1 SparkSQL
1.1 什么是Spark SQL
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。
1.2 为什么要学习Spark SQL
Spark SQL,是将Spark SQL转换成RDD,然后提交到集群执行,执行效率非常快!
1.易整合
- 统一的数据访问方式

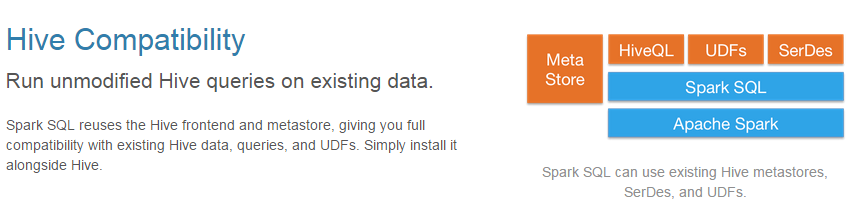
- 兼容Hive
- 标准的数据连接

1.3 SparkSQL的概念
中文的官网:spark.apachecn.org
Spark SQL 是一个用来处理结构化数据的spark组件,也可被视为一个分布式的SQL查询引擎。与基础的 Spark RDD API 不同, Spark SQL 提供了查询结构化数据及计算结果等信息的接口。在内部, Spark SQL 使用这个额外的信息去执行额外的优化.有几种方式可以跟 Spark SQL 进行交互, 包括 SQL 和 Dataset API。
两类API:DataFrames + Dataset
1.4 DataFrames
1.4.1 什么是DataFrames(1.3)
与RDD相似,DataFrame也是数据的一个不可变分布式集合。但与RDD不同的是,数据都被组织到有名字的列中,就像关系型数据库中的表一样,除了数据之外,还记录着数据的结构信息,即schema。设计DataFrame的目的就是要让对大型数据集的处理变得更简单,它让开发者可以为分布式的数据集指定一个模式,进行更高层次的抽象。还提供了特定领域内专用的API来处理分布式数据。
从API易用性的角度上 看,DataFrame API提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低。由于与R和Pandas的DataFrame类似,Spark DataFrame很好地继承了传统单机数据分析的开发体验。
dataframe = rdd + schema
dataframe就是带着schema信息的rdd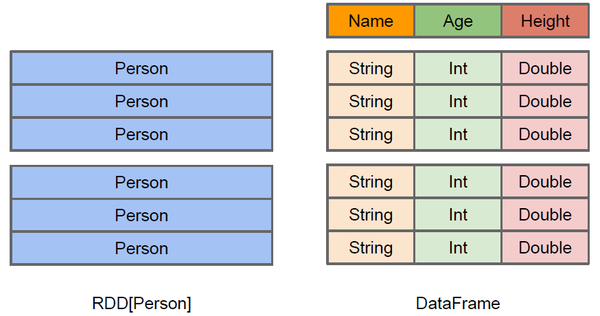
spark 基于RDD
sparkSql 基于DataFrame + Dataset
1.4.2 创建DataFrames
- 在本地创建一个文件,有三列,分别是id、name、age,用空格分隔,然后上传到hdfs上
hdfs dfs -put person.txt /
2.在spark shell执行下面命令,读取数据,将每一行的数据使用列分隔符分割
val lineRDD = sc.textFile(“hdfs://hdp-01:9000/person.txt”).map(_.split(“ “))
3.定义case class(相当于表的schema)
case class Person(id:Int, name:String, age:Int)
- 将RDD和case class关联
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))
- 将RDD转换成DataFrame
val personDF = personRDD.toDF
6.对DataFrame进行处理
personDF.show
1.5 Spark-shell中操作DataFrame
1.5.1 DSL风格语法
DSL : domain-specific language
//查看DataFrame中的内容
personDF.show
//查看DataFrame部分列中的内容
personDF.select(personDF.col(“name”)).show
personDF.select(col(“name”), col(“age”)).show
personDF.select(personDF (“name”)).show
personDF.select(“name”).show
//打印DataFrame的Schema信息
personDF.printSchema
personDF.schema
//查询所有的name和age,并将age+1
personDF.select(col(“id”), col(“name”), col(“age”) + 1).show
personDF.select(personDF(“id”), personDF(“name”), personDF(“age”) + 1).show
personDF.select(personDF(“name”),personDF.col(“age”)+10 as “tenyears”).show
//过滤age大于等于18的
personDF.filter(col(“age”) >= 18).show
//按年龄进行分组并统计相同年龄的人数
personDF.groupBy(“age”).count().show()
1.5.2 SQL风格语法
如果想使用SQL风格的语法,需要将DataFrame注册成表
personDF.registerTempTable(“t_person”)
//查询年龄最大的前两名
sqlContext.sql(“select * from t_person order by age desc limit 2”).show
//显示表的Schema信息
sqlContext.sql(“desc t_person”).show
1.6 DataFrame开发操作
1.6.1 SQL风格语法
使用sparksql需要导入sparksql的依赖jar包
| <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>${spark.version}</version> </dependency> |
|---|
使用toDF方式,指定schema信息
| object SqlDemo1 { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf() conf.setMaster(“local”).setAppName(“sql”) val sc: SparkContext = new SparkContext(conf)// 创建sparksql的操作对象 val sqlContext: SQLContext = new SQLContext(sc) // 准备数据 先从集合中准备 val data: RDD[String] = sc.parallelize(Array(“laoduan 9999 30”,“laozhao 99 32”,“zs 99 28”)) // 数据预处理操作 val maped: RDD[Boy] = data.map({ arr => // 获取各属性值 val fields: Array[String] = arr.split(“ “) val name = fields(0) val fv = fields(1).toDouble val age = fields(2).toInt // 封装成对象 __Boy(name, fv, age) }) // RDD类型的数据,想要使用sql来操作,就必须进行转换 转换成DataFrame // 需要导入sqlContext对象的隐式转换 import sqlContext.implicits. // 通过toDF方法,把RDD转换成了DataFrame类型 val boyDF: DataFrame = maped.toDF // 想要使用sql语法来查询,还需要把df对象注册成一张表 boyDF.registerTempTable(“boy”) // 使用sql语句执行查询,返回DataFrame对象, lazy执行的, val resDF: DataFrame = sqlContext.sql(“select * from boy order by fv desc ,age asc”) // 调用action方法执行 resDF.show() } } // case class 用于封装数据_ case class Boy(name:String,fv:Double,age:Int) extends Serializable |
|---|
使用StructType方式,指定schema信息
| def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setMaster(“local”).setAppName(“sql”)
val sc: SparkContext = new SparkContext(conf)// 创建sparksql的操作对象
val sqlContext: SQLContext = new SQLContext(sc)
// 准备数据 先从集合中准备
val data: RDD[String] = sc.parallelize(Array(“laoduan 9999 30”,“laozhao 99 32”,“zs 99 28”))
_// 数据预处理操作<br /> _**val **rdd= data.map({<br /> arr =><br /> _// 获取各属性值<br /> _**val **fields: Array[String] = arr.split(**" "**)<br /> **val **name = fields(0)<br /> **val **fv = fields(1).toDouble<br /> **val **age = fields(2).toInt<br /> _// 不封装case class,需要使用Row对象来封装<br /> __Row_(name,fv,age)<br /> })<br /> _// 将RDD关联scheme<br /> // structtype里面封装的是对象的类型信息<br /> _**val **schema:StructType=_StructType_(<br /> _List_(<br /> _StructField_(**"name"**,StringType),<br /> _StructField_(**"fv"**,DoubleType),<br /> _StructField_(**"age"**,IntegerType)<br /> ))<br /> **val **boyDF: DataFrame = sqlContext.createDataFrame(rdd,schema)<br /> _// 想要使用sql语法来查询,还需要把df对象注册成一张表<br /> _boyDF.registerTempTable(**"boy"**)<br /> _// 使用sql语句执行查询,返回DataFrame对象, lazy执行的,<br /> _**val **resDF: DataFrame = sqlContext.sql(**"select * from boy order by fv desc ,age asc"**)<br /> _// 调用action方法执行<br /> _resDF.show()<br /> } |
| —- |
1.6.2 DSL风格语法
|
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setMaster(“local”).setAppName(“sql”)
val sc: SparkContext = new SparkContext(conf)
// 创建sparksql的操作对象
val sqlContext: SQLContext = new SQLContext(sc)
// 准备数据 先从集合中准备
val data: RDD[String] = sc.parallelize(Array(“laoduan 9999 30”, “laozhao 99 32”, “zs 99 28”))
// 数据预处理操作
val rdd = data.map({
arr =>
// 获取各属性值
val fields: Array[String] = arr.split(“ “)
val name = fields(0)
val fv = fields(1).toDouble
val age = fields(2).toInt
// 不封装case class,需要使用Row对象来封装
__Row(name, fv, age)
})
// 将RDD关联scheme
// structtype里面封装的是对象的类型信息
val schema: StructType = StructType(
List(
StructField(“name”, StringType),
StructField(“fv”, DoubleType),
StructField(“age”, IntegerType)
))
val boyDF: DataFrame = sqlContext.createDataFrame(rdd, schema)
// 指定列名
val df1: DataFrame = boyDF.select(“name”, “fv”)
// 指定过滤条件
val df2 = df1.where(“fv > 90”)
// 排序 默认升序 sort和orderBy方法都可实现
// val df3 = df2.sort(“fv”)
// 如果按照指定的排序,需要导入隐式转换
import sqlContext.implicits.
val df3 = df2.orderBy($”fv” desc)
// 可以一行搞定
val by: Dataset[Row] = boyDF.select(“name”,“fv”).where(“fv > 90”).orderBy($”fv” desc)
// 查看结果
_df3.show()
} |
| —- |
1.6.3 spark 1.x SQL的用法总结
1.创建SparkContext
2.创建SQLContext
3.创建RDD
4.创建一个类,并定义类的成员变量
5.整理数据并关联class
6.将RDD转换成DataFrame(导入隐式转换)
7.将DataFrame注册成临时表
8.书写SQL(Transformation)
9.执行Action
————————————————-
1.创建SparkContext
2.创建SQLContext
3.创建RDD
4.创建StructType(schema)
5.整理数据将数据跟Row关联
6.通过rowRDD和schema创建DataFrame
7.将DataFrame注册成临时表
8.书写SQL(Transformation)
9.执行Action
1.7 Datasets and DataFrames
Dataset 是一个分布式的数据集合,Dataset 是在 Spark 1.6 中被添加的新接口, 它提供了 RDD 的优点(强类型化, 能够使用强大的 lambda 函数)与Spark SQL执行引擎的优点.一个 Dataset 可以从 JVM 对象来 构造 并且使用转换功能(map, flatMap, filter, 等等).
一个 DataFrame 是一个 Dataset 组成的指定列.它的概念与一个在关系型数据库或者在 R/Python 中的表是相等的, 但是有很多优化.
DataFrames 可以从大量的 sources 中构造出来, 比如: 结构化的文本文件, Hive中的表, 外部数据库, 或者已经存在的 RDDs.
在 Scala 和 Java中, 一个 DataFrame 所代表的是一个多个 Row(行)的Dataset(数据集合). 在Scala API中, DataFrame 仅仅是一个 Dataset[Row]类型的别名. 然而, 在 Java API中, 用户需要去使用 Dataset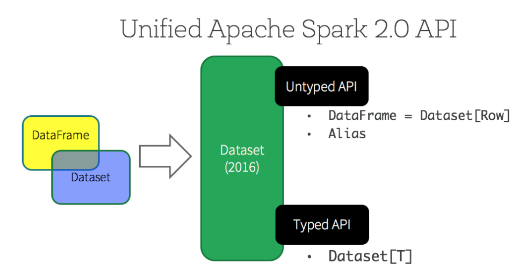
1.8 DataSet编程
sqlWordCount:
| def main(args: Array[String]): Unit = {
// 在spark2.0中,想要使用DataSet DataFrame 以及sql 程序执行的入口是SparkSession
// 通过builder方法,获取sparksession对象
val session: SparkSession = SparkSession.builder()
.appName(“xxx”)
.master(“local”)
.getOrCreate() _// 类似于单例,有就拿来使用,没有再创建
// 读取数据 调用read textFile 方法
val lines: Dataset[String] = session.read.textFile(“wc.txt”)
// 收集数据到driver端瞅一瞅
val collected: Array[String] = lines.collect()
// println(collected.toBuffer)
// DataSet中的数据也是有schema信息的
// lines.show()
// 必须导入隐式转换 才能使用DataSet的方法
import session.implicits.
val words: Dataset[String] = lines.flatMap(.split(“ “))
// 用sql的方式执行
// 创建一个临时视图(类似于表)
_words.createTempView(“t_words”)
val sql: DataFrame = session.sql(“select value word,count(*) count from t_words group by word order by count desc”)
sql.show()
session.close()
} |
| —- |
如果缺少隐式转换,就会报错:
DataSet DSL风格的WordCount
| def main(args: Array[String]): Unit = {
// 在spark2.0中,想要使用DataSet DataFrame 以及sql 程序执行的入口是SparkSession
// 通过builder方法,获取sparksession对象
val session: SparkSession = SparkSession.builder()
.appName(“xxx”)
.master(“local”)
.getOrCreate() _// 类似于单例,有就拿来使用,没有再创建
// 读取数据 调用read textFile 方法<br /> _**val **lines: Dataset[String] = session.read.textFile(**"wc.txt"**)_// 收集数据到driver端瞅一瞅<br /> _**val **collected: Array[String] = lines.collect()<br /> _// println(collected.toBuffer)<br /> // DataSet中的数据也是有schema信息的<br /> // lines.show()// 必须导入隐式转换 才能使用DataSet的方法<br /> _**import **session.implicits._<br /> **val **words: Dataset[String] = lines.flatMap(_.split(**" "**))_// 不需要再 进行单词和1的组装了,因为操作的是一张表,直接分组后调用聚合函数(实际上是一种表达式,spark会默认转化为方法)<br /> // 此时必须导入默认的函数<br /> _**import **org.apache.spark.sql.functions._<br /> **val **res: DataFrame = words.groupBy(**$"value"**).agg(_count_(**"*"**))<br /> _// 默认的列名是 value|count(1) ,可类似于sql中的指定别名 还可通过sort方法进行排序<br /> _**val **res2:DataFrame = words.groupBy(**$"value" **as **"word"**).agg(_count_(**"*"**) as **"counts"**).sort(**$"counts" **desc)<br /> _// 分组后求组内count 使用count方法一样可以实现<br /> _**val **res3: DataFrame = words.groupBy(**$"value" **as **"word"**).count() _// .sort($"count" desc)// 继续对res3调用count方法 返回的结果 相当于数据表中的行数<br /> _**val **res4: Long = res3.count()<br /> _// 重命名列名<br /> _**val **sort: Dataset[Row] = words.groupBy(**$"value" **as **"word"**).count().withColumnRenamed(**"count"**,**"countss"**).sort(**$"countss" **desc)<br /> sort.show()<br /> _// words.show()<br /> // 展示结果<br />// res3.show()<br />// println(s"counts = $res4" )<br /> _session.close()<br /> } |
| —- |
1.9 RDD、DataFrame和DataSet的区别
1.9.1 RDD的优点与缺点
优点:
编译时类型安全:编译时就能检查出类型错误
面向对象的编程风格:直接通过类名点的方式来操作数据
缺点:
序列化和反序列化的性能开销:无论是集群间的通信, 还是IO操作都需要对对象的结构和数据进行序列化和反序列化
GC的性能开销:频繁的创建和销毁对象, 势必会增加GC
1.9.2 DataFrame的优点与缺点
DataFrame引入了schema和off-heap
schema : RDD每一行的数据, 结构都是一样的. 这个结构就存储在schema中. Spark通过schema就能够读懂数据, 因此在通信和IO时就只需要序列化和反序列化数据, 而结构的部分就可以省略了.
off-heap : 意味着JVM堆以外的内存, 这些内存直接受操作系统管理(而不是JVM)。Spark能够以二进制的形式序列化数据(不包括结构)到off-heap中, 当要操作数据时, 就直接操作off-heap内存. 由于Spark理解schema, 所以知道该如何操作
优点:通过schema和off-heap, DataFrame解决了RDD的缺点,DataFrame不受JVM的限制,没有GC的困扰
缺点:DataFrame不是类型安全的, API也不是面向对象风格的
1.9.3 DataSet的优点
DataSet结合了RDD和DataFrame的优点(类型安全、面向对象、不受JVM限制、没有GC开销)
1.9.3.1 静态类型与运行时类型安全
如果你用的是Spark SQL的查询语句,要直到运行时才会发现有语法错误(这样做代价很大),而如果你用的是DataFrame和Dataset,你在编译时就可以捕获错误(这样就节省了开发者的时间和整体代价)。也就是说,当你在DataFrame中调用了API之外的函数时,编译器就可以发现这个错。不过,如果你使用了一个不存在的字段名字,那就要到运行时才能发现错误了。
因为Dataset API都是用lambda函数和JVM类型对象表示的,所有不匹配的类型参数都可以在编译时发现。而且在使用Dataset时,你的分析错误也会在编译时被发现,这样就节省了开发者的时间和代价。
所有这些最终都被解释成关于类型安全的图谱,内容就是你的Spark代码里的语法和分析错误。在图谱中,Dataset是最严格的一端,但对于开发者来说也是效率最高的。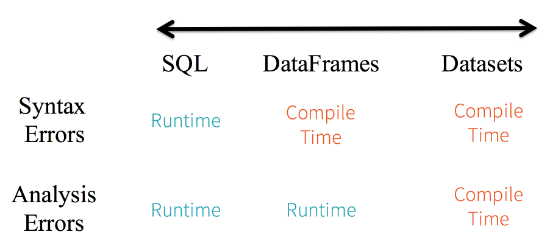
1.9.3.2 方便易用的结构化API
虽然结构化可能会限制Spark程序对数据的控制,但它却提供了丰富的语义,和方便易用的特定领域内的操作,后者可以被表示为高级结构。事实上,用Dataset的高级API可以完成大多数的计算。比如,比用RDD数据行的数据字段进行agg、select、sum、avg、map、filter或groupBy等操作更简单。
1.9.3.3 性能与优化
首先,因为DataFrame和Dataset API都是基于Spark SQL引擎构建的,它使用Catalyst来生成优化后的逻辑和物理查询计划。所有R、Java、Scala或Python的DataFrame/Dataset API,所有的关系型查询的底层使用的都是相同的代码优化器,因而会获得空间和速度上的效率。尽管有类型的Dataset[T] API是对数据处理任务优化过的,无类型的Dataset[Row](别名DataFrame)却运行得更快,适合交互式分析。

若有收获,就点个赞吧
0 人点赞
