DNN 模型便于处理连续数值型特征,而图像语音等天然满足这一条件,但是 CTR 预估场景会包含大量的离散特征,比如一个人的性别、毕业学校等都属于离散特征。所以用深度学习做 CTR 预估首先要解决的问题是如何表征离散特征,一种常见的方法是把离散特征转换为 One-hot 表示,但是在大型互联网公司应用场景下,特征维度都是百亿以上级别的,如果采用 One-hot 表征方式,意味着网络模型会包含太多参数需要学习。所以目前主流的深度学习解决方案都采用将 One-hot 特征表示转换为低维度实数向量(Dense Vector,类似于 NLP 中的 Word Embedding)的思路,这样可以大量降低参数规模。——2017年AI技术前沿进展与趋势 by 张俊林
1、什么是 Embedding
Embedding(嵌入/向量化/向量映射):是用一个低维稠密的数值向量“表示”一个对象(Object)的方法
- 主要作用:将稀疏向量转换成稠密向量,同时揭示对象之间的潜在关系
- 对象:可以是一个词、一个商品、一部电影等
- “表示”:即 Embedding 向量能够表达相应对象的某些特征,同时向量之间的距离反映了对象之间的相似性
- 即,一个物品能被向量表示,是因为这个向量跟其他物品向量之间的距离反映了这些物品的相似性
- 更进一步,两个向量间的距离向量甚至能够反映它们之间的关系
- Embedding 从另一个空间表达物品(对象),同时揭示物品(对象)之间的潜在关系
- 词 Embedding 向量之间的运算甚至能够包含词之间的语义关系信息,eg.
- 性别关系:
Embedding(woman) - Embedding(man) ≈ Embedding(queen) - Embedding(king) - 时态关系:
Embedding(walking) - Embedding(walked) ≈ Embedding(swimming) - Embedding(swam)
- 性别关系:
- Embedding 在其他领域的应用:
- eg.
Embedding(键盘)和Embedding(鼠标)的距离比较近,而Embedding(键盘)和Embedding(帽子)的距离相对较远
- eg.
- 词 Embedding 向量之间的运算甚至能够包含词之间的语义关系信息,eg.
- 训练方式不同:
- 词向量用大量文本预料进行训练(现在 NLP 领域常用 BERT 等模型预训练)
- 而其他领域的训练样本不同,比如
- 视频推荐领域往往使用用户的观看序列进行电影的 Embedding 化
- 电商平台往往使用用户的购买历史作为训练样本,进行商品的 Embedding 化
1.1 Embedding 的作用/重要性
Embedding 技术对深度学习推荐系统的重要性:是深度学习的“基础核心操作”
- Embedding 是处理稀疏特征的利器:推荐场景中存在大量类别、ID 型特征,使用 one-hot/multi-hot 进行编码,导致样本特征向量极度稀疏,Embedding 层负责将稀疏高维特征向量转换成稠密低维特征向量
- Embedding 可以融合大量有价值信息,本身就是极其重要的特征向量:Embedding 几乎可以引入任何信息进行编码,相较于 MF 等传统方法产生的由原始信息直接处理得来的特征向量,Embedding 的表达能力更强
- Embedding 不仅是一种处理稀疏特征的方法,也是融合大量基本特征,生成高阶特征向量的有效手段
- Embedding 对物品、用户相似度的计算是常用的推荐系统召回层技术:Embedding 更适用于对海量备选物品进行快速初筛,过滤出几千到几百量级的物品用于粗排/精排
- 用 Embedding 方法进行相似物品推荐,几乎成了业界最流行的做法
- eg. Netflix 利用矩阵分解 MF 方法生成电影和用户的隐向量(Embedding),根据用户和物品 embedding 之间的相似性进行推荐,将用户 embedding 周围的电影 embedding 对应的电影推荐给这个用户

2、Word2vec:经典的 Embedding 方法
Word2vec 模型:即 word to vector,是生成对“词”的向量表达的模型
- 训练语料:一组句子组成的语料库,其中一个长为 T 的句子为
 ,假定每个词都和其相邻的词的关系最密切
,假定每个词都和其相邻的词的关系最密切 - 两种形式:
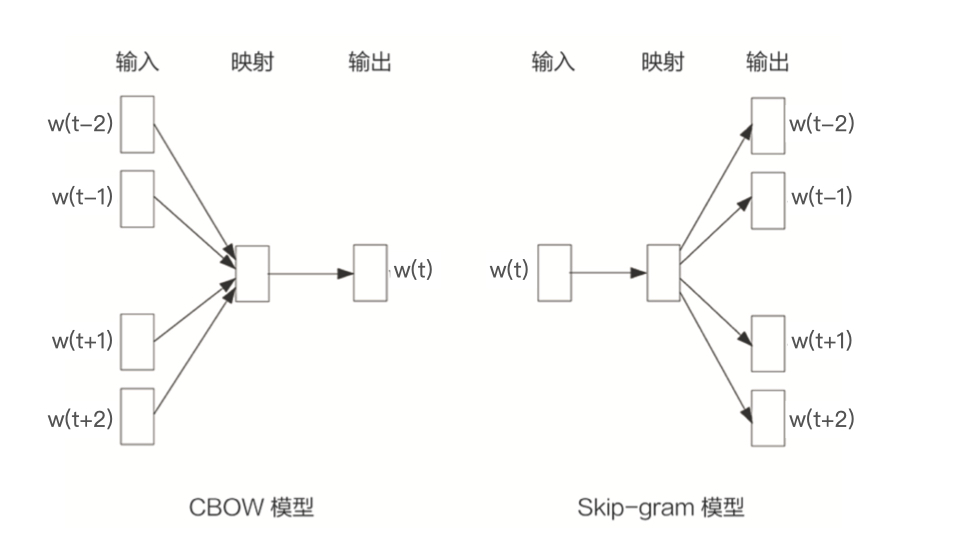
- CBOW 模型:假设句子中每个词的选取都由相邻的词决定
- 输入:
 周边的词,
周边的词,
- 预测的输出:

- 输入:
- Skip-gram 模型:假设句子中的每个词都决定了相邻词的选取
- 输入

- 预测的输出:
 周边的词,
周边的词,
按照一般的经验,Skip-gram 模型的效果会更好一些,以下都以 ski-gram 模型为例)
- 输入
- CBOW 模型:假设句子中每个词的选取都由相邻的词决定
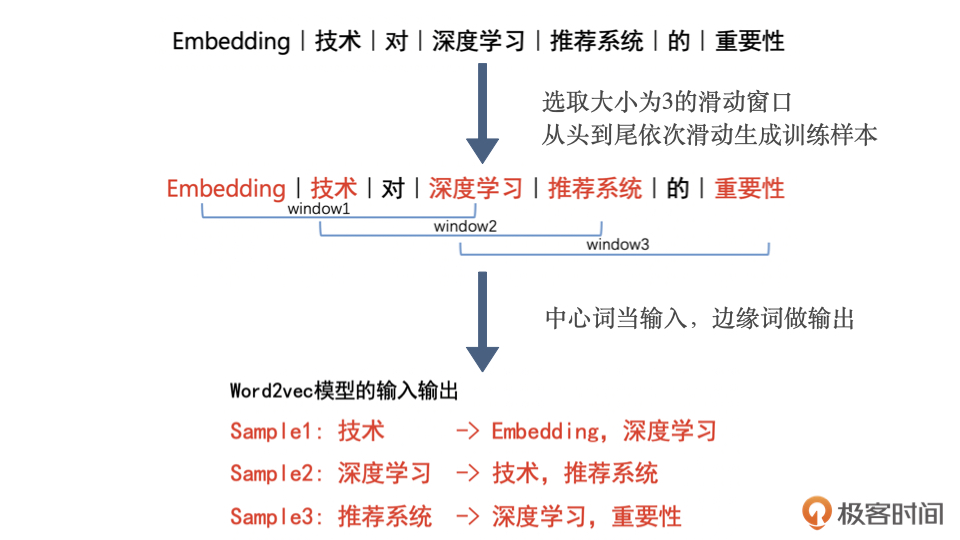
2.1 Word2vec 的训练样本生成过程
训练样本来源:Word2vec 是 NLP 模型,因此训练样本当然是来自语料库
- eg. 我们想训练一个电商网站中关键词的 Embedding 模型,那么电商网站中所有物品的描述文字就是很好的语料库
Word2vec 训练样本的生成过程:通过滑动窗口截取词组,把词组内的词转换成训练样本
- 从语料库中抽取一个句子,选取一个长度为 2c+1(目标词前后各选 c 个词)的滑动窗口,将滑动窗口由左至右滑动,每移动一次,窗口中的词组就形成了一个训练样本。根据 Skip-gram 模型,输入是样本的中心词,输出(label)是所有的相邻词
2.2 Word2vec 的模型结构
基于 Skip-gram 框架的 Word2vec 模型解决的是一个多分类问题,即:输入一个中心词,生成 10000 个词,每个词的概率是多少?
Word2vec 的模型结构:两层神经网络(输入层不算)
- 输入:维度为 V(即语料库词典的大小),输入向量是由输入词转换来的 one-hot 编码向量
- 隐层:维度为 N(最终每个词的 embedding 向量维度也是 N)。隐层没有激活函数
- N 大小的选择需要调参,需要对模型的效果和模型的复杂度进行权衡
- 输出:维度为 V,输出向量是由多个输出词转换来的 multi-hot 向量(相当于多分类问题)。采用 softmax 激活函数
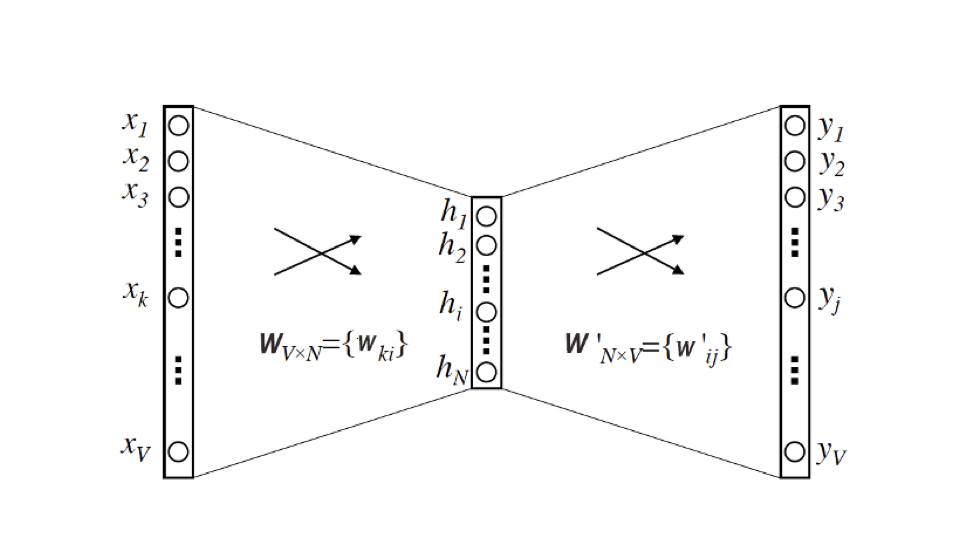
从 Word2vec 模型中提取出词向量的方法:
输入向量矩阵(输入层到隐层的权重矩阵) 的第 i 行的行向量就是第 i 个词的 Embedding(输入时 one-hot 向量,只有第 i 行为 1),维度为 N,即隐层的维度
的第 i 行的行向量就是第 i 个词的 Embedding(输入时 one-hot 向量,只有第 i 行为 1),维度为 N,即隐层的维度
转换为词向量查找表后,每行的权重就成了对应词的 embedding 向量
3、Item2vec:Word2vec 在推荐系统领域的推广

若有收获,就点个赞吧
0 人点赞
