进行并行写入,这将带来线性的性能提升。
count: 千万级别,500毫秒,1亿 800毫秒 2亿 900毫秒 3亿 1.1秒
group: 百万级别 200毫米,千万 1秒,1亿 10秒,2亿 20秒,3亿 30秒
join:千万-10万 600 毫秒, 千万 -百万:10秒,千万-千万 150秒
ClickHouse并非无所不能,查询语句需要不断的调优,可能与查询条件有关,不同的查询条件表是左join还是右join也是很有讲究的。
其他补充:
1,MySQL单条SQL是单线程的,只能跑满一个core,ClickHouse相反,有多少CPU,吃多少资源,所以飞快;
2,ClickHouse不支持事务,不存在隔离级别。ClickHouse的定位是分析性数据库,而不是严格的关系型数据库。
3,IO方面,MySQL是行存储,ClickHouse是列存储,后者在count()这类操作天然有优势,同时,在IO方面,MySQL需要大量随机IO,ClickHouse基本是顺序IO。
有人可能觉得上面的数据导入的时候,数据肯定缓存在内存里了,这个的确,但是ClickHouse基本上是顺序IO。对IO基本没有太高要求,当然,磁盘越快,上层处理越快,但是99%的情况是,CPU先跑满了(数据库里太少见了,大多数都是IO不够用)。
1.5 应用场景
今日头条 内部用ClickHouse来做用户行为分析,内部一共几千个ClickHouse节点,单集群最大1200节点,总数据量几十PB,日增原始数据300TB左右。
腾讯内部用ClickHouse做游戏数据分析,并且为之建立了一整套监控运维体系。
携程内部从18年7月份开始接入试用,目前80%的业务都跑在ClickHouse上。每天数据增量十多亿,近百万次查询请求。
快手内部也在使用ClickHouse,存储总量大约10PB, 每天新增200TB, 90%查询小于3S。
1.绝大多数请求都是用于读访问的
2.数据需要以大批次(大于1000行)进行更新,而不是单行更新;或者根本没有更新操作
3.数据只是添加到数据库,没有必要修改
4.读取数据时,会从数据库中提取出大量的行,但只用到一小部分列
5.表很“宽”,即表中包含大量的列
6.查询频率相对较低(通常每台服务器每秒查询数百次或更少)
7.对于简单查询,允许大约50毫秒的延迟
8.列的值是比较小的数值和短字符串(例如,每个URL只有60个字节)
9.在处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行)
10.不需要事务
11.数据一致性要求较低
12.每次查询中只会查询一个大表。除了一个大表,其余都是小表
13.查询结果显著小于数据源。即数据有过滤或聚合。返回结果不超过单个服务器内存大小
1.6 基本概念
1.6.1 列式存储

相比于行式存储,列式存储在分析场景下有着许多优良的特性。
1)如前所述,分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个bloCK中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询。
2)同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
3)更高的压缩比意味着更小的data size,从磁盘中读取相应数据耗时更短。
4)自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。
5)高压缩比,意味着同等大小的内存能够存放更多数据,系统cache效果更好。
官方数据显示,通过使用列存,在某些分析场景下,能够获得100倍甚至更高的加速效应。
1.6.2 向量化(算法)
ClickHouse不仅将数据按列存储,而且按列进行计算。传统OLTP数据库通常采用按行计算,原因是事务处理中以点查为主,SQL计算量小,实现这些技术的收益不够明显。但是在分析场景下,单个SQL所涉及计算量可能极大,将每行作为一个基本单元进行处理会带来严重的性能损耗:
1)对每一行数据都要调用相应的函数,函数调用开销占比高;
2)存储层按列存储数据,在内存中也按列组织,但是计算层按行处理,无法充分利用CPU cache的预读能力,造成CPU Cache miss严重;
3)按行处理,无法利用高效的SIMD指令;
ClickHouse实现了向量执行引擎(Vectorized execution engine),对内存中的列式数据,一个batch调用一次SIMD指令(而非每一行调用一次),不仅减少了函数调用次数、降低了cache miss,而且可以充分发挥SIMD指令的并行能力,大幅缩短了计算耗时。向量执行引擎,通常能够带来数倍的性能提升。
(SIMD全称Single Instruction Multiple Data,单指令多数据流,能够复制多个操作数,并把它们打包在大型寄存器的一组指令集。以同步方式,在同一时间内执行同一条指令。)
1.6.3 表
1.6.4 分片
ClickHouse的集群由分片 ( Shard ) 组成,而每个分片又通过副本 ( Replica ) 组成。这种分层的概念,在一些流行的分布式系统中十分普遍。例如,在Elasticsearch的概念中,一个索引由分片和副本组成,副本可以看作一种特殊的分片。如果一个索引由5个分片组成,副本的基数是1,那么这个索引一共会拥有10个分片 ( 每1个分片对应1个副本 )。
如果你用同样的思路来理解ClickHouse的分片,那么很可能会在这里栽个跟头。ClickHouse的某些设计总是显得独树一帜,而集群与分片就是其中之一。这里有几个与众不同的特性。
ClickHouse的1个节点只能拥有1个分片,也就是说如果要实现1分片、1副本,则至少需要部署2个服务节点。
分片只是一个逻辑概念(类似于Hbase中的region的概念,表的范围数据),其物理承载还是由副本承担的。
1.6.5 分区
ClickHouse支持PARTITION BY子句,在建表时可以指定按照任意合法表达式进行数据分区操作,比如通过toYYYYMM()将数据按月进行分区、toMonday()将数据按照周几进行分区、对Enum类型的列直接每种取值作为一个分区等。
类似于hive中的分区表
1.6.6 副本
1.6.7 引擎
就是表的类型,不同的表有不同的特点
2 ClickHouse安装篇
2.1 单机安装
- 安装curl工具
yum install -y curl
- 添加clickhouse的yum镜像
curl -s https://packagecloud.io/install/repositories/altinity/clickhouse/script.rpm.sh | sudo bash
- 检查镜像情况
ls /etc/yum.repos.d/
[root@doit04 yum.repos.d]# yum list | grep clickhouse
clickhouse-client.x86_64 20.5.4.40-1.el7 @Altinity_clickhouse
clickhouse-common-static.x86_64 20.5.4.40-1.el7 @Altinity_clickhouse
- 安装clickhouse的服务端和客户端
yum install -y clickhouse-server clickhouse-client
- 启动服务daunt
cd /etc/clickhouse-server
service clickhouse-server start
- 启动交互式客户端
clickhouse-client
客户端支持的参数如下:
2.2 集群安装
clickhouse的集群安装就是在每台机器上安装CH的服务端以及客户端!!所以在每台机器上重复单机安装步骤!
- 修改/etc/clickhouse-server/目录下的config.xml
- 将修改好的配置文件分发到其他CH节点上
- 在/etc/下创建集群配置文件metrika.xml文件(这个文件需要创建),在CH启动的时候会加载这个配置文件以集群的形式启动CH
```xml
true doit01 9000 true doit02 9000 true doit03 9000
``
1. 将配置文件分发到其他的CH节点上,并修改红色字体为自己的主机映射名!
在每台机器上启动CH服务.以集群的形式启动 , 如果想要再以单节点的形式启动那么就删除/etc/下的<br />metrika.xml文件即可单节点的形式启动!
1. 查看CH的集群情况
**select * from system.clusters**<br />
1. **ClickHouse实践篇**
<a name="OOkxd"></a>
## 2.3 数据类型
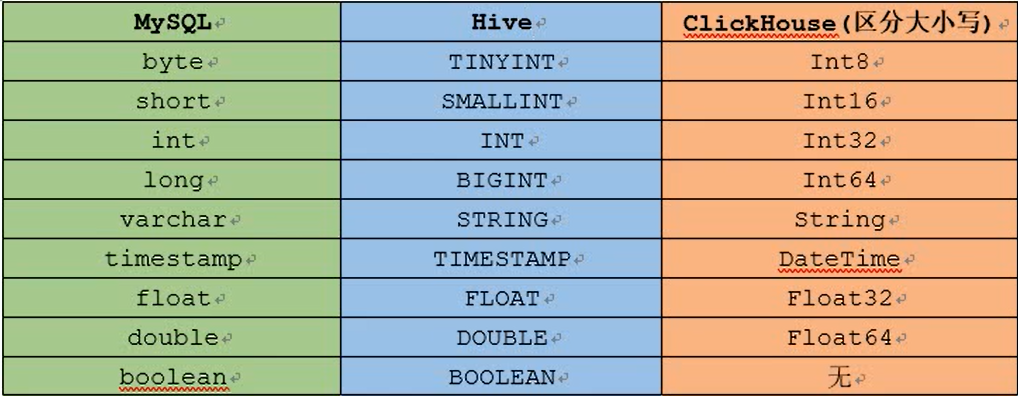
<a name="MjwI5"></a>
### 2.3.1 整型
固定长度的整型,包括有符号整型或无符号整型。<br />整型范围(-2n-1~2n-1-1):<br />Int8 - [-128 : 127]<br />Int16 - [-32768 : 32767]<br />Int32 - [-2147483648 : 2147483647]<br />Int64 - [-9223372036854775808 : 9223372036854775807]<br />无符号整型范围(0~2n-1):<br />UInt8 - [0 : 255]<br />UInt16 - [0 : 65535]<br />UInt32 - [0 : 4294967295]<br />UInt64 - [0 : 18446744073709551615]
<a name="oYGG0"></a>
### 2.3.2 浮点型
Float32 - float<br />Float64 – double<br />建议尽可能以整数形式存储数据。例如,将固定精度的数字转换为整数值,如时间用毫秒为单位表示,因为浮点型进行计算时可能引起四舍五入的误差。<br />:) select 1-0.9<br />┌───────minus(1, 0.9)─┐<br />│ 0.09999999999999998 │<br />└─────────────────────┘<br />与标准SQL相比,ClickHouse 支持以下类别的浮点数:<br />Inf-正无穷:<br />:) select 1/0<br />┌─divide(1, 0)─┐<br />│ inf │<br />└──────────────┘<br />-Inf-负无穷:<br />:) select -1/0<br />┌─divide(1, 0)─┐<br />│ -inf │<br />└──────────────┘<br />NaN-非数字:<br />:) select 0/0<br />┌─divide(0, 0)─┐<br />│ nan │<br />└──────────────┘
<a name="nausu"></a>
### 2.3.3 布尔型
没有单独的类型来存储布尔值。可以使用 UInt8 类型,取值限制为 0 或 1。
<a name="NTovv"></a>
### 2.3.4 字符串
**1)String**<br />字符串可以任意长度的。它可以包含任意的字节集,包含空字节。<br />**2)FixedString(N)**<br />固定长度 N 的字符串,N 必须是严格的正自然数。当服务端读取长度小于 N 的字符串时候,通过在字符串末尾添加空字节来达到 N 字节长度。 当服务端读取长度大于 N 的字符串时候,将返回错误消息。<br />与String相比,极少会使用FixedString,因为使用起来不是很方便。
<a name="W7OSU"></a>
### 2.3.5 枚举类型
包括 Enum8 和 Enum16 类型。Enum 保存 'string'= integer 的对应关系。<br />Enum8 用 'String'= Int8 对描述。<br />Enum16 用 'String'= Int16 对描述。<br />用法演示:<br />创建一个带有一个枚举 Enum8('hello' = 1, 'world' = 2) 类型的列:<br />CREATE TABLE t_enum<br />(<br /> x Enum8('hello' = 1, 'world' = 2)<br />)<br />ENGINE = TinyLog<br />这个 x 列只能存储类型定义中列出的值:'hello'或'world'。如果尝试保存任何其他值,ClickHouse 抛出异常。<br />:) INSERT INTO t_enum VALUES ('hello'), ('world'), ('hello')
INSERT INTO t_enum VALUES
Ok.
3 rows in set. Elapsed: 0.002 sec.
:) insert into t_enum values('a')
INSERT INTO t_enum VALUES
Exception on client:<br />Code: 49. DB::Exception: Unknown element 'a' for type Enum8('hello' = 1, 'world' = 2)<br />从表中查询数据时,ClickHouse 从 Enum 中输出字符串值。<br />SELECT * FROM t_enum
┌─x─────┐<br />│ hello │<br />│ world │<br />│ hello │<br />└───────┘<br />如果需要看到对应行的数值,则必须将 Enum 值转换为整数类型。<br />SELECT CAST(x, 'Int8') FROM t_enum
┌─CAST(x, 'Int8')─┐<br />│ 1 │<br />│ 2 │<br />│ 1 │<br />└─────────────────┘
<a name="sUh0Z"></a>
### 2.3.6 数组
**Array(T):**由 T 类型元素组成的数组。<br />T 可以是任意类型,包含数组类型。 但不推荐使用多维数组,ClickHouse 对多维数组的支持有限。例如,不能在 MergeTree 表中存储多维数组。<br />可以使用array函数来创建数组:<br />array(T)<br />也可以使用方括号:<br />[]<br />创建数组案例:<br />:) SELECT array(1, 2) AS x, toTypeName(x)
SELECT<br /> [1, 2] AS x,<br /> toTypeName(x)
┌─x─────┬─toTypeName(array(1, 2))─┐<br />│ [1,2] │ Array(UInt8) │<br />└───────┴─────────────────────────┘
1 rows in set. Elapsed: 0.002 sec.
:) SELECT [1, 2] AS x, toTypeName(x)
SELECT<br /> [1, 2] AS x,<br /> toTypeName(x)
┌─x─────┬─toTypeName([1, 2])─┐<br />│ [1,2] │ Array(UInt8) │<br />└───────┴────────────────────┘
1 rows in set. Elapsed: 0.002 sec.
<a name="tj766"></a>
### 2.3.7 元组
**Tuple(T1, T2, ...):**元组,其中每个元素都有单独的类型。<br />创建元组的示例:<br />:) SELECT tuple(1,'a') AS x, toTypeName(x)
SELECT<br /> (1, 'a') AS x,<br /> toTypeName(x)
┌─x───────┬─toTypeName(tuple(1, 'a'))─┐<br />│ (1,'a') │ Tuple(UInt8, String) │<br />└─────────┴───────────────────────────┘
1 rows in set. Elapsed: 0.021 sec.
<a name="QrLKE"></a>
### 2.3.8 Date
日期类型,用两个字节存储,表示从 1970-01-01 (无符号) 到当前的日期值。<br />还有很多数据结构,可以参考官方文档:[https://ClickHouse.yandex/docs/zh/data_types/](https://clickhouse.yandex/docs/zh/data_types/)<br />
<a name="nPRjk"></a>
### 2.3.9 函数类型
<a name="n4ERV"></a>
### 2.3.10 复杂的数据集合:Nested
**CREATE** **TABLE** test.visits<br />(<br /> CounterID UInt32,<br /> StartDate Date,<br /> Sign Int8,<br /> IsNew UInt8,<br /> VisitID UInt64,<br /> UserID UInt64,<br /> ...<br /> Goals Nested<br /> (<br /> ID UInt32,<br /> Serial UInt32,<br /> EventTime DateTime,<br /> Price Int64,<br /> OrderID String,<br /> CurrencyID UInt32<br /> ),<br /> ...<br />) ENGINE = CollapsingMergeTree(StartDate, intHash32(UserID), (CounterID, StartDate, intHash32(UserID), VisitID), 8192, Sign)<br />**SELECT**<br /> Goals.ID,<br /> Goals.EventTime<br />**FROM** test.visits<br />**WHERE** CounterID = 101500 **AND** **length**(Goals.ID) < 5<br />**LIMIT** 10
<a name="O18qP"></a>
## 2.4 表引擎
表引擎(即表的类型)决定了:
1. 数据的存储方式和位置,写到哪里以及从哪里读取数据
1. 支持哪些查询以及如何支持。
1. 并发数据访问。
1. 索引的使用(如果存在)。
1. 是否可以执行多线程请求。
1. 数据复制参数。
在读取时,引擎只需要输出所请求的列,但在某些情况下,引擎可以在响应请求时部分处理数据。对于大多数正式的任务,应该使用MergeTree族中的引擎。
<a name="ItehU"></a>
### 2.4.1 日志引擎
具有最小功能的[轻量级引擎](https://clickhouse.tech/docs/zh/engines/table-engines/log-family/)。当您需要快速写入许多小表(最多约100万行)并在以后整体读取它们时,该类型的引擎是最有效的。
<a name="N1v6u"></a>
#### 2.4.1.1 TinyLog引擎(数据不分快)
最简单的表引擎,用于将数据存储在磁盘上。每列都存储在单独的压缩文件中,写入时,数据将附加到文件末尾。<br />该引擎没有并发控制 <br /> - 只支持并发读<br />- 如果同时从表中读取和写入数据,则读取操作将抛出异常;<br />- 如果同时写入多个查询中的表,则数据将被破坏。<br />-- 建表 <br />create table tb_tinylog(id Int8 , name String , age Int8) engine=TinyLog ;<br />-- 插入数据<br />insert into tb_tinylog values(1,'马云',56),(2,'马化腾',55),(3,'马克思',123) ;<br />-- 查询数据<br />SELECT * FROM tb_tinylog<br />┌─id─┬─name───┬─age─┐<br />│ 1 │ 马云 │ 56 │<br />│ 2 │ 马化腾 │ 55 │<br />│ 3 │ 马克思 │ 123 │<br />└──┴────────┴─┘
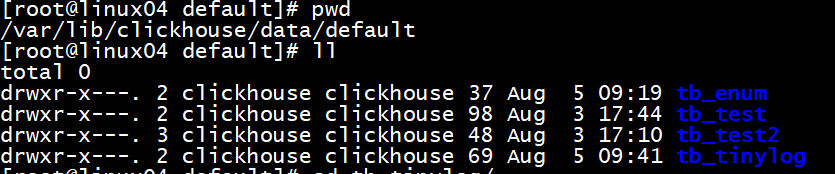<br />数据存储在机器的磁盘上,每列一个文件,插入数据向列文件的后面追加<br /><br />再插入一条数据后, 存储列数据的文件的大小增加了<br />
age.bin 和 id.bin,name.bin 是压缩过的对应的列的数据,sizes.json 中记录了每个 *.bin 文件的大小:<br />cat sizes.json <br />{"yandex":{"age%2Ebin":{"size":"56"},"id%2Ebin":{"size":"56"},"name%2Ebin":{"size":"87"}}
这种表引擎的典型用法是 write-once:首先只写入一次数据,然后根据需要多次读取。此引擎适用于相对较小的表(建议最多1,000,000行)。如果有许多小表,则使用此表引擎是适合的,因为它比需要打开的文件更少。当拥有大量小表时,可能会导致性能低下。 不支持索引。
<a name="7RPEa"></a>
#### 2.4.1.2 [StripeLog](https://clickhouse.tech/docs/zh/engines/table-engines/log-family/stripelog/#stripelog)(数据分块列在一起)
在你需要写入许多小数据量(小于一百万行)的表的场景下使用这个引擎。<br />-- 建表<br />CREATE TABLE stripe_log_table(<br /> timestamp DateTime,<br /> message_type String,<br />message String)ENGINE = StripeLog ;<br />-- 插入数据
INSERT INTO stripe_log_table VALUES (now(),'Title','多易教育') ;<br />INSERT INTO stripe_log_table VALUES (now(),'Subject','大数据'),(now(),'WARNING','学大数据到多易教育') ;
-- 写数据<br />插入一条数据<br />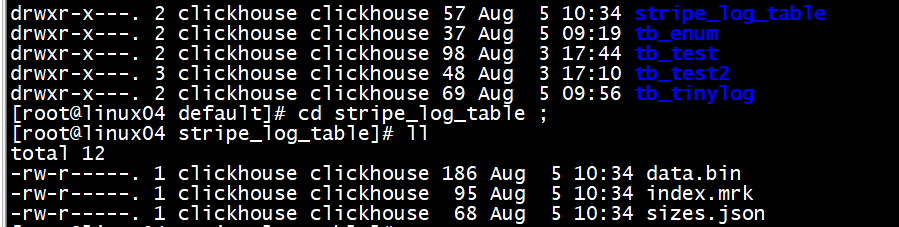
StripeLog 引擎将所有列存储在一个文件中。对每一次 Insert 请求,ClickHouse 将数据块追加在表文件的末尾,逐列写入。<br />ClickHouse 为每张表写入以下文件:<br />data.bin — 数据文件。<br />index.mrk — 带标记的文件。标记包含了已插入的每个数据块中每列的偏移量。<br />StripeLog 引擎不支持 ALTER UPDATE 和 ALTER DELETE 操作。
读数据<br />带标记的文件使得 ClickHouse 可以并行的读取数据。这意味着 SELECT 请求返回行的顺序是不可预测的。使用 ORDER BY 子句对行进行排序。<br />我们使用两次 INSERT 请求从而在 data.bin 文件中创建两个数据块。<br />ClickHouse 在查询数据时使用多线程。每个线程读取单独的数据块并在完成后独立的返回结果行。这样的结果是,大多数情况下,输出中块的顺序和输入时相应块的顺序是不同的。例如:<br />select * from stripe_log_table ;<br />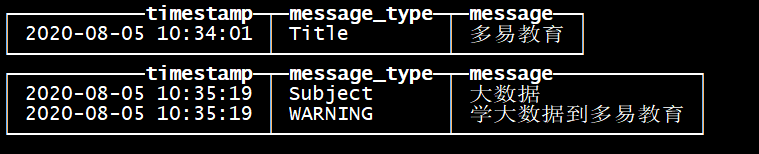
<a name="9bk1J"></a>
#### 2.4.1.3 [Log](https://clickhouse.tech/docs/zh/engines/table-engines/log-family/log/#log)(数据分块记录偏移量)
日志与 TinyLog 的不同之处在于,«标记» 的小文件与列文件存在一起。这些标记写在每个数据块上,并且包含偏移量,这些偏移量指示从哪里开始读取文件以便跳过指定的行数。这使得可以在多个线程中读取表数据。对于并发数据访问,可以同时执行读取操作,而写入操作则阻塞读取和其它写入。Log 引擎不支持索引。同样,如果写入表失败,则该表将被破坏,并且从该表读取将返回错误。Log 引擎适用于临时数据,write-once 表以及测试或演示目的。
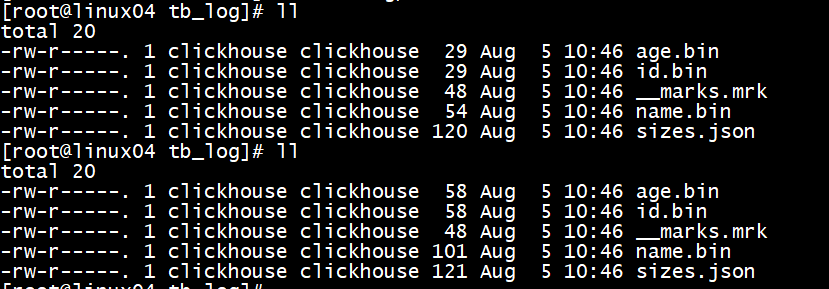
-- 建表<br />create table tb_log(id Int8 , name String , age Int8) engine=Log ;<br />--插入数据<br />insert into tb_log values(1,'马云',56),(2,'马化腾',55),(3,'马克思',123) ;<br />insert into tb_log values(4,'Hangge',26),(5,'Taoge',35),(6,'Xingge',45) ;
<a name="lBc2N"></a>
#### 2.4.1.4 总结
共同属性<br />数据存储在磁盘上。<br />写入时将数据追加在文件末尾。<br />不支持突变操作。不支持修改操作,底层管理数据块。<br />不支持索引。<br />这意味着SELECT在范围查询时效率不高。<br />非原子地写入数据。<br />如果某些事情破坏了写操作,例如服务器的异常关闭,你将会得到一张包含了损坏数据的表。
差异<br />Log 和 StripeLog 引擎支持:<br />并发访问数据的锁。<br />INSERT` 请求执行过程中表会被锁定,并且其他的读写数据的请求都会等待直到锁定被解除。如果没有写数据的请求,任意数量的读请求都可以并发执行。并行读取数据。
在读取数据时,ClickHouse 使用多线程。 每个线程处理不同的数据块。 Log 引擎为表中的每一列使用不同的文件。StripeLog 将所有的数据存储在一个文件中。因此 StripeLog 引擎在操作系统中使用更少的描述符,但是 Log 引擎提供更高的读性能。 TinyLog 引擎是该系列中最简单的引擎并且提供了最少的功能和最低的性能。TingLog 引擎不支持并行读取和并发数据访问,并将每一列存储在不同的文件中。它比其余两种支持并行读取的引擎的读取速度更慢,并且使用了和 Log 引擎同样多的描述符。你可以在简单的低负载的情景下使用它。 ### 2.4.2 MergeTree家族引擎 MergeTree系列的表引擎是ClickHouse数据存储功能的核心。它们提供了用于弹性和高性能数据检索的大多数功能:列存储,自定义分区,稀疏的主索引,辅助数据跳过索引等。
基本MergeTree表引擎可以被认为是单节点ClickHouse实例的默认表引擎,因为它在各种用例中通用且实用。
对于生产用途,ReplicatedMergeTree是必经之路,因为它为常规MergeTree引擎的所有功能增加了高可用性。一个额外的好处是在数据提取时自动进行重复数据删除,因此如果插入过程中出现网络问题,该软件可以安全地重试。
MergeTree系列的所有其他引擎为某些特定用例添加了额外的功能。通常,它是作为后台的其他数据操作实现的。
MergeTree引擎的主要缺点是它们很重。因此,典型的模式是没有太多。如果您需要许多小表(例如用于临时数据),请考虑使用Log engine family。 - 允许快速写入不断变化的对象状态。 - 删除后台中的旧对象状态。 这显着降低了存储体积。 该MergeTree系列(MergeTree)的引擎和其他引擎是最强大的ClickHouse表引擎。
该MergeTree系列中的引擎旨在将大量数据插入表中。数据快速地逐个部分地写入表中,然后应用规则在后台合并这些部分。这种方法比插入期间连续重写存储中的数据效率更高。
主要特点: - 存储按主键排序的数据。 - 支持索引 - 支持合并 这使您可以创建一个小的稀疏索引,以帮助更快地查找数据。 - 如果指定了分区键,则可以使用分区。 ClickHouse支持的某些分区操作比对相同数据,相同结果的常规操作更有效。ClickHouse还会自动切断在查询中指定了分区键的分区数据。这也提高了查询性能。 - 数据复制支持。 ReplicatedMergeTree表族提供数据复制。有关更多信息. - 数据采样支持。 如有必要,可以在表中设置数据采样方法。 1. MergeTree ##### 2.4.2.1 基本格式 CREATE TABLE [IF NOT EXISTS] [db.]table_name ON CLUSTER cluster GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(…) GRANULARITY value2) ENGINE = MergeTree()ORDER BY expr[PARTITION BY expr][PRIMARY KEY expr][SAMPLE BY expr][TTL expr [DELETE|TO DISK ‘xxx’|TO VOLUME ‘xxx’], …][SETTINGS name=value, …] ##### 2.4.2.1.1 参数解读 ENGINE—引擎的名称和参数。ENGINE = MergeTree()。该MergeTree引擎没有参数。
ORDER BY —排序键
列名称或任意表达式的元组。范例:ORDER BY (CounterID, EventDate)。
如果PRIMARY KEY子句未明确定义主键,则ClickHouse会将排序键用作主键。
ORDER BY tuple()如果不需要排序,请使用语法。
PARTITION BY— 分区键。可选的。
要按月进行分区,请使用toYYYYMM(date_column)表达式,其中的date_column是日期类型为Date的列。此处的分区名称具有”YYYYMM”格式。
PRIMARY KEY—主键(与排序键)不同。可选的。
默认情况下,主键与排序键(由ORDER BY子句指定)相同。因此,在大多数情况下,无需指定单独的PRIMARY KEY子句。
SAMPLE BY—用于采样的表达式。可选的。
如果使用采样表达式,则主键必须包含它。范例:SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID))。
TTL—规则列表,用于指定行的存储持续时间并定义磁盘和卷之间零件自动移动的逻辑。可选的。
结果必须有一个Date或一DateTime列。例:
TTL date + INTERVAL 1 DAY
规则的类型DELETE|TO DISK ‘xxx’|TO VOLUME ‘xxx’指定了在满足表达式(达到当前时间)时要对零件执行的操作:删除过期的行,将零件(如果对零件中的所有行都满足表达式)移动到指定的磁盘(TO DISK ‘xxx’)或到音量(TO VOLUME ‘xxx’)。规则的默认类型为删除(DELETE)。可以指定多个规则的列表,但最多只能有一个DELETE规则。
SETTINGS—控制MergeTree(可选)行为的其他参数: 1. index_granularity—索引标记之间的最大数据行数。默认值:8192。请参见数据存储。 1. index_granularity_bytes—数据粒度的最大大小(以字节为单位)。默认值:10Mb。要仅按行数限制颗粒大小,请设置为0(不建议)。请参阅数据存储。 1. enable_mixed_granularity_parts—启用或禁用过渡以通过index_granularity_bytes设置控制颗粒尺寸。在版本19.11之前,只有index_granularity用于限制颗粒大小的设置。index_granularity_bytes从具有大行(数十和数百MB)的表中选择数据时,此设置可提高ClickHouse性能。如果您的表具有大行,则可以为表启用此设置以提高SELECT查询效率。 1. use_minimalistic_part_header_in_zookeeper— ZooKeeper中数据部件头的存储方法。如果为use_minimalistic_part_header_in_zookeeper=1,则ZooKeeper存储的数据较少。有关更多信息,请参阅“服务器配置参数”中的设置说明。 1. min_merge_bytes_to_use_direct_io—使用对存储磁盘的直接I / O访问所需的最小合并操作数据量。合并数据部分时,ClickHouse会计算要合并的所有数据的总存储量。如果卷超过min_merge_bytes_to_use_direct_io字节,ClickHouse将使用直接I / O接口(O_DIRECT选项)读取数据并将数据写入存储磁盘。如果为min_merge_bytes_to_use_direct_io = 0,则直接I / O被禁用。默认值:10 1024 1024 1024字节。 1. merge_with_ttl_timeout—重复与TTL合并之前的最小延迟(以秒为单位)。默认值:86400(1天)。 1. write_final_mark—启用或禁用在数据部分的末尾(最后一个字节之后)写入最终索引标记。默认值:1.不要关闭它。 1. merge_max_bloCK_size—合并操作的块中的最大行数。默认值:8192 1. storage_policy—存储策略。请参阅使用多个块设备进行数据存储。 1. min_bytes_for_wide_part,min_rows_for_wide_part—可以以Wide格式存储的数据部分中的最小字节/行数。您可以设置这些设置之一,全部或全部。请参阅数据存储。 ##### 2.4.2.1.2 示例 建表
create table tb_merge_tree(
id Int8 ,
name String ,
ctime Date
)
engine=MergeTree()
order by id
partition by name ;
插入数据
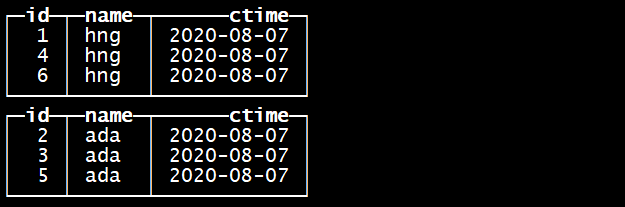
insert into tb_merge_tree values
(1,’hng’,’2020-08-07’),(4,’hng’,’2020-08-07’),(3,’ada’,’2020-08-07’),(2,’ada’,’2020-08-07’) ; 指定的分区字段是name
指定的排序字段是id

 再次插入数据
再次插入数据insert into tb_merge_tree values(5,’ada’,’2020-08-07’),(6,’hng’,’2020-08-07’) ;
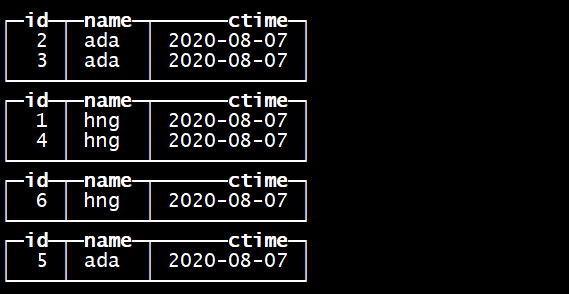

每批次的插入数据作为一个基础单元进行分区,区内数据按照指定的字段进行排序
进入到某个分区目录下
[root@linux04 8cc7880f023bd2c11f539b5088249423_1_1_0]# ll
total 48
-rw-r——-. 1 ClickHouse ClickHouse 361 Aug 5 14:43 cheCKsums.txt
-rw-r——-. 1 ClickHouse ClickHouse 74 Aug 5 14:43 columns.txt 所有的列
-rw-r——-. 1 ClickHouse ClickHouse 1 Aug 5 14:43 count.txt 记录数据的条数
-rw-r——-. 1 ClickHouse ClickHouse 30 Aug 5 14:43 ctime.bin
-rw-r——-. 1 ClickHouse ClickHouse 48 Aug 5 14:43 ctime.mrk2
-rw-r——-. 1 ClickHouse ClickHouse 28 Aug 5 14:43 id.bin
-rw-r——-. 1 ClickHouse ClickHouse 48 Aug 5 14:43 id.mrk2
-rw-r——-. 1 ClickHouse ClickHouse 8 Aug 5 14:43 minmax_name.idx
-rw-r——-. 1 ClickHouse ClickHouse 34 Aug 5 14:43 name.bin
-rw-r——-. 1 ClickHouse ClickHouse 48 Aug 5 14:43 name.mrk2
-rw-r——-. 1 ClickHouse ClickHouse 4 Aug 5 14:43 partition.dat
-rw-r——-. 1 ClickHouse ClickHouse 2 Aug 5 14:43 primary.idx - .bin是按列保存数据的文件
- .mrk保存块偏移量
- primary.idx保存主键索引 合并多次插入数据的分区
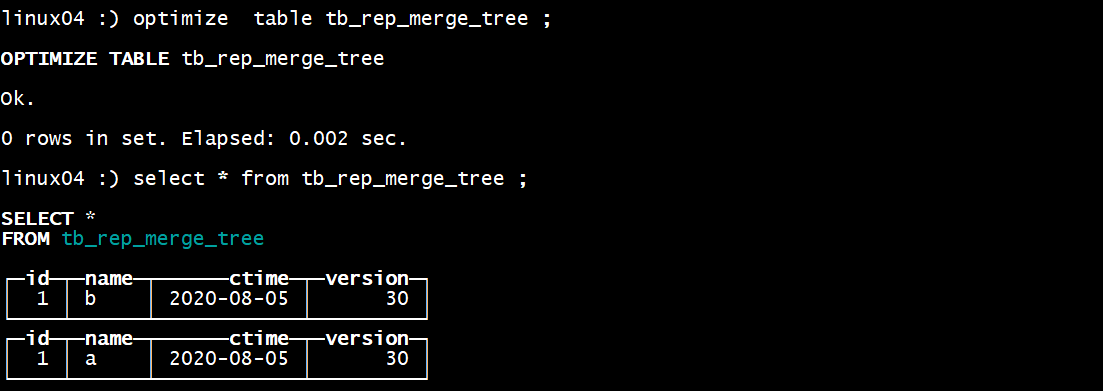
optimize table tb_merge_tree ;
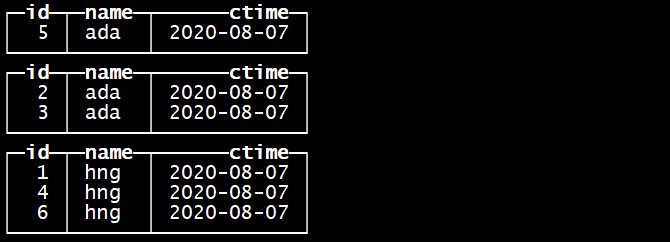
再合并一次 optimize table tb_merge_tree ;
合并完以后数据在磁盘上的存储是

[root@linux04 8cc7880f023bd2c11f539b5088249423_1_4_1]# cat count.txt
3[root@linux04 8cc7880f023bd2c11f539b5088249423_1_4_1]#
过段时间以后CK内部自动的会删除合并前的多余的文件夹
 #### 2.4.2.2 ReplacingMergeTree
这个引擎是在 MergeTree 的基础上,添加了“处理重复数据”的功能,该引擎和MergeTree的不同之处在于它会删除具有相同主键的重复项。数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进行,所以你无法预先作出计划。有一些数据可能仍未被处理。因此,ReplacingMergeTree 适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。
创建表
#### 2.4.2.2 ReplacingMergeTree
这个引擎是在 MergeTree 的基础上,添加了“处理重复数据”的功能,该引擎和MergeTree的不同之处在于它会删除具有相同主键的重复项。数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进行,所以你无法预先作出计划。有一些数据可能仍未被处理。因此,ReplacingMergeTree 适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。
创建表— 创建ReplacingMergeTree表
create table tb_rep_merge_tree(
id Int8 ,
name String ,
ctime Date ,
version UInt8
)
engine=ReplacingMergeTree(version) —- 处理重复数据,保留分区内最大的版本号 数据
order by id
partition by name
primary key id;
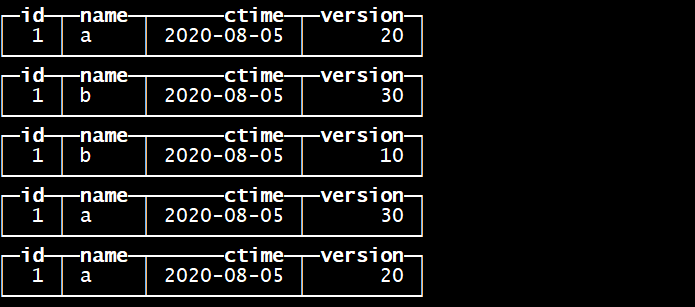
导入数据
insert into tb_rep_merge_tree values (1, ‘a’,’2020-08-05’, 20);
insert into tb_rep_merge_tree values (1, ‘b’,’2020-08-05’, 30);
insert into tb_rep_merge_tree values (1, ‘a’,’2020-08-05’, 20);
insert into tb_rep_merge_tree values (1, ‘a’,’2020-08-05’, 30);
insert into tb_rep_merge_tree values (1, ‘b’,’2020-08-05’, 10);
查询
合并 自行命令 optimize table tb_rep_merge_tree ;
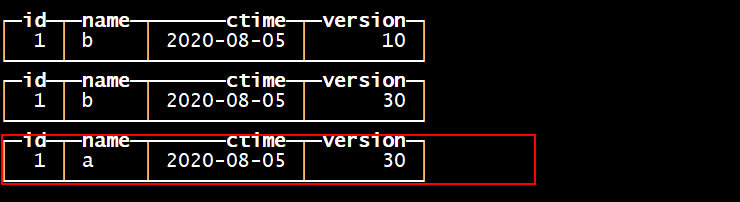
 在数据合并的时候 根据主键分区内自动的去重主键重复的数据,我们可以指定一个字段作为数据的版本,当去除重复数据的时候保留版本大的数据!
在数据合并的时候 根据主键分区内自动的去重主键重复的数据,我们可以指定一个字段作为数据的版本,当去除重复数据的时候保留版本大的数据!CH内部会自动的合并数据并去重重复数据 ,当然我们也可以手动的执行合并,但是每次处罚命令只能合并一个分区的数据,一般情况下等待他自己合并数据即可! 所以我们无法保证表中不存在重复主键数据 1. SummingMergeTree 该引擎继承自 MergeTree。区别在于,当合并 SummingMergeTree 表的数据片段时,ClickHouse 会把所有具有相同主键的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值。如果主键的组合方式使得单个键值对应于大量的行,则可以显著的减少存储空间并加快数据查询的速度,对于不可加的列,会取一个最先出现的值。 1. 建表 create table tb_summ_merge_tree(
id Int8 ,
name String ,
ctime Date ,
cost UInt8
)
engine=SummingMergeTree(cost)
order by id
partition by name
primary key id; 1. 导入数据 insert into tb_summ_merge_tree values (1, ‘a’,’2020-08-05’, 20);
insert into tb_summ_merge_tree values (1, ‘b’,’2020-08-05’, 30);
insert into tb_summ_merge_tree values (1, ‘a’,’2020-08-05’, 20);
insert into tb_summ_merge_tree values (1, ‘a’,’2020-08-05’, 30);
insert into tb_summ_merge_tree values (1, ‘b’,’2020-08-05’, 10); 1. 查看数据
 1. 合并
1. 合并
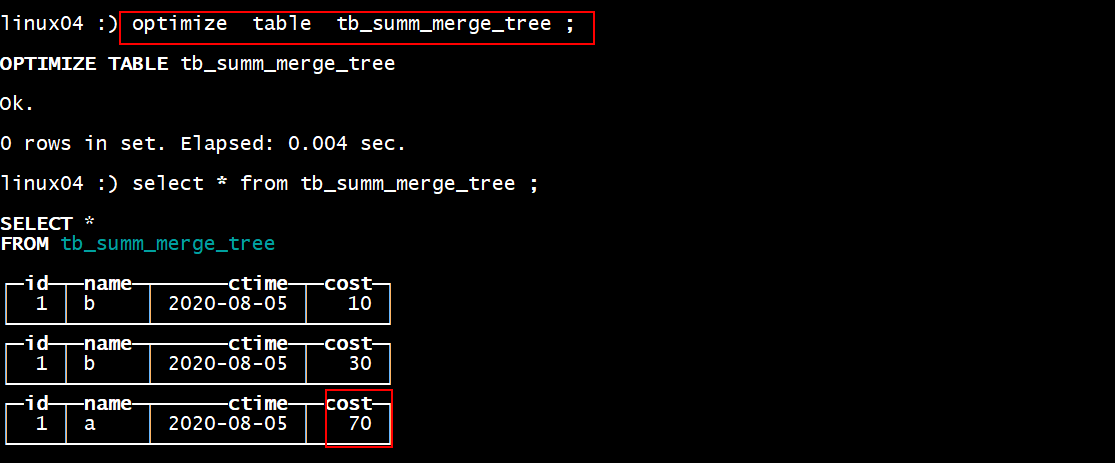
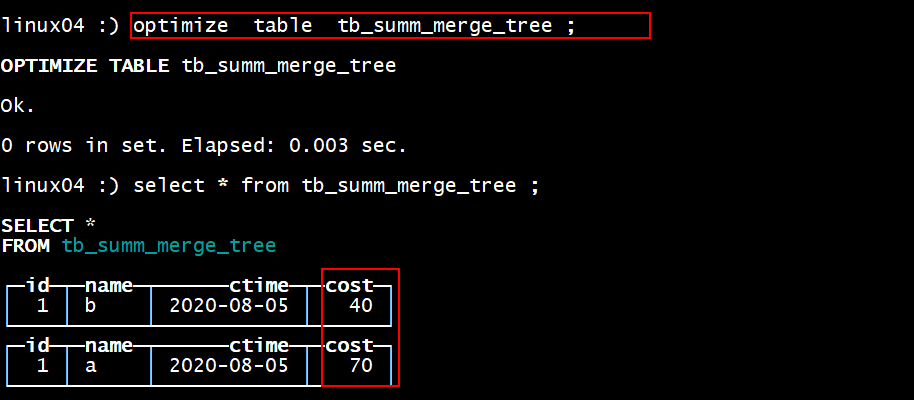 1. CollapsingMergeTree
ClickHouse实现了CollapsingMergeTree来消除ReplacingMergeTree的限制(只删除小版本字段的问题)。该引擎要求在建表语句中指定一个标记列Sign,后台Compaction时会将主键相同、Sign相反的行进行折叠,也即删除。
1. CollapsingMergeTree
ClickHouse实现了CollapsingMergeTree来消除ReplacingMergeTree的限制(只删除小版本字段的问题)。该引擎要求在建表语句中指定一个标记列Sign,后台Compaction时会将主键相同、Sign相反的行进行折叠,也即删除。CollapsingMergeTree将行按照Sign的值分为两类:Sign=1的行称之为状态行,Sign=-1的行称之为取消行。
每次需要新增状态时,写入一行状态行;需要删除状态时,则写入一行取消行。
在后台Compaction时,状态行与取消行会自动做折叠(删除)处理。而尚未进行Compaction的数据,状态行与取消行同时存在。
因此为了能够达到主键折叠(删除)的目的,需要业务层进行适当改造:
1) 执行删除操作需要写入取消行,而取消行中需要包含与原始状态行一样的数据(Sign列除外)。所以在应用层需要记录原始状态行的值,或者在执行删除操作前先查询数据库获取原始状态行;
2)由于后台Compaction时机无法预测,在发起查询时,状态行和取消行可能尚未被折叠;另外,ClickHouse无法保证primary key相同的行落在同一个节点上,不在同一节点上的数据无法折叠。因此在进行count()、sum(col)等聚合计算时,可能会存在数据冗余的情况。为了获得正确结果,业务层需要改写SQL,将count()、sum(col)分别改写为sum(Sign)、sum(col Sign)。
CollapsingMergeTree虽然解决了主键相同的数据即时删除的问题 - 示例 — 创建CollapsingMergeTree表
CREATE TABLE tb_cps_merge_tree
(
user_id UInt64,
name String,
age UInt8,
sign Int8
)
ENGINE = CollapsingMergeTree(sign)
ORDER BY user_id;
— 插入状态行,注意sign一列的值为1
INSERT INTO tb_cps_merge_tree VALUES (1001,’ADA’, 18, 1);
— 插入一行取消行,用于抵消上述状态行。注意sign一列的值为-1,其余值与状态行一致;并且插入一行主键相同的新状态行
INSERT INTO tb_cps_merge_tree VALUES (1001, ‘ADA’, 18, -1), (1001, ‘MADA’, 19, 1);
— 查询数据
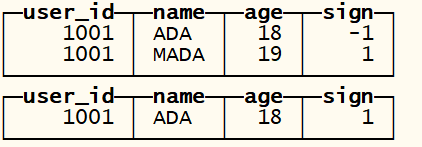
— 聚合正确的没有被剔除的数据,过滤掉被剔除的数据
SELECT
user_id,
sum(age sign) AS s_age
FROM tb_cps_merge_tree
GROUP BY user_id
HAVING sum(sign) > 0;
— 合并表查看数据
 数据最终在磁盘上存储
数据最终在磁盘上存储
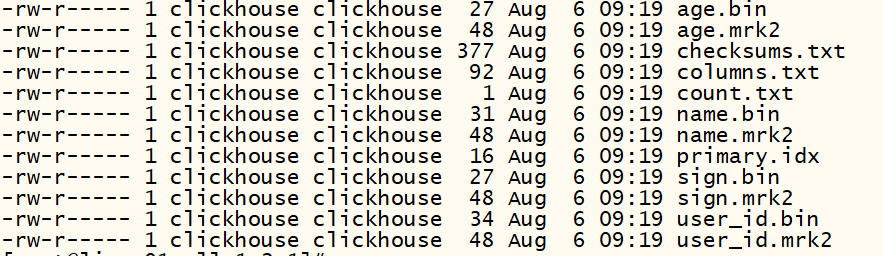
注意:
CollapsingMergeTree虽然解决了主键相同的数据即时删除的问题,但是状态持续变化且多线程并行写入情况下,状态行与取消行位置可能乱序,导致无法正常折叠。只有保证老的状态行在在取消行的上面, 新的状态行在取消行的下面! 但是多线程无法保证写的顺序! 时序错乱演示
— 建表
CREATE TABLE UAct_order
(
UserID UInt64,
PageViews UInt8,
Duration UInt8,
Sign Int8
)
ENGINE = CollapsingMergeTree(Sign)
ORDER BY UserID; — 先插入取消行
INSERT INTO UAct_order VALUES (4324182021466249495, 5, 146, -1);
— 后插入状态行
INSERT INTO UAct_order VALUES (4324182021466249495, 5, 146, 1); — 强制Compaction
optimize table UAct_order final; — 可以看到即便Compaction之后也无法进行主键折叠: 2行数据仍旧都存在。
select from UAct_order;
 1. VersionedCollapsingMergeTree
取消字段和数据版本同事使用,避免取消行数据无法删除的问题
1. VersionedCollapsingMergeTree
取消字段和数据版本同事使用,避免取消行数据无法删除的问题为了解决CollapsingMergeTree乱序写入情况下无法正常折叠问题,VersionedCollapsingMergeTree表引擎在建表语句中新增了一列Version,用于在乱序情况下记录状态行与取消行的对应关系。主键相同,且Version相同、Sign相反的行,在Compaction时会被删除。
与CollapsingMergeTree类似, 为了获得正确结果,业务层需要改写SQL,将count()、sum(col)分别改写为sum(Sign)、sum(col Sign)。
乱序插入示例。
— 建表
CREATE TABLE tb_vscmt
(
uid UInt64,
name String,
age UInt8,
sign Int8,
version UInt8
)
ENGINE = VersionedCollapsingMergeTree(sign, version)
ORDER BY uid; — 先插入一行取消行,注意Signz=-1, Version=1
INSERT INTO tb_vscmt VALUES (1001, ‘ADA’, 18, -1, 1);
— 后插入一行状态行
INSERT INTO tb_vscmt VALUES (1001, ‘ADA’, 18, 1, 1),(101, ‘DAD’, 19, 1, 2);(101, ‘DAD’, 11, 1, 3); — 数据版本
INSERT INTO tb_vscmt VALUES(101, ‘DAD’, 11, 1, 3) ;
查询没有合并前的数据
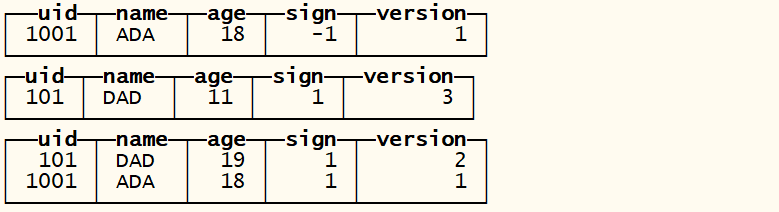
合并数据 , 查询合并后的数据 optimize table tb_vscmt ;
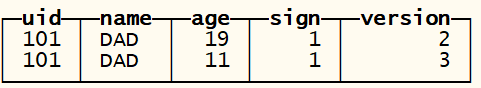
执行聚合操作 因为取消的数据被删除了 所以聚合操作两种得到的结果都正确的!
select
uid ,
sum(age sign) as sum_age
from
tb_vscmt
group by uid
having sign > 0 ; select
uid ,
sum(age)
from
tb_vscmt
group by uid ;
数据存储
 1. AggregatingMergeTree
AggregatingMergeTree也是预先聚合引擎的一种,用于提升聚合计算的性能。与SummingMergeTree的区别在于:SummingMergeTree对非主键列进行sum聚合,而AggregatingMergeTree则可以指定各种聚合函数。
1. AggregatingMergeTree
AggregatingMergeTree也是预先聚合引擎的一种,用于提升聚合计算的性能。与SummingMergeTree的区别在于:SummingMergeTree对非主键列进行sum聚合,而AggregatingMergeTree则可以指定各种聚合函数。AggregatingMergeTree的语法比较复杂,需要结合物化视图或ClickHouse的特殊数据类型AggregateFunction一起使用。在insert和select时,也有独特的写法和要求:写入时需要使用-State语法,查询时使用-Merge语法。
AggregateFunction(arg1 , arg2) ;
参数一 聚合函数
参数二 数据类型
先创建原始表 —-插入数据—-> 创建预先聚合表 —通过Insert的方式导入数据, 数据会按照指定的聚合函数聚合预先数据! 1. 配合聚合函数使用 — 建立明细表
CREATE TABLE detail_table
(id UInt8,
ctime Date,
uid UInt64
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(ctime)
ORDER BY (id, ctime); — 插入明细数据
INSERT INTO detail_table VALUES(1, ‘2020-08-06’, 1);
INSERT INTO detail_table VALUES(1, ‘2020-08-06’, 2);
INSERT INTO detail_table VALUES(2, ‘2020-08-07’, 1);
INSERT INTO detail_table VALUES(2, ‘2020-08-07’, 2); — 建立预先聚合表,
— 注意:其中UserID一列的类型为:AggregateFunction(uniq, UInt64)
CREATE TABLE agg_table
(id UInt8,
ctime Date,
uid AggregateFunction(uniq, UInt64) — 在这个字段上进行聚合操作
) ENGINE = AggregatingMergeTree()
PARTITION BY toYYYYMM(ctime)
ORDER BY (id, ctime);
— 从明细表中读取数据,插入聚合表。
— 注意:子查询中使用的聚合函数为 uniqState, 对应于写入语法
INSERT INTO agg_table
select id, ctime, uniqState(uid)
from detail_table
group by id, ctime ; — 不能使用普通insert语句向AggregatingMergeTree中插入数据。
— 本SQL会报错:Cannot convert UInt64 to AggregateFunction(uniq, UInt64)
INSERT INTO agg_table VALUES(1, ‘2020-08-06’, 1); — 从聚合表中查询。
— 注意:select中使用的聚合函数为uniqMerge,对应于查询语法
SELECT
id, ctime ,
uniqMerge(uid) AS state
FROM agg_table
GROUP BY id, ctime; 1. 使用物化视图 — 建立明细表
CREATE TABLE visits
(
UserID UInt64,
CounterID UInt8,
StartDate Date,
Sign Int8
)
ENGINE = CollapsingMergeTree(Sign)
ORDER BY UserID; — 对明细表建立物化视图,该物化视图对明细表进行预先聚合
— 注意:预先聚合使用的函数分别为: sumState, uniqState。对应于写入语法
CREATE MATERIALIZED VIEW visits_agg_view
ENGINE = AggregatingMergeTree()
PARTITION BY toYYYYMM(StartDate)
ORDER BY (CounterID, StartDate)
AS SELECT
CounterID,
StartDate,
sumState(Sign) AS Visits,
uniqState(UserID) AS Users
FROM visits
GROUP BY CounterID, StartDate; — 插入明细数据
INSERT INTO visits VALUES(0, 0, ‘2019-11-11’, 1);
INSERT INTO visits VALUES(1, 1, ‘2019-11-12’, 1); — 对物化视图进行最终的聚合操作
— 注意:使用的聚合函数为 sumMerge, uniqMerge。对应于查询语法
SELECT
StartDate,
sumMerge(Visits) AS Visits,
uniqMerge(Users) AS Users
FROM visits_agg_view
GROUP BY StartDate
ORDER BY StartDate; — 普通函数 sum, uniq不再可以使用
— 如下SQL会报错: Illegal type AggregateFunction(sum, Int8) of argument
SELECT
StartDate,
sum(Visits),
uniq(Users)
FROM visits_agg_view
GROUP BY StartDate
ORDER BY StartDate; #### 2.4.2.3 GraphiteMergeTree 该引擎用来对 Graphite数据进行瘦身及汇总,能减少存储空间,同时能提高Graphite数据的查询效率。
CREATE TABLE [IF NOT EXISTS] [db.]table_name ON CLUSTER cluster
ENGINE = GraphiteMergeTree(config_section)
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
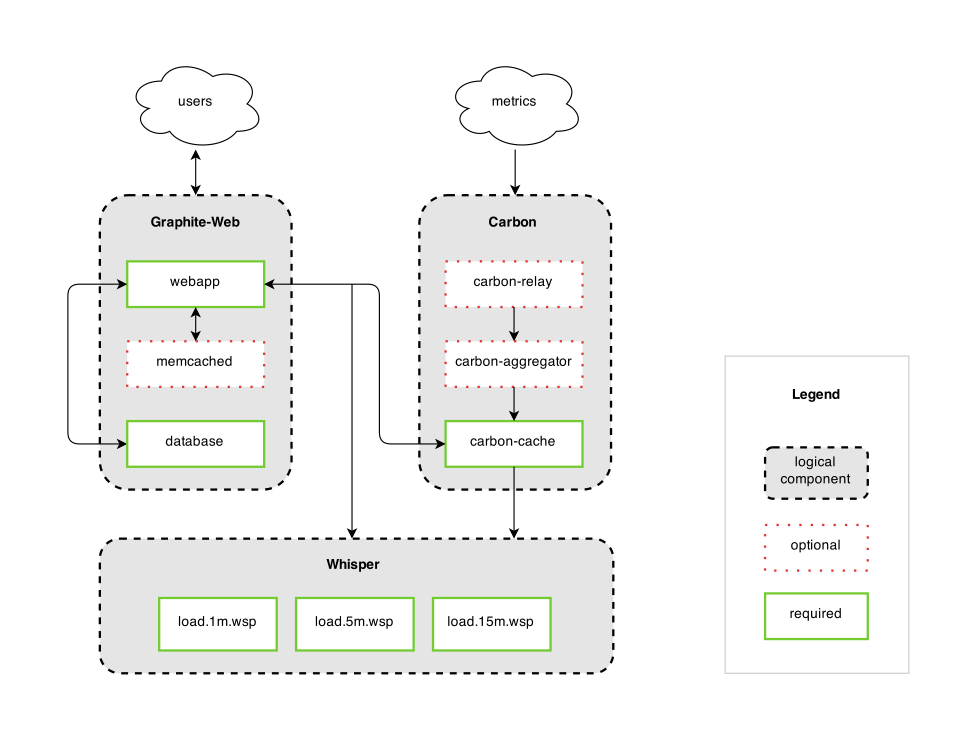
[SETTINGS name=value, …] Graphite是一个开源实时的、显示时间序列度量数据的图形系统。Graphite并不收集度量数据本身,而是像一个数据库,通过其后端接收度量数据,然后以实时方式查询、转换、组合这些度量数据。Graphite支持内建的Web界面,它允许用户浏览度量数据和图。 Graphite有三个主要组件组成:
1)Graphite-Web
这是一个基于Django的Web应用,可以呈现图形和仪表板
2)Carbon
这是一个度量处理守护进程
3)Whisper
这是一个基于时序数据库的库
Graphite的整体架构图
一、Graphite的应用场景
Graphite通常用于监控基础设施级别的度量,比如CPU、内存、I/O利用率、网络吞吐量和延迟,当然Graphite在应用程序级的度量和业务级的度量方面也很不错。
Collectd是一个著名的、持续很久的Linux项目,它用于收集基础设施级的度量,在2012年被Graphite打包到项目中,作为Graphite的“写插件”。Collectd自带了很多采集插件,可以捕获从CPU到电池利用率方面度量数据,还可以度量Java和Redis方面。
通常度量不会直接发送给Graphite的后端,而是发送一次一个度量或采样给度量采集服务。StatsD是另一个开源项目,是一个著名的度量采集服务。它可以聚合接收到的采样数据,做计算统计,求平均值、标准差和其他一些统计,周期性地刷新数据到度量数据库。Graphite是StatsD的默认后端。
出于可视化的目的,内建Web界面是目前主流的选择。创建光滑的仪表板并不难,Grafana首先从Graphite获取信息,而且还可以与其它几个流行的度量数据库协同工作,比如InfluxDB、OpenTSDB和Premetheus。
当度量数据超过了预期的边界时,Graphite自身并不提供提醒功能。这方面有几个方案可以解决此问题。Cabot就是一个流行的选择,还可以使用另一个选择StackState,它提供了同样的功能。Cabot和StackState之间提醒功能的不同之处在于StackState集成了多个监控解决方案,它可以运行检查,不仅检查Graphite数据,而且检查各种以组合的监控数据。
二、Graphite的优点
1)Graphite非常快,它的架构是模块化可规模化的
2)Graphite很著名,有庞大的社区和广泛的支持
3)有很多与Graphite相互协作的开源工具
4)Graphite完成单个工作且做得很好
5)Graphite采用Apache 2.0许可证
三、Graphite的不足
1)Graphite不能对数据进行分片,因此要解决这个问题就是采用多个Graphite实例
2)Graphite的安装是一个很复杂的任务,尽管目前有了完整的Docker映像可以一次性安装Graphite及其依赖 ### 2.4.3 其他引擎 #### 2.4.3.1 分布式引擎 分布式引擎,是CH本身不存储数据, 但可以在多个服务器上进行分布式查询。 读是自动并行的。读取时,远程服务器表的索引(如果有的话)会被使用。
Distributed(cluster_name, database, table [, sharding_key])
参数解析: - cluster_name - 服务器配置文件中的集群名,在/etc/metrika.xml中配置的 - database – 数据库名 - table – 表名 - sharding_key – 数据分片键 相关配置
- 集群模式启动CH
保证在每台机器的/etc/目录下有配置文件 metrika.xml
- 在每台CH中创建一个普通的表
create table tb_distribute(id UInt16, name String) ENGINE=TinyLog;
- 分表向表中插入数据
第一台机器
insert into tb_distribute values (1, ‘ADA’);
insert into tb_distribute values (2, ‘HANG’);
第二台机器
insert into tb_distribute values (11, ‘ADA’);
insert into tb_distribute values (22, ‘HANG’);
第三台机器
insert into tb_distribute values (111, ‘ADA’);
insert into tb_distribute values (222, ‘HANG’);
- 创建分布式表
create table dis_table(id UInt16, name String) ENGINE=Distributed(perftest_3shards_1replicas, default, tb_distribute, id);
- 查询分布式表中的数据
select * from dis_table
- 向分布式表中插入数据
insert into dis_table values (101, ‘HANG’);
insert into dis_table values (3, ‘HANG’);

2.4.3.2 Memory引擎
内存引擎,数据以未压缩的原始形式直接保存在内存当中,服务器重启数据就会消失。读写操作不会相互阻塞,不支持索引。简单查询下有非常非常高的性能表现(超过10G/s)。
一般用到它的地方不多,除了用来测试,就是在需要非常高的性能,同时数据量又不太大(上限大概 1 亿行)的场景。
— 创建一个Memory引擎的表
create table tb_memory(id Int8 , name String) engine = Memory ;
— 插入数据
insert into tb_memory values (1,’zss’),(2,’lss’),(3,’peiqi’) ;
— 存储数据的文件夹中没有对应的表文件夹
— 查看数据 select * from tb_memory ;
— 重启机器
重启以后 表还在,但是数据已经不存在, 数据并没有持久化到磁盘 , 数据丢失
2.4.3.3 缓存引擎
缓冲数据以写入内存,并定期将其刷新到另一个表。在读取操作期间,同时从缓冲区和另一个表读取数据。
Buffer(database, table, num_layers, min_time, max_time, min_rows, max_rows, min_bytes, max_bytes)
引擎参数:
database- 数据库名称。可以使用返回字符串的常量表达式来代替数据库名称。
table –将数据刷新到的表。
num_layers–并行层。在物理上,该表将表示为num_layers独立的缓冲区。建议值:16。
min_time,max_time,min_rows,max_rows,min_bytes,和max_bytes-条件从缓冲区刷新数据。
如果满足所有min条件或至少一个max条件,则从缓冲区刷新数据并将其写入目标表。
min_time,max_time–从第一次写入缓冲区起的时间(以秒为单位)。
min_rows,max_rows–缓冲区中的行数条件。
min_bytes,max_bytes–缓冲区中字节数的条件。
在写操作期间,数据被插入到num_layers许多随机缓冲区中。或者,如果要插入的数据部分足够大(大于max_rows或max_bytes),则将其直接写入目标表,而忽略缓冲区。
对于每个num_layers缓冲区,分别计算刷新数据的条件。例如,如果num_layers = 16和max_bytes = 100000000,则最大RAM消耗为1.6 GB。
例:
CREATE TABLE merge.hits_buffer AS merge.hits ENGINE = Buffer(merge, hits, 16, 10, 100, 10000, 1000000, 10000000, 100000000)
创建一个具有与’merge.hits’相同结构的’merge.hits_buffer’表,并使用Buffer引擎。写入此表时,数据会缓冲在RAM中,然后再写入“ merge.hits”表。创建了16个缓冲区。如果经过了100秒,或者已写入一百万行,或者已写入100 MB数据,则将刷新其中每个数据;或者同时经过10秒并写入10,000行和10 MB数据。例如,如果只写了一行,则无论如何,在100秒后它将被刷新。但是,如果已写入许多行,则将更快地刷新数据。
当服务器停止时,使用DROP TABLE或DETACH TABLE,缓冲区数据也将刷新到目标表。
您可以在数据库名称和表名称的单引号中设置空字符串。这表明没有目标表。在这种情况下,当达到数据刷新条件时,只需清除缓冲区。这对于将数据窗口保留在内存中可能很有用。
从缓冲区表读取数据时,将从缓冲区和目标表(如果有的话)中处理数据。
请注意
- 缓冲区表不支持索引。换句话说,缓冲区中的数据已被完全扫描,这对于大型缓冲区而言可能很慢。(对于下级表中的数据,将使用其支持的索引。)
- 如果“缓冲区”表中的列集与从属表中的列集不匹配,则插入两个表中都存在的列子集。
- 如果类型与缓冲区表和从属表中的任一列都不匹配,则会在服务器日志中输入错误消息,并清除缓冲区。
如果刷新缓冲区时从属表不存在,也会发生相同的情况。 - 如果需要对下级表和Buffer表运行ALTER,建议先删除Buffer表,对下级表运行ALTER,然后再次创建Buffer表。
- 如果服务器异常重启,缓冲区中的数据将会丢失。
- FINAL和SAMPLE对于缓冲区表不能正常工作。这些条件将传递到目标表,但不用于处理缓冲区中的数据。如果需要这些功能,建议从目标表读取时仅使用缓冲区表进行写入。
- 将数据添加到缓冲区时,缓冲区之一被锁定。如果同时从表执行读取操作,则会导致延迟。
- 插入到缓冲区表中的数据可能以不同的顺序和不同的块最终出现在从属表中。因此,很难使用Buffer表正确地写入CollapsingMergeTree。为了避免出现问题,可以将“ num_layers”设置为1。
- 如果目标表被复制,则写入缓冲区表时,复制表的某些预期特性会丢失。数据部分的行顺序和大小的随机变化会导致重复数据删除退出工作,这意味着不可能对复制表进行可靠的“仅一次”写入。
- 由于这些缺点,我们仅建议在极少数情况下使用Buffer表。
- 当在一个单位时间内从大量服务器接收到太多INSERT且无法在插入之前对数据进行缓冲的情况下,将使用Buffer表,这意味着INSERT不能足够快地运行。
- 注意,即使一次插入缓冲区表也没有意义。这样只会产生每秒几千行的速度,而插入更大的数据块则每秒会产生一百万行以上的速度(请参阅“性能”一节)。
- 创建一个目标表
create table tb_user(uid Int8 , name String) engine=TinyLog ;
- 创建一个缓存表
CREATE TABLE tb_user_buffer AS tb_user ENGINE = Buffer(merge, hits, 16, 10, 100, 10000, 1000000, 10000000, 100000000) ;
- 向缓存表中插入数据
insert into tb_user_buffer2 values(1,’Yang’),(2,’Haha’) ,(3,’ADA’) ;
- 等待以后查看目标表中的数据
select * from tb_user ;
2.4.3.4 文件引擎
File表引擎以特殊的文件格式(TabSeparated,Native等)将数据保存在文件中。
用法示例: File(Format)
- 数据从ClickHouse导出到文件。
- 将数据从一种格式转换为另一种格式。
- 通过编辑磁盘上的文件来更新ClickHouse中的数据。
支持的格式如下
https://ClickHouse.tech/docs/v20.3/en/interfaces/formats/#formats
2.4.3.4.1 示例一
- 建表
create table tb_file_demo1(uid UInt16 , name String) engine=File(TabSeparated) ;
- 在指定的目录下创建数据文件
/var/lib/ClickHouse/data/default/tb_file_demo1
[root@linux01 tb_file_demo1]# vi data.TabSeparated 注意这个文件的名字不能变化
1001 TaoGe
1002 XingGe
1003 HANGGE
- 查询数据

2.4.3.4.2 示例2
- 建表
create table tb_file_demo2(uid UInt16 , name String) engine=File(CSV) ;
- 指定目录下编辑数据文件
vi data.CSV 注意后缀是大写
101,TaoGe
102,XingGe
103,HANGGE
- 查看表数据

2.4.3.4.3 local语法
在ClickHouse-local中,文件引擎除了还接受文件路径Format。默认输入/输出流可使用数字或人类可读的名称等来指定0或stdin,1或stdout。
echo -e “1,2\n3,4” | ClickHouse-local -q “CREATE TABLE tb_local1 (a Int64, b Int64) ENGINE = File(CSV, stdin);select * from tb_local1;”
cat ./data.CSV | ClickHouse-local -q “CREATE TABLE tb_local2 (id Int64, name String) ENGINE = File(CSV, stdin); select * from tb_local2 ;”
2.4.3.4.4 client用法
在CH中建表
create table tb_client (id UInt16 , name String) engine=TinyLog ;
将数据导入到CH表中
cat data.CSV | ClickHouse-client —query=”INSERT INTO tb_client FORMAT CSV”;

2.4.3.5 Merge
但可用于同时从任意多个其他的表中读取数据。 读是自动并行的,不支持写入。读取时,那些被真正读取到数据的表的索引(如果有的话)会被使用。
Merge 引擎的参数:一个数据库名和一个用于匹配表名的正则表达式。
create table tt1 (id UInt16, name String) ENGINE=TinyLog;
create table tt2 (id UInt16, name String) ENGINE=TinyLog;
create table tt3 (id UInt16, name String) ENGINE=TinyLog;
insert into tt1(id, name) values (1, ‘Taoge’);
insert into tt2(id, name) values (2, ‘Xingge’);
insert into tt3(id, name) values (3, ‘Hangge’);
create table t (id UInt16, name String) ENGINE=Merge(currentDatabase(), ‘^tt’);
2.4.4 集成引擎
2.5 SQL语法
1. **创建数据库**
1. **本地引擎**
默认的引擎, 默认操作本地或者是指定集群的数据
Clickhouse-client –m 支持多行sql的语句
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster] [ENGINE = engine(…)]
1. **mysql引擎**
MySQL引擎用于将远程的MySQL服务器中的表映射到ClickHouse中,并允许您对表进行INSERT和SELECT查询,以方便您在ClickHouse与MySQL之间进行数据交换。
MySQL数据库引擎会将对其的查询转换为MySQL语法并发送到MySQL服务器中,因此您可以执行诸如SHOW TABLES或SHOW CREATE TABLE之类的操作。
支持的数据类型如下
- 创建一个数据库
CREATE DATABASE IF NOT EXISTS ch_to_mysql
ENGINE = MySQL(‘linux01:3306’, db_doit_ch, ‘root’, ‘root’)
- 查看系统中的所有的数据库

- 切换数据库
use ch_to_mysql ;
- 展示所有的表 发现和mysql中的表一致

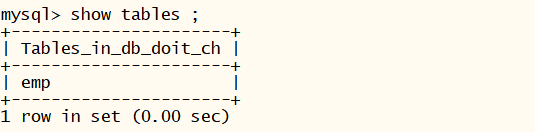
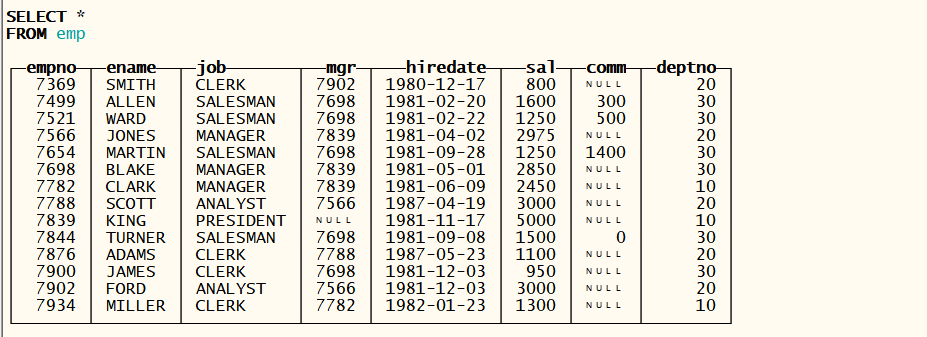
- 查看表数据
插入数据
INSERT INTO emp VALUES (8888,’HANG’,’LEADER’,NULL,’2018-01-23’,9300,NULL,10);
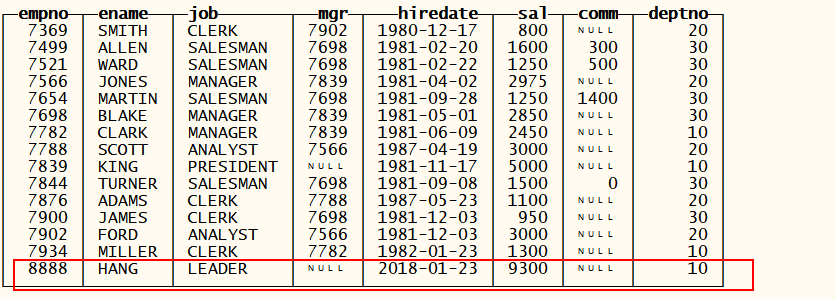
发现mysql中的数据也发生了变化 , 只支持查询和插入操作1. **lazy引擎**
和*.log类型的表配合使用, 向将表数据加载到内存中,当间隔一定的时间以后再将数据持久化!对大量的小表操作做了优化!
1. **创建表**
数据存储:/var/lib/clickhouse
建一个新表。根据使用情况,此查询可以具有各种语法形式。
默认情况下,仅在当前服务器上创建表。分布式DDL查询作为ON CLUSTER子句实现 CREATE TABLE [IF NOT EXISTS] [db.]table_name ON CLUSTER cluster ENGINE = engine
CREATE TABLE [IF NOT EXISTS] [db.]table_name ON CLUSTER cluster ENGINE = engine
2.5.1 基本语法建表
create table if not exists tb_user(
uid UInt64,
name String,
age UInt8,
sal Float64,
gender String
)engine=TinyLog;
insert into tb_user(1,’hangge’,18,’1990-01-05’,1000);
表的引擎决定存储的方式:
create table if not exists tb_stripeLog(
uid UInt64,
name String,
age UInt8,
sal Float64,
gender String
)engine=StripeLog;
insert into tb_stripeLog values(1001,’zss’,23,1000,’M’),(1002,’ls’,21,2000,’F’);
2.5.1.1 as其他表结构
create table tb_demo2 as tb_demo1 ;
可以不指定表的引擎 , 新建表的引擎和原来表的引擎一致
2.5.1.2 as查询数据结构
create table if not exists tb_demo3 engine=TinyLog as select id , name ,age from tb_demo1 ;
注意,一定要指定表的引擎 , 否则会报错
2.5.1.3 表函数
numbers()
create table tb_demo4 as numbers(3) ;

2.5.1.4 列属性
2.5.1.4.1 默认值
create table tb_t1(
id Int8 ,
name String,
role String default ‘vip’)
engine=TinyLog ;
insert into tb_t1(id , name) values(1,’hangge’) ;
insert into tb_t1(id , name) values(2,’ada’) ;
insert into tb_t1(id , name) values(3,’jack’) ;
2.5.1.4.2 TTL
定义值的存储时间。只能为MergeTree系列表指定。确定值的生存期。
当列中的值过期时,ClickHouse会将其替换为列数据类型的默认值。如果数据部分中的所有列值均已过期,则ClickHouse将从文件系统中的数据部分删除此列。
TTL可以为整个表和每个单独的列设置该子句。表级TTL也可以指定在磁盘和卷之间自动移动数据的逻辑
- 表
CREATE TABLE tb_ttl2
(
ctime DateTime,
name String
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(ctime)
ORDER BY ctime
TTL ctime + INTERVAL 15 SECOND; — 设置表过期时间为15秒
insert into tb_ttl2 values(now() ,’hangge’) ;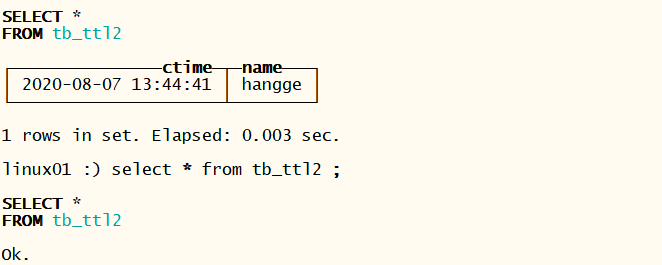
- 列
CREATE TABLE tb_ttl
(
d DateTime,
a Int TTL d + INTERVAL 1 MONTH,
b Int TTL d + INTERVAL 1 MONTH,
c Int TTL d + INTERVAL 10 SECOND,
e String
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d;
insert into tb_ttl values(now() , 100,100,88,’hangge’) ;
10秒以后查询数据,TTL过期的数据被替换成了默认值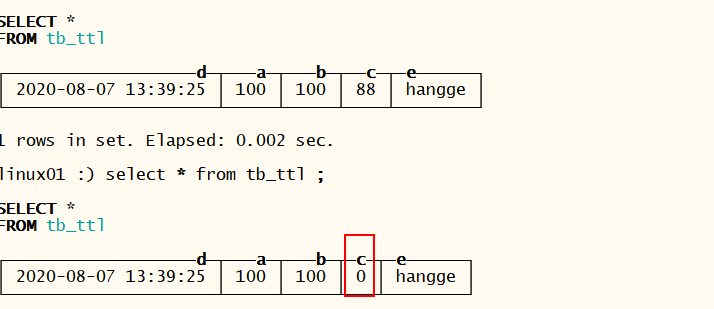
ALTER TABLE example_table
MODIFY COLUMN
c String TTL d + INTERVAL 1 MONTH;
2.5.1.5 临时表
ClickHouse支持具有以下特征的临时表:
- 会话结束时,包括连接断开,临时表都会消失。
- 临时表仅使用内存引擎。
- 无法为临时表指定数据库。它是在数据库外部创建的。
- 无法在所有群集服务器上通过分布式DDL查询创建临时表(通过使用ON CLUSTER):该表仅存在于当前会话中。
- 如果一个临时表与另一个表具有相同的名称,并且查询指定表名而不指定DB,则将使用该临时表。
- 对于分布式查询处理,查询中使用的临时表将传递到远程服务器。
 CREATE TEMPORARY TABLE [IF NOT EXISTS] table_name(
CREATE TEMPORARY TABLE [IF NOT EXISTS] table_name(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
…)
在大多数情况下,临时表不是手动创建的,而是在使用外部数据进行查询或分布式时创建的(GLOBAL) IN。
可以使用ENGINE = Memory的表代替临时表。
2.5.2 SELECT
SELECT 查询执行数据检索。 默认情况下,请求的数据返回给客户端,同时与 INSERT INTO 它可以被转发到不同的表。
语法格式:
[WITH expr_list|(subquery)]SELECT [DISTINCT] expr_list[FROM [db.]table | (subquery) | table_function] [FINAL][SAMPLE sample_coeff][ARRAY JOIN …][GLOBAL] [ANY|ALL|ASOF] [INNER|LEFT|RIGHT|FULL|CROSS] [OUTER|SEMI|ANTI] JOIN (subquery)|table (ON
- 示例1
— 建表
create table tb_stu(sid UInt16 , name String , gender String , age UInt8) engine=TinyLog;
— 导入数据
insert into tb_stu values(101,’ZSS’,’M’,23),(102,’lSS’,’M’,22),(103,’WW’,’F’,21) ;
— 查看所有的数据
select * from tb_stu ;
- 示例2
select columns(‘sid’) , columns(‘age’) , name , toTypeName(‘gender’) from tb_stu;
select sid+age from tb_stu ;
- 示例3
select
gender ,
avg(age) as avg_age
from
tb_stu
where sid < 200
group by gender
having avg_age >=21
order by avg_age desc
limit 3 ;
2.5.3 FROM
2.5.3.1 表中
select col1 , col2 …from tb_name ;
2.5.3.2 子查询
select
from
(
select * from tb_name
) ;
2.5.3.3 方法

- hdfs(uri, format,struct) ;
- select * from numbers(10) ;
- mysql(‘host:port’, ‘database’, ‘table’, ‘user’, ‘password’[, replace_query, ‘on_duplicate_clause’]);
- file(path, format, structure) — 文件的位必须在本地的指定的目录下
注意MySQL开启远程访问权限
mysql> set global validate_password_policy=0;
mysql> set global validate_password_length=1; 这个两个设置以后 密码很简单不会报错
开启远程连接权限
mysql > grant all privileges on . to ‘root’@’%’ identified by ‘root’ with grant option;
mysql > flush privileges;
例子1
参数一 路径
参数二 格式化规则
参数三 虚拟表结构对应数据结构
file(path, format, structure)
vi demo.csv 注意文件的位置在 //var/lib/ClickHouse/user_files 目录下
1,zss,25
2,lss,34
3,ada,19
SELECT *
FROM file(‘demo.csv’, ‘CSV’, ‘id Int8, name String ,age UInt8’)


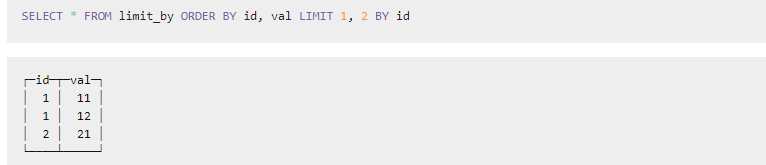
2.5.4 Limit by
limie n , m by 字段 按照某个维度每组显示n
示例
建表
CREATE TABLE tb_limit_by
(
id Int8,
name String,
score UInt8
)
ENGINE = TinyLog
插入数据
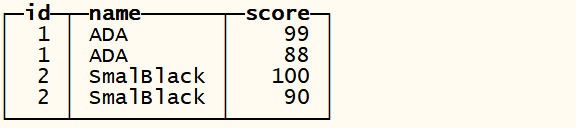
insert into tb_limit_by values(1,’ADA’,66),(1,’ADA’,88),(1,’ADA’,99);
insert into tb_limit_by values(2,’SmalBlack’,77),(2,’SmalBlack’,90),(2,’SmalBlack’,100);
查询数据
SELECT *
FROM tb_limit_by
┌─id─┬─name──────┬─score─┐
│ 1 │ ADA │ 66 │
│ 1 │ ADA │ 88 │
│ 1 │ ADA │ 99 │
│ 2 │ SmalBlack │ 77 │
│ 2 │ SmalBlack │ 90 │
│ 2 │ SmalBlack │ 100 │
└────┴───────────┴───────┘
查询每个人分数最高的两条记录
SELECT
FROM
(
SELECT
FROM tb_limit_by
ORDER BY score DESC
LIMIT 2 BY id
)
ORDER BY name ASC
2.5.5 ORDER BY
SELECT *
FROM numbers(10)
WHERE number > 3
┌─number┐
│ 4 │
│ 5 │
│ 6 │
│ 7 │
│ 8 │
│ 9 │
└─────┘
示例1
SELECT n, source FROM (
SELECT toFloat32(number % 10) AS n, ‘original’ AS source
FROM numbers(10) WHERE number % 3 = 1) ORDER BY n
┌─n─┬─source───┐
│ 1 │ original │
│ 4 │ original │
│ 7 │ original │
└───┴──────────┘
SELECT n, source FROM (
SELECT toFloat32(number % 10) AS n, ‘original’ AS source
FROM numbers(10) WHERE number % 3 = 1
) ORDER BY n WITH FILL FROM 0 TO 5.51 STEP 0.5
┌───n─┬─source───┐
│ 0 │ │
│ 0.5 │ │
│ 1 │ original │
│ 1.5 │ │
│ 2 │ │
│ 2.5 │ │
│ 3 │ │
│ 3.5 │ │
│ 4 │ original │
│ 4.5 │ │
│ 5 │ │
│ 5.5 │ │
│ 7 │ original │
└─────┴──────────┘
示例2
控制null值石是否优先显示
drop table tb_order_by ;
create table tb_order_by(x Int8 , y Nullable(Int8)) engine=TinyLog ;
insert into tb_order_by values(1,11),(2,22),(3,NULL),(4,NULL),(5,55),(6,4);
SELECT
FROM tb_order_by
ORDER BY y ASC NULLS FIRST ;
SELECT
FROM tb_order_by
ORDER BY y ASC NULLS LAST;
2.5.6 JOIN
CH中的join和HIVE中的类似只支持等值连接 不支持非等值连接
所有标准 SQL JOIN) 支持类型:
- INNER JOIN, only matching rows are returned.
- LEFT OUTER JOIN, non-matching rows from left table are returned in addition to matching rows.
- RIGHT OUTER JOIN, non-matching rows from right table are returned in addition to matching rows.
- FULL OUTER JOIN, non-matching rows from both tables are returned in addition to matching rows.
- CROSS JOIN, produces cartesian product of whole tables, “join keys” are not specified.
JOIN 没有指定类型暗示 INNER. 关键字 OUTER 可以安全地省略。 替代语法 CROSS JOIN 在指定多个表 FROM条款 用逗号分隔。
ClickHouse中提供的其他联接类型:
- LEFT SEMI JOIN and RIGHT SEMI JOIN, a whitelist on “join keys”, without producing a cartesian product.
- LEFT ANTI JOIN and RIGHT ANTI JOIN, a blacklist on “join keys”, without producing a cartesian product.
- LEFT ANY JOIN, RIGHT ANY JOIN and INNER ANY JOIN, partially (for opposite side of LEFT and RIGHT) or completely (for INNER and FULL) disables the cartesian product for standard JOIN types.
- ASOF JOIN and LEFT ASOF JOIN, joining sequences with a non-exact match. ASOF JOIN usage is described below.
2.5.7 INSERT INTO
2.5.7.1 基本格式
- insert into tb_name (col1 , col2…) values(v1,v2…) ; 指定字段插入
- insert into tb_name values(v1,v2…) ;插入所有字段
- insert into tb_name (col1 , col2…) values(v1,v2…) ,(),() 一次插入多条数据;
2.5.7.2 SELECT格式
在进行INSERT时将会对写入的数据进行一些处理,按照主键排序,按照月份对数据进行分区等。所以如果在您的写入数据中包含多个月份的混合数据时,将会显著的降低INSERT的性能。为了避免这种情况:
- 数据总是以尽量大的batch进行写入,如每次写入100,000行。
- 数据在写入ClickHouse前预先的对数据进行分组。
在以下的情况下,性能不会下降:
- 数据总是被实时的写入。
- 写入的数据已经按照时间排序。
drop table tb_insert ;
create table tb_insert(id String , name String) engine=TinyLog;
insert into tb_insert select * from tb_user ;
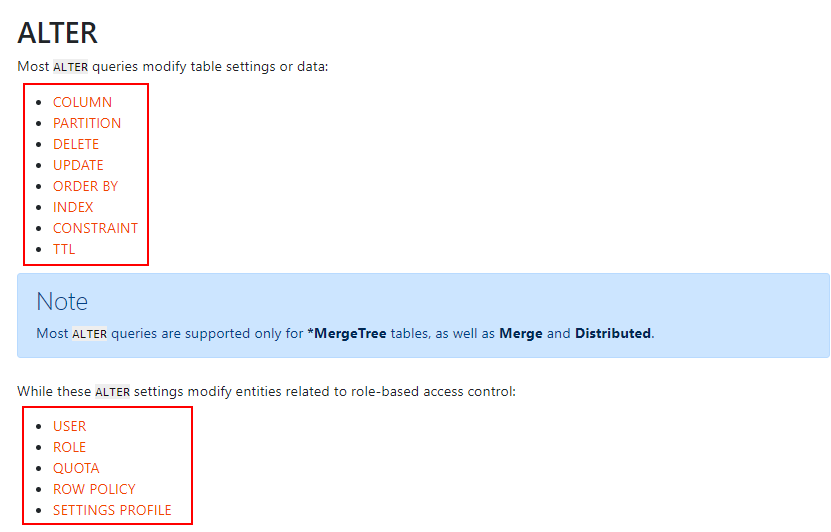
2.5.8 ALTER
2.5.9 SHOW
2.5.9.1 显示建表语句
SHOW CREATE TABLE tb_cps_merge_tree
──────────────────────────────────────────────────────────────┐
│ CREATE TABLE default.tb_cps_merge_tree
(
user_id UInt64,
name String,
age UInt8,
sign Int8
)
ENGINE = CollapsingMergeTree(sign)
ORDER BY user_id
SETTINGS index_granularity = 8192 │
└────────────────────────────────────────────────────────────────
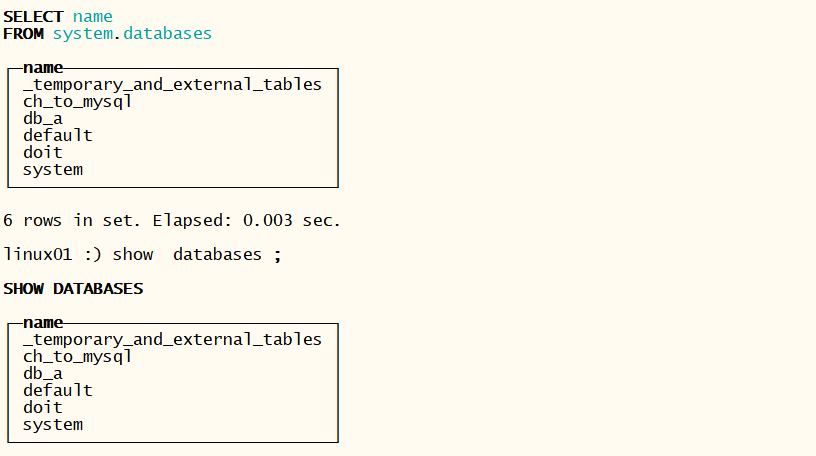
2.5.9.2 显示所有的数据库
- show databases ;
- select name from system.databases ;
2.5.9.3 显示表
- show tables ; — 显示当前数据库中的所有的表
- show tables from|in dbbase ; — 显示某个数据库中所有的表
- SHOW TABLES FROM doit LIKE ‘%tb%’ ; — 模糊查看数据库中的表
┌─name─────┐
│ tb_user │
│ tb_user2 │
└────────┘
2.5.10 DROP

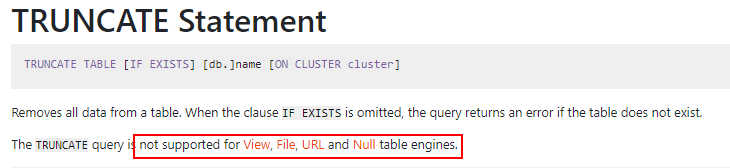
2.5.11 TRUNCATE
2.5.11.1 optimize
该查询尝试使用MergeTree系列中的表引擎初始化表的未计划的数据部分合并。
MaterializedView和Buffer引擎OPTMIZE也支持。不支持其他表引擎。
当OPTIMIZE与使用ReplicatedMergeTree表引擎,ClickHouse创造了合并,并等待所有节点上执行(如果该任务replication_alter_partitions_sync已启用设置)。
- 如果OPTIMIZE由于任何原因未执行合并,则不会通知客户端。要启用通知,请使用optimize_throw_if_noop设置。
- 如果指定PARTITION,则仅优化指定的分区。如何设置分区表达式。
- 如果指定FINAL,即使所有数据已经在一个部分中,也会执行优化。
- 如果指定DEDUPLICATE,则将对完全相同的行进行重复数据删除(比较所有列),这仅对MergeTree引擎有意义。
2.6 函数
ClickHouse主要提供两类函数—普通函数和聚合函数。普通函数由IFunction接口定义,拥有数十种函数实现,例如FunctionFormatDateTime、FunctionSubstring等。除了一些常见的函数 ( 诸如四则运算、日期转换等 ) 之外,也不乏一些非常实用的函数,例如网址提取函数、IP地址脱敏函数等。普通函数是没有状态的,函数效果作用于每行数据之上。当然,在函数具体执行的过程中,并不会一行一行地运算,而是采用向量化的方式直接作用于一整列数据。
聚合函数由IAggregateFunction接口定义,相比无状态的普通函数,聚合函数是有状态的。以COUNT聚合函数为例,其AggregateFunctionCount的状态使用整型UInt64记录。聚合函数的状态支持序列化与反序列化,所以能够在分布式节点之间进行传输,以实现增量计算。
2.6.1 普通函数

2.6.1.1 类型转换
toXX()
toXXOrxx()
cast(exp , ‘type’)
2.6.1.2 日期函数
SELECT
toDateTime(‘2016-06-15 23:00:00’) AS time,
toDate(time) AS date_local,
toDate(time, ‘Asia/Yekaterinburg’) AS date_yekat,
toString(time, ‘US/Samoa’) AS time_samoa
┌─────────time─┬─date_local─┬─date_yekat─┬─time_samoa───┐
│ 2016-06-15 23:00:00 │ 2016-06-15 │ 2016-06-15 │ 2016-06-15 04:00:00 │
└─────────────────────┴────────────┴────────┴
2.6.1.3 条件函数
create table if not exists tb_if(
uid Int16,
name String ,
gender String
)engine = TinyLog ;
insert into tb_if values(1,’zss1’,’M’) ;
insert into tb_if values(2,’zss2’,’M’) ;
insert into tb_if values(3,’zss3’,’F’) ;
insert into tb_if values(4,’zss4’,’O’) ;
insert into tb_if values(5,’zss5’,’F’) ;
SELECT
,
if(gender = ‘M’, ‘男’, ‘女’)
FROM tb_if ;
多条件判断语法
SELECT
,
multiIf(gender = ‘M’, ‘男’, gender = ‘F’, ‘女’, ‘保密’) AS sex
FROM tb_if;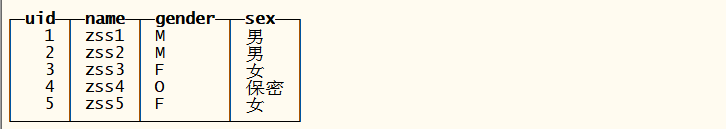
2.6.1.4 数组函数
2.6.1.4.1 数组的定义
SELECT range(2, 10, 2) — 定义一个范围数组
select array(2 , 10 , 2) ; — 定义数组
select arrayconcat([‘a’,’b’],[‘hello’,’jim’],[‘e’,’f’]); — 合并数组
- 是否包含

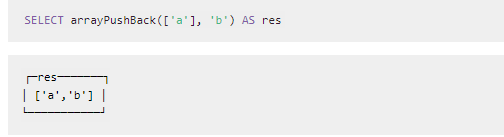
2.6.1.4.2 添加元素

2.6.1.4.3 数组排序
arrayReverseSort([func,] arr, …)

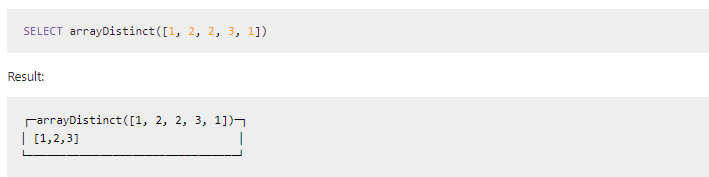
2.6.1.4.4 数组去重
2.6.1.4.5 数组拉链操作

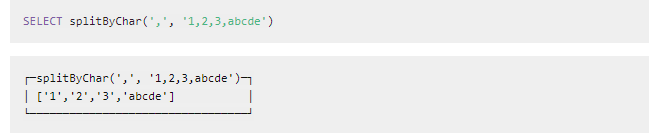
2.6.1.5 字符串切割

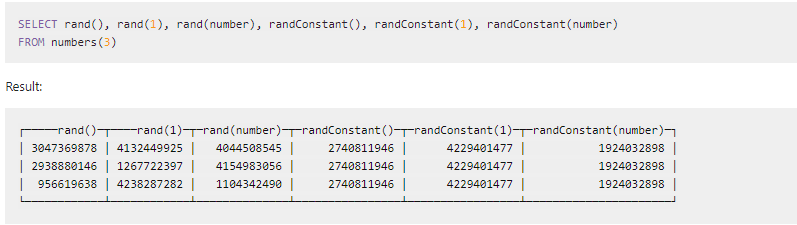
2.6.1.6 随机数据和随机字符串
2.6.1.7 JSON
linux01 :) select visitParamExtractString(‘{“name”:”zss”,”age”:21}’ , ‘name’) ;
SELECT visitParamExtractString(‘{“name”:”zss”,”age”:21}’, ‘name’)

2.6.1.8 高阶函数
- arrayMap
- arrayFilter
- arrayFill
- arrayReverseFill
- arraySplit
- arrayReverseSplit
- arrayFirst
- arrayFirstIndex
2.6.1.8.1 arrayMap

2.6.1.8.2 arrayFilter

2.6.1.8.3 arrayFill
Scan through arr1 from the first element to the last element and replace arr1[i] by arr1[i - 1] if func returns 0. The first element of arr1 will not be replaced.
从第一个元素开始扫描 ,当遇到符合条件的元素被前面的元素覆盖掉, 如果不满足条件数据不做处理!
2.6.1.8.4 arrayReverseFill
和上面的方法一样, 知识满足条件的数据被后面的替换
2.6.1.8.5 arraySplit
指定前面数组的拆分点
2.6.1.8.6 arrayReverseSplit


2.6.1.9 行转列
create table tb_array_join(id Int8 , msg String) engine=TinyLog ;
insert into tb_array_join values (1, ‘a,b,c’) ;
insert into tb_array_join values (2, ‘h,j,k’) ;
linux01 :) select id, arrayJoin(splitByChar(‘,’,msg)) from tb_array_join ;
SELECT
id,
arrayJoin(splitByChar(‘,’, msg))
FROM tb_array_join
2.6.1.10 列转行
数据如下:
将name所有的数据一行显示
┌─uid─┬─name─┐
│ 1 │ Hang │
│ 2 │ Jie │
│ 3 │ Li │
│ 4 │ Ying │
│ 2 │ Jie │
│ 3 │ Li │
│ 4 │ Ying │
│ 2 │ ADA │
│ 3 │ ADA │
│ 4 │ ADA │
│ 2 │ Jie │
│ 3 │ Li │
│ 4 │ Ying │
│ 2 │ Jie │
│ 3 │ Li │
│ 4 │ hhhh │
└───┴──────┘
select groupArray(name) from tb_user ; — 将所有的列聚合成一个数组!
│ [‘Hang’,’Jie’,’Li’,’Ying’,’Jie’,’Li’,’Ying’,’ADA’,’ADA’,’ADA’,’Jie’,’Li’,’Ying’,’Jie’,’Li’,’hhhh’] │
select arrayStringConcat(groupArray(name),’|’) from tb_user ; — 实现需求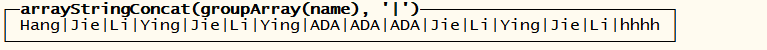
2.6.2 聚合函数
2.6.2.1 min 聚合函数 获取一列在最小值
2.6.2.2 max 聚合函数 获取一列在最大值
2.6.2.3 sum 集合函数 求一列数据的和
2.6.2.4 avg 集合函数 求一列数据的平均值
2.6.2.5 count聚合函数 统计非null数据的行数
2.6.2.6 grouparray 将一列数据聚合成一个数组
2.6.2.7 any 返回第一个符合条件的数据
2.6.2.8 argMin(arg1(维度) , arg2(比较))

2.6.2.9 argMax
2.6.2.10 avgWeighted
计算加权算术平均值。
句法avgWeighted(x, weight)
SELECT avgWeighted(x, y)
FROM values(‘x Int8,y Int8’, (4, 1), (4, 1), (8, 3))
┌─avgWeighted(x, y)─┐
│ 6.4 │
└─────────────┘
计算过程是
(41+41+8*3)/(1+1+3)
2.6.2.11 topK 返回以某个字段为维度出现频次最高的前n条记录
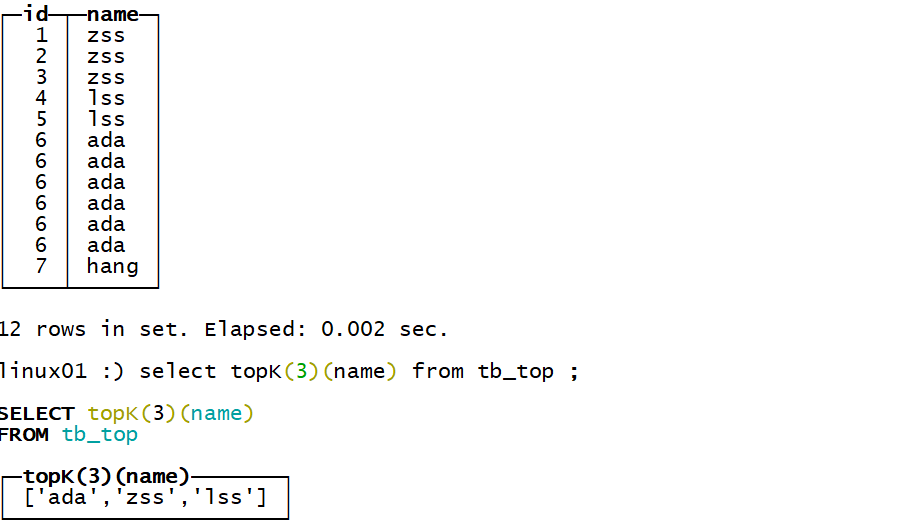
2.6.2.12 uniq和uniqExact 去重计数
uniq这个不是特点的精准, 是估值
uniqExact 这个函数是精准计数 ,但是它比价消耗内存资源
select uniqExact(name) from tb_top ;
2.6.2.13 uniqCombined 去重计数

2.6.2.14 * 链路函数
这组函数可以做动态规划,漏斗模型…
- sequenceMatch(pattern)(time, cond1, cond2, …) 判断是否存在满足根据时间排序且依次条件1,条件2,…条件n都成立的链路.若满足 返回 1,否则为 0 .
- sequenceCount(pattern)(time, cond1, cond2, …) 判断是否存在满足根据时间排序且依次条件1,条件2,…条件n都成立的链路 若满足 返回出现的次数
- windowFunnel(window)(time, cond1, cond2, …) 判断是否存在满足根据时间排序且依次条件1,条件2,…条件n都成立的链路. 并且设置链路的窗口时间. 一般用于计算漏斗模型
动态规划最大连续子序列案例
CREATE TABLE tb_test(uid String, eventid String, eventTime UInt64)ENGINE = Log;
cat event3.csv | clickhouse-client —query=”INSERT INTO tb_test FORMAT CSV”;
统计每个用户在40秒内最大连续子序列 ; 返回一个Int类型的数字 ,说明执行到符合规则的第几步
select
uid,windowFunnel(40)(toDateTime(eventTime),eventid = ‘A’ ,eventid = ‘B’,eventid = ‘C’) as funnel
from tb_test
group by uid ;
2.6.2.15 sumMap
语法:sumMap(key, value)或sumMap(Tuple(key, value)) 注意key和value也都是数组
create table tb_map1(
id Int8 ,
code_map Nested(
acc String ,
cost Int8
),
code_tuple Tuple(Array(String),Array(Int16))
) engine=TinyLog;
create table tb_map(
id Int8 ,
acc Array(String) ,
cost Array(Int8),
code_tuple Tuple(Array(String),Array(Int16))
) engine=TinyLog;


插入数据
insert into tb_map1 values(1 , [‘a’,’a’,’b’,’c’] ,[10,10,10,10] , ([‘ada’,’ada’,’aad’,’daa’],[99,99,99,88]))
select sumMap(code_map.acc , code_map.cost) from tb_map1 ;
select sumMap(code_tuple) from tb_map1 ;
2.6.2.16 minMap(Tuple)和maxMap(Tuple)
获取每组中最小或者最大的数据
SELECT minMap(code_tuple)
FROM tb_map1
│ ([‘aad’,’ada’,’daa’],[99,99,88]) │
2.6.3 聚合函数组合
2.6.3.1 IF

SELECT sumIf(id, name = ‘ada’)
FROM tb_top
┌─sumIf(id, equals(name, ‘ada’))─┐
│ 36 │
└───────────────────┘
2.6.3.2 Array
arraySum(arr)
sumArray(arr)
uniqArray(arr) 数组去重统计个数
arrayJoin(arr) 数组炸裂
SELECT sumArray([1, 2, 3, 4])
┌─sumArray(array(1, 2, 3, 4))─┐
│ 10 │
└─────────────────┘
SELECT arraySum([1, 2, 3, 4, 5])
┌─arraySum(array(1, 2, 3, 4, 5))─┐
│ 15 │
└───────────────────┘
————————————————————————————————————————————————-

————————————————————————————————————————————————-
2.6.3.3 ForEach
CREATE TABLE tb_for2
(
id Int8,
names Array(Int8)
)
ENGINE = TinyLog
insert into tb_for2 values(1 , [1,2,3])(2,[2,3,4])
SELECT *
FROM tb_for2
SELECT sumForEach(names)
FROM tb_for2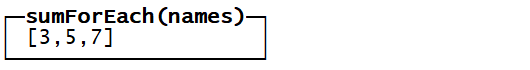
2.6.4 表函数
构建表的函数 , 使用场景如下:
2.6.4.1 file
file(path, format, structure)
- path — The relative path to the file from user_files_path. Path to file support following globs in readonly mode: *, ?, {abc,def} and {N..M} where N, M — numbers, `’abc’, ‘def’ — strings.
- format — The format of the file.
- structure — Structure of the table. Format ‘column1_name column1_type, column2_name column2_type, …’.
数据文件必须在指定的目录下 /var/lib/clickhouse/user_files
[root@linux01 user_files]# cat demo.csv
1,zss,25
2,lss,34
3,ada,19
SELECT *
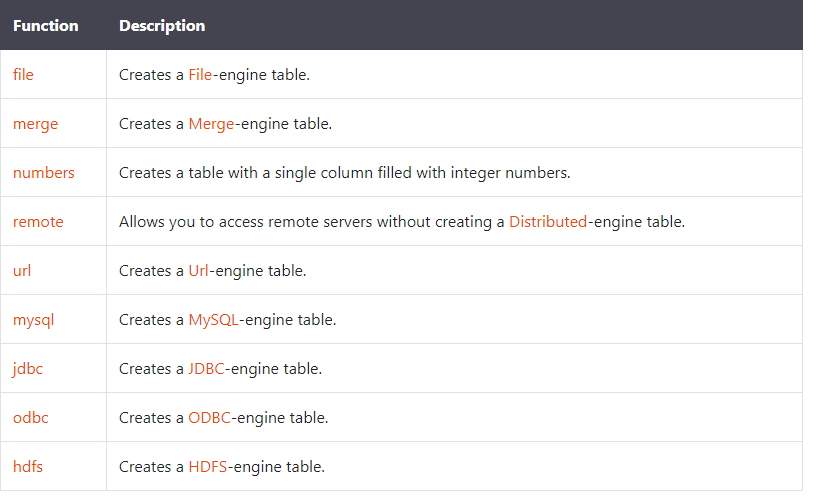
FROM file(‘demo.csv’, ‘CSV’, ‘id Int8,name String , age UInt8’)
┌─id─┬─name─┬─age─┐
│ 1 │ zss │ 25 │
│ 2 │ lss │ 34 │
│ 3 │ ada │ 19 │
└── ┴─────┴────┘
文件夹下任意的文件
SELECT
FROM file(‘‘, ‘CSV’, ‘id Int8,name String , age UInt8’)
2.6.4.2 merge
SELECT *
FROM merge(‘default’, ‘tb_top’)
┌─id─┬─name─┐
│ 1 │ zss │
│ 2 │ zss │
│ 3 │ zss │
│ 4 │ lss │
│ 5 │ lss │
│ 6 │ ada │
│ 6 │ ada │
│ 6 │ ada │
│ 6 │ ada │
│ 6 │ ada │
│ 6 │ ada │
│ 7 │ hang │
└────┴──────┘
2.6.4.3 numbers
SELECT *
FROM numbers(10) ;
SELECT *
FROM numbers(2, 10) ;
SELECT *
FROM numbers(10) limit 3 ;
SELECT toDate(‘2020-01-01’) + number AS d
FROM numbers(365)
2.6.4.4 url
SELECT FROM url(‘http://127.0.0.1:12345/‘, CSV, ‘column1 String, column2 UInt32’) *LIMIT
2.6.4.5 mysql
CH可以直接从mysql服务中查询数据
mysql(‘host:port’, ‘database’, ‘table’, ‘user’, ‘password’[, replace_query, ‘on_duplicate_clause’]);
SELECT *
FROM mysql(‘linux01:3306’, ‘db_doit_ch’, ‘emp’, ‘root’, ‘root’)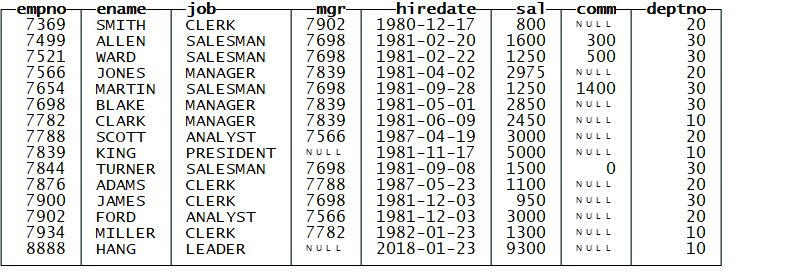
2.6.4.6 JDBC
SELECT FROM jdbc(‘jdbc:mysql://localhost:3306/?user=root&password=root’, ‘schema’, ‘table’)
SELECT FROM jdbc(‘mysql://localhost:3306/?user=root&password=root’, ‘schema’, ‘table’)
SELECT *FROM jdbc(‘datasource://mysql-local’, ‘schema’, ‘table’)
2.6.4.7 HDFS
SELECT *FROM hdfs(‘hdfs://hdfs1:9000/test’, ‘TSV’, ‘column1 UInt32, column2 UInt32, column3 UInt32’)LIMIT 2
SELECT *
FROM hdfs(‘hdfs://linux01:8020/demo.csv’, ‘CSV’, ‘id Int8 ,name String , age Int8’)
2.6.4.8 cluster
cluster(‘cluster_name’, db.table)
cluster(‘cluster_name’, db, table)
clusterAllReplicas(‘cluster_name’, db.table)
clusterAllReplicas(‘cluster_name’, db, table)
2.6.5 UD(A)F
2.6.5.1 自定义函数逻
2.7 数据导入
全量数据导入:数据导入临时表 -> 导入完成后,将原表改名为tmp1 -> 将临时表改名为正式表 -> 删除原表
增量数据导入: 增量数据导入临时表 -> 将原数据除增量外的也导入临时表 -> 导入完成后,将原表改名为tmp1-> 将临时表改成正式表-> 删除原数据表
导入引擎
2.7.1 HDFS
在HDFS的指定目录下上传数据文件,直接建表加载数据
CREATE TABLE hdfs_engine_table
(
name String,
age UInt32
)
ENGINE = HDFS(‘hdfs://doit01:8020/data/ch/demo1.csv’, ‘CSV’)
Ok.
0 rows in set. Elapsed: 0.026 sec.
doit04 :) select * from hdfs_engine_table ;
SELECT *
FROM hdfs_engine_table
┌─name─┬─age─┐
│ ada │ 18 │
│ daa │ 21 │
│ caa │ 22 │
└──────┴─────┘
2.7.2 KAFKA
2.7.3 文件引擎
2.7.3.1 示例一
- 建表
create table tb_file_demo1(uid UInt16 , name String) engine=File(TabSeparated) ;
- 在指定的目录下创建数据文件
/var/lib/ClickHouse/data/default/tb_file_demo1
[root@linux01 tb_file_demo1]# vi data.TabSeparated 注意这个文件的名字不能变化
1001 TaoGe
1002 XingGe
1003 HANGGE
- 查询数据

2.7.3.2 示例二
- 建表
create table tb_file_demo2(uid UInt16 , name String) engine=File(CSV) ;
- 指定目录下编辑数据文件
vi data.CSV 注意后缀是大写
101,TaoGe
102,XingGe
103,HANGGE
- 查看表数据

2.7.4 insert方式
- 创建表
- Insert数据
- insert select语法 使用这种形式在进行导入数据的时候注意不要使用Log系列引擎,会造成表的损坏!!建议使用MergeTree系列引擎的表!
创建一个表
CREATE TABLE tb_insert
(
id Int8,
name String,
age UInt8
)
ENGINE = MergeTree()
ORDER BY age
插入数据
insert into tb_insert values(1,’songjiang’,23) ;
insert into tb_insert values(2,’linchong’,35),(3,’wusong’,28) ;
Insert into select方式插入数据
insert into tb_insert select * from tb_insert ;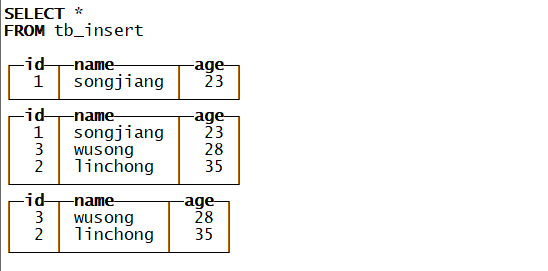
2.7.5 缓存方式
2.7.6 local方式
2.7.7 client方式
cat ./* | clickhouse-client —query=”INSERT INTO default.app_event_dtl FORMAT Parquet”
2.7.8 From方式
2.8 导出数据
2.9 JDBC
- 创建maven项目添加依赖
- 开放机器访问CH的权限
vi /etc/clickhouse-server/config.xm
- 编写代码
/*
@Author: 多易教育-行哥
@Date:Create:in 2020/8/21 0021
@Description: clickhouse入门程序
JDBC 读取CH中的数据
/_public class Demo1 {
public static void main(String[] args) throws Exception {
Class._forName(“ru.yandex.clickhouse.ClickHouseDriver”);
String address = “jdbc:clickhouse://192.168.133.6:8123/default”;
Connection conn = DriverManager.getConnection(address);
Statement st = conn.createStatement();
ResultSet resultSet = st.executeQuery(“select * from userlog”);
while(resultSet.next()){
String uid = resultSet.getString(“uid”);
String value = resultSet.getString(“value”);
System._out.println(uid+”—-“+value);
}
resultSet.close();
st.close() ;
conn.close();
}
}
展示读取的clickhouse中的数据
2.10 可视化工具
http://ui.tabix.io/#!/login 提供的一个页面可视化工具

3 ClickHouse原理加强篇
3.1 ClickHouse为何如此之快
很多用户心中一直会有这样的疑问,为什么ClickHouse这么快?前面的介绍对这个问题已经做出了科学合理的解释。比方说,因为ClickHouse是列式存储数据库,所以快;也因为ClickHouse使用了向量化引擎,所以快。这些解释都站得住脚,但是依然不能消除全部的疑问。因为这些技术并不是秘密,世面上有很多数据库同样使用了这些技术,但是依然没有ClickHouse这么快。所以我想从另外一个角度来探讨一番ClickHouse的秘诀到底是什么。
首先向各位读者抛出一个疑问:在设计软件架构的时候,做设计的原则应该是自顶向下地去设计,还是应该自下而上地去设计呢?在传统观念中,或者说在我的观念中,自然是自顶向下的设计,通常我们都被教导要做好顶层设计。而ClickHouse的设计则采用了自下而上的方式。ClickHouse的原型系统早在2008年就诞生了,在诞生之初它并没有宏伟的规划。相反它的目的很单纯,就是希望能以最快的速度进行GROUP BY查询和过滤。他们是如何实践自下而上设计的呢?
3.1.1 着眼硬件,先想后做


3.1.2 算法在前, 抽象在后
常有人念叨:’有时候,选择比努力更重要。’确实,路线选错了再努力也是白搭。在ClickHouse的底层实现中,经常会面对一些重复的场景,例如字符串子串查询、数组排序、使用HashTable等。如何才能实现性能的最大化呢?算法的选择是重中之重。以字符串为例,有一本专门讲解字符串搜索的书,名为’Handbook of Exact String Matching Algorithms’,列举了35种常见的字符串搜索算法。各位猜一猜ClickHouse使用了其中的哪一种?答案是一种都没有。这是为什么呢?因为性能不够快。在字符串搜索方面,针对不同的场景,ClickHouse最终选择了这些算法:对于常量,使用Volnitsky算法;对于非常量,使用CPU的向量化执行SIMD,暴力优化;正则匹配使用re2和hyperscan算法。性能是算法选择的首要考量指标。
3.1.3 勇于尝鲜,不行就换
除了字符串之外,其余的场景也与它类似,ClickHouse会使用最合适、最快的算法。如果世面上出现了号称性能强大的新算法,ClickHouse团队会立即将其纳入并进行验证。如果效果不错,就保留使用;如果性能不尽人意,就将其抛弃。
3.1.4 特定场景 ,特殊优化
针对同一个场景的不同状况,选择使用不同的实现方式,尽可能将性能最大化。关于这一点,其实在前面介绍字符串查询时,针对不同场景选择不同算法的思路就有体现了。类似的例子还有很多,例如去重计数uniqCombined函数,会根据数据量的不同选择不同的算法:当数据量较小的时候,会选择Array保存;当数据量中等的时候,会选择HashSet;而当数据量很大的时候,则使用HyperLogLog算法。
对于数据结构比较清晰的场景,会通过代码生成技术实现循环展开,以减少循环次数。接着就是大家熟知的大杀器—向量化执行了。SIMD被广泛地应用于文本转换、数据过滤、数据解压和JSON转换等场景。相较于单纯地使用CPU,利用寄存器暴力优化也算是一种降维打击了。
3.1.5 持续测试 ,持续改进
如果只是单纯地在上述细节上下功夫,还不足以构建出如此强大的ClickHouse,还需要拥有一个能够持续验证、持续改进的机制。由于Yandex的天然优势,ClickHouse经常会使用真实的数据进行测试,这一点很好地保证了测试场景的真实性。与此同时,ClickHouse也是我见过的发版速度最快的开源软件了,差不多每个月都能发布一个版本。没有一个可靠的持续集成环境,这一点是做不到的。正因为拥有这样的发版频率,ClickHouse才能够快速迭代、快速改进。
所以ClickHouse的黑魔法并不是一项单一的技术,而是一种自底向上的、追求极致性能的设计思路。这就是它如此之快的秘诀。
表引擎(即表的类型)决定了:
- 数据的存储方式和位置,写到哪里以及从哪里读取数据
- 支持哪些查询以及如何支持。
- 并发数据访问。
- 索引的使用(如果存在)。
- 是否可以执行多线程请求。
- 数据复制参数。
在读取时,引擎只需要输出所请求的列,但在某些情况下,引擎可以在响应请求时部分处理数据。对于大多数正式的任务,应该使用MergeTree族中的引擎。
3.2 架构设计
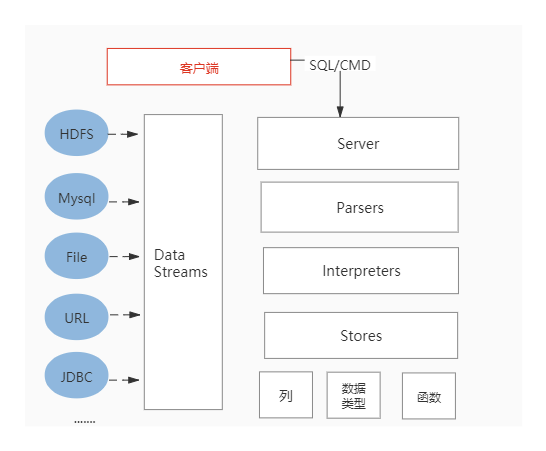
3.2.1 Column与Field
Column和Field是ClickHouse数据最基础的映射单元。作为一款百分之百的列式存储数据库,ClickHouse按列存储数据,内存中的一列数据由一个Column对象表示。Column对象分为接口和实现两个部分,在IColumn接口对象中,定义了对数据进行各种关系运算的方法,例如插入数据的insertRangeFrom和insertFrom方法、用于分页的cut,以及用于过滤的filter方法等。而这些方法的具体实现对象则根据数据类型的不同,由相应的对象实现,例如ColumnString、ColumnArray和ColumnTuple等。在大多数场合,ClickHouse都会以整列的方式操作数据,但凡事也有例外。如果需要操作单个具体的数值 ( 也就是单列中的一行数据 ),则需要使用Field对象,Field对象代表一个单值。与Column对象的泛化设计思路不同,Field对象使用了聚合的设计模式。在Field对象内部聚合了Null、UInt64、String和Array等13种数据类型及相应的处理逻辑。
一个列中的数据一般是以文件单独存储的
3.2.2 DataType
数据的序列化和反序列化工作由DataType负责。IDataType接口定义了许多正反序列化的方法,它们成对出现,例如serializeBinary和deserializeBinary、serializeTextJSON和deserializeTextJSON等,涵盖了常用的二进制、文本、JSON、XML、CSV和Protobuf等多种格式类型。IDataType也使用了泛化的设计模式,具体方法的实现逻辑由对应数据类型的实例承载,例如DataTypeString、DataTypeArray及DataTypeTuple等。
3.2.3 BloCK与BloCK流
ClickHouse内部的数据操作是面向BloCK对象进行的,并且采用了流的形式。虽然Column和Filed组成了数据的基本映射单元,但对应到实际操作,它们还缺少了一些必要的信息,比如数据的类型及列的名称。于是ClickHouse设计了BloCK对象,BloCK对象可以看作数据表的子集。BloCK对象的本质是由数据对象、数据类型和列名称组成的三元组,即Column、DataType及列名称字符串。Column提供了数据的读取能力,而DataType知道如何正反序列化,所以BloCK在这些对象的基础之上实现了进一步的抽象和封装,从而简化了整个使用的过程,仅通过BloCK对象就能完成一系列的数据操作。在具体的实现过程中,BloCK并没有直接聚合Column和DataType对象,而是通过ColumnWithTypeAndName对象进行间接引用。
有了BloCK对象这一层封装之后,对BloCK流的设计就是水到渠成的事情了。流操作有两组顶层接口:IBloCKInputStream负责数据的读取和关系运算,IBloCKOutputStream负责将数据输出到下一环节。BloCK流也使用了泛化的设计模式,对数据的各种操作最终都会转换成其中一种流的实现。IBloCKInputStream接口定义了读取数据的若干个read虚方法,而具体的实现逻辑则交由它的实现类来填充。
IBloCKInputStream接口总共有60多个实现类,它们涵盖了ClickHouse数据摄取的方方面面。这些实现类大致可以分为三类:第一类用于处理数据定义的DDL操作,例如DDLQueryStatusInputStream等;第二类用于处理关系运算的相关操作,例如LimitBloCKInput-Stream、JoinBloCKInputStream及AggregatingBloCKInputStream等;第三类则是与表引擎呼应,每一种表引擎都拥有与之对应的BloCKInputStream实现,例如MergeTreeBaseSelect-BloCKInputStream ( MergeTree表引擎 )、TinyLogBloCKInputStream ( TinyLog表引擎 ) 及KafkaBloCKInputStream ( Kafka表引擎 ) 等。
IBloCKOutputStream的设计与IBloCKInputStream如出一辙。IBloCKOutputStream接口同样也定义了若干写入数据的write虚方法。它的实现类比IBloCKInputStream要少许多,一共只有20多种。这些实现类基本用于表引擎的相关处理,负责将数据写入下一环节或者最终目的地,例如MergeTreeBloCKOutputStream 、TinyLogBloCKOutputStream及StorageFileBloCK-OutputStream等。
3.2.4 Table
在数据表的底层设计中并没有所谓的Table对象,它直接使用IStorage接口指代数据表。表引擎是ClickHouse的一个显著特性,不同的表引擎由不同的子类实现,例如IStorageSystemOneBloCK ( 系统表 )、StorageMergeTree ( 合并树表引擎 ) 和StorageTinyLog ( 日志表引擎 ) 等。IStorage接口定义了DDL ( 如ALTER、RENAME、OPTIMIZE和DROP等 ) 、read和write方法,它们分别负责数据的定义、查询与写入。在数据查询时,IStorage负责根据AST查询语句的指示要求,返回指定列的原始数据。后续对数据的进一步加工、计算和过滤,则会统一交由Interpreter解释器对象处理。对Table发起的一次操作通常都会经历这样的过程,接收AST查询语句,根据AST返回指定列的数据,之后再将数据交由Interpreter做进一步处理。
3.2.5 Parser与Interpreter
Parser和Interpreter是非常重要的两组接口:Parser分析器负责创建AST对象;而Interpreter解释器则负责解释AST,并进一步创建查询的执行管道。它们与IStorage一起,串联起了整个数据查询的过程。Parser分析器可以将一条SQL语句以递归下降的方法解析成AST语法树的形式。不同的SQL语句,会经由不同的Parser实现类解析。例如,有负责解析DDL查询语句的ParserRenameQuery、ParserDropQuery和ParserAlterQuery解析器,也有负责解析INSERT语句的ParserInsertQuery解析器,还有负责SELECT语句的ParserSelectQuery等。
Interpreter解释器的作用就像Service服务层一样,起到串联整个查询过程的作用,它会根据解释器的类型,聚合它所需要的资源。首先它会解析AST对象;然后执行’业务逻辑’ ( 例如分支判断、设置参数、调用接口等 );最终返回IBloCK对象,以线程的形式建立起一个查询执行管道。
3.2.6 分片与副本
ClickHouse的集群由分片 ( Shard ) 组成,而每个分片又通过副本 ( Replica ) 组成。这种分层的概念,在一些流行的分布式系统中十分普遍。例如,在Elasticsearch的概念中,一个索引由分片和副本组成,副本可以看作一种特殊的分片。如果一个索引由5个分片组成,副本的基数是1,那么这个索引一共会拥有10个分片 ( 每1个分片对应1个副本 )。
如果你用同样的思路来理解ClickHouse的分片,那么很可能会在这里栽个跟头。ClickHouse的某些设计总是显得独树一帜,而集群与分片就是其中之一。这里有几个与众不同的特性。
ClickHouse的1个节点只能拥有1个分片,也就是说如果要实现1分片、1副本,则至少需要部署2个服务节点。
分片只是一个逻辑概念,其物理承载还是由副本承担的。
代码清单1所示是ClickHouse的一份集群配置示例,从字面含义理解这份配置的语义,可以理解为自定义集群ch_cluster拥有1个shard ( 分片 ) 和1个replica ( 副本 ),且该副本由10.37.129.6服务节点承载。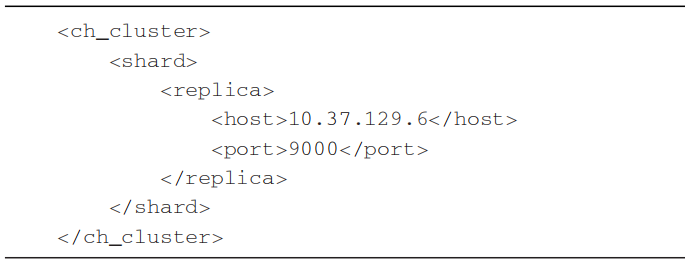
从本质上看,这组1分片、1副本的配置在ClickHouse中只有1个物理副本,所以它正确的语义应该是1分片、0副本。分片更像是逻辑层的分组,在物理存储层面则统一使用副本代表分片和副本。所以真正表示1分片、1副本语义的配置,应该改为1个分片和2个副本,如代码清单2所示。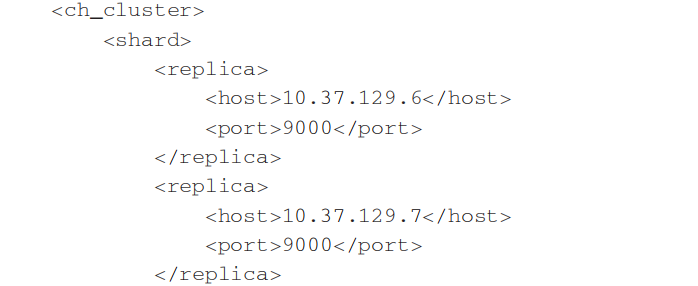
3.3 数据存储特点
3.3.1 列式存储
3.3.2 数据有序存储
ClickHouse支持在建表时,指定将数据按照某些列进行sort by。
排序后,保证了相同sort key的数据在磁盘上连续存储,且有序摆放。在进行等值、范围查询时,where条件命中的数据都紧密存储在一个或若干个连续的BloCK中,而不是分散的存储在任意多个BloCK, 大幅减少需要IO的bloCK数量。另外,连续IO也能够充分利用操作系统page cache的预取能力,减少page fault。
3.3.3 主键索引
ClickHouse支持主键索引,它将每列数据按照index granularity(默认8192行)进行划分,每个index granularity的开头第一行被称为一个mark行。主键索引存储该mark行对应的primary key的值。对于where条件中含有primary key的查询,通过对主键索引进行二分查找,能够直接定位到对应的index granularity,避免了全表扫描从而加速查询。
但是值得注意的是:ClickHouse的主键索引与MySQL等数据库不同,它并不用于去重,即便primary key相同的行,也可以同时存在于数据库中。要想实现去重效果,需要结合具体的表引擎ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree实现,我们会在未来的文章系列中再进行详细解读。
3.3.4 稀疏索引
ClickHouse支持对任意列创建任意数量的稀疏索引。其中被索引的value可以是任意的合法SQL Expression,并不仅仅局限于对column value本身进行索引。之所以叫稀疏索引,是因为它本质上是对一个完整index granularity(默认8192行)的统计信息,并不会具体记录每一行在文件中的位置。目前支持的稀疏索引类型包括:
- minmax: 以index granularity为单位,存储指定表达式计算后的min、max值;在等值和范围查询中能够帮助快速跳过不满足要求的块,减少IO。
- set(max_rows):以index granularity为单位,存储指定表达式的distinct value集合,用于快速判断等值查询是否命中该块,减少IO。
- ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed):将string进行ngram分词后,构建bloom filter,能够优化等值、like、in等查询条件。
- tokenbf_v1(size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed): 与ngrambf_v1类似,区别是不使用ngram进行分词,而是通过标点符号进行词语分割。
bloom_filter([false_positive]):对指定列构建bloom filter,用于加速等值、like、in等查询条件的执行。
3.3.5 数据分片(表片段)
ClickHouse支持单机模式,也支持分布式集群模式。在分布式模式下,ClickHouse会将数据分为多个分片,并且分布到不同节点上。不同的分片策略在应对不同的SQL Pattern时,各有优势。ClickHouse提供了丰富的sharding策略,让业务可以根据实际需求选用。
1) random随机分片:写入数据会被随机分发到分布式集群中的某个节点上。
2) constant固定分片:写入数据会被分发到固定一个节点上。
3)column value分片:按照某一列的值进行hash分片。
4)自定义表达式分片:指定任意合法表达式,根据表达式被计算后的值进行hash分片。
数据分片,让ClickHouse可以充分利用整个集群的大规模并行计算能力,快速返回查询结果。
更重要的是,多样化的分片功能,为业务优化打开了想象空间。比如在hash sharding的情况下,JOIN计算能够避免数据shuffle,直接在本地进行local join; 支持自定义sharding,可以为不同业务和SQL Pattern定制最适合的分片策略;利用自定义sharding功能,通过设置合理的sharding expression可以解决分片间数据倾斜问题等。
另外,sharding机制使得ClickHouse可以横向线性拓展,构建大规模分布式集群,从而具备处理海量数据的能力。3.3.6 数据Partitioning(类似于hive的分区表)
ClickHouse支持PARTITION BY子句,在建表时可以指定按照任意合法表达式进行数据分区操作,比如通过toYYYYMM()将数据按月进行分区、toMonday()将数据按照周几进行分区、对Enum类型的列直接每种取值作为一个分区等。
数据Partition在ClickHouse中主要有两方面应用:在partition key上进行分区裁剪,只查询必要的数据。灵活的partition expression设置,使得可以根据SQL Pattern进行分区设置,最大化的贴合业务特点。
- 对partition进行TTL管理,淘汰过期的分区数据。
3.3.7 数据TTL
在分析场景中,数据的价值随着时间流逝而不断降低,多数业务出于成本考虑只会保留最近几个月的数据,ClickHouse通过TTL提供了数据生命周期管理的能力。
ClickHouse支持几种不同粒度的TTL:
1) 列级别TTL:当一列中的部分数据过期后,会被替换成默认值;当全列数据都过期后,会删除该列。
2)行级别TTL:当某一行过期后,会直接删除该行。
3)分区级别TTL:当分区过期后,会直接删除该分区。3.3.8 高吞吐写入能力
ClickHouse采用类LSM Tree的结构,数据写入后定期在后台Compaction。通过类LSM tree的结构,ClickHouse在数据导入时全部是顺序append写,写入后数据段不可更改,在后台compaction时也是多个段merge sort后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力,即便在HDD上也有着优异的写入性能。
官方公开benchmark测试显示能够达到50MB-200MB/s的写入吞吐能力,按照每行100Byte估算,大约相当于50W-200W条/s的写入速度。3.3.9 有限支持delete、update
在分析场景中,删除、更新操作并不是核心需求。ClickHouse没有直接支持delete、update操作,而是变相支持了mutation操作,语法为alter table delete where filter_expr,alter table update col=val where filter_expr。
目前主要限制为删除、更新操作为异步操作,需要后台compation之后才能生效。3.3.10 主备同步
ClickHouse通过主备复制提供了高可用能力,主备架构下支持无缝升级等运维操作。而且相比于其他系统它的实现有着自己的特色:
1)默认配置下,任何副本都处于active模式,可以对外提供查询服务;
2)可以任意配置副本个数,副本数量可以从0个到任意多个;
3)不同shard可以配置不同的副本个数,用于解决单个shard的查询热点问题;
3.4 ClickHouse计算层
ClickHouse在计算层做了非常细致的工作,竭尽所能榨干硬件能力,提升查询速度。它实现了单机多核并行、分布式计算、向量化执行与SIMD指令、代码生成等多种重要技术。
3.4.1 多核并行
ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity,然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。
在这种设计下,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时。
3.4.2 分布式计算
除了优秀的单机并行处理能力,ClickHouse还提供了可线性拓展的分布式计算能力。ClickHouse会自动将查询拆解为多个task下发到集群中,然后进行多机并行处理,最后把结果汇聚到一起。
在存在多副本的情况下,ClickHouse提供了多种query下发策略:
随机下发:在多个replica中随机选择一个;
- 最近hostname原则:选择与当前下发机器最相近的hostname节点,进行query下发。在特定的网络拓扑下,可以降低网络延时。而且能够确保query下发到固定的replica机器,充分利用系统cache。
- in order:按照特定顺序逐个尝试下发,当前一个replica不可用时,顺延到下一个replica。
first or random:在In Order模式下,当第一个replica不可用时,所有workload都会积压到第二个Replica,导致负载不均衡。first or random解决了这个问题:当第一个replica不可用时,随机选择一个其他replica,从而保证其余replica间负载均衡。另外在跨region复制场景下,通过设置第一个replica为本region内的副本,可以显著降低网络延时。
3.5 ZooKeeper
ClickHouse内核分析系列文章,本文将为大家深度解读Zookeeper在ClickHouse集群中的作用,目前和Zookeeper密切相关的功能包括分布式DDL执行和ReplicatedMergeTree表引擎。最近碰到了很多同学询问和Zookeeper相关的问题,希望通过本文大家可以深刻理解ClickHouse用Zookeeper到底解决哪些问题。正文将会为大家依次介绍分布式DDL执行和ReplicatedMergeTree表引擎依赖的实现细节,建议读者先补充系列文章中关于MergeTree表引擎的前两篇文章,这样会比较容易理解ReplicatedMergeTree表引擎。ReplicatedMergeTree表引擎中的主备同步完全依赖Zookeeper,并且逻辑十分复杂,本文只能为大家呈现一个大体的逻辑链路。3.5.1 Zookeeper在ClickHouse中的应用简介
Zookeeper作为一个分布式一致性存储服务,提供了丰富的读写接口和watch机制,分布式应用基于Zookeeper可以解决很多常见问题,例如心跳管理、主备切换、分布式锁等。建议对Zookeeper完全没有了解的同学先补充一些Zookeeper的基本概念再来读本文。
ClickHouse中依赖Zookeeper解决的问题可以分为两大类:分布式DDL执行、ReplicatedMergeTree表主备节点之间的状态同步。
分布式DDL执行:ClickHouse中DDL执行默认不是分布式化的,用户需要在DDL语句中加上on Cluster XXX的申明才能触发这个功能。和其他完全分布式化的数据库不同,ClickHouse对库、表的管理都是在存储节点级别独立的,集群中各节点之间的库、表元数据信息没有一致性约束。这是由ClickHouse的架构特色决定的:1)彻底Share Nothing,各节点之间完全没有相互依赖;2)节点完全对等,集群中的节点角色统一,ClickHouse没有传统MPP数据库中的前端节点、Worker节点、元数据节点等概念。ClickHouse的这种架构特色决定它可以敏捷化、小规模部署,集群可以任意进行分裂、合并,当然前提要求是感知数据在集群节点上的分布。在ClickHouse的架构形态下,用户可以直接连接任意一个节点进行请求,当用户发送DDL命令时,默认只会在当前连接的节点执行命令。现实中如果用户有一个100台机器的集群,为了创建一个分布式存储的表难道用户需要依次连接每台机器发送DDL命令吗?这会让用户抓狂的,并且存在多个DDL之间的冲突问题无法解决:用户A和用户B同时创建同名表但是表字段又不一致,这肯定会让系统陷入一个诡异的不一致状态。这个就是分布式DDL执行要解决的问题了,ClickHouse集群的每个节点都会把收到的分布式执行DDL请求放入到一个公共的Zookeeper任务队列中,然后每个节点的后台线程会依次任务队列里的DDL,保证了所有分布式DDL的串行执行顺序。
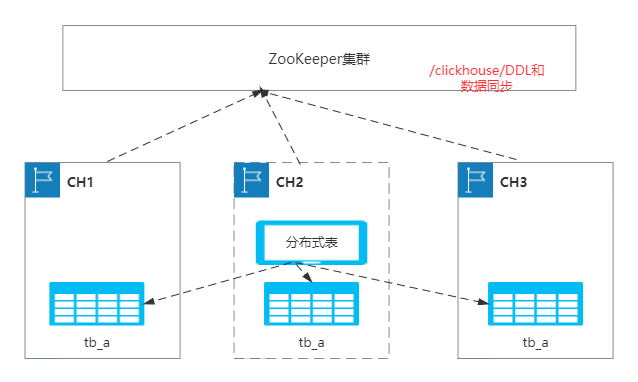
主备节点状态同步:ClickHouse集群化部署中有三个逻辑概念需要先展开介绍一下Cluster、Shard和Replicate,这三者都是ClickHouse在集群节点资源规划上的概念。一个集群可以包括若干个Cluster,一个Cluster可以包括若干个Shard,一个Shard又可以包含若干个Replicate,一个Replicate就是一个特定的节点实例,用户可以通过ClickHouse启动的config.xml来配置这套节点规划逻辑。基于这套逻辑,用户可以把一个集群规划成若干个Cluster,每个Cluster可自定义Shard数量,每个Shard又可以自定义副本数量。这三个概念只作用于资源规划上,单个存储节点内部不同Cluster之间的表都是相互可见的。在数据分析在线化的大趋势下,用户的分析场景对RT和QPS有越来越高的要求。降低RT的一个核心能力是自定义表的Shard数量(Scale Out),传统的MPP数据也都有这个能力。而提升QPS的一个核心能力是自定义表的Replicate数量,传统的MPP数据库都没有表级别的自定义副本数能力,只能做全库的副本数配置。ClickHouse能做到表的Replicate数量自定义技术核心是它把主备同步逻辑放到了具体的表引擎中实现,而不是在节点级别做数据复制。当前只有ReplicatedMergeTree表引擎可以自动做主备状态同步,其他表引擎没有状态同步机制。如果用户需要在多副本Cluster下创建其他表引擎,则需要在写入链路上配置多写逻辑。ReplicatedMergeTree表引擎的同步包括写入同步、异步Merge同步、异步Mutation同步等,它所有的同步逻辑都是强依赖Zookeeper。3.5.2 分布式DDL执行链路
在介绍具体的分布式DDL执行链路之前,先为大家梳理一下到底哪些操作是可以走分布式DDL执行链路的,大家也可以自己在源码中查看一下ASTQueryWithOnCluster的继承类有哪些:
ASTCreateQuery:包括常见的建库、建表、建视图,还有ClickHouse独有的Attach Table(可以从存储文件中直接加载一个之前卸载的数据表)。
- ASTAlterQuery:包括ATTACH_PARTITION、FETCH_PARTITION、FREEZE_PARTITION、FREEZE_ALL等操作(对表的数据分区粒度进行操作)。
- ASTDropQuery:其中包含了三种不同的删除操作(Drop / Truncate / Detach),Detach Table和Attach Table对应,它是表的卸载动作,把表的存储目录整个移到专门的detach文件夹下,然后关闭表在节点RAM中的”引用”,这张表在节点中不再可见。
- ASTOptimizeQuery:这是MergeTree表引擎特有的操作命令,它可以手动触发MergeTree表的合并动作,并可以强制数据分区下的所有Data Part合并成一个。
- ASTRenameQuery:修改表名,可更改到不同库下。
ASTKillQueryQuery:可以Kill正在运行的Query,也可以Kill之前发送的Mutation命令。
3.5.3 DDL Query Task分发
ClickHouse内核对每种SQL操作都有对应的IInterpreter实现类,其中的execute方法负责具体的操作逻辑。而以上列举的ASTQuery对应的IInterpreter实现类中的execute方法都加入了分布式DDL执行判断逻辑,把所有分布式DDL执行链路统一都DDLWorker::executeDDLQueryOnCluster方法中。executeDDLQueryOnCluster的过程大致可以分为三个步骤:检查DDLQuery的合法性,把DDLQuery写入到Zookeeper任务队列中,等待Zookeeper任务队列的反馈把结果返回给用户。
检查Query合法性这块有一点值得注意:用户在当前session的database空间下执行一个分布式DDL命令,真实执行DDL操作的节点会在什么database下执行这个DDL呢?这里的逻辑是:1)优先使用DDL Query中指明的database,2)当DDL Query中没有指明database时,优先使用config.xml中的Cluster配置,每个Shard配置可以申明自己的default database,3)若前两者都没有,则使用当前session的database。
DDL Query的分发过程依赖Zookeeper,每一条需要分发的DDL Query转换成一个如下的DDL LogEntry,然后把LogEntry序列化成字符串保存到Zookeeper的任务队列中。LogEntry中包含了SQL信息,分布式执行目标Cluster对应的所有节点地址信息,LogEntry的生成者信息。Zookeeper的任务队列位置是在config.xml配置中统一配置的(用户可以让多个ClickHouse集群共用一套Zookeeper,默认路径为/ClickHouse/taskqueue/ddl)。ClickHouse都是利用Zookeeper序列自增节点(Sequence Znodes)的特性实现来任务队列,把每个DDL LogEntry保存为任务队列目录下的一个Persistent Sequential Znode,相当于对每个DDL Query赋予了一个集群自增的数字ID,在每个DDL LogEntry对应的Znode下面,还需要创建两个status节点:active Znode用来管理当前有多少节点正在执行这个DDL,finished Znode用来管理当前有多少节点以及完成这个DDL并收集返回的状态信息(包括Exception)。
struct DDLLogEntry
{
String query;
std::vectorhosts; // optional_
String initiator;
static constexpr int CURRENT_VERSION = 1;
…
}
分布式DDL的执行链路如下图所示: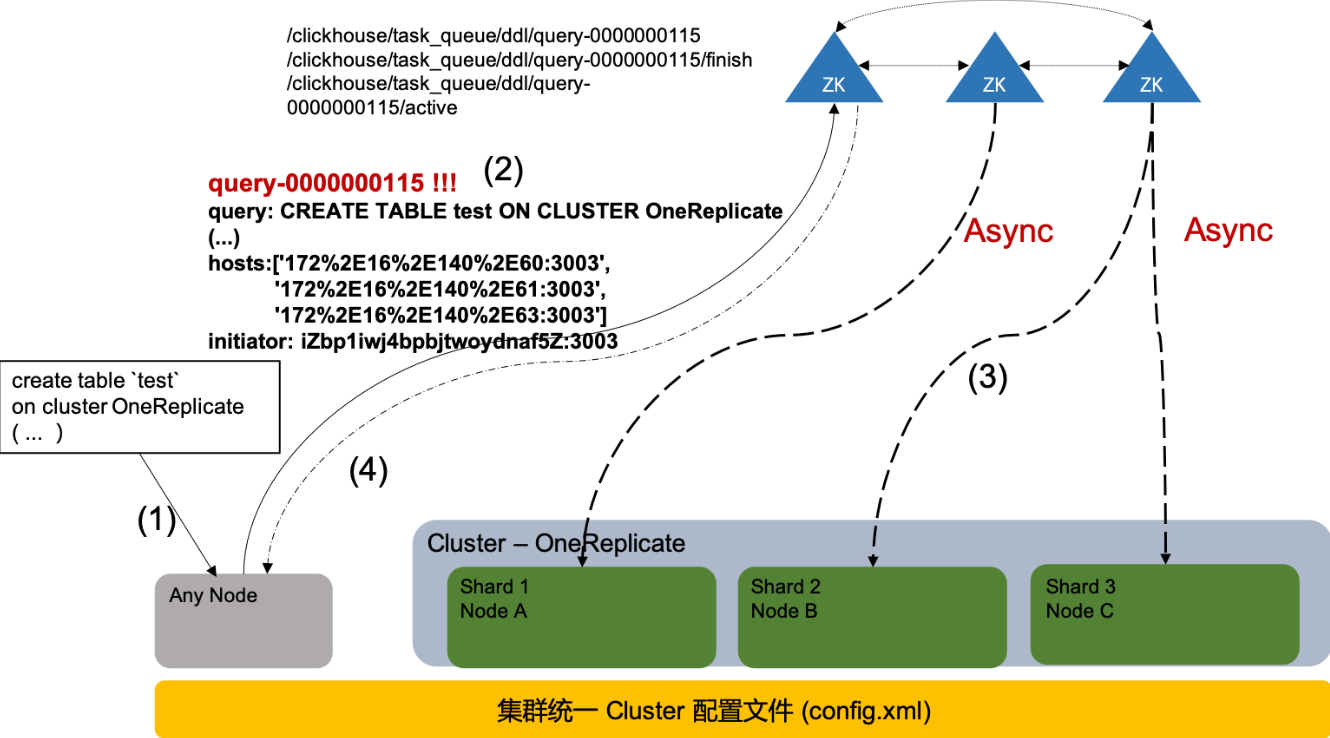
1)节点收到用户的分布式DDL请求;
2)节点校验分布式DDL请求合法性,在Zookeeper的任务队列中创建Znode并上传DDL LogEntry(示例中为query-0000000115),同时在LogEntry的Znode下创建active和finish两个状态同步的Znode;
3)Cluster中的节点后台线程消费Zookeeper中的LogEntry队列执行处理逻辑,处理过程中把自己注册到acitve Znode下,并把处理结果写回到finish Znode下;
4)用户的原始请求节点,不断轮询LogEntry Znode下的active和finish状态Znode,当目标节点全部执行完成任务或者触发超时逻辑时,用户就会获得结果反馈;
这个分发逻辑中有个值得注意的点:分布式DDL执行链路中有超时逻辑,如果触发超时用户将无法从客户端返回中确定最终执行结果,需要自己去Zookeeper上cheCK节点返回结果(也可以通过system.zookeeper系统表查看)。每个节点只有一个后台线程在消费执行DDL任务,碰到某个DDL任务(典型的是optimize任务)执行时间很长时,会导致DDL任务队列积压从而产生大面积的超时反馈。3.5.4 DDL Query Task执行和清理
节点的后台线程在处理一个DDL LogEntry Task时,首先会检查自己是否在DDL LogEntry的目标hosts中,这样可以区分出不同Cluster上的DDL任务,在具体执行DDL之前把自己注册到active Znode下,执行完成DDL之后会把返回结果包括异常信息写回到finish Znode下。
具体的DDL任务执行逻辑还是复用单节点上的执行逻辑,节点之间在处理DDL任务时互不感知。但是在ReplicatedMergeTree表引擎上有一些差异,ReplicatedMergeTree表引擎上的Alter、Optimize、Truncate命令都只在主副本节点上执行,备副本节点拿到这类DDL任务时会直接丢弃掉,主副本节点在执行的过程中也会使用Zookeeper分布式锁锁住这个任务再执行。因为ReplicatedMergeTree表引擎上的数据修改链路有自己内部的一套机制保证主备相互同步,这样避免了破坏主备之间的同步逻辑。下一章会详细讲ReplicatedMergeTree表主备之间的同步问题。
每个节点后台除了一个DDL任务消费线程外,还有一个过期DDL任务清理线程。清理线程会根据DDL任务队列的容量以及过期时间来清理以及全部完成的任务,清理过程中依旧会使用基于Zookeeper实现的分布式锁进行保护。3.5.5 DDL Query Task状态收集
用户请求节点会不断轮训DDL LogEntry Znode下的active Znode和finish Znode,拉取执行状态,随着轮训次数的增加线程不断增加sleep时间,最后等到超时或者全部节点完成任务才把统计信息返回给客户端。到这里整个分布式DDL执行链路就已经全部完成啦,可以看出Zookeeper在分布式DDL执行过程中主要充当DDL Task的分发、串行化执行、结果收集的一致性介质。分布式DDL功能对Zookeeper不会造成很大的性能压力,多个ClickHouse集群可以共享同一套Zookeeper来完成分布式DDL任务。最后ClickHouse虽然用Zookeeper解决了分布式DDL串行化执行的问题,但是目前还没有实现两阶段提交的逻辑,用户需要注意分布式DDL如果失败可能会导致节点间的状态不一致。
3.5.6 ReplicatedMergeTree主备同步
上一章介绍的分布式DDL功能对Zookeeper的依赖情况还是比较轻量级的,接下来介绍的ReplicatedMergeTree表引擎对Zookeeper的依赖可以说是所有表操作全方面的依赖,真实集群中大量的ReplicatedMergeTree表会对Zookeeper造成非常大的请求压力,需要用户关注Zookeeper的运维。
ReplicatedMergeTree表引擎实现的主备同步和传统主备同步有很大的差异:1)它不是一个(抢主,主节点执写入更新,备节点同步follow)的模型,ClickHouse的主节点和备节点都可以写,同步是双向的;2)它不是物理同步,ClickHouse没有基于物理文件的WAL;3)它的逻辑同步日志粒度是MergeTree的Data Part级别的(没有单条记录的同步日志),包含Data Part的增、删、改。ReplicatedMergeTree表的Data Part Log主要包含以下几类:
enum Type
{
EMPTY, /// Not used.
GET_PART, /// Get the part from another replica.
MERGE_PARTS, /// Merge the parts.
DROP_RANGE, /// Delete the parts in the specified partition in the specified number range.
CLEAR_COLUMN, /// Drop specific column from specified partition.
CLEAR_INDEX, /// Drop specific index from specified partition.
REPLACE_RANGE, /// Drop certain range of partitions and replace them by new ones
MUTATE_PART, /// Apply one or several mutations to the part.
};
这些类型的Log中部分只有主节点可以生成(”MERGE_PARTS”),部分是主备节点都可以生成的(”GET_PART”)。”GET_PART”日志是节点数据写入时产生的,且主备节点都可以写,每个节点写入数据后上传一个”GET_PART”日志到Zookeeper通知其他副本节点从自己这里下载数据。这里大家可能会疑惑:既然主备节点都可以写入,那为什么主备节点不能独立进行merge或者mutation?我认为核心原因有两个:
1)降低代码逻辑复杂度,MergeTree表引擎有两类后台异步任务(Merge/Mutation),同时又有所有节点可写的设定,这两个逻辑融合到一起的话复杂度会爆炸,ClickHouse的内核实现中是把写入和异步动作的链路完全解耦开的。主节点负责分发各种异步任务到Zookeeper上的任务队列,Shard下的所有节点观察任务队列进行follow执行。当万一某个其他节点上的数据和主节点不一致无法完成某个异步任务时,还有保底方法是让它直接从主节点去下载完成merge / mutation的Data Part。
2)MergeTree结构的表引擎有众多的变种merge逻辑(ReplacingMergeTree、CollapsingMergeTree等),再加上异步mutation的机制,多副本之间独立merge / mutation的话,副本间的数据视图同步进度就会完全失控(用户可能需要停写很长时间再加上手动Optimize才能达到副本间一致)。
上一篇系列文章中,我介绍过MergeTree表对Data Part的管理方式,要实现基于Data Part Log的同步,首先要确保节点之间的Data Part有统一的命名体系,而决定Data Part命名的核心因素是每一批数据写入时被赋予的bloCKNumber(数据的写入版本号),ClickHouse的写入链路利用了Zookeeper来生成全局一致的bloCKNumber序列。其次为了数据一致性保证,ClickHouse把ReplacingMergeTree表引擎中的所有Data Parts都注册到了Zookeeper上(包括它们的列信息和cheCKsum),最终本地数据都要以Zookeeper上的状态为准。3.5.7 ReplicatedMergeTree同步写入
ReplicatedMergeTree的写入链路分为三步:
1)把数据写入到本地的临时Data Part中,
2)从Zookeeper上申请自增的bloCKNumber序列号,
3)commit临时Data Part,生成一条”GET_PART”的同步日志上传到Zookeeper任务队列中。和分布式DDL执行任务队列不同,每一个ReplicatedMergeTree表引擎在Zookeeper上都有一个独立的Znode,这个Znode的路径可以在建表示配置。下图展示了示例dm_t_pecust_lab_part表的Znode目录结构,每个Shard和Replicate逻辑都有自己独立的目录空间。
一次常规的ReplicatedMergeTree批量写入首先会把写入的数据按照数据分区进行拆分,然后依次处理拆分后的每个数据BloCK。把数据BloCK写入到存储的临时Data Part后,ClickHouse需要从Zookeeper中获取下一个全局的bloCKNumber,这部分逻辑主要在StorageReplicatedMergeTree::allocateBloCKNumber函数中,核心是调用Zookeeper生成一个Ephemeral Sequential Znode来获取全局唯一的序列(这里的”全局”是单个数据分区级别唯一,跨数据分区是可以重合的)。最后是commit这个Data Part,commit的过程需要完成一系列的”检查动作”最后上传一个”GET_PART”类型的Log到Shard对应的Zookeeper目录下的的log Znode下,其他副本通过观察Zookeeper会异步来拷贝写入的Data Part。前序的”检查动作”目前包括,检查本地表的meta(列信息)版本是否已经落后于Zookeeper上的状态,注册写入Data Part的columns信息和cheCKsums到Data Part的Znode下。从这里可以看出一次Batch写入的过程和Zookeeper交互的次数不下10次,要是Batch数据跨10个数据分区的话那就是100次。老话重提一下:使用ClickHouse时一定要做Batch写入并且按照数据分区提前聚合。
两阶段提交的设计中,有个普遍问题是往Zookeeper上提交”GET_PART” Log时zk session断开或者超时了怎么办?本地的Data Part是Commit还是RollbaCK?ClickHouse在这里的解法是Commit Data Part,并抛错给用户重试写入数据,同时把Data Part丢到一个异步检查线程的任务队列中,异步检查线程会等待重连Zookeeper,检查本地的Data Part是否注册在Zookeeper上,如果没有则会移除本地的Data Part。相当于一个异步的数据修复保护手段,在其他两阶段提交链路中碰到相同的问题也都是依赖这个异步检查线程来进行修复。具体的异步检查线程代码在ReplicatedMergeTreePartCheCKThread::run函数中,有兴趣的同学可以仔细看一下这块代码。
ReplicatedMergeTree的写入链路有关的还有几个开关值得注意:
use_minimalistic_part_header_in_zookeeper,这是一个降低Zookeeper压力的配置(默认关闭)。开启之后每个新写入的Data Part不再注册自己的columns信息和cheCKsums到Zookeeper上。而是压缩成Hash值写到Data Part的Znode data中。
insert_quorum,这个开关会强迫写入链路检查数据同步的副本数达到要求才能成功返回(默认是0)。开启之后写入节点在Commit Data Part时还会创建一个Shard级别的quorum/status Znode,其他节点同步完数据之后需要更新到quorum/status,写入节点这边通过Watch机制收到通知再返回客户的写入请求。这个开关不建议开启的,因为写入链路的RT肯定会明显上升,同时因为quorum/status Znode是Shard级别创建,不能再多个副本并行写入。
insert_deduplicate,简单实用的数据去重功能(默认开启)。ClickHouse会对每次收到的批量写入数据计算一个Hash Value,然后注册到Zookeeper上。后续如果出现完全重复的一批数据,写入链路上会出现Zookeeper创建重复节点异常,用户就会收到重复写入反馈。当然批量写入的Hash Value保存是有窗口大小限制的,有统一的异步后台线程会清理这些Zookeeper上的过期记录,清理的逻辑代码在ReplicatedMergeTreeCleanupThread::run函数中,有兴趣的同学可以仔细看一下这块代码。3.5.8 ReplicatedMergeTree异步Task
介绍完ReplicatedMergeTree的整个同步写入过程,接下来就是多副本之间的异步同步过程了,ClickHouse为每个ReplicatedMergeTree表引擎实例创建了非常多的异步Task,所有Data Part的生命周期管理由这些异步Task共同完成。因为文章篇幅原因下面只会依次简单介绍每个Task所做的事情以及其中逻辑特别复杂的点,希望读者对ReplicatedMergeTree主备同步的逻辑复杂度有一个简单的了解:
StorageReplicatedMergeTree::queueUpdatingTask
同步Zookeeper中Shard级别下的Data Part Log任务队列数据到自己的Znode任务队列中,同时在自己的Znode下维护更新当前正在处理的logpointer(当前已经拷贝过的最大log Id)和min_unprocessed_insert_time(近似评估写入的延迟时间)信息,最后会把任务放到节点的RAM队列中。从Shard级别的公共任务队列迁移数据到节点自己的任务队列,核心问题是高频写入时公共任务队列里的任务发布会非常频繁,需要尽快清理公共队列,防止公共任务队列膨胀,因为所有节点都在轮训读取公共队列(Zookeeper的任务队列无法增量读取)。
StorageReplicatedMergeTree::mutationsUpdatingTask
从Zookeeper的Shard级别下的Mutation任务队列同步数据到节点的RAM状态中,这里没有再为每个节点维护自己的内部Znode队列,Mutation是相对低频的操作,公共的任务队列不会有数据积压。另一个问题是Mutation操作如此低频,ClickHouse如何调度Task运行呢?这里核心的机制也是依赖Zookeeper的Watch机制来通知ClickHouse的BaCKgroundSchedulePool调度起工作Task,包括上一个queueUpdatingTask也是相同机制被调度。
StorageReplicatedMergeTree::queueTask
上面两个Task都是从Zookeeper中同步任务到RAM的任务队列中,而且Task都是单线程调度执行。queueTask则是负责从RAM任务队列中消费执行具体的操作,并且会有多个后台线程被调度起并行执行多个任务。由于queueTask会被并行执行,运行的过程中有一个问题是如何从RAM中的任务队列里找到下一个要执行的任务?如果Task A是merge Data Part 1 和 Data Part 2, 而Data Part 2的下载任务正在另一个线程中执行,这时Task A就不能调度执行。ClickHouse在RAM状态中追踪了所有正在执行的任务即将产生和依赖的Data Part,可以保证有数据依赖关系的任务串行化执行。对于”GET_PART”类型的任务,Task执行逻辑会尝试从远端节点下载数据到本地,同时如果有quorum数量要求的话更新quorum统计信息。这里ClickHouse对节点下载远端数据的并行数做了控制,详见参数replicated_max_parallel_fetches、replicated_max_parallel_fetches_for[table|host]。
对于”MERGE_PARTS”,”MUTATE_PART”的任务,节点首先会尝试在本地进行实际的merge或者mutation动作,但是当本地的Input Data Part存在缺失或者损坏时,ClickHouse可以采用保守策略:尝试从远端下载merge完成的Data Part。当Input Data Part的数据量很大同时这个任务创建时间又很长时(远端大概率已经存在Output Data Part),ClickHouse会直接选择从远端下载的策略来跳过本地merge / mutation加速任务执行。在大规模数据场景下,每次merge、mutation的开销都是非常大的,配置只选择主副本完成merge、mutation任务,而让其他副本直接从远程下载可以大幅减轻集群的负载。
当一些极端场景出现,远端的结果Data Part N也无法下载时(一般是这个任务对应的远端Data Part N再次发生了数据变更变成了Data Part M),节点会把当前这个任务放回到任务队列的尾端,让它延迟执行,然后等待生成Data Part M的任务到来,只要从远端直接下载到Data Part M,通过Merge Tree的版本机制节点就可以直接跳过生成Data Part N的任务,因为这个任务生成的数据已经“过时”了,可以直接忽略。
StorageReplicatedMergeTree::mergeSelectingTask
这个Task的只有主副本节点会调度,它负责不断选择下一次要进行merge / mutation的Data Parts,把具体的merge / mutation的任务日志发布到Zookeeper的任务队列上。主节点在选择需要merge的Data Parts时,主体逻辑和上一篇系列文章中提到的MergeTree表的启发式挑选规则一致,唯一有一点不同的是这里还需要去从Zookeeper上获取实时写入数据的同步状态的,新写入的Data Part只有同步到全部副本节点后才可以参与merge。mergeSelectingTask是一个后台的任务发布者(上一节中的数据写入链路也会发布任务),而queueUpdatingTask和mutationsUpdating Task作为任务消费者会把任务拉到节点的RAM任务队列中,最后由queueTask去执行RAM队列里的任务。以上4个Task配合完成了ReplicatedMergeTree最核心的主备异步同步逻辑。实际上这4个Task在运行的过程中,存在着数据依赖关系,彼此之间会有一些同步调用或者异步唤醒调度的逻辑,这里不再展开讲这个调度流程。
StorageReplicatedMergeTree::movePartsTask
这个异步Task主要是配合ClickHouse的存储分层设计,当高性能(SDD)的存储空间快用满时,它会不断自动地把数据往更低级(HDD)的存储上去迁移。当前Task是每个节点独立工作,不感知主备状态,不需要和Zookeeper交互。但是后续如果要做基于DFS(分布式文件系统)的存储分层的话,Data Part迁移的逻辑也会需要考虑主备状态的问题,同个Data Part只需要迁移一次。基于DFS的存储分层功能实现代价还比较高,因为ClickHouse中没有File System层面的抽象设计,估计社区也不会很快支持。
StorageReplicatedMergeTree::mutationsFinalizingTask
这个Task的作用是异步去更新当前副本的mutation任务队列执行进度,它需要检查当前节点中所有的Data Part以及正在同步的Data Part的数据版本都以及超过mutation。
ReplicatedMergeTree表引擎中除了上述的一些异步Task在调度运行之外,还有一些后台线程在一直工作:ReplicatedMergeTreeCleanupThread是负责清理Zookeeper上的过期数据,上述所有异步Task在Zookeeper上的过期数据都由该线程统一清理。
- ReplicatedMergeTreeAlterThread是负责监听Zookeeper上Shard级别的表列信息变更,并执行实际的Alter操作。在ReplicatedMergeTree表上的Alter操作流程和第一节中将的分布式DDL执行很像,当某个副本节点收到Alter命令时,它就现在本地完成Alter操作,然后把新的表结构版本发布到Zookeeper上,等待其他副本follow执行。
- ReplicatedMergeTreePartCheCKThread是专门处理在两阶段提交过程中如何和Zookeeper失联,就把对应的Data Part丢到一个异步CheCK队列里,由这个线程去延迟检查和Zookeeper的状态是否一致并修复数据。
- ReplicatedMergeTreeRestartingThread负责在Zookeeper上的心跳注册管理。
这一章中讲到的所有ReplicatedMergeTree表引擎的异步Task以及在Zookeeper上的任务队列、心跳注册、状态存储都是ReplicatedMergeTree表级别独立的,集群里的ReplicatedMergeTree表数量、副本数量、写入流量都会影响Zookeeper的服务压力(压力山大),这也是ClickHouse在表引擎级别实现副本逻辑的代价。大家在大规模集群环境中需要谨慎运维Zookeeper。最后ClickHouse在引入异步Mutation机制之后,对副本同步链路的复杂度有比较大的影响,mutation和merge的处理逻辑最大的不同是mutation一次涉及的Input Data Parts几乎是全表,它不能像merge任务一样一次把所有的Input转化到Output,mutation任务需要对Input Data Parts拆分进行挨个操作,任务执行的生命周期特别长,并且Input Data Parts可能动态变化。
3.6 ClickHouse内核分析—MergeTree的存储结构和查询加速
ClickHouse是最近比较火的一款开源列式存储分析型数据库,它最核心的特点就是极致存储压缩率和查询性能,本人最近正在学习ClickHouse这款产品中。从我个人的视角来看存储是决定一款数据库核心竞争力、适用场景的关键所在,所以接下来我会陆续推出一系列文章来分析ClickHouse中最重要的MergeTree存储内核。本文主旨在于介绍MergeTree的存储格式,并且彻底剖析MergeTree存储的极致检索性能。
3.6.1 MergeTree思想
提到MergeTree这个词,可能大家都会联想到LSM-Tree这个数据结构,我们常用它来解决随机写磁盘的性能问题,MergeTree的核心思想和LSM-Tree相同。MergeTree存储结构需要对用户写入的数据做排序然后进行有序存储,数据有序存储带来两大核心优势:
• 列存文件在按块做压缩时,排序键中的列值是连续或者重复的,使得列存块的数据压缩可以获得极致的压缩比。
• 存储有序性本身就是一种可以加速查询的索引结构,根据排序键中列的等值条件或者range条件我们可以快速找到目标行所在的近似位置区间(下文会展开详细介绍),而且这种索引结构是不会产生额外存储开销的。
大家可以从ClickHouse的官方文档上找到一系列的MergeTree表引擎,包括基础的MergeTree,拥有数据去重能力的ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree,拥有数据聚合能力的SummingMergeTree、AggregatingMergeTree等。但这些拥有“特殊能力”的MergeTree表引擎在存储上和基础的MergeTree其实没有任何差异,它们都是在数据Merge的过程中加入了“额外的合并逻辑”,这部分会在后续介绍MergeTree异步Merge机制的文章中详细展开介绍。
3.6.2 MergeTree存储结构
为了方便大家理解表的存储结构,下面列举了某个POC用户的测试表DDL,我们将从这个表入手来分析MergeTree存储的内核设计。从DDL的PARTITION BY申明中我们可以看出用户按每个区服每小时粒度创建了数据分区,而每个数据分区内部的数据又是按照(action_id, scene_id, time_ts, level, uid)作为排序键进行有序存储。
CREATE TABLE user_action_log (
time DateTime DEFAULT CAST(‘1970-01-01 08:00:00’, ‘DateTime’) COMMENT ‘日志时间’,
action_id UInt16 DEFAULT CAST(0, ‘UInt16’) COMMENT ‘日志行为类型id’,
action_name String DEFAULT ‘’ COMMENT ‘日志行为类型名’,
region_name String DEFAULT ‘’ COMMENT ‘区服名称’,
uid UInt64 DEFAULT CAST(0, ‘UInt64’) COMMENT ‘用户id’,
level UInt32 DEFAULT CAST(0, ‘UInt32’) COMMENT ‘当前等级’,
trans_no String DEFAULT ‘’ COMMENT ‘事务流水号’,
ext_head String DEFAULT ‘’ COMMENT ‘扩展日志head’,
avatar_id UInt32 DEFAULT CAST(0, ‘UInt32’) COMMENT ‘角色id’,
scene_id UInt32 DEFAULT CAST(0, ‘UInt32’) COMMENT ‘场景id’,
time_ts UInt64 DEFAULT CAST(0, ‘UInt64’) COMMENT ‘秒单位时间戳’,
index avatar_id_minmax (avatar_id) type minmax granularity 3
) ENGINE = MergeTree()
PARTITION BY (toYYYYMMDD(time), toHour(time), region_name)
ORDER BY (action_id, scene_id, time_ts, level, uid)
PRIMARY KEY (action_id, scene_id, time_ts, level);
该表的MergeTree存储结构逻辑示意图如下: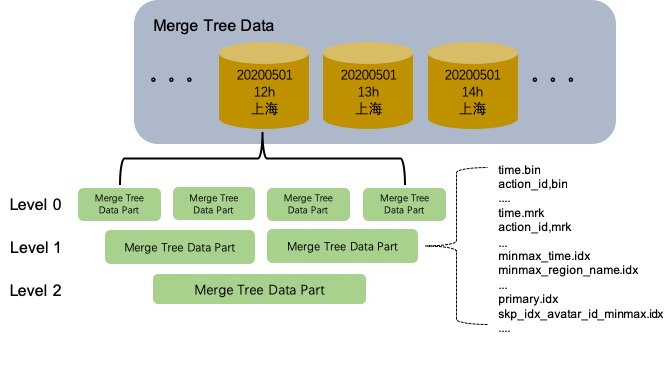
MergeTree表的存储结构中,每个数据分区相互独立,逻辑上没有关联。单个数据分区内部存在着多个MergeTree Data Part。这些Data Part一旦生成就是Immutable的状态,Data Part的生成和销毁主要与写入和异步Merge有关。MergeTree表的写入链路是一个极端的batch load过程,Data Part不支持单条的append insert。每次batch insert都会生成一个新的MergeTree Data Part。如果用户单次insert一条记录,那就会为那一条记录生成一个独立的Data Part,这必然是无法接受的。一般我们使用MergeTree表引擎的时候,需要在客户端做聚合进行batch写入或者在MergeTree表的基础上创建Distributed表来代理MergeTree表的写入和查询,Distributed表默认会缓存用户的写入数据,超过一定时间或者数据量再异步转发给MergeTree表。MergeTree存储引擎对数据实时可见要求非常高的场景是不太友好的。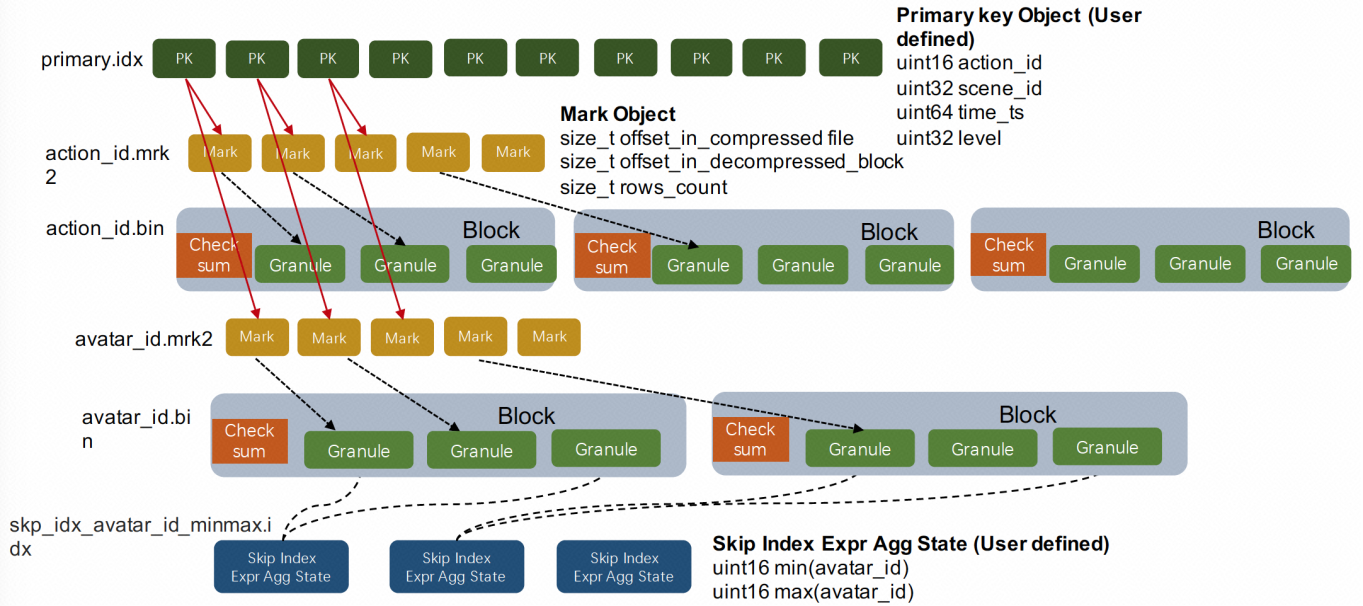
上图展示了单个MergeTree Data Part里最核心的一部分磁盘文件(只画了action_id和avatar_id列其关的存储文件),从功能上分主要有三个类:
1 数据文件:action_id.bin、avatar_id.bin等都是单个列按块压缩后的列存文件。ClickHouse采用了非常极端的列存模式,这里展开一些细节,单个列数据可能会对应多个列存文件,例如申明一个Nullable字段时会多一个nullable标识的列存文件,申明一个Array字段时会多一个array size的列存文件, 采用字典压缩时字典Key也会单独变成一个列存文件。有一点小Tips:当用户不需要Null值特殊标识时,最好不要去申明Nullable,这是ClickHouse的极简化设计思路。
2 Mark标识文件:action_id.mrk2、avatar_id.mrk2等都是列存文件中的Mark标记,Mark标记和MergeTree列存中的两个重要概念相关:Granule和BloCK。
- Granule是数据按行划分时用到的逻辑概念。关于多少行是一个Granule这个问题,在老版本中这是用参数index_granularity设定的一个常量,也就是每隔确定行就是一个Granule。在当前版本中有另一个参数index_granularity_bytes会影响Granule的行数,它的意义是让每个Granule中所有列的sum size尽量不要超过设定值。老版本中的定长Granule设定主要的问题是MergeTree中的数据是按Granule粒度进行索引的,这种粗糙的索引粒度在分析超级大宽表的场景中,从存储读取的data size会膨胀得非常厉害,需要用户非常谨慎得设定参数。
- BloCK是列存文件中的压缩单元。每个列存文件的BloCK都会包含若干个Granule,具体多少个Granule是由参数min_compress_bloCK_size控制,每次列的BloCK中写完一个Granule的数据时,它会检查当前BloCK Size有没有达到设定值,如果达到则会把当前BloCK进行压缩然后写磁盘。
- 从以上两点可以看出MergeTree的BloCK既不是定data size也不是定行数的,Granule也不是一个定长的逻辑概念。所以我们需要额外信息快速找到某一个Granule。这就是Mark标识文件的作用,它记录了每个Granule的行数,以及它所在的BloCK在列存压缩文件中的偏移,同时还有Granule在解压后的BloCK中的偏移位置。
3主键索引:primary.idx是表的主键索引。ClickHouse对主键索引的定义和传统数据库的定义稍有不同,它的主键索引没用主键去重的含义,但仍然有快速查找主键行的能力。ClickHouse的主键索引存储的是每一个Granule中起始行的主键值,而MergeTree存储中的数据是按照主键严格排序的。所以当查询给定主键条件时,我们可以根据主键索引确定数据可能存在的Granule Range,再结合上面介绍的Mark标识,我们可以进一步确定数据在列存文件中的位置区间。CliCKHoue的主键索引是一种在索引构建成本和索引效率上相对平衡的粗糙索引。MergeTree的主键序列默认是和Order By序列保存一致的,但是用户可以把主键序列定义成Order By序列的部分前缀。
4分区键索引:minmax_time.idx、minmax_region_name.idx是表的分区键索引。MergeTree存储会把统计每个Data Part中分区键的最大值和最小值,当用户查询中包含分区键条件时,就可以直接排除掉不相关的Data Part,这是一种OLAP场景下常用的分区裁剪技术。
5Skipping索引:skp_idx_avatar_id_minmax.idx是用户在avatar_id列上定义的MinMax索引。Merge Tree中 的Skipping Index是一类局部聚合的粗糙索引。用户在定义skipping index的时候需要设定granularity参数,这里的granularity参数指定的是在多少个Granule的数据上做聚合生成索引信息。用户还需要设定索引对应的聚合函数,常用的有minmax、set、bloom_filter、ngrambf_v1等,聚合函数会统计连续若干个Granule中的列值生成索引信息。Skipping索引的思想和主键索引是类似的,因为数据是按主键排序的,主键索引统计的其实就是每个Granule粒度的主键序列MinMax值,而Skipping索引提供的聚合函数种类更加丰富,是主键索引的一种补充能力。另外这两种索引都是需要用户在理解索引原理的基础上贴合自己的业务场景来进行设计的。
3.6.3 MergeTree查询
这一章主要会结合ClickHouse的源码为大家分析MergeTree表引擎上的数据查询过程,我大致把这个过程分为两块:索引检索和数据扫描。索引检索部分对每个MergeTree Data Part是串行执行,但Data Part之间的检索没有任何关联。而在数据扫描部分中最底层的列存扫描是多所有Data Part并行执行,各Data Part的列存扫描之间也没有任何关联。
3.6.4 索引检索
MergeTree存储在收到一个select查询时会先抽取出查询中的分区键和主键条件的KeyCondition,KeyCondition类上实现了以下三个方法,用于判断过滤条件可能满足的Mark Range。上一章讲过MergeTree Data Part中的列存数据是以Granule为粒度被Mark标识数组索引起来的,而Mark Range就表示Mark标识数组里满足查询条件的下标区间。
/// Whether the condition is feasible in the key range.
/// left_key and right_key must contain all fields in the sort_descr in the appropriate order.
/// data_types - the types of the key columns.
bool mayBeTrueInRange(sizet used_key_size, const Field left_key, const Field right_key, const DataTypes & data_types) const;
/// Whether the condition is feasible in the direct product of single column ranges specified by parallelogram.
bool mayBeTrueInParallelogram(const std::vector
/// leftkey must contain all the fields in the sort_descr in the appropriate order.
bool mayBeTrueAfter(size_t used_key_size, const Field * left_key, const DataTypes & data_types) const;
索引检索的过程中首先会用分区键KeyCondition裁剪掉不相关的数据分区,然后用主键索引挑选出粗糙的Mark Range,最后再用Skipping Index过滤主键索引产生的Mark Range。用主键索引挑选出粗糙的Mark Range的算法是一个不断分裂Mark Range的过程,返回结果是一个Mark Range的集合。起始的Mark Range是覆盖整个MergeTree Data Part区间的,每次分裂都会把上次分裂后的Mark Range取出来按一定粒度步长分裂成更细粒度的Mark Range,然后排除掉分裂结果中一定不满足条件的Mark Range,最后Mark Range到一定粒度时停止分裂。这是一个简单高效的粗糙过滤算法。
使用Skipping Index过滤主键索引返回的Mark Range之前,需要构造出每个Skipping Index的IndexCondition,不同的Skipping Index聚合函数有不同的IndexCondition实现,但判断Mark Range是否满足条件的接口和KeyCondition是类似的。
3.6.5 数据Sampling
经过上一小节的索引过滤之后,我们已经得到了需要扫描的Mark Range集合,接下来就应该是数据扫描部分了。这一小节插入简单讲一下MergeTree里的数据Sampling是如何实现的。它并不是在数据扫描过程中实现的,而是在索引检索的过程中就已经完成,这种做法是为了极致的sample效率。用户在建表的时候可以指定主键中的某个列或者表达式作为Sampling键,ClickHouse在这里用了简单粗暴的做法:Sampling键的值必须是数值类型的,并且系统假定它的值是随机均匀分布的一个状态。如果Sampling键的值类型是Uint32,当我们设定sample比率是0.1的时候,索引检索过程中会把sample转换成一个filter条件:Sampling键的值 < Uint32::max * 0.1。用户在使用Sampling功能时必须清楚这个细节,不然容易出现采样偏差。一般我们推荐Sampling键是列值加一个Hash函数进行随机打散。
3.6.6 数据扫描
MergeTree的数据扫描部分提供了三种不同的模式:
- Final模式:该模式对CollapsingMergeTree、SummingMergeTree等表引擎提供一个最终Merge后的数据视图。前文已经提到过MergeTree基础上的高级MergeTree表引擎都是对MergeTree Data Part采用了特定的Merge逻辑。它带来的问题是由于MergeTree Data Part是异步Merge的过程,在没有最终Merge成一个Data Part的情况下,用户无法看到最终的数据结果。所以ClickHouse在查询是提供了一个final模式,它会在各个Data Part的多条BloCKInputStream基础上套上一些高级的Merge Stream,例如DistinctSortedBloCKInputStream、SummingSortedBloCKInputStream等,这部分逻辑和异步Merge时的逻辑保持一致,这样用户就可以提前看到“最终”的数据结果了。
- Sorted模式:sort模式可以认为是一种order by下推存储的查询加速优化手段。因为每个MergeTree Data Part内部的数据是有序的,所以当用户查询中包括排序键order by条件时只需要在各个Data Part的BloCKInputStream上套一个做数据有序归并的InputStream就可以实现全局有序的能力。
- Normal模式:这是基础MergeTree表最常用的数据扫描模式,多个Data Part之间进行并行数据扫描,对于单查询可以达到非常高吞吐的数据读取。
- 接下来展开介绍下Normal模式中几个关键的性能优化点:
- 并行扫描:传统的计算引擎在数据扫描部分的并发度大多和存储文件数绑定在一起,所以MergeTree Data Part并行扫描是一个基础能力。但是MergeTree的存储结构要求数据不断mege,最终合并成一个Data Part,这样对索引和数据压缩才是最高效的。所以ClickHouse在MergeTree Data Part并行的基础上还增加了Mark Range并行。用户可以任意设定数据扫描过程中的并行度,每个扫描线程分配到的是Mark Range In Data Part粒度的任务,同时多个扫描线程之间还共享了Mark Range Task Pool,这样可以避免在存储扫描中的长尾问题。
- 数据Cache:MergeTree的查询链路中涉及到的数据有不同级别的缓存设计。主键索引和分区键索引在load Data Part的过程中被加载到内存,Mark文件和列存文件有对应的MarkCache和UncompressedCache,MarkCache直接缓存了Mark文件中的binary内容,而UncompressedCache中缓存的是解压后的BloCK数据。
- SIMD反序列化:部分列类型的反序列化过程中采用了手写的sse指令加速,在数据命中UncompressedCache的情况下会有一些效果。
- PreWhere过滤:ClickHouse的语法支持了额外的PreWhere过滤条件,它会先于Where条件进行判断。当用户在sql的filter条件中加上PreWhere过滤条件时,存储扫描会分两阶段进行,先读取PreWhere条件中依赖的列值,然后计算每一行是否符合条件。相当于在Mark Range的基础上进一步缩小扫描范围,PreWhere列扫描计算过后,ClickHouse会调整每个Mark对应的Granule中具体要扫描的行数,相当于可以丢弃Granule头尾的一部分行。
3.7 ClickHouse内核分析-MergeTree的Merge和Mutation机制
3.7.1 引言
ClickHouse内核分析系列文章,继上一篇文章 MergeTree查询链路 之后,这次我将为大家介绍MergeTree存储引擎的异步Merge和Mutation机制。建议读者先补充上一篇文章的基础知识,这样会比较容易理解。3.7.2 MergeTree Mutation功能介绍
在上一篇系列文章中,我已经介绍过ClickHouse内核中的MergeTree存储一旦生成一个Data Part,这个Data Part就不可再更改了。所以从MergeTree存储内核层面,ClickHouse就不擅长做数据更新删除操作。但是绝大部分用户场景中,难免会出现需要手动订正、修复数据的场景。所以ClickHouse为用户设计了一套离线异步机制来支持低频的Mutation(改、删)操作。3.7.3 Mutation命令执行
ALTER TABLE [db.]table DELETE WHERE filter_expr;ALTER TABLE [db.]table UPDATE column1 = expr1 [, …] WHERE filter_expr;
ClickHouse的方言把Delete和Update操作也加入到了Alter Table的范畴中,它并不支持裸的Delete或者Update操作。当用户执行一个如上的Mutation操作获得返回时,ClickHouse内核其实只做了两件事情:
- 检查Mutation操作是否合法;
- 保存Mutation命令到存储文件中,唤醒一个异步处理merge和mutation的工作线程;
两者的主体逻辑分别在MutationsInterpreter::validate函数和StorageMergeTree::mutate函数中。
MutationsInterpreter::validate函数dry run一个异步Mutation执行的全过程,其中涉及到检查Mutation是否合法的判断原则是列值更新后记录的分区键和排序键不能有变化。因为分区键和排序键一旦发生变化,就会导致多个Data Part之间之间Merge逻辑的复杂化。剩余的Mutation执行过程可以看做是打开一个Data Part的BloCKInputStream,在这个BloCKStream的基础上封装删除操作的FilterBloCKInputStream,再加上更新操作的ExpressionBloCKInputStream,最后把数据通过BloCKOutputStream写回到新的Data Part中。这里简单介绍一下ClickHouse的计算层实现,整体上它是一个火山模型的计算引擎,数据的各种filer、投影、join、agg都是通过BloCKStrem抽象实现,在BloCKStream中数据是按照BloCK进行传输处理的,而BloCK中的数据又是按照列模式组织,这使得ClickHouse在单列的计算上可以批量化并使用一些SIMD指令加速。BloCKOutputStream承担了MergeTree Data Part列存写入和索引构建的全部工作,我会在后续的文章中会详细展开介绍ClickHouse计算层中各类功能的BloCKStream,以及BloCKOutputStream中构建索引的实现细节。
在Mutation命令的执行过程中,我们可以看到MergeTree会把整条Alter命令保存到存储文件夹下,然后创建一个MergeTreeMutationEntry对象保存到表的待修改状态中,最后唤醒一个异步处理merge和 mutation的工作线程。这里有一个关键的问题,因为Mutation的实际操作是异步发生的,在用户的Alter命令返回之后仍然会有数据写入,系统如何在异步订正的过程中排除掉Alter命令之后写入的数据呢?下一节中我会介绍MergeTree中Data Part的Version机制,它可以在Data Part级别解决上面的问题。但是因为ClickHouse写入链路的异步性,ClickHouse仍然无法保证Alter命令前Insert的每条纪录都被更新,只能确保Alter命令前已经存在的Data Part都会被订正,推荐用户只用来订正T+1场景的离线数据。
3.7.4 异步Merge&Mutation
3.7.5 Batch Insert和Mutation的数据一致性
struct MergeTreePartInfo
{
String partitionid;
Int64 min_bloCK = 0;
Int64 max_bloCK = 0;
UInt32 level = 0;
Int64 mutation = 0; /// If the part has been mutated or contains mutated parts, is equal to mutation version number.
…
/// Get bloCK number that can be used to determine which mutations we still need to apply to this part
/// (all mutations with version greater than this bloCK number)._
Int64 getDataVersion() const { return mutation ? mutation : min_bloCK; }
…
bool operator<(const MergeTreePartInfo & rhs) const
{
return std::forward_as_tuple(partition_id, min_bloCK, max_bloCK, level, mutation)
< std::forward_as_tuple(rhs.partition_id, rhs.min_bloCK, rhs.max_bloCK, rhs.level, rhs.mutation);
}
}
在具体展开MergeTree的异步merge和mutation机制之前,先需要详细介绍一下MergeTree中对Data Part的管理方式。每个Data Part都有一个MergeTreePartInfo对象来保存它的meta信息,MergeTreePartInfo类的结构如上方代码所示。
- partition_id:表示所属的数据分区id。
- min_bloCK、max_bloCK:bloCKNumber是数据写入的一个版本信息,在上一篇系列文章中讲过,用户每次批量写入的数据都会生成一个Data Part。同一批写入的数据会被assign一个唯一的bloCKNumber,而这个bloCKNumber是在MergeTree表级别自增的。以及MergeTree在merge多个Data Part的时候会准守一个原则:在同一个数据分区下选择bloCKNumber区间相邻的若干个Data Parts进行合并,不会出现在同一个数据分区下Data Parts之间的bloCKNumber区间出现重合。所以Data Part中的min_bloCK和max_bloCK可以表示当前Data Part中数据的版本范围。
- level:表示Data Part所在的层级,新写入的Data Part都属于level 0。异步merge多个Data Part的过程中,系统会选择其中最大的level + 1作为新Data Part的level。这个信息可以一定程度反映出当前的Data Part是经历了多少次merge,但是不能准确表示,核心原因是MergeTree允许多个Data Part跨level进行merge的,为了最终一个数据分区内的数据merge成一个Data Part。
- mutation:和批量写入数据的版本号机制类似,MergeTree表的mutation命令也会被assign一个唯一的bloCKNumber作为版本号,这个版本号信息会保存在MergeTreeMutationEntry中,所以通过版本号信息我们可以看出数据写入和mutation命令之间的先后关系。Data Part中的这个mutation表示的则是当前这个Data Part已经完成的mutation操作,对每个Data Part来说它是按照mutation的bloCKNumber顺序依次完成所有的mutation。
解释了MergeTreePartInfo类中的信息含义,我们就可以理解上一节中遗留的异步Mutation如何选择哪些Data Parts需要订正的问题。系统可以通过MergeTreePartInfo::getDataVersion() { return mutation ? mutation : min_bloCK }函数来判断当前Data Part是否需要进行某个mutation订正,比较两者version即可。
3.7.6 Merge&Mutation工作任务
ClickHouse内核中异步merge、mutation工作由统一的工作线程池来完成,这个线程池的大小用户可以通过参数baCKgroundpool_size进行设置。线程池中的线程Task总体逻辑如下,可以看出这个异步Task主要做三块工作:清理残留文件,merge Data Parts 和 mutate Data Part。
BaCKgroundProcessingPoolTaskResult StorageMergeTree::mergeMutateTask()
{
….
try
{
/// Clear old parts. It is unnecessary to do it more than once a second.
if (auto loCK = time_after_previous_cleanup.compareAndRestartDeferred(1))
{
{
/// TODO: Implement tryLoCKStructureForShare.
auto loCK_structure = loCKStructureForShare(false, “”);
clearOldPartsFromFilesystem();
clearOldTemporaryDirectories();
}
clearOldMutations();
}
///TODO: read deduplicate option from table config
if (merge(false /aggressive/, {} /partition_id/, false /final/, false /deduplicate/))
return BaCKgroundProcessingPoolTaskResult::SUCCESS;
if (tryMutatePart())
return BaCKgroundProcessingPoolTaskResult::SUCCESS;
return BaCKgroundProcessingPoolTaskResult::ERROR;
}
…
}
需要清理的残留文件分为三部分:过期的Data Part,临时文件夹,过期的Mutation命令文件。如下方代码所示,MergeTree Data Part的生命周期包含多个阶段,创建一个Data Part的时候分两阶段执行Temporary->Precommitted->Commited,淘汰一个Data Part的时候也可能会先经过一个Outdated状态,再到Deleting状态。在Outdated状态下的Data Part仍然是可查的。异步Task在收集Outdated Data Part的时候会根据它的shared_ptr计数来判断当前是否有查询Context引用它,没有的话才进行删除。清理临时文件的逻辑较为简单,在数据文件夹中遍历搜索”tmp“开头的文件夹,并判断创建时长是否超过temporarydirectories_lifetime。临时文件夹主要在ClickHouse的两阶段提交过程可能造成残留。最后是清理数据已经全部订正完成的过期Mutation命令文件。
enum class State
{
Temporary, /// the part is generating now, it is not in data_parts list
PreCommitted, /// the part is in data_parts, but not used for SELECTs Committed, /// active data part, used by current and upcoming SELECTs Outdated, /// not active data part, but could be used by only current SELECTs, could be deleted after SELECTs finishes
Deleting, /// not active data part with identity refcounter, it is deleting right now by a cleaner
DeleteOnDestroy, /// part was moved to another disk and should be deleted in own destructor
};_3.7.7 Merge逻辑
StorageMergeTree::merge函数是MergeTree异步Merge的核心逻辑,Data Part Merge的工作除了通过后台工作线程自动完成,用户还可以通过Optimize命令来手动触发。自动触发的场景中,系统会根据后台空闲线程的数据来启发式地决定本次Merge最大可以处理的数据量大小,max_bytes_to_merge_at_min_space_in_pool和max_bytes_to_merge_at_max_space_in_pool参数分别决定当空闲线程数最大时可处理的数据量上限以及只剩下一个空闲线程时可处理的数据量上限。当用户的写入量非常大的时候,应该适当调整工作线程池的大小和这两个参数。当用户手动触发merge时,系统则是根据disk剩余容量来决定可处理的最大数据量。
接下来介绍merge过程中最核心的逻辑:如何选择Data Parts进行merge?为了方便理解,这里先介绍一下Data Parts在MergeTree表引擎中的管理组织方式。上一节中提到的MergeTreePartInfo类中定义了比较操作符,MergeTree中的Data Parts就是按照这个比较操作符进行排序管理,排序键是(partition_id, min_bloCK, max_bloCK, level, mutation),索引管理结构如下图所示: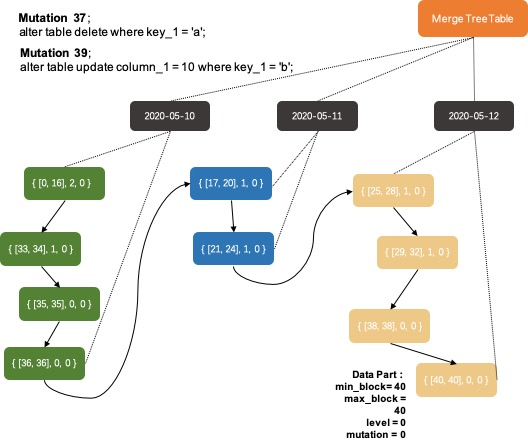
自动Merge的处理逻辑,首先是通过MergeTreeDataMergerMutator::selectPartsToMerge函数筛选出本次merge要合并的Data Parts,这个筛选过程需要准守三个原则:跨数据分区的Data Part之间不能合并;
- 合并的Data Parts之间必须是相邻(在上图的有序组织关系中相邻),只能在排序链表中按段合并,不能跳跃;
- 合并的Data Parts之间的mutation状态必须是一致的,如果Data Part A 后续还需要完成mutation-23而Data Part B后续不需要完成mutation-23(数据全部是在mutation命令之后写入或者已经完成mutation-23),则A和B不能进行合并;
- 所以我们上面的Data Parts组织关系逻辑示意图中,相同颜色的Data Parts是可以合并的。虽然图中三个不同颜色的Data Parts序列都是可以合并的,但是合并工作线程每次只会挑选其中某个序列的一小段进行合并(如前文所述,系统会限定每次合并的Data Parts的数据量)。对于如何从这些序列中挑选出最佳的一段区间,ClickHouse抽象出了IMergeSelector类来实现不同的逻辑。当前主要有两种不同的merge策略:TTL数据淘汰策略和常规策略。
- TTL数据淘汰策略:TTL数据淘汰策略启用的条件比较苛刻,只有当某个Data Part中存在数据生命周期超时需要淘汰,并且距离上次使用TTL策略达到一定时间间隔(默认1小时)。TTL策略也非常简单,首先挑选出TTL超时最严重Data Part,把这个Data Part所在的数据分区作为要进行数据合并的分区,最后会把这个TTL超时最严重的Data Part前后连续的所有存在TTL过期的Data Part都纳入到merge的范围中。这个策略简单直接,每次保证优先合并掉最老的存在过期数据的Data Part。
- 常规策略:这里的选举策略就比较复杂,基本逻辑是枚举每个可能合并的Data Parts区间,通过启发式规则判断是否满足合并条件,再有启发式规则进行算分,选取分数最好的区间。启发式判断是否满足合并条件的算法在SimpleMergeSelector.cpp::allow函数中,其中的主要思想分为以下几点:系统默认对合并的区间有一个Data Parts数量的限制要求(每5个Data Parts才能合并);如果当前数据分区中的Data Parts出现了膨胀,则适量放宽合并数量限制要求(最低可以两两merge);如果参与合并的Data Parts中有很久之前写入的Data Part,也适量放宽合并数量限制要求,放宽的程度还取决于要合并的数据量。第一条规则是为了提升写入性能,避免在高速写入时两两merge这种低效的合并方式。最后一条规则则是为了保证随着数据分区中的Data Part老化,老龄化的数据分区内数据全部合并到一个Data Part。中间的规则更多是一种保护手段,防止因为写入和频繁mutation的极端情况下,Data Parts出现膨胀。启发式算法的策略则是优先选择IO开销最小的Data Parts区间完成合并,尽快合并掉小数据量的Data Parts是对在线查询最有利的方式,数据量很大的Data Parts已经有了很较好的数据压缩和索引效率,合并操作对查询带来的性价比较低。
3.7.8 Mutation逻辑
StorageMergeTree::tryMutatePart函数是MergeTree异步mutation的核心逻辑,主体逻辑如下。系统每次都只会订正一个Data Part,但是会聚合多个mutation任务批量完成,这点实现非常的棒。因为在用户真实业务场景中一次数据订正逻辑中可能会包含多个Mutation命令,把这多个mutation操作聚合到一起订正效率上就非常高。系统每次选择一个排序键最小的并且需要订正Data Part进行操作,本意上就是把数据从前往后进行依次订正。
Mutation功能是MergeTree表引擎最新推出一大功能,从我个人的角度看在实现完备度上还有一下两点需要去优化:
- mutation没有实时可见能力。我这里的实时可见并不是指在存储上立即原地更新,而是给用户提供一种途径可以立即看到数据订正后的最终视图确保订正无误。类比在使用CollapsingMergeTree、SummingMergeTree等高级MergeTree引擎时,数据还没有完全merge到一个Data Part之前,存储层并没有一个数据的最终视图。但是用户可以通过Final查询模式,在计算引擎层实时聚合出数据的最终视图。这个原理对mutation实时可见也同样适用,在实时查询中通过FilterBloCKInputStream和ExpressionBloCKInputStream完成用户的mutation操作,给用户提供一个最终视图。
- mutation和merge相互独立执行。看完本文前面的分析,大家应该也注意到了目前Data Part的merge和mutation是相互独立执行的,Data Part在同一时刻只能是在merge或者mutation操作中。对于MergeTree这种存储彻底Immutable的设计,数据频繁merge、mutation会引入巨大的IO负载。实时上merge和mutation操作是可以合并到一起去考虑的,这样可以省去数据一次读写盘的开销。对数据写入压力很大又有频繁mutation的场景,会有很大帮助。
for (const auto & part : getDataPartsVector())
{
…
size_t current_ast_elements = 0;
for (auto it = mutations_begin_it; it != mutations_end_it; ++it)
{
MutationsInterpreter interpreter(shared_from_this(), it->second.commands, global_context);
size_t commands_size = interpreter.evaluateCommandsSize();
if (current_ast_elements + commands_size >= max_ast_elements)
break;
current_ast_elements += commands_size;
commands.insert(commands.end(), it->second.commands.begin(), it->second.commands.end());
}
auto new_part_info = part->info;
new_part_info.mutation = current_mutations_by_version.rbegin()->first;
future_part.parts.push_baCK(part);
future_part.part_info = new_part_info;
future_part.name = part->getNewName(new_part_info);
tagger.emplace(future_part, MergeTreeDataMergerMutator::estimateNeededDiskSpace({part}), *this, true);
break;
}
最后在经过后台工作线程一轮merge和mutation操作之后,上一节中展示的MergeTree表引擎中的Data Parts可能发生的变化如下图所示,2020-05-10数据分区下的头两个Data Parts被merge到了一起,并且完成了Mutation 37和Mutation 39的数据订正,新产生的Data Part如红色所示: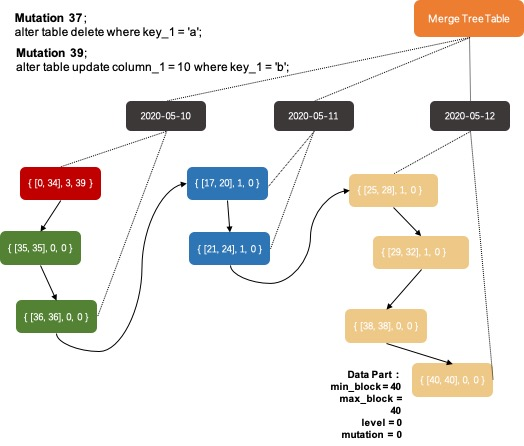
3.7.9 ClickHouse优化
4 ClickHouse应用案例篇
4.1 漏斗转化率分析
4.2 有连续N天销售记录的店铺
a,2020-02-05,200
a,2020-02-06,300
a,2020-02-07,200
a,2020-02-08,400
a,2020-02-10,600
a,2020-03-01,200
a,2020-03-02,300
a,2020-03-03,200
a,2020-03-04,400
a,2020-03-05,600
b,2020-02-05,200
b,2020-02-06,300
b,2020-02-08,200
b,2020-02-09,400
b,2020-02-10,600
c,2020-01-31,200
c,2020-02-01,300
c,2020-02-02,200
c,2020-02-03,400
c,2020-02-10,600
SELECT DISTINCT name
FROM
(
SELECT
name,
count() AS cc
FROM
(
SELECT
,
subtractDays(value, row_number) AS diff
FROM
(
SELECT
name,
value,
row_number
FROM
(
SELECT
name,
groupArray(dt) AS value_list,
arrayEnumerate(value_list) AS index_list
FROM
(
SELECT
FROM hdfs(‘hdfs://doit01:8020/data/shop/.csv’, CSV, ‘name String , dt Date , cost Int32’)
ORDER BY dt ASC
)
GROUP BY name
)
ARRAY JOIN
value_list AS value,
index_list AS row_number
ORDER BY name ASC
) AS t
) AS t2
GROUP BY
name,
diff
HAVING cc > 3
) AS t3

若有收获,就点个赞吧
0 人点赞
