整个空间 多任务学习模型 ESMM,点击转化率预估 pCVR
论文链接:https://arxiv.org/abs/1804.07931 推荐常用算法的实现:https://github.com/yinyajun/Details-In-Recommendation?utm_source=catalyzex.com 博客:
ESMM 的主要思想:将 ctr/cvr 两个目标放在统一的空间里进行训练,以解决 cvr 模型对于曝光样本的不可见和多目标优化、训练的问题
0. 摘要
在推荐和广告等工业应用中,准确地预估点击后的转化率(CVR),对排序系统(ranking system)是至关重要的
传统的 CVR 建模方式:
- 优点:采用流行的深度学习方法,并取得了最先进的性能
- 缺点:在实践中遇到一些任务特定的问题,使得 CVR 建模具有挑战性
- 问题一:传统的 CVR 模型,训练时使用的是被点击的曝光样本(仅点击作为负样本,点击后下单作为正样本),但在推理时使用的是所有曝光样本 对整个空间进行推理,这造成了样本选择偏差问题
- 问题二:此外,还存在极度的数据稀疏问题,使得模型拟合相当困难
本文从一个全新的视角出发,通过充分利用用户行为的顺序模式(即,曝光 -> 点击 -> 转化),对 CVR 进行建模,提出的方法称为 ESMM (Entire Space Multi-Task Model) ,通过以下方法,可以同时消除 样本选择偏差问题 和 数据稀疏问题
- 1)直接在整个空间上建模 CVR
- 2)采用特征表示迁移策略
发布了第一个公开的用于 CVR 建模的数据集,其中的样本对点击和转化标签有着顺序的依赖
1. 引言
本文主要的研究任务:点击后的 CVR 预估
- 用户的行为遵循 曝光 -> 点击 -> 转化 的顺序模式
- 因此,CVR 建模是要对点击后的转化率进行预估,即 pCVR = p(转化|点击,曝光)
传统的 CVR 建模方法:使用和 CTR 预估任务相似的技术,存在一些任务特定的问题
- SSB 样本选择偏差问题 (sample selection bias) :
- 训练数据集:曝光样本集合种被点击的样本子集
- 测试/推理数据集:整个曝光样本集合
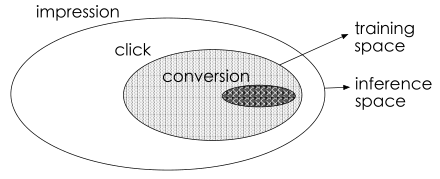
- DS 数据稀疏问题 (data sparsity) :在实践中,为训练 CVR 模型收集的数据量比 CTR 任务少得多,训练数据的稀疏性使得 CVR 模型的拟合变得非常困难
本文提出的 ESMM (Entire Space Multi-Task Model) 方法对 CVR 进行建模
- 优点:通过充分利用用户行为的顺序模式(曝光 -> 点击 -> 转化),使得能够同时消除 SSB 和 DS 问题
- 直接在整个空间上建模 CVR —— 解决 SSB 样本选择偏差问题
- 引入了两个辅助任务:
- 1)预测曝光后的点击率 pCTR (post-view click-through rate)
- 2)预测曝光后的点击转化率 pCTCVR (post-view click through&conversion rate)
- CTCVR 是点击且转化的概率,CTCVR = CTR * CVR
- 不再是直接用点击后的曝光样本子集来训练 CVR 模型,而是将 pCVR 作为中间变量,和 pCTR 相乘得到 pCTCVR(pCTCVR = pCVR* pCTR)
- pCTCVR 和 pCTR 都是在整个曝光样本集空间上预测的,因此解决了 SSB 问题
- 引入了两个辅助任务:
- 参数迁移学习(特征表示迁移策略) —— 解决 DS 数据稀疏问题
- CVR 网络和 CTR 网络共享特征表示参数,而 CTR 网络有更丰富的样本用于训练,这种参数迁移学习显著地减轻了 DS 问题
本文的数据集来自于淘宝推荐系统的日志,完整的数据集包含了 8.9 亿个包含【点击,转化】顺序标签的样本
2. 方法
2.1 符号标记
观测数据集 
样本  ,取自分布
,取自分布 
 是特征空间,
是特征空间, 是标签空间,N 是曝光样本总数
是标签空间,N 是曝光样本总数  是观测到的曝光的特征向量,通常是一个高维的稀疏向量,包含多个域(user fields、item fields 等)
是观测到的曝光的特征向量,通常是一个高维的稀疏向量,包含多个域(user fields、item fields 等)- y、z 是二值标签,y = 1 代表发生点击事件,z = 1 代表发生转化事件
- y->z:揭示了点击和转化标签的顺序依赖关系,当转化时间发生时总是先有一个点击事件
点击后的 CVR 建模(post-click CVR)是要预估 pCVR = p(z = 1|y = 1, x)
两个相关的概率:
- 曝光后的点击率 pCTR (post-view click-through rate):pCTR = p(y = 1|x)
- 曝光后的点击转化率 pCTCVR (post-view click through&conversion rate):pCTCVR = p(y = 1, z = 1|x)
这几个概率之间的关系:
2.2 CVR 建模和挑战
传统的基于深度学习对 CVR 建模的方法,基本都遵循类似的 Embedding&MLP 网络架构,2.3 节的图的左半边就说明了这种结构,称为 基础模型(BASE model),直接预估 点击后的转化率 pCVR = p(z = 1|y = 1, x) ,用被点击了的曝光样本子集( ,M 是所有曝光样本中被点击的样本数)来训练模型。
,M 是所有曝光样本中被点击的样本数)来训练模型。 中被转化了的样本为正样本,未转化的为负样本。在实践中,CVR 建模遇到了一些任务特定的问题,具有挑战性
中被转化了的样本为正样本,未转化的为负样本。在实践中,CVR 建模遇到了一些任务特定的问题,具有挑战性
2.2.1 SSB 样本选择偏差问题 (sample selection bias)
传统的 CVR 建模通过引入辅助特征空间  来预估
来预估 
 是和
是和  相关的有限特征空间,对
相关的有限特征空间,对  ,存在一个 pair:
,存在一个 pair: ,
, ,
,  是
是  的点击标签
的点击标签 是在特征空间
是在特征空间  、被点击的曝光样本子空间
、被点击的曝光样本子空间  上训练
上训练- 在测试/推理阶段,
 的预估是在整个特征空间
的预估是在整个特征空间  上,。。。。。。
上,。。。。。。
这受到 很少发生的点击事件 的影响,而点击事件的概率在空间  的不同区域是不同的
的不同区域是不同的
并且, 和
和  可能很不一样,这会导致训练样本的分布相对于真实分布存在偏差,并降低 CVR 建模的泛化性能
可能很不一样,这会导致训练样本的分布相对于真实分布存在偏差,并降低 CVR 建模的泛化性能
2.2.2 DS 数据稀疏问题 (data sparsity)
传统的 CVR 建模是使用被点击了的曝光样本子集  来训练 CVR 模型。极少发生的点击事件导致 CVR 建模的数据极其稀疏。直观上,这通常比相关的 CTR 任务少 1-3 个数量级
来训练 CVR 模型。极少发生的点击事件导致 CVR 建模的数据极其稀疏。直观上,这通常比相关的 CTR 任务少 1-3 个数量级
除了以上两个问题,现有的 CVR 建模还有 延迟反馈 等问题
2.3 ESMM (Entire Space Multi-Task Model)
ESMM 的架构图如下所示,很好地利用了用户行为的顺序模式。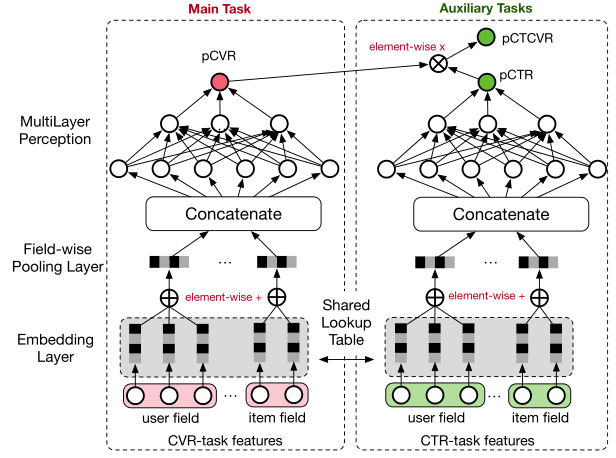
本文提出的用于 CVR 建模的 ESMM 方法的总体架构图
ESMM 引入了 CTR 和 CTCVR 这两个辅助任务,来:
- 帮助在整个空间上建模 CVR
- 特工特征表示迁移学习
同时消除了上面提到的 SSB 样本选择偏差问题 和 DS 数据稀疏问题
ESMM 包含两个子网络:两个自网络的 Embedding 参数共享
- CVR 网络(上图左半部分)
- CTR 网络(上图右半部分)
CTCVR 将 CTR 和 CVR 网络的输出相乘作为输出
2.3.1 在整个空间上建模 CVR
2.1 节提到的各个概率之间的关系的公式可以转换为: ,即 pCVR = pCTCVR / pCTR
,即 pCVR = pCTCVR / pCTR
- 这里 pCTCVR 和 pCTR 都是在整个曝光数据集
 上建模的 (两个模型分别独立的训练)
上建模的 (两个模型分别独立的训练) - 也就是说,通过对 pCTCVR 和 pCTR 的预估,pCVR 可以在整个输入空间
 上导出,这就直接解决了 SSB 样本选择偏差问题
上导出,这就直接解决了 SSB 样本选择偏差问题 - 但 pCTR 是一个很小的数字,除以 pCTR 会引发数值不稳定性。
ESMM 通过乘法形式避免了这个问题
- 在 ESMM 中,pCVR 只是一个受方程
 约束的中间变量
约束的中间变量 - pCTCVR 和 pCTR 是 ESMM 实际上在整个空间上预估的主要因子
- 乘法形式使得这三个相关且共同训练的评估对象能够利用数据的顺序模式,并且在训练期间相互交流信息
- 此外,这还保证了 pCVR 的预估值在 [0, 1] 之间,,而如果用除法方法则预估值可能超过 1
ESMM 的损失函数,包含 CTR 和 CTCVR 两个任务的损失项(这两个任务都是在整个曝光样本集合上计算的),没有使用 CVR 任务的 loss

 分别是 CTR 网络和 CVR 网络的参数
分别是 CTR 网络和 CVR 网络的参数 是交叉熵损失函数
是交叉熵损失函数
- 将 y->z 分解为两部分: y 和 y&z,实际上利用了点击和转化标签的顺序依赖性
2.3.2 特征表示迁移
Embedding 层将大规模稀疏输入映射到低维的表示向量,贡献了深度网络的大部分参数,因此需要大量的训练样本来学习
在 ESMM 中,CVR 网络和 CTR 网络的 embedding 字典是共享的,遵循了特征迁移学习范式
CTR 任务使用所有曝光样本作为训练样本,比 CVR 任务数据充足很多,ESMM 的参数共享机制使得 ESMM 中的 CVR 网络能够从未点击的曝光样本中学习,为缓解数据稀疏问题提供了极大帮助

若有收获,就点个赞吧
0 人点赞
