1 put过程
/*** Implements Map.put and related methods.** @param hash hash for key* @param key the key* @param value the value to put* @param onlyIfAbsent if true, don't change existing value* @param evict if false, the table is in creation mode.* @return previous value, or null if none*/final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;}
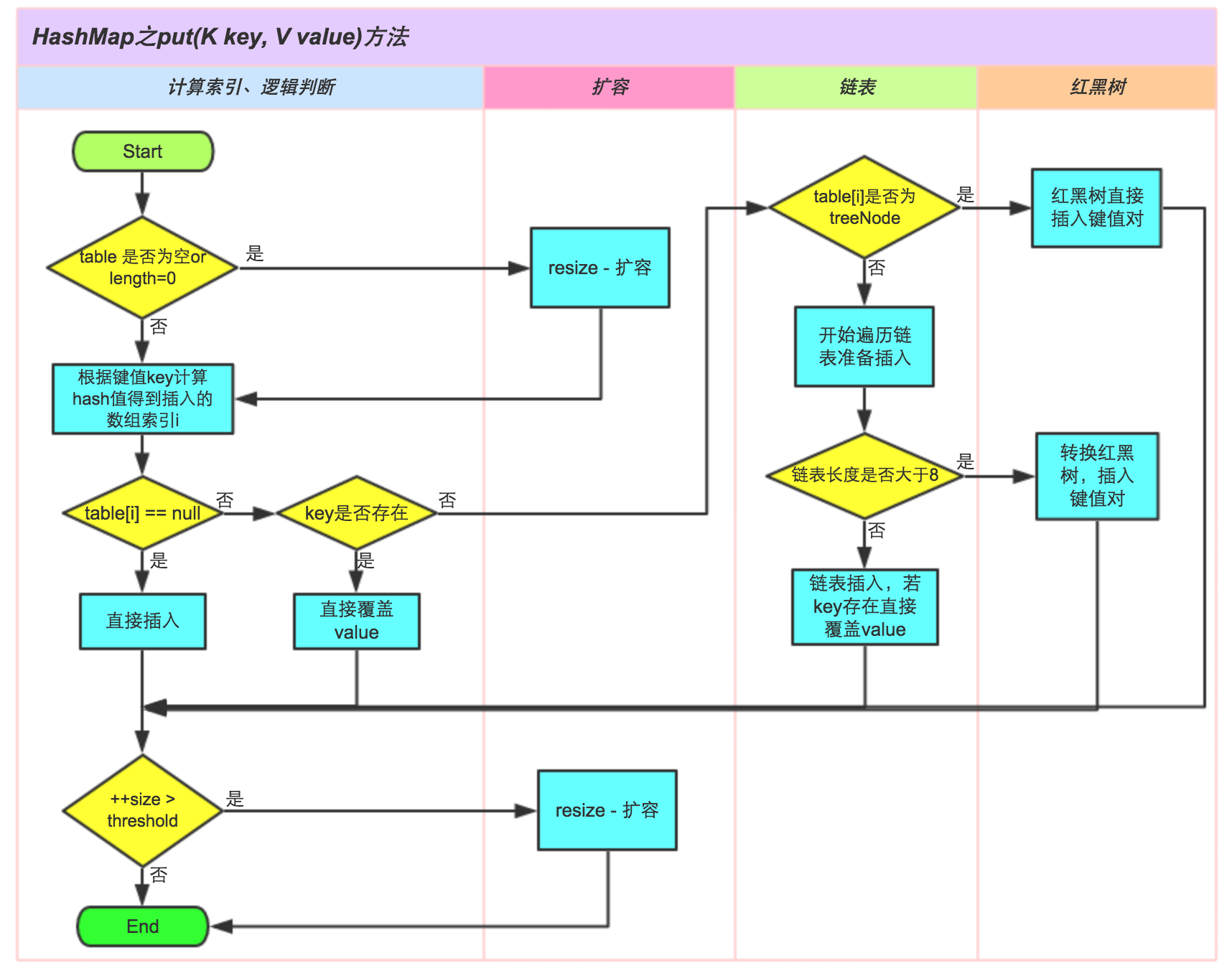
1.判断散列表是否为null,如果为null,重新初始化散列表
2.如果不为null并且没有发生碰撞,直接添加元素到散列表中
3.如果发生碰撞了,并且要插入的元素的桶的hash和key都相等,记录下来,将新值覆盖旧值
4.如果桶hash与key不想等,并且该节点是红黑树结构,调用树的插入方法
5.如果是链表结构,找到了key映射节点,就记录这个节点,退出循环。如果没有找到,在链表尾部插入节点。
插入后如果发现临界值大于TREEIFY_THRESHOLD,转成红黑树
2 解决hash冲突的一般过程
- 开放地址法:此处不留爷,我去下一家
- 分离链表法:就像窗口打饭,来一个打饭的,跟在后面就行了,构成链表
3 hashMap扩容阈值为何是2的整数幂?
~~ 初始容量为何是16
扩容代码:/*** Initializes or doubles table size. If null, allocates in* accord with initial capacity target held in field threshold.* Otherwise, because we are using power-of-two expansion, the* elements from each bin must either stay at same index, or move* with a power of two offset in the new table.** @return the table*/final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;if (oldCap > 0) {if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold}else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}threshold = newThr; //threshold:扩容阈值loadFactor(0.75)*length(16)@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;if (oldTab != null) {for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // preserve orderNode<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;}
容量计算方法:
public HashMap(int initialCapacity, float loadFactor) {......this.threshold = tableSizeFor(initialCapacity);}static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}
总结:为什么这里一定要指定容量为2的n次方呢?
当length总是 2 的n次方时,h& (length-1)运算等价于对length取模,也就是h%length,但是&比%具有更高的效率。这样也能使hashcode的取模结果更为平均,尽量的减少冲突
下面我们讲解下JDK1.8做了哪些优化。经过观测可以发现,我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。看下图可以明白这句话的意思,n为table的长度,图(a)表示扩容前的key1和key2两种key确定索引位置的示例,图(b)表示扩容后key1和key2两种key确定索引位置的示例,其中hash1是key1对应的哈希与高位运算结果。
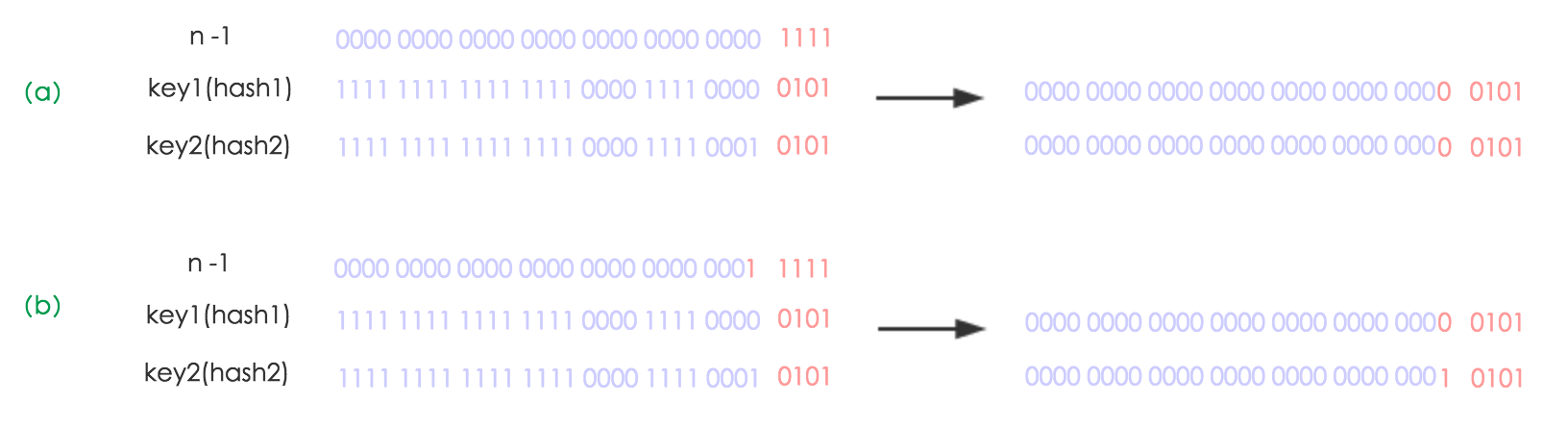
元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化: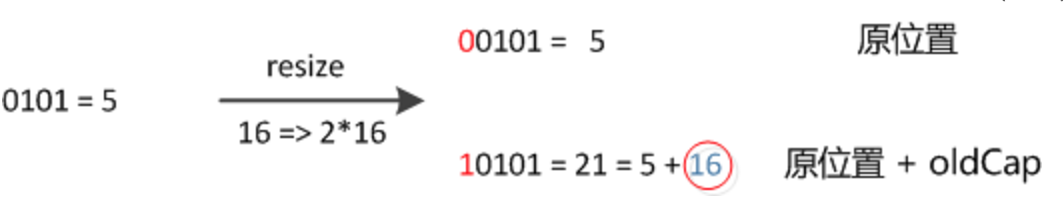
因此,我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”
4 为什么在链表长度为 8 的时候转红黑树,为啥不能是 9 是 10?
* threshold of 0.75, although with a large variance because of* resizing granularity. Ignoring variance, the expected* occurrences of list size k are (exp(-0.5) * pow(0.5, k) /* factorial(k)). The first values are:** 0: 0.60653066* 1: 0.30326533* 2: 0.07581633* 3: 0.01263606* 4: 0.00157952* 5: 0.00015795* 6: 0.00001316* 7: 0.00000094* 8: 0.00000006* more: less than 1 in ten million
总结:随机hash码下,哈希表中频率分布遵循泊松分布(单位(时间)内出现的次数),长度为8,出现的概率为千万分之6,概率极低
5 为什么要转红黑树?
转红黑树代码:
/*** Replaces all linked nodes in bin at index for given hash unless* table is too small, in which case resizes instead.*/final void treeifyBin(Node<K,V>[] tab, int hash) {int n, index; Node<K,V> e;if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)resize();......}
问题博客
总结:① 在获取数据的时候,链表复杂度为O(n),而链表复杂度为O(logN)
② 为何不直接使用红黑树,因为树节点的大小是链表节点大小的两倍,所以只有在容器中包含足够的节点保证使用才用它。显然尽管转为树使得查找的速度更快,但是在节点数比较小的时候,此时对于红黑树来说内存上的劣势会
6 JDK1.8做了那些改变?
- hash表由原来的“数组+链表”——>”数组+链表+红黑树”
- 链表增加节点“头插法”——>”尾插法”(避免死锁)
参考文档

若有收获,就点个赞吧
0 人点赞
