Apache Flink是一个分布式处理引擎框架,用于对无界和有界数据流进行有状态计算。Flink设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
一:组件栈

组件栈主要分为4层,从上往下主要为:
Deployment层(物理部署层):
主要涉及flink部署模式:本地、集群(Standlone/YARN)、云(GCE/EC2)
Runtime(core)层:
runtime层提供支持flink计算的全部核心实现,比如:支持分布式stream处理、JobGraph到ExecutionGraph的映射、调度等等,为上层API层提供基础服务。
API层:
API层主要实现了面向无界Stream的流处理和面向Batch的批处理API,其中面向流处理对应DataStreamAPI,面向批处理对应DataSetAPI。
Libaries层
在API层之上构建的满足特定应用的实现计算框架,也分别对应用面向流处理和面向批处理两类。
二:基本架构
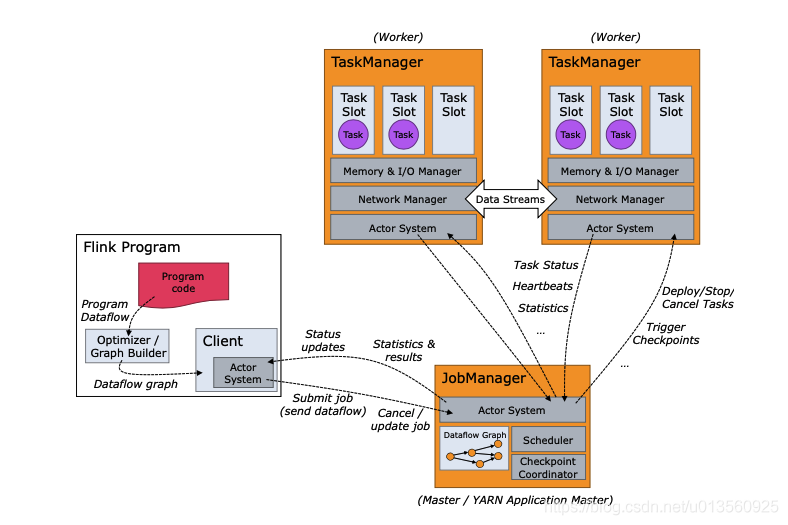
a. JobClient是Flink程序和JobManager交互的桥梁(同Spark Driver),主要负责接收程序、解析程序的执行计划、优化程序的执行计划,然后提交执行计划到JobManager。
b.JobManager是一个进程,主要负责申请资源,协调以及控制整个job的执行过程,具体包括,调度任务、处理checkpoint、容错等等,在接收到JobClient提交的执行计划之后,针对收到的执行计划,继续解析,因为JobClient只是形成一个operaor层面的执行计划,所以JobManager继续解析执行计划(根据算子的并发度,划分task),形成一个可以被实际调度的由task组成的拓扑图,如上图被解析之后形成下图的执行计划,最后向集群申请资源,一旦资源就绪,就调度task到TaskManager。c.TaskManager是一个进程,及一个JVM(Flink用java实现)。主要作用是接收并执行JobManager发送的task,并且与JobManager通信,反馈任务状态信息,比如任务分执行中,执行完等状态,上文提到的checkpoint的部分信息也是TaskManager反馈给JobManager的。如果说JobManager是master的话,那么TaskManager就是worker主要用来执行任务。在TaskManager内可以运行多个task。多个task运行在一个JVM内有几个好处,首先task可以通过多路复用的方式TCP连接,其次task可以共享节点之间的心跳信息,减少了网络传输。<br />2.Task 执行<br /> Spark中每个Stage中的Task会被分配到一个Worker中的 -> Executor容器里面的 -> 一个线程池中被执行,Flink称每个Executor为一个TaskManager,每个TaskManager中会有多个slot作为内存隔离:
Spark:Worker ——> Executor ——> 线程池 ——> 线程
Flink: Worker ——> TaskManager ——> Slot ——> 线程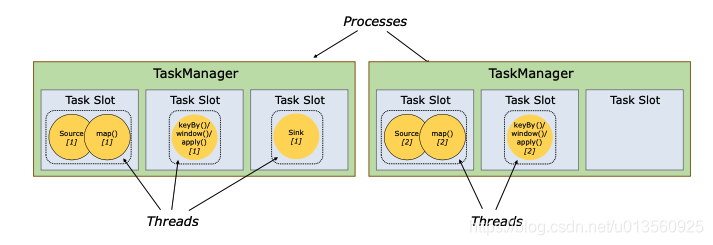
Slot是TaskManager资源粒度的划分,每个Slot都有自己独立的内存。所有Slot平均分配TaskManger的内存,比如TaskManager分配给Solt的内存为8G,两个Slot,每个Slot的内存为4G,四个Slot,每个Slot的内存为2G,值得注意的是,Slot仅划分内存,不涉及cpu的划分。同时Slot是Flink中的任务执行器(类似Storm中Executor),每个Slot可以运行多个task,而且一个task会以单独的线程来运行。Slot主要的好处有以下几点:<br />可以起到隔离内存的作用,防止多个不同job的task竞争内存。<br />Slot的个数就代表了一个Flink程序的最高并行度,简化了性能调优的过程<br />允许多个Task共享Slot,提升了资源利用率,举一个实际的例子,kafka有3个partition,对应flink的source有3个task,而keyBy我们设置的并行度为20,这个时候如果Slot不能共享的话,需要占用23个Slot,如果允许共享的话,那么只需要20个Slot即可(Slot的默认共享规则计算为20个)。
Slot 注意点:
a.隔离内存
b.Slot共享并不是必须配置,但是启用可以加速任务执行
c. Task 共享同一个Slot,需要满足:不同Task但是属于同一个SlotShardingGroup,默认所有的Task属于同一 个default组
d.在不开启Slot共享的情况下,Slot数量和Flink并行度相同,Slot 解析资料链接
三:flink的特点
- 事件驱动(Event-driven)
- 基于流处理一切皆由流组成,离线数据是有界的流;实时数据是一个没有界限的流。(有界流、无界流)
分层API
数据模型
- Spark采用RDD模型,spark streaming的DStream实际上也就是一组组小批数据RDD的集合
- flink基本数据模型是数据流,以及事件(Event)序列
运行时架构
- spark是批计算,将DAG划分为不同的stage,一个完成后才可以计算下一个
- flink是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点处理
五:Flink部署
1 standalone
2 yarn
- Session Cluster模式
- Session-Cluster 模式需要先启动集群,然后再提交作业,接着会向 yarn 申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到 yarn 中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作业共享 Dispatcher 和 ResourceManager;共享资源;适合规模小执行时间短的作业。
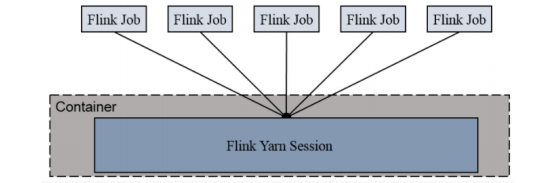
在 yarn 中初始化一个 flink 集群,开辟指定的资源,以后提交任务都向这里提交。这个 flink 集群会常驻在 yarn 集群中,除非手工停止。
- 启动hadoop集群(略)
- 启动yarn-session./yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d其中:
- -n(—container):TaskManager的数量。
- -s(—slots):每个TaskManager的slot数量,默认一个slot一个core,默认每个taskmanager的slot的个数为1,有时可以多一些taskmanager,做冗余。
- -jm:JobManager的内存(单位MB)。
- -tm:每个taskmanager的内存(单位MB)。
- -nm:yarn 的appName(现在yarn的ui上的名字)。
- -d:后台执行。
- 执行任务./flink run -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar —host lcoalhost –port 7777
- 去 yarn 控制台查看任务状态
取消
yarn-sessionyarn application --kill application_1577588252906_0001
- Per Job Cluster模式
- 一个 Job 会对应一个集群,每提交一个作业会根据自身的情况,都会单独向 yarn 申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享 Dispatcher 和 ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。
每次提交都会创建一个新的 flink 集群,任务之间互相独立,互不影响,方便管理。任务执行 完成之后创建的集群也会消失。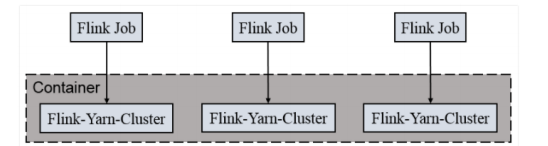
- 启动hadoop集群(略)
不启动yarn-session,直接执行
job./flink run –m yarn-cluster -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host lcoalhost –port 7777
3 kubernetes
容器化部署时目前业界很流行的一项技术,基于Docker镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是Kubernetes(k8s),而Flink也在最近的版本中支持了k8s部署模式。
搭建Kubernetes集群(略)
- 配置各组件的yaml文件
在k8s上构建Flink Session Cluster,需要将Flink集群的组件对应的docker镜像分别在k8s上启动,包括JobManager、TaskManager、JobManagerService三个镜像服务。每个镜像服务都可以从中央镜像仓库中获取。
启动Flink Session Cluster
// 启动jobmanager-service 服务kubectl create -f jobmanager-service.yaml// 启动jobmanager-deployment服务kubectl create -f jobmanager-deployment.yaml// 启动taskmanager-deployment服务kubectl create -f taskmanager-deployment.yaml
访问Flink UI页面集群启动后,就可以通过JobManagerServicers中配置的WebUI端口,用浏览器输入以下url来访问Flink UI页面了:
http://{JobManagerHost:Port}/api/v1/namespaces/default/services/flink-jobmanager:ui/proxy

若有收获,就点个赞吧
0 人点赞
