1 集合
1.1 集合综述
Scala的集合有三大类:序列Seq、集Set、映射Map,所有的集合都扩展自Iterable特质
在Scala中集合有可变(mutable)和不可变(immutable)两种类型(两个不同的包),immutable类型的集合初始化后就不能改变了(注意与val修饰的变量进行区别)
包的全局路径:scala.collection.immutable 这个包是默认导入的包
如果想使用可变的集合,就需要导包 scala.collection.mutable
scala.collection.immutable.*
2 集合整体架构(了解)
顶级抽象类或父类: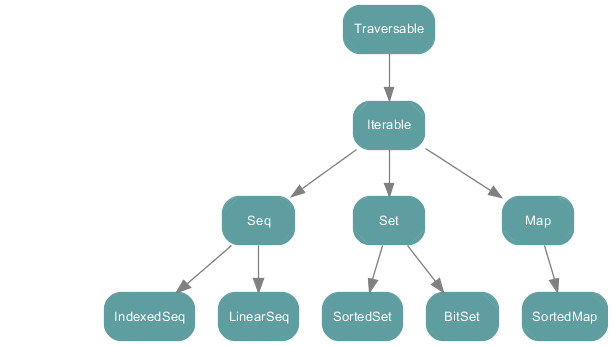
不可变集合(scala.collection.immutable):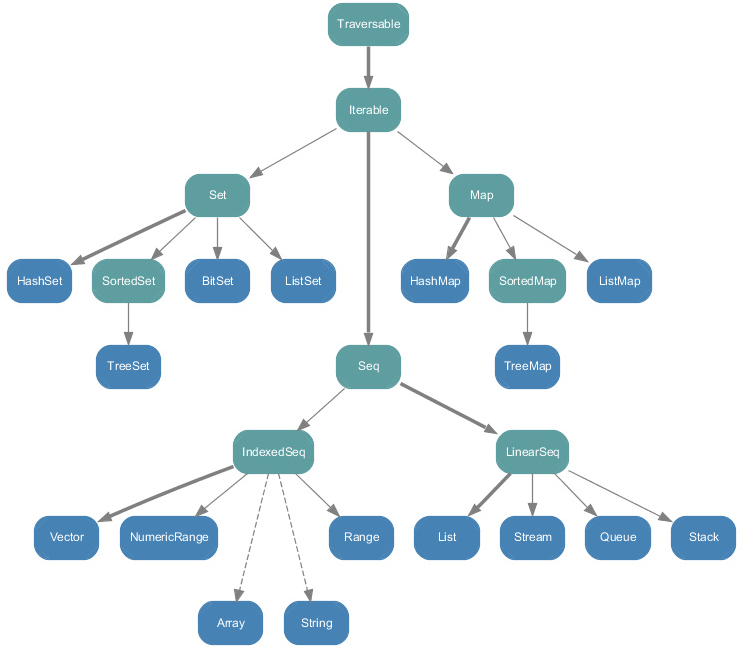
可变集合(scala.collection.mutable):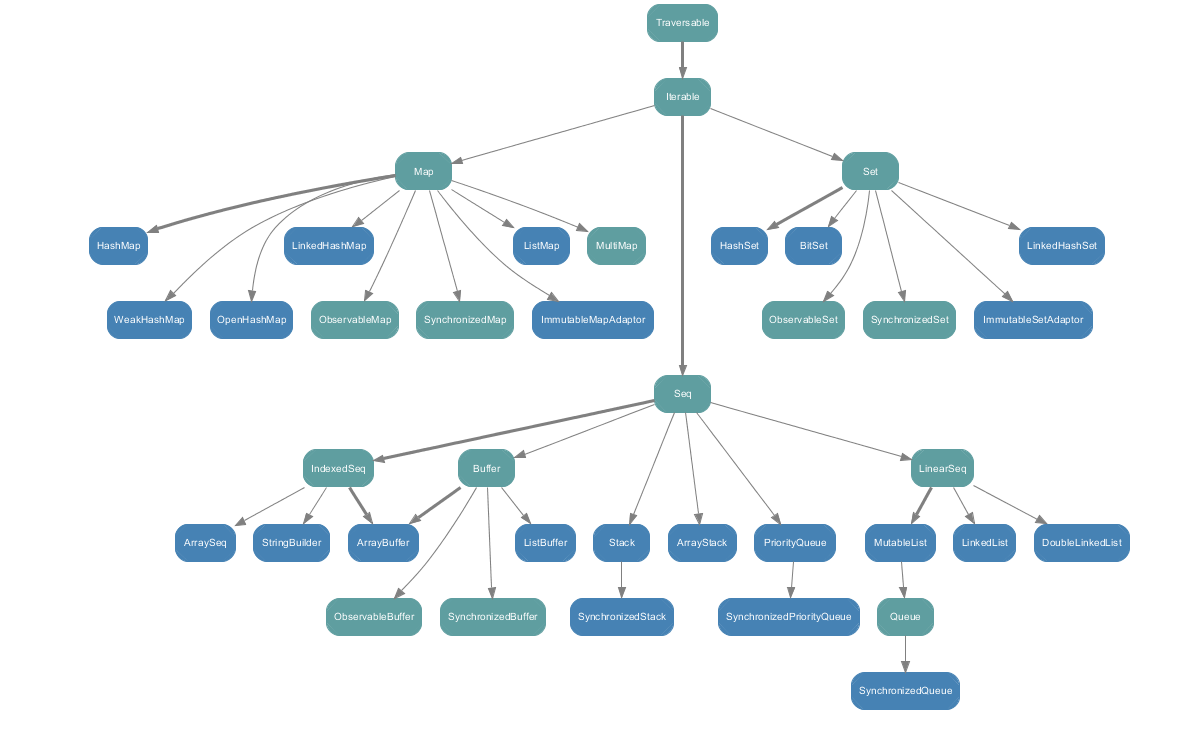
3 数组
3.1 定长数组和变长数组
Nothing是所有类型的子类型,Null ,有一个值,就是null
定长数组,是不可变的,长度不可变,内容可变,默认类型 scala.collection.immutable.
变长数组,可变的,长度可变,内容可变
创建定长数组:
指定数组类型,并赋值,类型可省略,编译器会自动推导。
val arr1 = ArrayInt
通过new关键字创建的数组,必须指定数组的类型和长度。
val arr2 = new ArrayInt
取值赋值,下标从0开始:
arr1(0)
arr1(0) =100
| object ArrayTest {
def main(args: Array[String]) {
_//初始化一个长度为8的定长数组,其所有元素均为0<br /> _**val **arr1 = **new **Array[Int](8)<br /> _//直接打印定长数组,内容为数组的hashcode值<br /> println_(arr1)<br /> _//将数组转换成数组缓冲,就可以看到原数组中的内容了<br /> //toBuffer会将数组转换长数组缓冲<br /> println_(arr1.toBuffer)_//注意:如果不是new,相当于调用了数组的apply方法,直接为数组赋值<br /> //初始化一个长度为1的定长数组<br /> _**val **arr2 = _Array_[Int](10)<br /> _println_(arr2.toBuffer)_//定义一个长度为3的定长数组<br /> _**val **arr3 = _Array_(**"hadoop"**, **"storm"**, **"spark"**)<br /> _//使用()来访问元素<br /> println_(arr3(2))_//////////////////////////////////////////////////<br /> //变长数组(数组缓冲)<br /> //如果想使用数组缓冲,需要导入import scala.collection.mutable.ArrayBuffer包<br /> _**val **ab = ArrayBuffer[Int](1,3,4)<br />**val **ab = new ArrayBuffer[Int]()<br /> _//向数组缓冲的尾部追加一个元素<br /> //+=尾部追加元素<br /> _ab += 1<br /> _//追加多个元素<br /> _ab += (2, 3, 4, 5)<br />_//减少多个元素_<br />ab -= (3, 4)<br /> _//追加一个数组++=<br /> _ab ++= _Array_(6, 7)<br /> _//追加一个数组缓冲<br /> _ab ++= ArrayBuffer(8,9)<br />_//减少一个数组++=_ ab --= _Array_(6, 7)__ //在数组某个位置插入元素用insert,第一个参数为插入元素的位置,后面的可变参数为插入的元素<br /> _ab.insert(0, -1, 0)<br /> _//删除数组某个位置的元素用remove,第一个参数为要删除的元素位置,第二个参数为删除几个元素<br /> _ab.remove(8, 2)<br /> _println_(ab)<br />_// 清空ab1.clear()<br />println(ab1)<br /> }<br />} |
| —- |
3.2 遍历数组
1.增强for循环
2.生成器 to或者until,0 until 10 包含0不包含10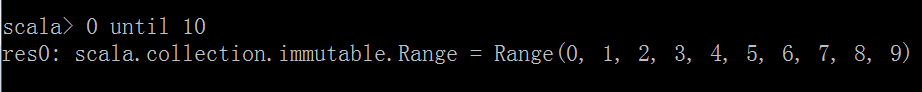
| object ForArrayTest {
def main(args: Array[String]) {
//初始化一个数组
val arr = Array(1,2,3,4,5,6,7,8)
//增强for循环
for(i <- arr)
println(i)
_//好用的until会生成一个Range<br /> //reverse是将前面生成的Range反转<br /> _**for**(i <- (0 until arr.length).reverse)<br /> _println_(arr(i))<br /> }<br />} |
| —- |
3.3 数组转换
toArray 变长数组转换成定长数组
toBuffer 定长数组转换成变长数组
yield关键字将原始的数组进行转换会产生一个新的数组,原始的数组不变
| object ArrayYieldTest {
def main(args: Array[String]) {
//定义一个数组
val arr = _Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
//将偶数取出乘以10后再生成一个新的数组
val res = for (e <- arr if e % 2 == 0) yield e * 10
println(res.toBuffer)
_//更高级的写法,用着更爽<br /> //filter是过滤,接收一个返回值为boolean的函数<br /> //map相当于将数组中的每一个元素取出来,应用传进去的函数<br /> _**val **r = arr.filter(_ % 2 == 0).map(_ * 10)<br /> _println_(r.toBuffer)<br /> }<br />} |
| —- |
3.4 数组常用方法
在Scala中,数组上的某些方法对数组进行相应的操作非常方便!
sorted默认是升序排序的。
arr. 然后输入Tab,可查看所有的方法。
val arr = Array(1,3,4,6,8)
数组反转:arr1.reverse
数组切片:arr.slice(1,4) 第一个起始位置,包含;第二个终止位置,不包含 [ )
4 元组Tuple
与数组或列表不同,元组可以容纳不同类型的对象,但它们也是不可变的。
元组是不同类型元素的集合
4.1 创建元组
定义元组时,使用小括号将多个元素括起来,元素之间使用逗号分隔,元素的类型可以不同,元素的个数任意多个(不超过22个)
注意:元组没有可变和不可变之分,都是不可变的。
| val t = (12.3, 1000, “spark”) val t4 = new Tuple4(1,2.0,””,3) // 必须4个元素 |
|---|
4.2 获取元组中的值
获取元组的值使用下标获取,但是元组的下标时从1开始的,而不是0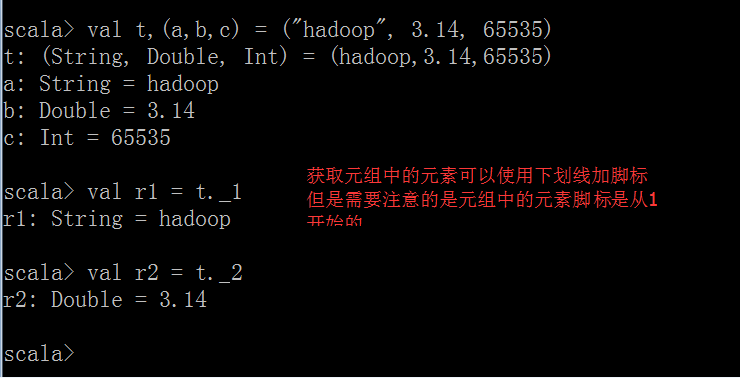
4.3 将对偶的集合转换成映射

4.4 拉链操作
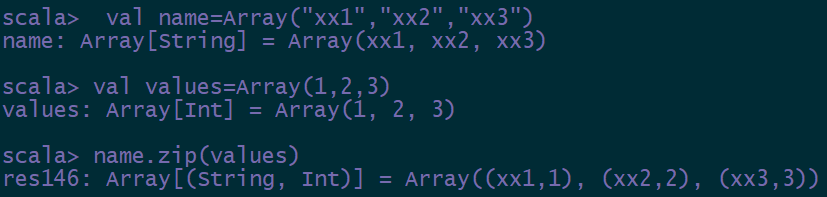
zip命令可以将多个值绑定在一起,生成元组
| val name=Array(“xx1”,”xx2”,”xx3”,”xx4”) val values=Array(1,2,3) name.zip(values) |
|---|
多个zip # name zip values zip values.map(_*10)
注意:如果两个数组的元素个数不一致,拉链操作后生成的数组的长度为较小的那个数组的元素个数
4.5 元素交换
可以使用 Tuple.swap 方法来交换对偶元组的元素。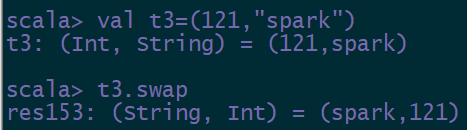
| // 定义元组var t = (1, “hello”, true)// 或者val tuple3 = new Tuple3(1, “hello”, true)
// 访问tuple中的元素println(t.2) // 访问元组总的第二个元素
// 迭代元组t.productIterator.foreach(_println)
// 对偶元组val tuple2 = (1, 3)// 交换元组的元素位置, tuple2没有变化, 生成了新的元组val swap = tuple2.swap |
| —- |
元组类型Tuple1,Tuple2,Tuple3等等。目前在Scala中只能有22个上限,如果需要更多个元素,那么可以使用集合而不是元组。
练习1:定义一个方法或函数,求Double数组的平均值
练习2:定义一个方法或函数,求一个数组的最大值和最小值,返回两个最值组成的元组。
5 序列List
5.1 不可变序列
默认就是不可变序列
构造列表的两个基本单位是 Nil 和 ::
Nil 表示为一个空列表。
创建List集合的两种方式:
val list1= ListInt
val list2 = 9::5::2::Nil
注意::: 操作符是右结合的,该操作符就是将给定的头和尾创建一个新的列表
如9 :: 5 :: 2 :: Nil相当于 9 :: (5 :: (2 :: Nil))
注意:在Scala中列表要么为空,要么是一个head元素加上一个tail列表。
列表的连接:
可以使用++ 或 ::: 运算符或++:或 List.concat() 方法来连接两个或多个列表
注意:对不可变List的所有的操作,全部生成新的List
| object ImmutListTest {
def main(args: Array[String]) {
//创建一个不可变的集合
val lst1 = List(1,2,3)
//将0插入到lst1的前面生成一个新的List
val lst2 = 0 :: lst1
val lst4 = 0 +: lst1 // 推荐使用这种
_//将一个元素添加到lst1的后面产生一个新的集合<br /> _**val **lst6 = lst1 :+ 3<br /> **val **lst0 = _List_(4,5,6)<br /> _//将2个list合并成一个新的List<br /> _**val **lst7 = lst1 ++ lst0<br />**val **lst8 = lst1 ++: lst0<br />**val **lst9 = lst1 ::: lst0<br />**val **lst10 = List.concat(lst1,lst0)<br />_// 列表反转_<br />lst1.reverse<br /><br />// 列表头元素<br />lst1.head<br />// 列表的尾列表<br />lst1.tail<br /> } <br />} |
| —- |
List和Array的对比:
list不可变,表示长度不可变,内容也不可变
array 长度不可变,但是内容可变
不可变list和可变List的比较(List和ListBuffer):
不可变List,长度不可变,值不可变
可变List,长度可变,值可变
5.2 可变序列
ListBuffer
需要显示导包 import scala.collection.mutable._
创建ListBuffer的两种方式:
val lb1 = ListBufferInt // 创建的同时可赋初值val lb2 = new ListBufferInt // 类型必须显示指定
添加元素:
+=方法和append方法,都可以添加多个元素。
| import scala.collection.mutable.ListBuffer
object MutListTest extends App{
//构建一个可变列表,初始有3个元素1,2,3
val lst0 = ListBufferInt
//创建一个空的可变列表
val lst1 = new ListBuffer[Int]
//向lst1中追加元素,注意:没有生成新的集合
lst1 += (4,6)
lst1.append(5) //将lst0和lst1合并成一个新的ListBuffer 注意:生成了一个新集合
val lst2 = lst0 ++ lst1
//将lst1中的元素追加到lst0中, 注意:没有生成新的集合
lst0 ++= _lst1
//将元素追加到lst0的后面生成一个新的集合
val _lst3 = lst0 :+ 5
//将元素追加到lst0的前面
val lst4 = 5 +: lst0
// 去除元素_lb2 -= (1,3)
lb2 —= _List(7,9)
lb2.remove(1,2) //去除元素 根据一个或多个下标
// 判断集合是否为空
Lb2.isEmpty()
} |
| —- |
6 映射Map
在Scala中,把哈希表这种数据结构叫做映射
映射是K/V对 类型的值。
6.1 定义map
在Scala中,有两种Map,一个是immutable包下的Map,该Map中的内容不可变;另一个是mutable包下的Map,该Map中的内容可变。
默认是immutable包下的map,
| // 默认是immtable包下的Map val mp1 = Map((“a”,1),(“b”,2))val mp2 = _Map(“a”->1,“b”->2)// 添加元素之后生成新的mapval mp3 = mp2+(“c”->1) |
|---|
可使用mutable.Map
| // 导包import scala.collection.mutable// 创建集合val mp4 = new mutable.HashMapString,Intval mp5 = mutable.MapString,Int |
|---|

6.2 添加元素
针对可变集合,多种赋值方式
| mp4 += (“e”->8, “f”->9) mp4+= ((“b1”,121)) mp4.put(“lyf”,21) mp4(“nvshen”)=18 |
|---|
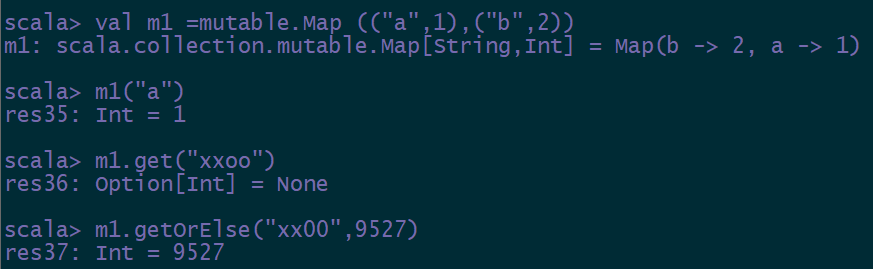
6.3 获取映射值
m1(“a”)
m1.get(“xxoo”)
如果没有值,赋予默认值:
m1.getOrElse(“xxoo”,9527)

补充:通常我们在创建一个集合时会用val这个关键字修饰一个变量(相当于java中的final),那么就意味着该变量的引用不可变,该引用中的内容是不是可变,取决于这个引用指向的集合的类型
6.4 赋值和修改值
m1.getOrElse(“d”, 0)
m1(“b”) = 22
m1.update(“b”,22)
6.5 删除元素
根据key来删除一个或多个值
m1 -= (“a”)
m1.remove(“a”)
去除多个key:
m1 -= (“a”,”b”)
6.6 map遍历
for(i <- mp) println(i)
for((k,v) <- mp){println(k)}
for((_,v) <- mp){println(v)}
_是占位符,如果只需要遍历value,不需要遍历key,就可以用占位符
交换k,v
for((k,v) <- mp) yield (v,k)
mp.map(x=>(x._2,x._1))
mp.map(x=>x.swap)
6.7 获得keys和values
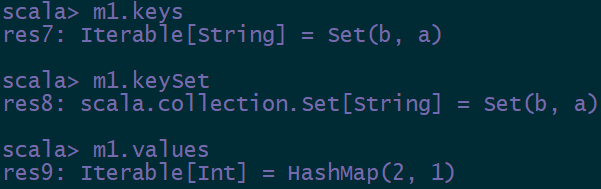
合并
使用 ++ 运算符或 Map.++() 方法来连接两个 Map,Map 合并时会移除重复的 key。
| // 合并时,相同的key元素会被覆盖val colors1 = Map(“nvshen” ->18,“nanshen” -> 35)val colors2 = Map(“bq” -> 40,“nvshen” -> 20)var colors = colors1 ++ colors2 |
|---|
7 Set
7.1 不可变的Set
长度和值都不可变,set中的元素不能重复
| object ImmutSetTest extends App{ // 默认是immtable包下的Setval set1 = Set (1,4,6)// 执行添加,删除的操作,都是生成了新的Set集合val s2: Set[Int] = set1 + (10,12) set1 - (1) println(set1) // 查看set集合内容 set1.foreach(println) //set中元素不能重复 val set3 = set1 ++ Set(5, 6, 7) val set0 = Set(1,3,4) ++ set1 } |
|---|
7.2 可变的Set
可变Set中,remove方法,移除的是元素,而不是下标
ListBuffer中,remove方法,参数是下标
| import scala.collection.mutable
object MutSetTest extends App{
import scala.collection.mutable.Set // 可以在任何地方引入 可变集合
val mSet = new mutable.HashSetInt
val mutableSet = Set(1,2,3)
mutableSet.add(4)_// mutableSet += 5<br /> _mutableSet += (5,15)<br /> _// 添加set集合<br /> _mutableSet ++= Set(12,14)_// mutableSet -= 4<br /> _mutableSet -= (4,2)_// remove方法,删除的不是下标,而是元素<br /> _mutableSet.remove(2)<br /> _println_(mutableSet)<br /> _// 转换为不可变集合<br /> _**val **another = mutableSet.toSet<br /> _println_(another.getClass.getName) _// scala.collection.immutable.Set_} |
| —- |
8 Map和Option
在Scala中Option类型样例类用来表示可能存在或也可能不存在的值(Option的子类有Some和None)。Some包装了某个值,None表示没有值。
| // Option是Some和None的父类
// Some代表有(多例),样例类
// None代表没有(单例),样例对象
val mp = Map(“a” -> 1, “b” -> 2, “c” -> 3)val r: Int = mp(“d”)
// Map 的get方法返回的为Option, 也就意味着 rv 可能取到也有可能没取到val rv: Option[Int] = mp.get(“d”)
// 如果rv=None时, 会出现异常情况val r1 = rv.get
// 使用getOrElse方法,
// 第一个参数为要获取的key,
// 第二个参数为默认值, 如果没有获取到key对应的值就返回默认值val r2 = mp.getOrElse(“d”, -1)
println(r2) | | —- |
9 map|flatten|flatMap|foreach方法的使用
map 迭代集合中的每一个元素,然后按照自己的逻辑来修改元素
flatten 压平 如果有嵌套集合,就会把内层的嵌套去掉了
flatMap 先map 再flatten 先map 再压平
foreach 对每一个元素执行操作,相当于遍历 println
map和foreach的区别:
返回值不同,map返回值类型为函数返回值类型(map方法的参数就是一个函数),foreach返回值为Unit
| // 定义一个数组val array = ArrayInt// map方法是将array数组中的每个元素进行某种映射操作, (x: Int) => x * 2 为一个匿名函数, x 就是array中的每个元素val y = array ._map((x: Int) => x * 2)// 或者这样写, 编译器会自动推测x的数据类型val _z = array.map(x => x2)// 亦或者, 表示入参, 表示数组中的每个元素值val _x = array.map(_ 2)
println(x.toBuffer)
println(“————分割线————“)
// 定义一个数组val words = Array(“hello tom hello jim hello jerry”, “hello Hatano”)
// 将数组中的每个元素进行分割
// Array(Array(hello, tom, hello, jim, hello, jerry), Array(hello, Hatano))val splitWords: Array[Array[String]] = words.map(wd => wd.split(“ “))
// 此时数组中的每个元素经过split之后变成了Array, flatten是对splitWords里面的元素进行扁平化操作
// Array(hello, tom, hello, jim, hello, jerry, hello, Hatano)val flattenWords = splitWords.flatten
// 上述的2步操作, 可以等价于flatMap, 意味先map操作后进行flatten操作val result: Array[String] = words.flatMap(wd => wd.split(“ “))
// 遍历数组, 打印每个元素result.foreach(println) |
| —- |
10 案例wordCount
| // 定义一个数组val words = Array(“hello tom hello star hello sheep”, “hello tao hello tom”)
words.flatMap(.split(“ “)) // 对数组中的每个元素进行切分, 并进行扁平化操作
.map((, 1)) // 将数组的每个元素转换成一个对偶元组, 元组的第二个元素为1
.groupBy(._1) // 对集合中的所有元素进行按单词分组, 相同单词的元组分到一组
.mapValues(.length) // 对每个key 的value集合进行求长度操作
.toList _// 将map 转换成List
// 实现方式二words.flatMap(.split(“ “)).groupBy(x => x).map(t => (t._1, t._2.length)).toList | | —- |
11 集合常用的方法
map
filter
过滤出满足条件的所有元素,并返回一个集合
find
过滤出满足条件的一个元素,并返回一个Option
如果说有结果值,返回值的是Some(Int),就是get方法来获取值
sorted
按元素的升序排序
sortBy
按照指定的条件排序
支持,多个条件的排序
sortWith
接收两个参数,并进行比较
mapValues
类似于map,只是处理的是k-v类型中的v值
groupBy
按照指定条件分组
grouped
按照指定元素个数进行分组
count
统计满足条件的元素个数
reduce
元素累加
参数是一个函数,这个函数有两个参数 累加值 元素值 调用的就是reduceLeft
| val arr=Array(“aa”,”bb”,”cc”,”dd”) arr.reduce( + ) arr.reduce( ++ ) arr.reduce(+” “ ++ ) |
|---|
reduceLeft reduceRight
fold foldLeft foldRight
fold有两个参数,第一个参数是默认值,第二个参数是一个函数,该函数有两个参数 累加值 元素值 调用的就是reduceLeft
fold 要求函数的2个输入参数类型必须一致,foldLeft 可以允许函数的2个输入参数类型不一致
| 示例:求平均值
val d1 = Array((“bj”,28.1), (“sh”,28.7), (“gz”,32.0), (“sz”, 33.1))val d2 = Array((“bj”,27.3), (“sh”,30.1), (“gz”,33.3))val d3 = Array((“bj”,28.2), (“sh”,29.1), (“gz”,32.0), (“sz”, 30.5))
// 1,需要把数据组装到一起
val data1: Array[(String, Double)] = d1.union(d2).union(d3) _// d1 union d2 union d3
//d1 ++ d2 ++ d3
// 2 分组 按照城市名称来分组val data2: Map[String, Array[(String, Double)]] = data1.groupBy(t=>t._1)
// 统计val data4 = data2.mapValues({
kv=>
// kv数据类型: Array[(String,Double)]
// t的数据类型是元组(String,Double)
})
_println(“————111——————“)
println(data4)
// 3 统计 拿到这几个月份的温度的总值,然后再求平均val result: Map[String, Double] = data2.map {
t =>
// t (String,Array[(String, Double)])
val city = t.1
// foldLeft 第一个是累加值 第二个是元素值
val wendu: Double = t._2.foldLeft(0d)({
// total是Double a是(String, Double)
(total, a) =>
total + a._2
}) / t._2.length
(city, wendu)
}
_println(result) |
| —- |
交集,并集 差集
intersect union diff
union是一个轻量级的方法
distinct 元素去重
mkString 把元素拼接成字符串
take(n) 取集合中前几个元素
slice(from,until) 截取元素,提取元素列表中的from 到until位置的元素
聚合 aggregate
val arr = List(List(1, 2, 3), List(2))
val result = arr.aggregate(0)(+.sum, +)
12 并行化集合par(了解)
调用集合的par方法, 会将集合转换成并行化集合.
| //创建一个Listval lst0 = List(1,7,9,8,0,3,5,4,6,2)//折叠:有初始值(无特定顺序)val lst11 = lst0.par.fold(100)((x, y) => x + y)//折叠:有初始值(有特定顺序)val lst12 = lst0.foldLeft(100)((x, y) => x + y) |
|---|
13 练习:
1,计算一个Array[Double]数组的平均值
2,编写一个函数或方法,返回数组中最小值和最大值的对偶 (元组)
3,编写一个函数或方法,getValues(values: Array[lnt],v:Int),返回数组中小于v、等于v和大于v的元素个数,要求三个值一起返回
4,数组反转
5,求平均值
6,key value互换
7,展示量点击量

若有收获,就点个赞吧
0 人点赞
