写程序时,sparkContext对象,在使用完毕之后要关闭。
sc.stop()
Spark分区器
HashPartitioner和RangePartitioner
自定义分区器
0.1 RDD的属性

一组分片列表(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
RDD之间的依赖关系列表。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
可选,一个Partitioner,即RDD的分区函数。当前Spark中实现了两种类型的分区函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分区数量,也决定了parent RDD Shuffle输出时的分区数量。
一个数据存储列表,存储每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
以MapPartitionsRDD类为例,其compute方法如下
override def compute(split: Partition, context: TaskContext): Iterator[U] =
f(context, split.index, firstParent[T].iterator(split, context))
MapPartitionsRDD类的compute方法调用当前RDD内的第一个父RDD的iterator方法,该方法的目的是拉取父RDD对应分区的数据,iterator方法会返回一个迭代器对象,迭代器内部存储的每一个元素即父RDD对应分区内的数据记录。
RDD的粗粒度转换体现在map方法上,f函数是map转换操作函数,RDD会对一个分区(而不是一条一条数据记录)内的数据执行单的的操作f,最终返回包含所有经过转换过的数据记录的新迭代器,即新的分区。
其他RDD子类的compute方法与之类似,在需要用用到父RDD的分区数据时,就会调用iterator方法,然后根据需求在得到的数据上执行相应的操作。换句话说,compute函数负责的是父RDD分区数据到子RDD分区数据的变换逻辑。
粗粒度: 启动时就指定运行资源数量,不管资源是否使用。
细粒度:按需索取,任务运行时可以动态分配资源。
0.2 RDD的依赖关系
RDD只能基于在稳定物理存储中的数据集和其他已有的RDD上执行确定性操作来创建。
能从其他RDD通过确定操作创建新的RDD的原因是RDD含有从其他RDD衍生(即计算)出本RDD的相关信息(即Lineage)
Dependency代表了RDD之间的依赖关系,即血缘(Lineage),
RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。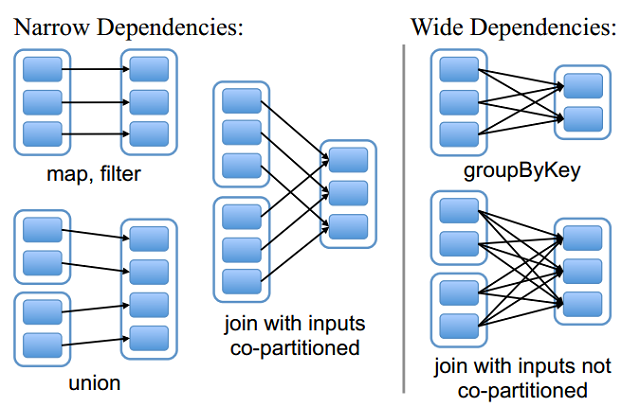
划分宽依赖和窄依赖的关键点在:
父RDD的一个分区,是最多被子RDD的一个分区所依赖,还是说被子RDD的多个子分区依赖。
也就是说父rdd的一个分区的数据,是给一个子rdd的分区,还是给子RDD的多个分区。
一旦有宽依赖,就会发生数据的shuffle
0.2.1 窄依赖
窄依赖指的是父RDD的一个分区,是最多被子RDD的一个分区所依赖
子RDD的每个分区依赖于常数个父分区。
输入输出一对一的算子,且结果RDD的分区结构不变。主要是map/flatmap
输入输出一对一的算子,但结果RDD的分区结构发生了变化,如union/coalesce
从输入中选择部分元素的算子,如filter、distinct、substract
0.2.2 宽依赖
宽依赖指的是父RDD的一个分区,被子RDD的多个子分区依赖。
子RDD的每个分区依赖于所有的父RDD分区。
对单个RDD基于key进行重组和reduce,如groupByKey,reduceByKey
对两个RDD基于key进行join和重组,如join(父RDD不是hash-partitioned )
需要进行分区,如partitionBy
总结:窄依赖我们形象的比喻为超生
普通的join: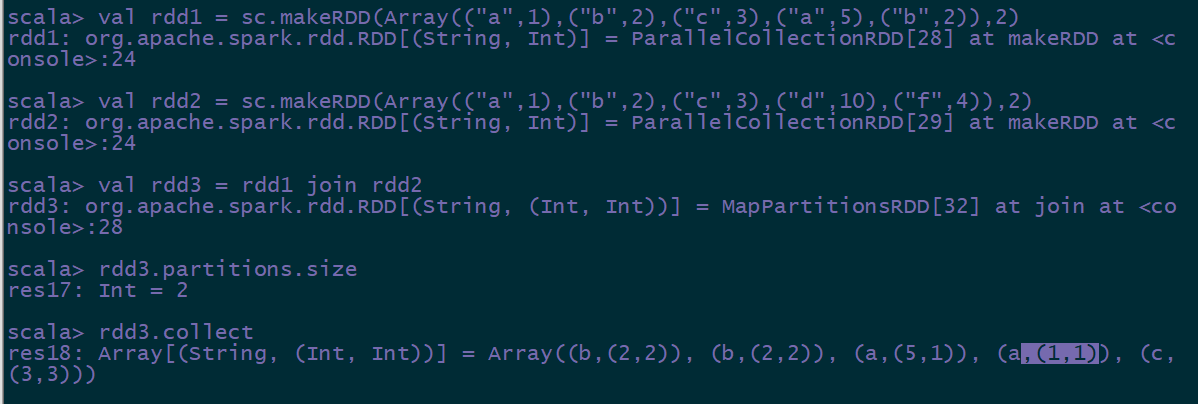
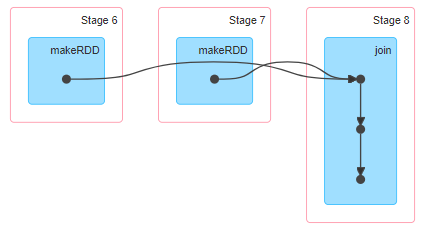
特殊的join:
条件:进行join的两个rdd必须经过了shuffle,而且有相同的分区。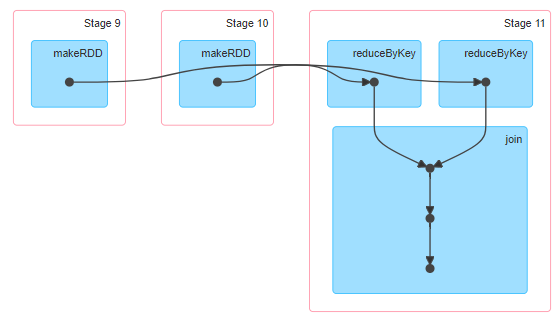
0.2.3 Lineage
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(即血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
分区是在driver端生成的,即使某一个分区挂掉了,也没有关系,driver端会根据rdd的依赖关系,重新起新的task进行任务执行。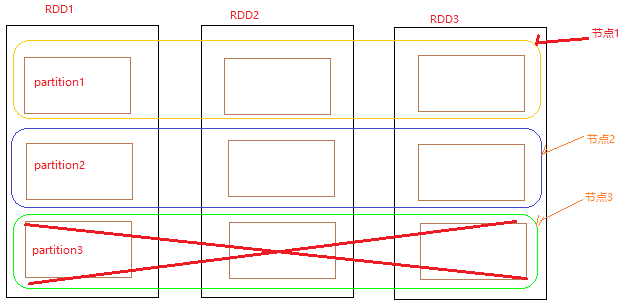
0.2.4 依赖与stage划分
Spark将窄依赖划分在同一个stage中,因为它们可以进行流水线计算。而宽依赖往往意味着shuffle操作,这也是Spark划分stage的主要边界。一个Stage的开始就是从外部存储或者shuffle结果中读取数据;一个Stage的结束就是发生shuffle或者生成结果时。
0.2.5 依赖与RDD容错
宽/窄依赖的概念不止用在stage划分中,对容错也很有用。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
如果transformation操作中间发生计算失败:
- 运算是窄依赖:只要把丢失的父RDD分区重新计算即可,跟其他节点没有依赖,这样可以大大减少恢复丢失的数据分区的开销
- 运算是宽依赖:需要父RDD的所有分区都存在,重算代价较高
- 增加检查点:当Lineage特别长或者有宽依赖时,主动调用checkpoint把当前数据写入稳定存储,作为检查点。但Checkpoint会产生磁盘开销,因为其就是将数据持久化到磁盘中,所以做检查点的RDD最好是已经在内存中缓存了。
0.2.6 DAG的生成
DAG(Directed Acyclic Graph)叫做有向无环图,指任意一条边有方向,且不存在环路的图。在spark里每一个操作生成一个RDD,RDD之间连一条边,最后这些RDD和他们之间的边组成一个有向无环图,这个就是spark中的DAG。原始的RDD通过一系列的转换就就形成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage,对于窄依赖,partition的转换处理在Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。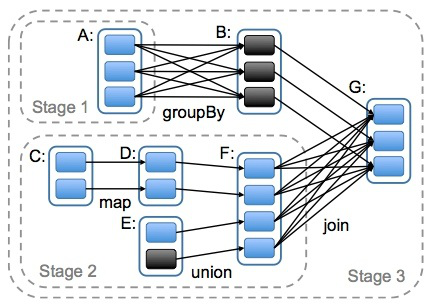
宽依赖是划分stage的标识。
总结:
DAG有向无环图图,代表RDD的转换过程,其实就是代表着数据的流向。
DAG是有边界的,有开始,有结束。通过sparkContext创建RDD就是开始,触发action就会生成一个完整的DAG。DAG会被切分成多个Stage(阶段),切分的依据就是宽依赖(shuffle),先会提交前面的stage,然后提交后面的stage,一个Stage中有多个Task,多个Task可以并行执行。
0.3 RDD的缓存
Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或缓存个数据集。当持久化某个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此RDD或衍生出的RDD进行的其他动作中重用。这使得后续的动作变得更加迅速。RDD相关的持久化和缓存,是Spark最重要的特征之一。可以说,缓存是Spark构建迭代式算法和快速交互式查询的关键。
0.3.1 缓存意义
RDD被缓存后,Spark将会在集群中,保存相关元数据,下次查询这个RDD时,它将能更快速访问,不需要计算。RDD相关的持久化和缓存,是Spark最重要的特征之一。可以说,缓存是Spark构建迭代式算法和快速交互式查询的关键。
默认情况下,每一个转换过的RDD都会在它之上执行一个动作时被重新计算。
如果rdd只被使用一次或者很少次,不需要持久化,如果持久化无谓的RDD,会浪费内存(或硬盘)空间,反而降低系统整体性能。如果rdd被重复使用或者计算其代价很高,才考虑持久化。另外,shuffle后生成的rdd尽量持久化,因为shuffle代价太高。
0.3.2 RDD缓存方式
RDD通过persist方法或cache方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
通过查看源码发现cache最终也是调用了persist方法,默认的存储级别都是仅在内存存储一份,Spark的存储级别还有好多种,存储级别在object StorageLevel中定义的。根据useDisk、useMemory、deserialized、off_heap、replication五个参数的组合提供了11种存储级别。

cache需要注意的事项
1.cache的返回值,必须赋值给一个新的变量(或者原来的是var类型的变量),然后在其他job中直接使用这个变量即可
2.cache是一个懒执行的算子,所以必须有Actions类型的算子(比如:count)触发它
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
注意:如果内存放不下全部数据,只会cache部分数据。如果使用的是memory and disk,优先使用内存,如果内存不足,才会使用disk
最常用的:
cache
persist(StorageLevel.MEMORY_AND_DISK)
cache执行方式: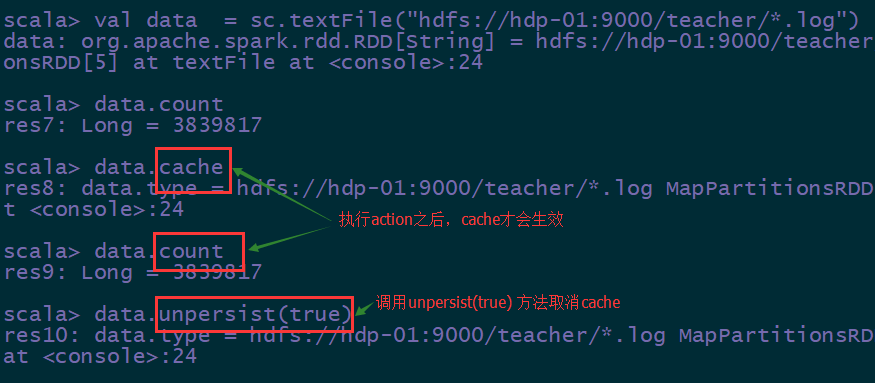
查看任务监控界面: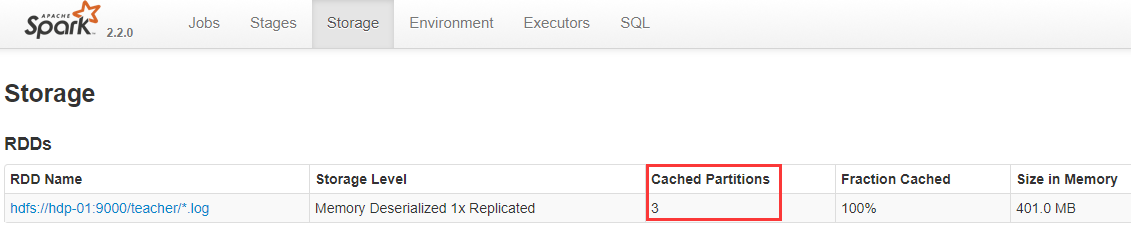
cache的目的:
为了更快速的获取数据,进行计算。
如果一个RDD的数据,被使用了超过一次,就建议把rdd中的数据进行cache。
什么时候使用缓存、持久化:
要求计算速度快
集群的资源要足够大
如果某一个RDD被使用了超过一次,就应该进行cache。提升效率。
非常复杂的计算结果(shuffle,得到的结果后续被使用,应当进行cache)
0.4 Checkpoint
既然可以缓存,为何需要检查点
如果缓存丢失了,则需要重新计算。
即使存在磁盘中,也可能因为单机挂掉导致数据丢失
如果计算特别复杂或者计算耗时特别多,那么缓存丢失对于整个Job的影响是不容忽视的。为了避免缓存丢失重新计算带来的开销,Spark又引入检查点机制。
缓存是在
为当前RDD设置检查点。该函数将会创建一个二进制的文件,并存储到checkpoint目录中,该目录是用SparkContext.setCheckpointDir()设置的。在checkpoint的过程中,该RDD的所有依赖于父RDD中的信息将全部被移出。对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发。
Checkpoint操作比较适用于迭代计算非常复杂的情况,也就是恢复计算代价非常高的情况,适当进行checkpoint会有很大的好处。
checkpoint流程: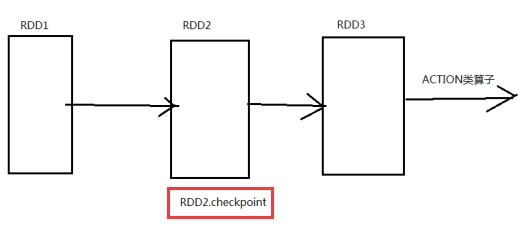
1.在RDD的job执行完成之后,会自动的从finalRDD(RDD3)从后往前进行回溯(为什么能够回溯?因为RDD的第三大特性,RDD之间是有一系列的依赖关系),遇到哪一个RDD(这里是RDD2)调用了checkpoint这个方法,就会对这个RDD做一个标记maked for checkpoint
2.另外重新启动一个新的job,重新计算被标记的RDD,将RDD的结果写入到HDFS中
3.如何对第二步进行优化:重新计算被标记的RDD,这样的话这个RDD就被计算了两次,最好调用checkpoint之前进行cache一下,这样的话,重新启动这个job只需要将内存中的数据拷贝到HDFS上就可以(省去了计算的过程)
4.checkpoint的job执行完成之后,会将这个RDD的依赖关系切断(即RDD2不需要再依赖RDD1,因为已经将RDD2这一步持久化了,以后需要数据的时候直接从持久化的地方取就可以了),并统一更名为checkpointRDD(RDD3的父RDD更名为checkpointRDD)
checkpoint 检查点,将中间结果存放到HDFS中,我们有的计算场景是经过了复杂的计算才得到了中间结果,这个中间结果后面要反复使用,所以我们把中间结果存起来
操作步骤:
| # 读取数据 val data = sc.textFile(“hdfs://hdp-01:9000/teacher/*.log”) # 设置sparkContext的checkpoint目录 sc.setCheckpointDir(“hdfs://hdp-01:9000/ck2017”) # 对数据进行一些复杂的算子操作 val data2 = data.filter(_.contains(“bigdata”)) # 对得到的结果数据设置检查点 data2.checkpoint # 触发执行 data2.count # 此处会有两次执行,一次把数据写入checkpoint目录,一次执行count计算结果 还可以对data2这个rdd执行缓存,然后执行时,会从缓存中写入数据到hdfs中的checkpoint目录。 data2.cache |
|---|
缓存和checkpoint比较:
RDD的缓存是在计算结束后,直接将计算结果通过用户定义的存储级别写入不同的介质(内存,磁盘等)。
而RDD的检查点不同,它是在计算完成后,重新建立一个Job来计算。
正常情况下,我们spark的程序,会使用cache,多一些
机器学习,迭代信息,从历史的数据中,分析出来的一些规律,然后基于这些规律进行预测。
优先使用cache+checkpoint
需求:根据访问日志中的IP地址字段,来计算IP归属地,并按照省份,计算出访问次数,并将计算好的结果写入到mysql中
| // 定义一个方法,把ip地址转换为10进制def ip2Long(ip: String): Long = { val fragments = ip.split(“[.]”) var ipNum = 0L for (i <- 0 until fragments.length){ ipNum = fragments(i).toLong | ipNum << 8L } ipNum } // 连接数据库方式 var conn: Connection = null var pstm: PreparedStatement = null try { conn = DriverManager.getConnection(“jdbc:mysql://localhost:3306/scott”, “root”, “123”) pstm = conn.prepareStatement(“insert into access_log values (?,?)”) // 因为拿到的每一个元素是一个迭代器,所以这里还需要循环迭代 _tp.foreach({ t => pstm.setString(1, t._1) pstm.setInt(2, t._2) pstm.executeUpdate() }) } catch { case e: Exception => _println(e.printStackTrace()) }finally { // 关闭连接 if (pstm != null) pstm.close() if (conn != null) conn.close() } <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.32</version> </dependency> |
|---|
0.5 共享变量
0.5.1 广播变量
通过在一个变量v上调用SparkContext.broadcast(v)可以创建广播变量。广播变量是围绕着v的封装,可以通过value方法访问这个变量。
广播变量的好处,不是每个task一份变量副本,而是变成每个节点的executor才一份副本。这样的话,就可以让变量产生的副本大大减少。
广播变量,初始的时候,就在Drvier上有一份副本。task在运行的时候,想要使用广播变量中的数据,此时首先会在自己本地的Executor对应的BlockManager中,尝试获取变量副本;如果本地没有,BlockManager,也许会从远程的Driver上面去获取变量副本;也有可能从距离比较近的其他节点的Executor的BlockManager上去获取,并保存在本地的BlockManager中;BlockManager负责管理某个Executor对应的内存和磁盘上的数据,此后这个executor上的task,都会直接使用本地的BlockManager中的副本。
注意:
广播变量缓存到各个节点的内存中,而不是每个 Task
广播变量被创建后,能在集群中运行的任何函数调用
广播变量是只读的,不能在被广播后修改
rdd不能广播
val broadcastVar = sc.broadcast(Array(1, 2, 3))
0.5.2 累加器
累加器是仅仅被相关操作累加的变量,因此可以在并行中被有效地支持。它可以被用来实现计数器和总和。
累加器通过对一个初始化了的变量v调用SparkContext.accumulator(v)来创建。在集群上运行的任务可以通过add或者”+=”方法在累加器上进行累加操作。但是,它们不能读取它的值。只有Driver能够读取它的值,通过累加器的value方法。
累加器只支持加法操作,可以高效地并行,用于实现计数器和变量求和。
val accum = sc.accumulator(0,”totalCounts”)
sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)
accum.value
sc.parallelize(Array(1, 2, 3, 4)).foreach(x => if(x%2==0) accum += x else accum+= 0)
可在任务监控页面查看

若有收获,就点个赞吧
0 人点赞
