论文链接:https://arxiv.org/abs/1902.09154 博客:
0. 摘要
背景:随着电商平台提供的服务种类越来越多,评价其成功与否的指标也变得越来越多目标 (multi-targeting)
本文提出了 DBMTL (Deep Bayesian Multi-Target Learning) 框架,是一种将目标事件建模为贝叶斯网络的多目标优化框架
- 目标事件被建模为贝叶斯网络的形式,其中有向链接由隐藏层参数化,并通过训练样本进行学习
- 贝叶斯网络的结构由模型选择决定
- 该框架被应用于淘宝直播的推荐,同时对 点击率(CTR)、用户在直播房间停留时间、购买行为和交互 等多个目标进行优化(并取得平衡)
与其他 MTL 框架(多目标学习框架)和非 MTL 模型相比,本文提出的方法有显著的提升
优点:
- 实践表明,通过使用集成的因果结构,可以有效地使一个目标的学习从其他目标中受益,产生显著的协同效应,从而提高所有目标的学习效果
- 由 DBMTL 指导的神经网络架构适用于连接特征和多目标的一般概率模型,其假设条件比本文讨论的其他方法弱。这种理论上的一般性带来了对多种目标分布(包含稀疏目标和连续值目标)可实践的推广能力
1. 引言
淘宝直播为用户提供了丰富的交互方式,不仅可以让用户观看、评论、点赞(like)、与直播主持人建立联系,还提供了添加到购物车、购买等行为。评价淘宝直播这种多媒体平台的标准是多维的,不仅涉及点击率(CTR),还涉及许多和用户体验相关的指标,eg. 平均用户停留时间、交易链中的许多其他环节。对于这样多维的评价系统,推荐系统的设计自然是多目标的,将点击率等多种用户行为加入到有标注的数据系统
在推荐系统中,多目标学习(MTL,Multi-Target Learning)一直是一个非常有用的研究方向
- 一个特别重要的案例:电商 or 广告平台,同时追求点击率 (CTR) 和转化率 (CVR)
进行多目标学习的动机可以归结为两个方面:
- 平衡多种性能指标,尤其是相互冲突的性能指标
- 通常是一项业务需求(business requirement),比如淘宝直播业务追求的不仅是用户的关注度(CTR),还有用户体验(直播间的停留时间)、社交关系建立(follow 关注)、交易转化率
- 目标之间的平衡通常靠在训练和推理时使用权重来实现
- 结合辅助目标信息,以提升主要目标的预测精度(本文主要关注、讨论的点)
本文主要探讨的是上面动机的第二点:结合辅助目标信息,以提升主要目标的预测精度
- 在许多实际应用中,多个目标实际上是高度相关的,并且具有显著的协同潜力,而不是相互独立 or 相互抑制
- 在这种情况下,不同目标引导的梯度下降方向实际上可以引导彼此朝着全局更好的解决方案前进,而不是相互角力以达到平庸的妥协
- 这条线上的模型设计方法就是试图找到一个模型,能更好地表达目标之间潜在的相关性
- 在深层网络中的实现方式:硬参数共享(hard parameter sharing)、软参数共享(soft parameter sharing)以及 十字绣网络(cross-stitch networks)
- 从贝叶斯网络的角度来看,共享层生成多目标公共的 parents,而非共享参数生成不同的 parents。也就是说,多目标之间可以有有共同的或不同的原因
在实践中,只要适当地调整参数和共享结构,通过共享和不共享的参数,实现公共的和不同的先驱 (priors) ,就能取得令人满意的结果。然而,从更广泛的角度来看,这种形式并没有捕捉到一个事实:不同的目标之间相互可以产生直接的因果效应
- eg. 淘宝直播的 case:用户点击并进入直播房间之前,不能进行任何的直播间操作 or 购买行为
- 像上面这样明确的因果关系可以被硬编码到模型中,以规范其行为,ESMM 就是这样做的
- 但对于没那么明显的关系,硬编码并不容易
为了处理需要学习的目标之间的直接因果关系,本文建议从数据中学习跨目标事件的贝叶斯网络
- 一个轻量级且诱人的解决方案:只使用目标节点估计估计贝叶斯网络,切断特征侧,然后重新安装任何复杂的特征侧深度网络来进行微调
- 问题:当分别评估这两个网络时,引入了“explaining-away”的问题
- 考虑到现在的推荐系统中特征侧的深度网络结构越来越复杂,复杂的特征信息对目标关系的影响也越来越大,分开的评估流程不太可能取得好的效果
- 在没有特征证据的情况下,目标之间的因果关系可能是模糊的
- eg. 用户在直播间的停留时间和购买行为的联合分布,可能非常依赖于直播和用户本身的特征
以上这些,都是导致本文提出 DBMTL (Deep Bayesian Multi-Target Learning) 这一集成贝叶斯框架 的灵感和考量
综上所述,DBMTL 是一个同时建模了 特征-目标 & 目标-目标 之间关系的集成前馈网络
- 相比之前的方法,该框架基于更弱的概率假设
- 本文尝试通过目标节点之间直接的前馈 MLPs 来建模多个目标之间的因果关系,并通过评估和模型选择来调整每个前馈链路的方向
- 通过让模型自动从数据中学习交叉推理参数和方向,避免了对目标事件之间的因果关系做出错误的先验假设
2. 深度贝叶斯多目标学习 DBMTL (Deep Bayesian Multi-Target Learning)
本章节,
- 首先,将单目标/多目标预测问题形式化为其最抽象的概率形式
- 然后,讨论了以往的模型所采用的各种假设
- 最后,介绍了 DBMTL,并描述了它是如何弱化这些假设的
2.1 多目标学习的概率公式
对于单目标 l:以 CTR 预估为例,概率公式为
在概率形式下,在推荐系统中学习 CTR 预测的模型可以形式化为:将点击目标的条件概率和训练数据进行拟合
- x:一个曝光的特征;l:这个曝光是否被点击的 label;H:模型的参数
- 学习过程试图拟合模型 H,来最大化概率

- 在没有正则化的情况下,这是一个最大似然估计(MLE)
- H 上的正则化通常对应于 H 上的某种先验假设,因此是一个最大后验概率估计(MAP),因此最大化

对于多目标:以两个待预估的目标 l、m 为例,概率公式为 
- 以淘宝直播为例:
- l:二值变量,代表用户是否点击并进入直播间
- m:二值变量,代表用户是否点击商品列表按钮(商品列表按钮将用户引导到直播主持人要介绍的商品列表,点击商品列表按钮代表着用户想要购买某件商品)
- 如果是多个目标,则概率公式为

2.2 目标变量的分离
当我们有一个单一的二元(或多类)目标时,预测的最后阶段通常被建模为 Logistic 回归(或 softmax 回归)。当我们有多个二元目标,可以在每个目标空间的笛卡尔空间中将它们一起建模为多分类问题。
但当目标数量相当多时,笛卡尔空间中地类别数量呈指数增长。组合目标值的每个样本变得非常稀疏,使得预测性能迅速恶化。
因此 ,通常对概率模型做一定的假设,来将联合概率分布分解成更小的联合分布或独立分布,来避免这种指数空间扩张
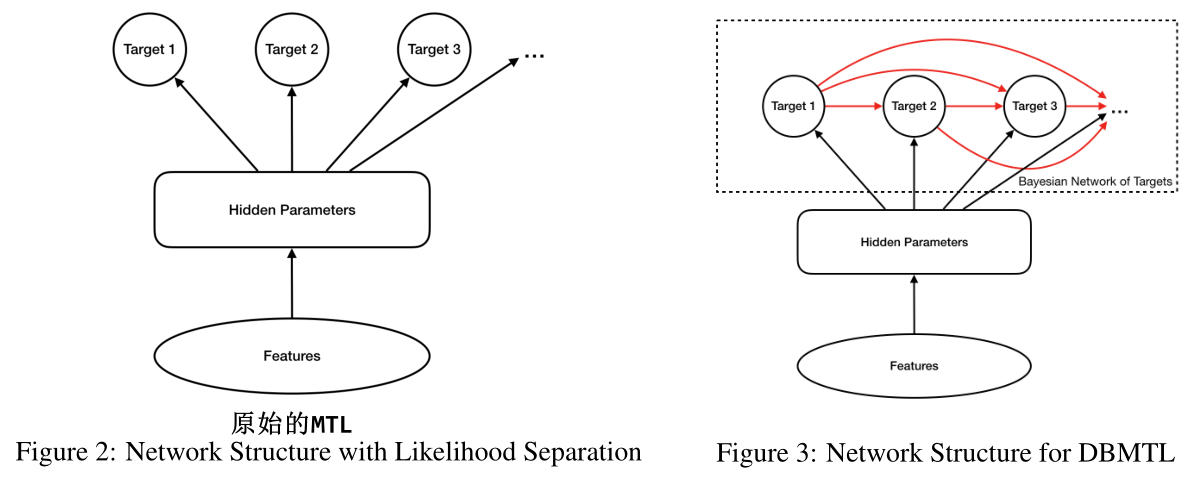
原始的多目标学习 vanilla MTL(也称为 share-bottom):
没有刻画目标之间的联系,而是通过底层的共享机制来完成
- 假设两个目标事件概率独立,则可以将概率公式分解为:

- loss 被分成两个不同的项,标签控件的维度灾难就消失了
- 网络拓扑结构如下图 2 所示,隐藏层可以使用各种不同的网络结构,但在最后一层,向不同的 targets heads 伸出独立的前馈分支
但是,这种很强的目标独立性假设是不必要的
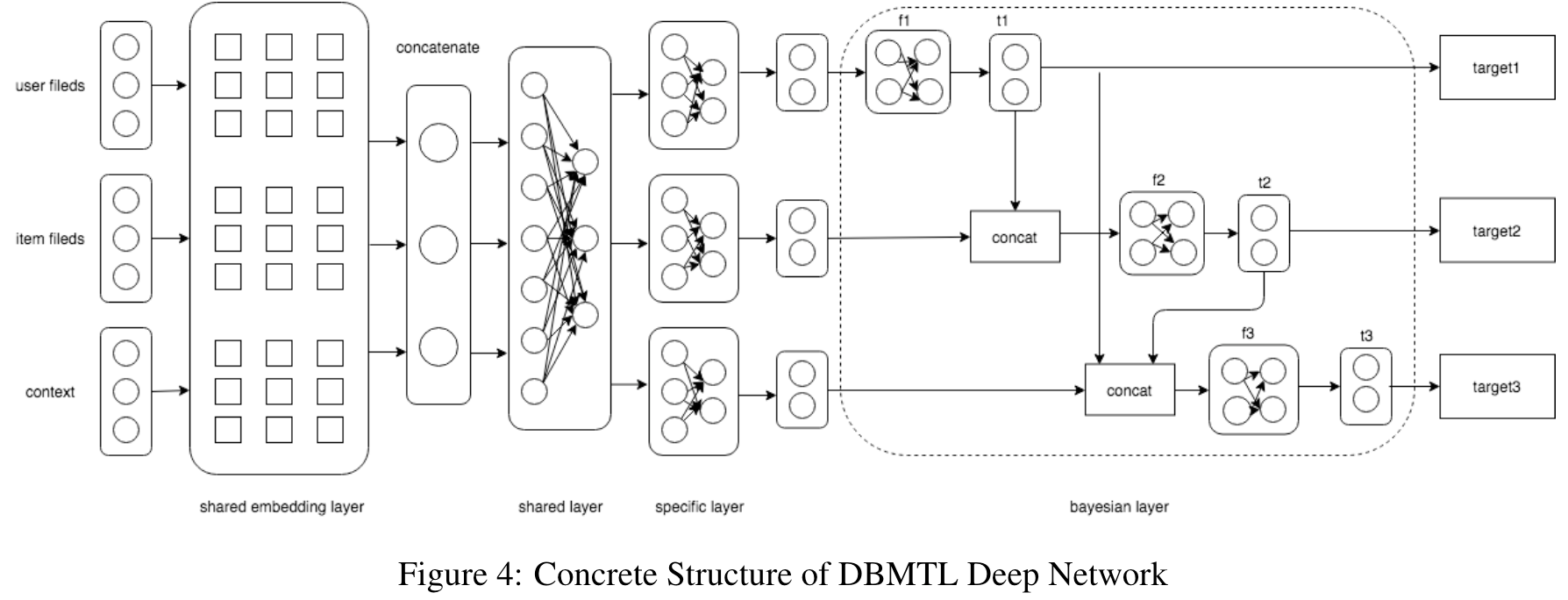
深度贝叶斯多目标学习 DBMTL:为了捕捉目标之间可能存在的因果关系
- 使用贝叶斯的形式,可以将这种似然表示为:

- 需要的假设更弱:
 是可以被有效学习的(即目标 m 依赖于 l,l 是因,m是果)
是可以被有效学习的(即目标 m 依赖于 l,l 是因,m是果) - 拓扑结构如上图 3 所示
模型选择:
当两个目标事件之间的因果关系方向不明确时,让跨目标的关系变得可学习 就更为重要
- 在这种情况下,两个模型
 和
和  都可以训练和测试,然后做模型选择,决定哪个更好
都可以训练和测试,然后做模型选择,决定哪个更好 - 问题不在于哪种结构是正确的(从贝叶斯的观点看,两种都是正确的),而在于哪一种结构更容易从数据中学习
以上的这些讨论都可以很自然地扩展到两个以上的目标,即 
- 以淘宝直播为例,目标事件包括:用户点击、直播间购买行为、用户在一个会话中的停留时间、直播间中的互动、建立关注关系等
- 这些目标事件大多是二值的,
- 但当有实数值目标(eg. 用户停留时间)进入目标集合,会引起一些细微的问题,这种情形下,
 应该被理解为概率密度,而不是概率,同时本节所有的推导和结论仍然成立
应该被理解为概率密度,而不是概率,同时本节所有的推导和结论仍然成立
2.3 模型结构的选择
当需要预测目标很多,且因果关系模糊时,通常不太可能遍历所有可能的配置进行实验并比较结果,因为目标之间的关系有  种,所有可能的贝叶斯网络配置有
种,所有可能的贝叶斯网络配置有 
贝叶斯网络结构学习的简单技巧可以用来缩小探索空间:
- 一种方法:增量、贪婪地构建贝叶斯网络,即逐渐增加目标节点,并固定现有的边不变,只迭代与新的目标节点相关的链接来确定最佳的方向,将复杂度降低到

- 另一种方法:即与直觉和因果关系的先验知识,提供一个初始化的网络结构,然后在一定的迭代范围内应用局部变化,保持好的局部变化,并丢弃坏的变化
- 一些原则可以引导我们找到好的初始设计:
- 具有自然因果关系的方向 通常比 具有自然反因果关系的方向 好
- 使用一个分布更均匀的目标 来预测 一个分布较不均匀的目标,通常比反过来效果好
- eg. 淘宝直播中,关注按钮的点击率分布就不如宝贝口袋按钮的点击率分布均匀,关注按钮的点击率相对较少,而又接近 1/2 的直播间用户会点击宝贝口袋按钮,因此用关注事件作为原因 结果会比较差,而用宝贝口袋点击率作为因(关注事件作为果)的效果会比较好
- 一些原则可以引导我们找到好的初始设计:
3. DBMTL 的实现和实验
3.1 DBMTL 网络架构
DBMTL 框架包含:输入层、共享 embedding 层、共享层、特定层、贝叶斯层
- 输入层
- 共享 embedding 层:是一个共享的查找表,其中,共享的 embedding 层被跨目标学习
- 共享层:是 MLP,捕捉不同目标共同的特征
- 特定层:是 MLP,捕捉不同目标各自特定的特征
- 贝叶斯层:是 DBMTL 中最重要的部分
- 实现了贝叶斯公式:

- 相应的负对数似然损失:

- 出于实际的原因,对损失函数的各项使用了不同的权重,来控制各种目标的相对重要性,因此损失函数/目标函数变为:

- 其中,

 用全连接感知机/MLP 实现,来学习各个目标之间的隐藏关系
用全连接感知机/MLP 实现,来学习各个目标之间的隐藏关系- 每个 f 将其输入的 embedding 拼接(concat),作为 MLP 的输入,并输出 输出目标的 embedding
- 每个 目标embedding 经过一个最终的线性逻辑层,生成对应目标的最终概率值
- 其中,
- 实现了贝叶斯公式:
在本文的实验中,DBMTL 是用 Tensorflow 的 Wide&Deep 框架实现的。通过最小化目标函数来学习模型的参数,采用了 Adam 优化器来加速收敛,batch size = 2000,学习率为 0.001.为了避免过拟合,在网络层中使用了 L1 正则化、L2 正则化、Dropout 等技术。对于大约 10 亿个训练样本,模型的超参数调整为:embedding size = 8,共享层的维度 = [256, 128, 64],特定层的维度 = [54, 32],贝叶斯层的维度 = [32]
3.2 实验设置
淘宝直播的多个目标:
| 目标 target | 说明 | loss heads |
|---|---|---|
| CTR 点击率 Click Through Rate |
对于所有曝光,导致点击并进入直播间的曝光的占比 | logistic loss head (因为对应于二值输出) |
| CGR 商品列表转化率 Goodslist Conversion Rate |
进入直播间的用户中,点击了宝贝口袋按钮的用户的占比 | |
| CFR 关注转化率 Follow Conversion Rate |
进入直播间的用户中,进行了关注主播行为的用户的占比 | |
| CCR 评论转化率 Comment Conversion Rate |
进入直播间的用户中,进行了评论行为的用户的占比 | |
| CLR 喜欢转化率 Like Conversion Rate |
进入直播间的用户中,点击了喜欢主播按钮的用户额占比 | |
| AST 平均停留时间 Average Stay Time |
用户在直播间中停留的平均时间 考虑到实值的尺度问题,使用停留时间的对数 |
MSE 均方误差, Mean Square Error (因为是实值回归问题) |
实验的数据集来自线上的日志。在某个时间窗口内,取前 15 天的数据作为训练数据,而下一天的样本用于测试性能。从每个数据样本中提取出了超过 100 多个特征,包括许多大规模的稀疏 ID 类特征。
对于标签部分,由于所有的直播间交互都首先依赖于用户进入了直播间,只有当 CTR 的 label 为“on”时,CGR,CFR,CCR,CLR,AST 的 labels 才被转为“on”(对于二值的赋值为 1,对于 AST 赋值为本身,即平均停留时间),否则为 off(对于 二值的赋值为 0,对于 AST 赋值为 0.0)
3.3 多目标的总体性能
多目标之间的结构设计:遵循自然的因果原理,CTR 指向 CGR,CFR,CCR,CLR,AST。出于商业上对各个目标重要性的考量,损失函数中 CTR, CGR,CFR,CCR,CLR,AST 的权重分别设置为 [0.7, 0.05, 0.05, 0.0, 0.0, 0.1]
- 用户停留时间 相对 商品列表转化率和关注转化率 来说,是更重要的辅助目标
- CCR 和 CLR 目标的权重故意保留为 0.0,来测试模型对非训练目标的泛化能力,以便在记过分析中更加清晰
AUC: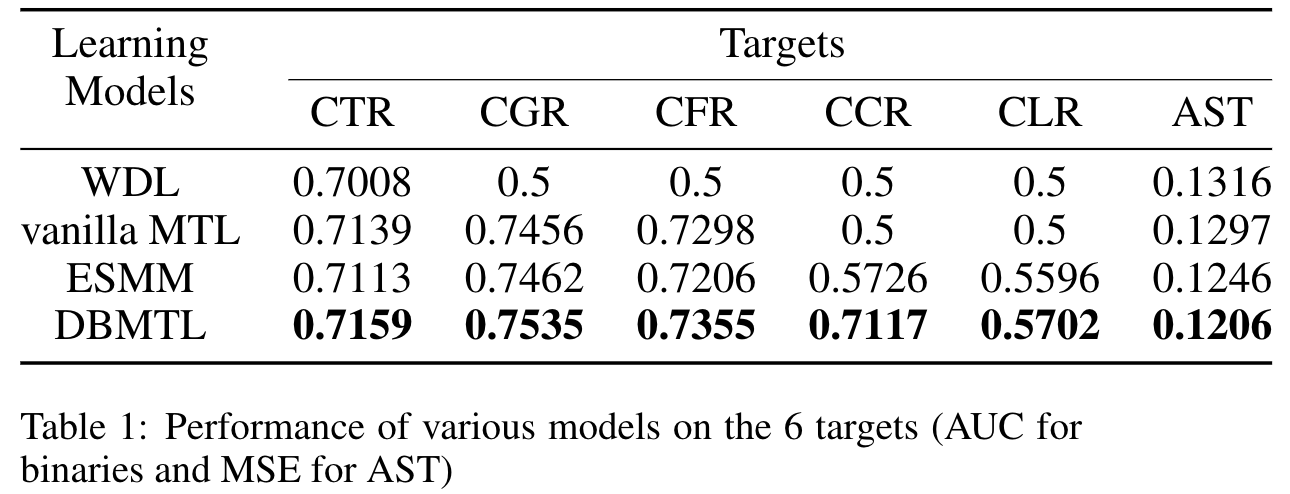
三点结论:
- 多目标模型通常能比单目标模型取得更好的性能表现
- 尽管单目标模型被特别地调优来优化主目标 CTR,但多目标模型在主目标 CTR 的表现还是更优秀
- 这证明了,加入辅助目标,能改善主目标的性能表现,即便我们并不关注辅助目标
- 因为淘宝直播中的辅助行为(宝贝口袋点击、关注、评论、喜欢和直播间停留时间)都是对直播质量非常强的评价指标,因此是预测 CTR 目标的有效信息来源
- 在三个多目标模型中,DBMTL 在 6 个目标上的性能明显都更好
- 这证明了,用贝叶斯网络对跨目标建模,可以更好地捕捉多目标之间的因果关系,并且预测性能受益于较弱的统计假设
- 这种效应能表现的很好,是因为相关的目标之间具有复杂的黑盒因果关系,用 MLP 能更好的表达这种关系
- 尽管故意保留 CCR 和 CLR 目标不进行训练,ESSM 和 DBMTL 仍能够学习到这两个目标的重要信息(原始的 MTL 并没有这个能力,因为没有建模跨目标之间的关系?)
以上结论,一方面加强了使用辅助目标来增强主目标的优势,另一方面也进一步暗示了目标间的贝叶斯建模的确有利于学习
3.4 目标对的性能
将辅助目标 CGR(正常稀疏性的二值目标,直播间用户点击宝贝口袋按钮的比例很高)、CFR(极度稀疏性的二值目标,直播间用户点击关注按钮的比例很低)、AST(实值目标) 分别和 CTR 组成优化对
三点结论:
- DBMTL 在三个实验中性能都优于其他多目标学习方法,表明了 DBMTL 在各种目标类型中的通用性
- ESSM 和 DBMTL 对建模辅助目标都更有效,但在 CTR-CGR(非稀疏) case 上的提升不如 CTR-CFR(稀疏) case 上显著
- 可能是因为目标之间的相互连接,在学习稀疏目标时,能带来特别的增益,因为稀疏目标可以利用非稀疏的主目标的数据的信息
- 在 CTR-AST(实值)case 下,DBMTL 相对 ESSM 的改进更为显著,体现了 DBMTL 在处理连续值目标时的泛化能力
3.5 不同的贝叶斯结构
贝叶斯网络结构(即,非循环贝叶斯网络的连接方向)会对性能产生重大影响。为了验证 2.3 节提出的设计原则,本文选择了三个目标:CTR、CGR、CFR,共三个结构,分别假设一个目标事件指向另外两个目标事件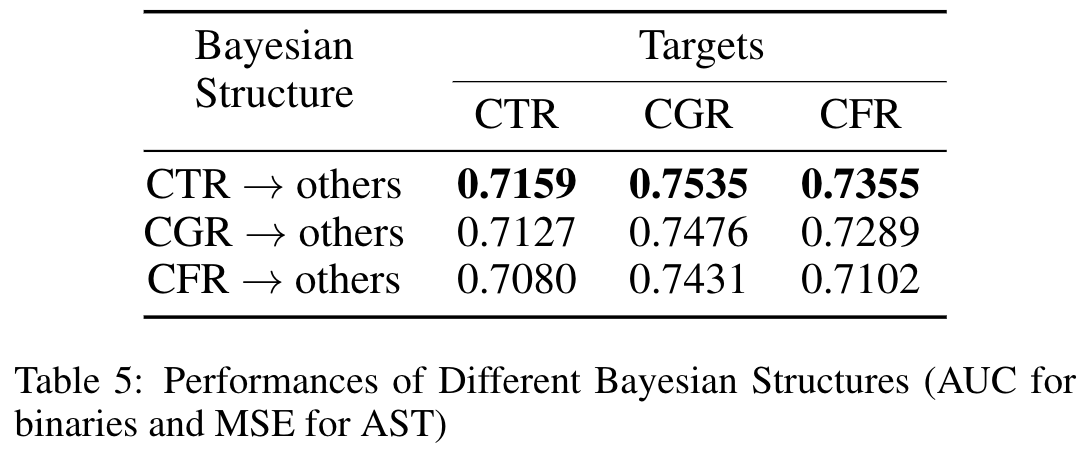
结论:
- 和直觉猜测一样,自然的因果方向 CTR -> others 产生了最好的性能表现(自然的意思是,用户只能在点击并进入直播间后,才能有其它的直播间行为),证明了第一个设计原则:具有自然因果关系的方向 通常比 具有自然反因果关系的方向 好
- 原因:正确的因果关系通常可以更有效地学习和建模
- CGR -> others 方向的性能表现优于 CFR -> others(CGR 的正负样本比率比 CFR 更均匀分布) ,证明了另一个设计原则:使用一个分布更均匀的目标 来预测 一个分布较不均匀的目标,通常比反过来效果好
- 原因:均匀分布的目标比不均匀分布的目标包含更多的信息(熵值更高)
4. 结论
对于多目标学习问题,本文明确提出了 DBMTL 的公式,用对跨目标 heads 的贝叶斯网络结构显式地对不同目标之间的因果关系进行建模
DBMTL 有效的原因:DBMTL 对目标和特征之间的因果关系进行建模的整体方式,削弱了其他深度 MTL 结构为底层概率模型采用的许多假设
DBMTL 并没有对目标分布和类型做具体的假设,因此很容易推广到各种分布和值类型
本文提出了设计贝叶斯结构的两个原则:
- 尊重明确的自然因果关系
- 将熵值更高的目标指向熵值更低的目标

若有收获,就点个赞吧
0 人点赞
