1 Kafka概述
1.1 什么是Kafka
Apache Kafka是分布式发布-订阅消息系统(消息中间件)。它最初由LinkedIn公司开发,之后成为Apache项目的一部分。Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。
简单说明什么是Kafka:
举个例子,生产者消费者,生产者生产鸡蛋,消费者消费鸡蛋,生产者生产一个鸡蛋,消费者就消费一个鸡蛋,假设消费者消费鸡蛋的时候噎住了(系统宕机了),生产者还在生产鸡蛋,那新生产的鸡蛋就丢失了。再比如生产者很强劲(大交易量的情况),生产者1秒钟生产100个鸡蛋,消费者1秒钟只能吃50个鸡蛋,那要不了一会,消费者就吃不消了(消息堵塞,最终导致系统超时),消费者拒绝再吃了,”鸡蛋“又丢失了,这个时候我们放个篮子在它们中间,生产出来的鸡蛋都放到篮子里,消费者去篮子里拿鸡蛋,这样鸡蛋就不会丢失了,都在篮子里,而这个篮子就是”Kafka“。
鸡蛋其实就是“数据流”,系统之间的交互都是通过“数据流”来传输的(就是tcp、http什么的),也称为报文,也叫“消息”。
消息队列满了,其实就是篮子满了,”鸡蛋“ 放不下了,那赶紧多放几个篮子,其实就是Kafka的扩容。Kafka就是例子中的”篮子”。
传统消息中间件服务RabbitMQ、Apache ActiveMQ等。
Apache Kafka与传统消息系统相比,有以下不同:
- 它是分布式系统,易于向外扩展;
- 它同时为发布和订阅提供高吞吐量;
- 它支持多订阅者,当失败时能自动平衡消费者;
- 它将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。
1.2 Kafka术语
| 术语 | 解释 | | —- | —- | | Broker | Kafka集群包含一个或多个服务器,这种服务器被称为broker | | Topic | 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处) | | Partition | Partition是物理上的概念,每个Topic包含一个或多个Partition. | | Producer | 负责发布消息到Kafka broker | | Consumer | 消息消费者,向Kafka broker读取消息的客户端 | | Consumer Group | 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group) | | replica | partition 的副本,保障 partition 的高可用 | | leader | replica 中的一个角色, producer 和 consumer 只跟 leader 交互 | | follower | replica 中的一个角色,从 leader 中复制数据 | | controller | Kafka 集群中的其中一个服务器,用来进行 leader election 以及各种 failover |
小白理解:
- producer:生产者,就是它来生产“鸡蛋”的。
- consumer:消费者,生出的“鸡蛋”它来消费。
- topic:把它理解为标签,生产者每生产出来一个鸡蛋就贴上一个标签(topic),消费者可不是谁生产的“鸡蛋”都吃的,这样不同的生产者生产出来的“鸡蛋”,消费者就可以选择性的“吃”了。
- broker:就是篮子了。
如果从技术角度,topic标签实际就是队列,生产者把所有“鸡蛋(消息)”都放到对应的队列里了,消费者到指定的队列里取。
2 Kafka安装
2.1 下载
Apache kafka 官方: http://kafka.apache.org/downloads.html
Scala 2.11 - kafka_2.11-0.10.2.0.tgz (asc, md5)
2.2 Kafka集群安装
2.2.1 安装JDK &配置JAVA_HOME
2.2.2 安装Zookeeper
参照Zookeeper官网搭建一个ZK集群, 并启动ZK集群。
2.2.3 解压Kafka安装包
2.2.3.1 修改配置文件config/server.properties
| vi server.properties broker.id=1 //为依次增长的:0、1、2、3、4,集群中唯一id log.dirs=/root/kafkaData/ // Kafka的消息数据存储路径 zookeeper.connect=hdp-01:2181,hdp-02:2181,hdp-03:2181 //zookeeperServers列表,各节点以逗号分开 delete.topic.enable=true listeners=PLAINTEXT://hdp-01:9092 log.dirs=/root/kafkaData/ num.partitions=3 # 安装包分发 for i in 2 3 ; do scp -r kafka_2.11-0.10.2.1/ hdp-0$i:$PWD ;done 再其它几台节点上,分别修改该配置文件。 |
|---|
2.2.3.2 启动Kafka
启动kafka之前,必须要保证zookeeper是启动的。
在每台节点上启动:
bin/kafka-server-start.sh [-daemon] config/server.properties
2.2.3.3 测试集群
1-进入kafka根目录,创建Topic名称为: test的主题
bin/kafka-topics.sh —create —zookeeper hdp-01:2181,hdp-02:2181,hdp-03:2181 —replication-factor 3 —partitions 1 —topic test
2-列出已创建的topic列表
bin/kafka-topics.sh —list —zookeeper hdp-01:2181
3-查看Topic的详细信息
bin/kafka-topics.sh —describe —zookeeper localhost:2181 —topic test
Topic:test PartitionCount:1 ReplicationFactor:3 Configs:
Topic: test Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
第一行是对所有分区的一个描述,然后每个分区对应一行,因为只有一个分区所以下面一行。
leader:负责处理消息的读和写,leader是从所有节点中随机选择的.
replicas:列出了所有的副本节点,不管节点是否在服务中.
isr:是正在服务中的节点.
在例子中,节点1是作为leader运行。
4-模拟客户端去发送消息
bin/kafka-console-producer.sh —broker-list hdp-01:9092,hdp-02:9092 —topic hellotopic
5-模拟客户端去接受消息
连接broker的地址
bin/kafka-console-consumer.sh —bootstrap-server hdp-03:9092 —from-beginning —topic hellotopic
如果想指定消费者的group id,可以通过参数 consumer-property参数来指定
kafka-console-consumer.sh —topic firstTopic —bootstrap-server hdp-01:9092,hdp-02:9092,hdp-03:9092 —consumer-property group.id=xx
6-测试一下容错能力.
Kill -9 pid[leader节点]
另外一个节点被选做了leader,node 1 不再出现在 in-sync 副本列表中:
bin/kafka-topics.sh —describe —zookeeper localhost:2181 —topic test
Topic:test PartitionCount:1 ReplicationFactor:3 Configs:
Topic: test Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2,0
虽然最初负责续写消息的leader down掉了,但之前的消息还是可以消费的:
bin/kafka-console-consumer.sh —zookeeper localhost:2181 —from-beginning —topic test
删除主题:
bin/kafka-topics.sh —delete —zookeeper hdp-01:2181,hdp-02:2181,hdp-03:2181 —topic test2
3 Kafka客户端开发
3.1 Java Client
3.1.1 添加pom.xml依赖
3.1.2 Producer 生产者
| Properties props = new Properties();
// 设置brokers地址
_props.setProperty(“bootstrap.servers”, “hdp-01:9092,hdp-02:9092,hdp-03:9092”);
// kafka的 key 和 value的序列化
_props.setProperty(“key.serializer”, StringSerializer.class.getName());
props.setProperty(“value.serializer”, “org.apache.kafka.common.serialization.StringSerializer”);
_// 发送的时候做应答<br /> // all -1 0 1<br /> // 0 不做任何应答<br /> // 1 leader 会给 producer做应答<br /> // all -1 follower ---> leader >> producer<br />// props.setProperty("acks", "1");// 自定义分区器<br /> // props.setProperty("partitioner.class", "org.apache.kafka.clients.producer.internals.DefaultPartitioner");/// 创建一个生产者的客户端实例<br /> _KafkaProducer<String, String> producer = **new **KafkaProducer<>(props);**int **i = 1;<br /> **while **(i < 20000) {<br /> _// 假定有3个分区<br /> _**int **partition = i % 3;_// String topic, Integer partition, Long timestamp, K key, V value<br /> _ProducerRecord<String, String> topic = **new **ProducerRecord<>(**"helloTopic3"**, **"bbbb"**, **""**+i);_// 发送消息<br /> _producer.send(topic);Thread._sleep_(3000);<br /> i+= 1;<br /> }producer.close();<br /> System.**_out_**.println(**"send msg success"**); |
| —- |
3.1.3 Consumer 消费者
|
// Properties props = new Properties();
_HashMap
props.put(“bootstrap.servers”, “hdp-01:9092,hdp-02:9092,hdp-03:9092”);
props.put(“key.deserializer”, StringDeserializer.class.getName());
props.put(“value.deserializer”, StringDeserializer.class.getName());
// props.put(“group.id”, “1111”);
_props.put(“group.id”, “3333”);
_// [latest, earliest, none]<br /> _props.put(**"auto.offset.reset"**,**"earliest"**); _// 从哪个位置开始获取数据<br /> _props.put(**"enable.auto.commit"**, **false**);_// 是否要自动提交偏移量(offset)// 创建一个消费者客户端实例<br /> _KafkaConsumer<String,String> consumer = **new **KafkaConsumer(props);_// 订阅主题(告诉客户端从按个主题获取数据)<br /> _consumer.subscribe(Arrays._asList_(**"helloTopic3"**));**while **(**true**){_// 拉取数据,会从kafka所有分区下拉取数据<br /> _ConsumerRecords<String,String> records = consumer.poll(2000);<br /> Iterator<ConsumerRecord<String, String>> iterator = records.iterator();<br /> **while **(iterator.hasNext()){<br /> ConsumerRecord<String, String> msg = iterator.next();<br /> System.**_out_**.println(**"收到消息:"**+msg);<br /> }<br /> }<br /> } |
| —- |
4 Kafka原理
4.1 Kafka的拓扑结构
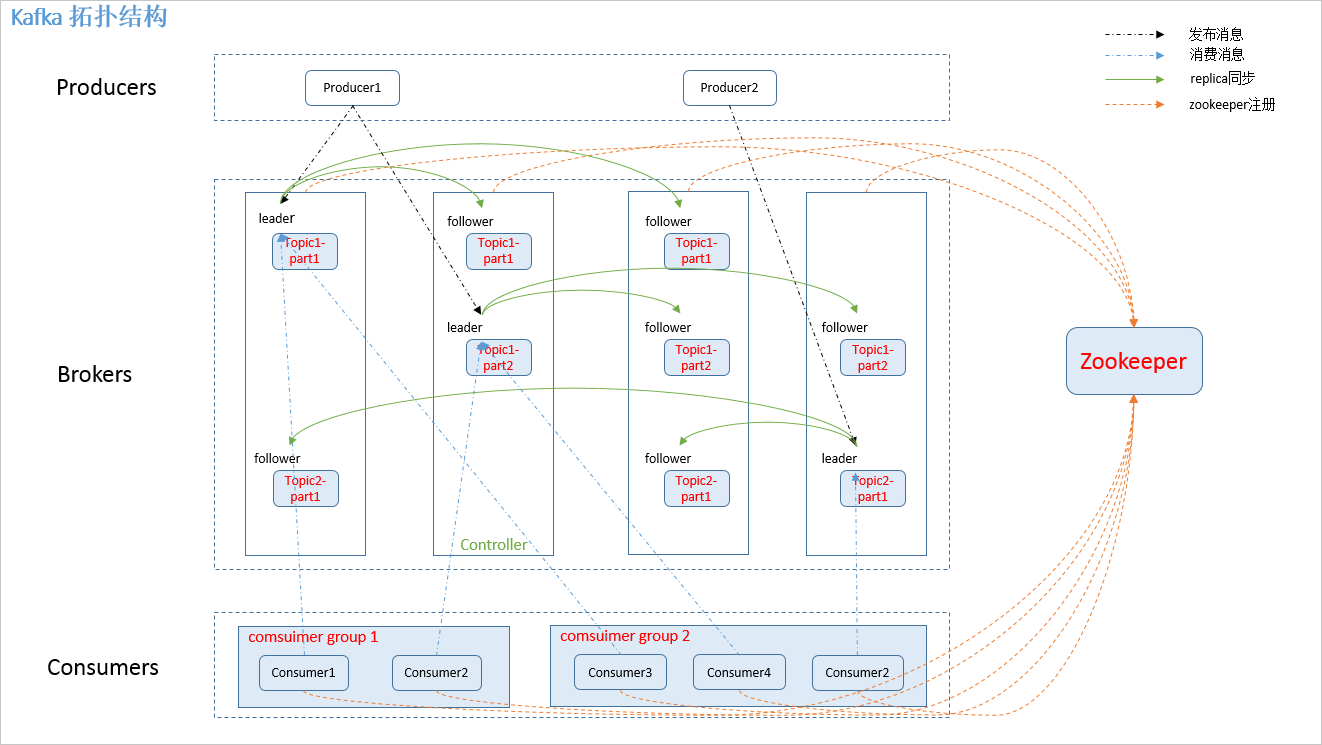
如上图所示,一个典型的Kafka集群中包含若干Producer,若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
4.2 Zookeeper节点
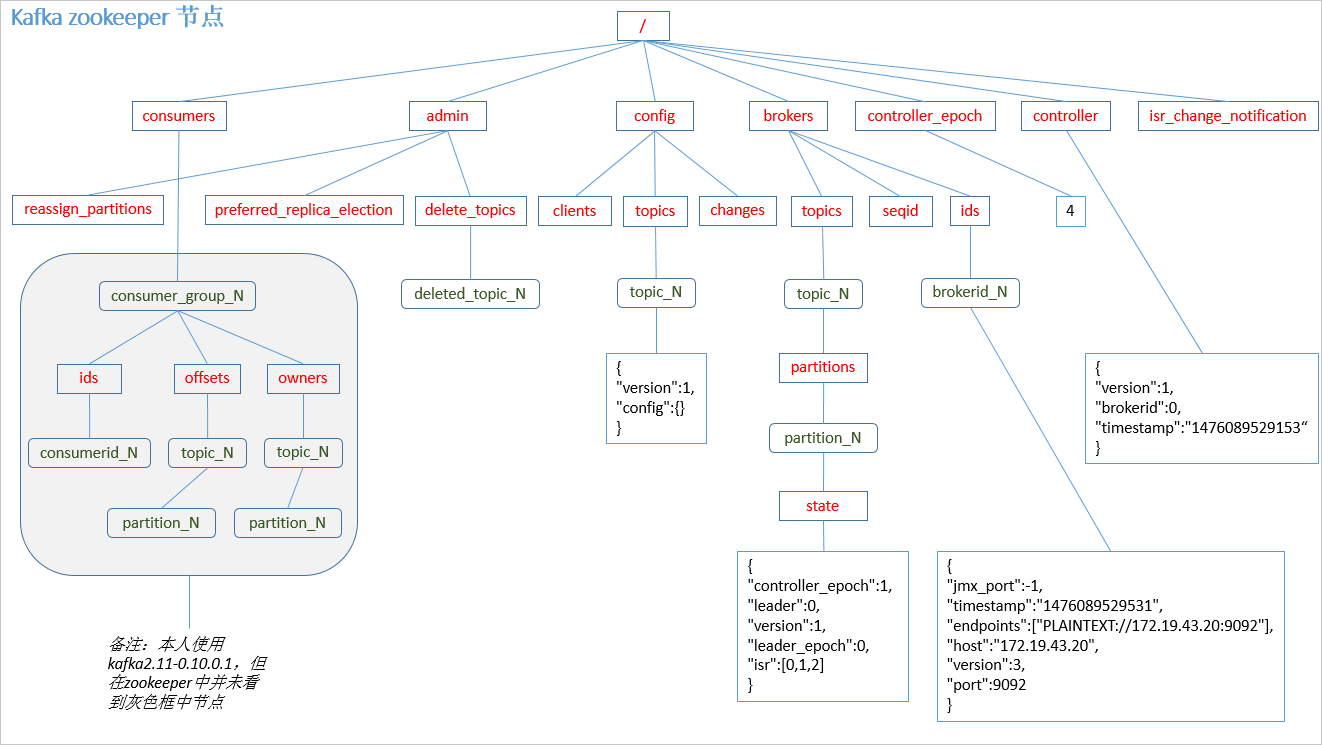
4.3 Producer发布消息
- producer 采用 push 模式将消息发布到 broker,每条消息都被 append 到 partition 中,属于顺序写磁盘。
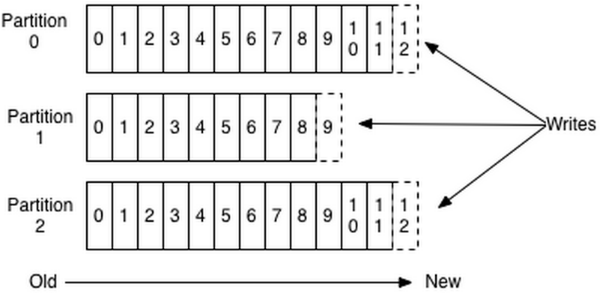
- producer 发送消息到 broker 时,会根据分区算法选择将其存储到哪一个partition。
| 1. 指定了 partition,则直接使用;
2. 未指定 partition 但指定 key,通过对 key 的 value 进行hash 选出一个 partition
3. partition 和 key 都未指定,使用轮询选出一个 partition 。 | | —- |
4.3.1 写数据流程
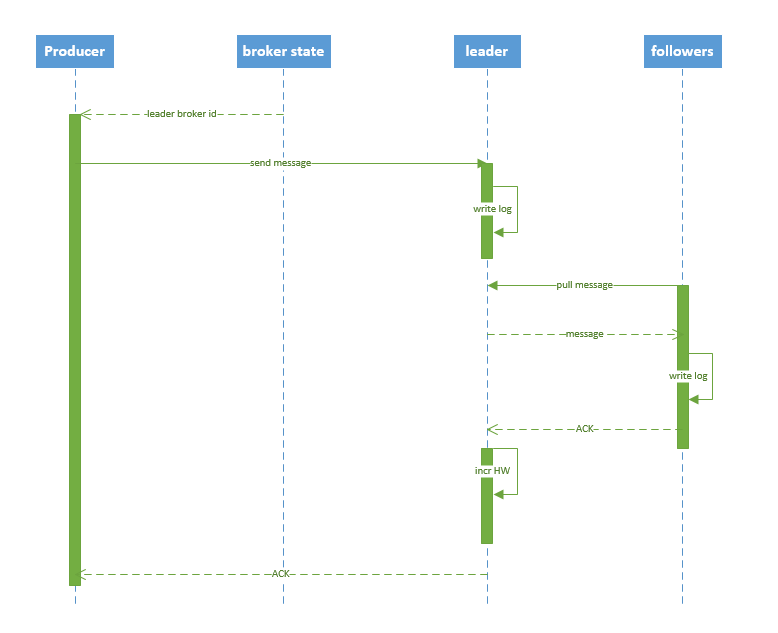
| 1. producer 先从 zookeeper 的 “/brokers/…/state” 节点找到该 partition 的 leader 2. producer 将消息发送给该 leader 3. leader 将消息写入本地 log 4. followers 从 leader pull 消息,写入本地 log 后 leader 发送 ACK 5. leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset) 并向 producer 发送 ACK |
|---|
4.4 Broker存储消息
4.4.1 消息存储方式
物理上把 topic 分成一个或多个 patition(对应 server.properties 中的 num.partitions=3 配置),每个 patition 物理上对应一个文件夹(该文件夹存储该 patition 的所有消息和索引文件),如下: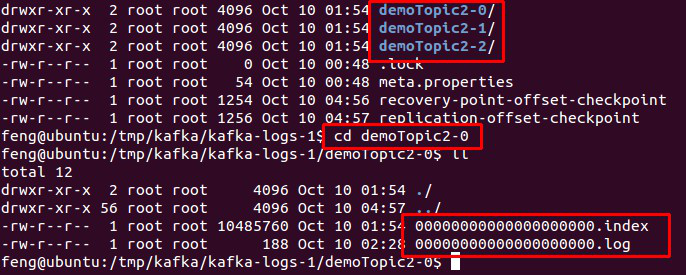
数据是存在 log日志文件中。
该文件的文件名称中,有起始偏移量 ,1g 就会切换文件。
000000000.log
0000000300.log
0000000500.log
index索引文件: 存储了offset对应的数据的位置
查找的时候:
offset是345,二分搜索,查找的偏移量,在哪个日志文件中。 0000000300.log
就去0000000300.index中去获取我的指定偏移量在数据存储的位置。
根据指定位置,直接去定位数据。
4.4.2 消息存储策略
无论消息是否被消费,kafka 都会保留所有消息。有两种策略可以删除旧数据:
log.retention.hours=168 #基于时间
log.retention.bytes=1073741824 #基于大小
4.5 Topic创建删除
4.5.1 创建Topic
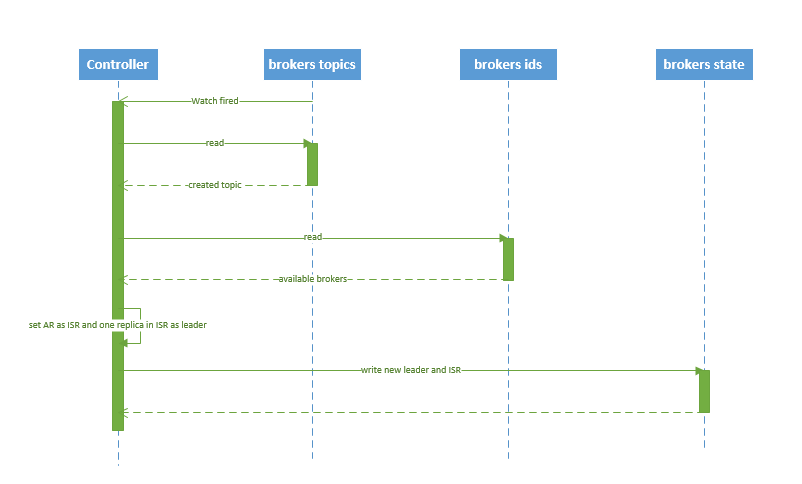
| 1. controller 在 ZooKeeper 的 /brokers/topics 节点上注册 watcher,当 topic 被创建,则 controller 会通过 watch 得到该 topic 的 partition/replica 分配。 2. controller从 /brokers/ids 读取当前所有可用的 broker 列表,对于 set_p 中的每一个 partition: 2.1 从分配给该 partition 的所有 replica(称为AR)中任选一个可用的 broker 作为新的 leader,并将AR设置为新的 ISR 2.2 将新的 leader 和 ISR 写入 /brokers/topics/[topic]/partitions/[partition]/state 3. controller 通过 RPC 向相关的 broker 发送 LeaderAndISRRequest。 |
|---|
controller会自动对我们的分区,进行负载均衡。
- 关掉broker.id=0 上的kafka
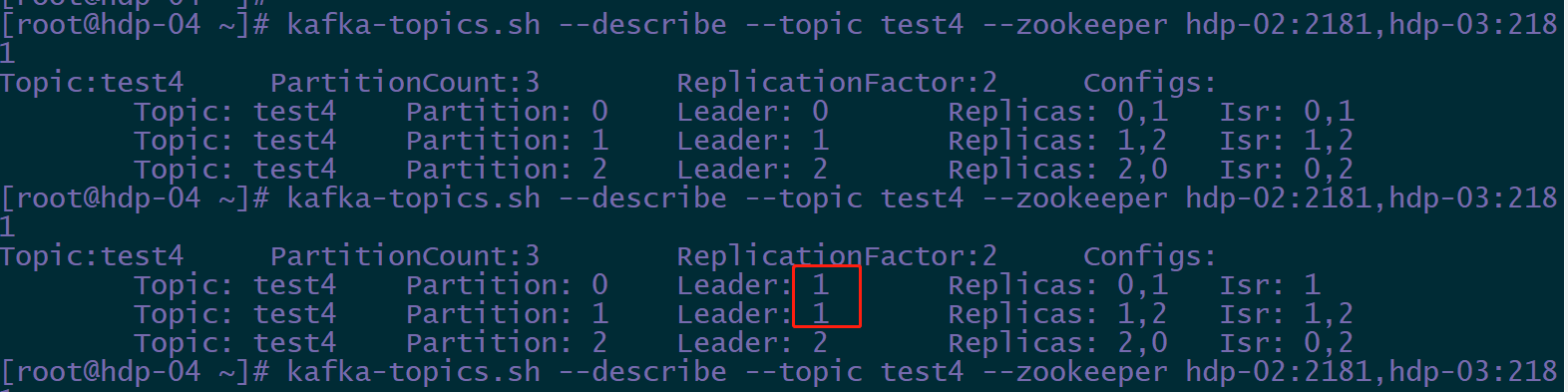
4.5.2 删除Topic

| 1. controller 在 zooKeeper 的 /brokers/topics 节点上注册 watcher,当 topic 被删除,则 controller 会通过 watch 得到该 topic 的 partition/replica 分配。 2. 若 delete.topic.enable=false,结束;否则 controller 注册在 /admin/delete_topics 上的 watch 被 fire,controller 通过回调向对应的 broker 发送 StopReplicaRequest。 |
|---|

若有收获,就点个赞吧
0 人点赞
