注:以下代码分析版本为开源版本 ClickHouse v21.8.10.19-lts。类图、顺序图未严格按照 UML 规范;为方便表意,函数名、函数参数等未严格按照原版代码。
HouseKeeper Vs Zookeeper
- Zookeeper java 开发,有 JVM 痛点,执行效率不如 C++;Znode 数量太多容易出现性能问题,Full GC 比较多。
- Zookeeper 运维复杂,需要独立部署组件,之前出问题比较多。HouseKeeper 部署形态比较多,可以 standalone 模式和集成模式。
- Zookeeper ZXID overflow 问题,HouseKeeper 没有该问题。
- HouseKeeper 读写性能均有提升,支持读写线性一致性,关于一致性的级别参见https://xzhu0027.gitbook.io/blog/misc/index/consistency-models-in-distributed-system。
HouseKeeper 代码与 CK 统一,自主闭环可控。未来可扩展能力强,可以基于此做 MetaServer 的设计开发。主流的的 MetaServer 基本都是 Raft+rocksDB 的组合,可以借助该 codebase 进行开发。
Zookeeper Client
Zookeeper Client 完全不需要修改,HouseKeeper 完全适配 Zookeeper 的协议。
- Zookeeper Client 由 CK 自己开发,放弃使用 libZookeeper(是一个bad smell代码库),CK 自己从 TCP 层进行封装遵循 Zookeeper Protocol。
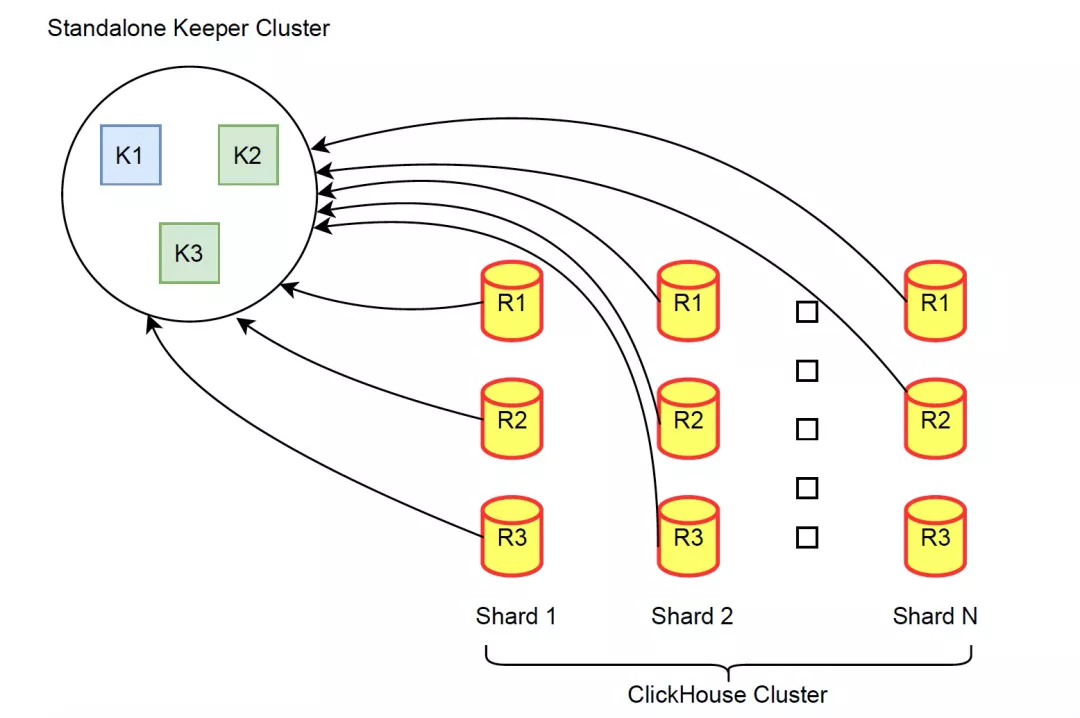
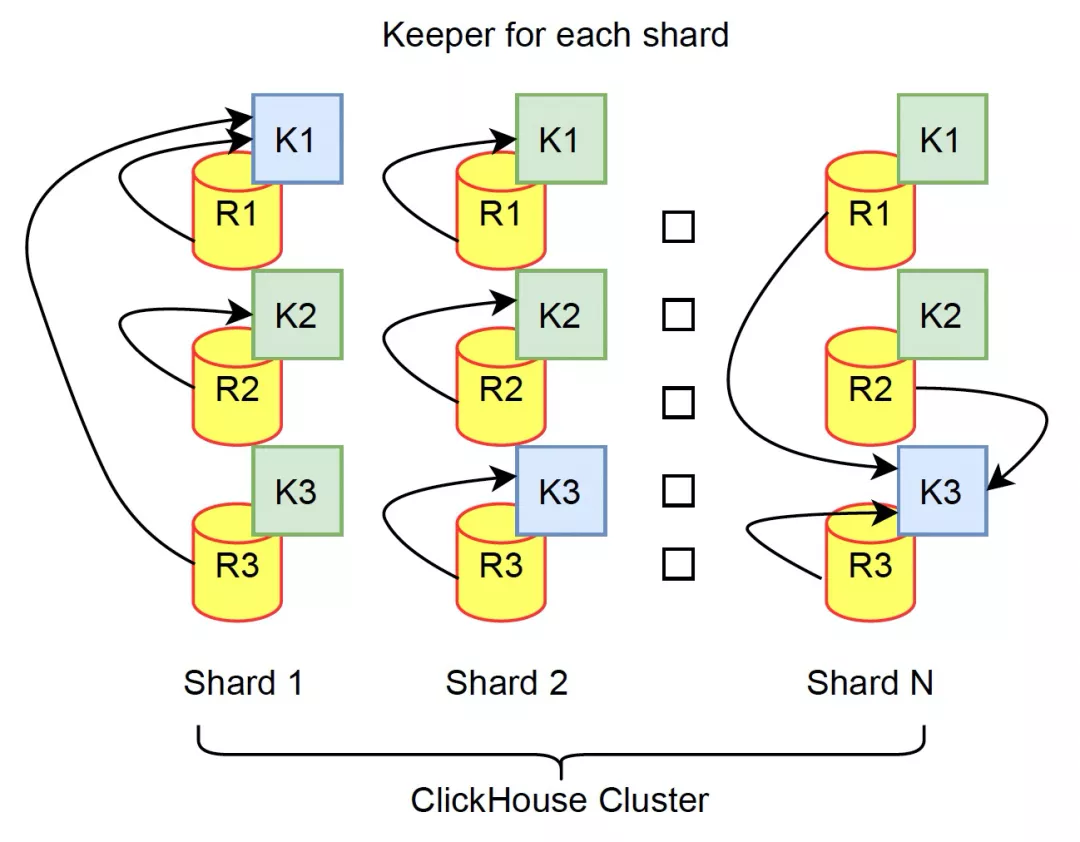
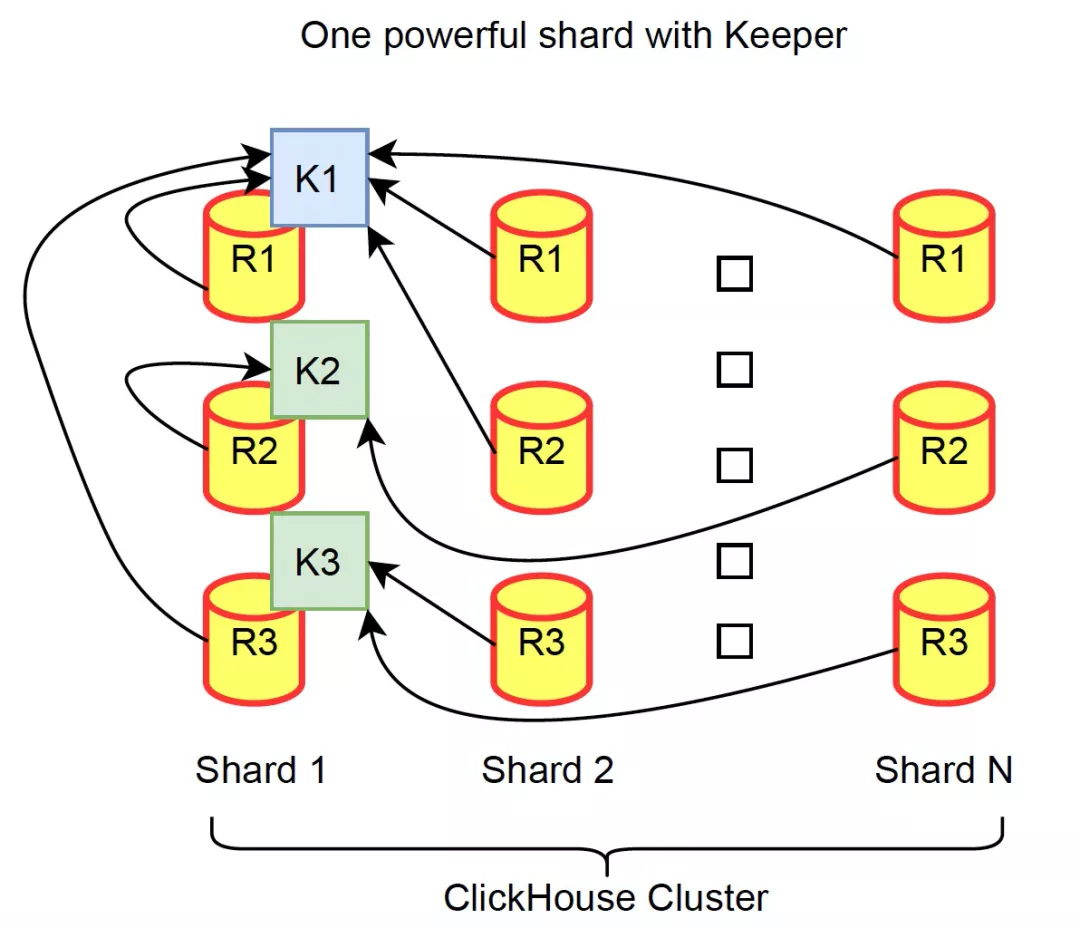
架构图
- 3种部署模式,推荐第一种 standalone 方式,可以选择小机型 SSD 磁盘,最大程度发挥 Keeper 的性能。
核心流程图梳理
类图关系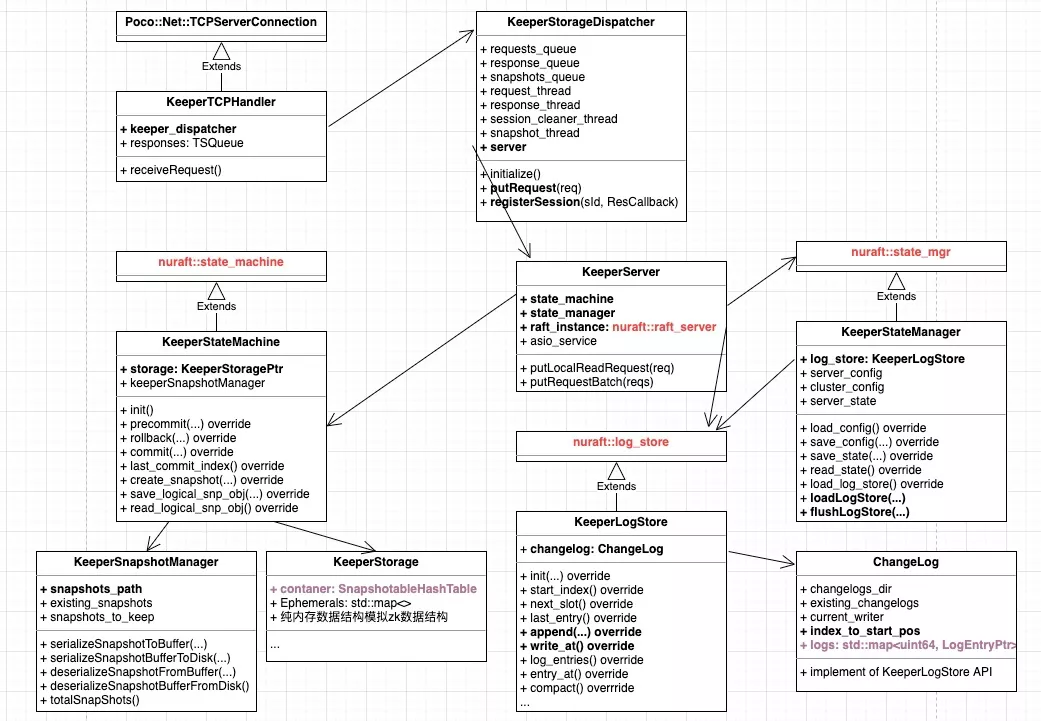
- 入口 main 函数,主要做2件事:
- 初始化 Poco::Net::TCPServer,定义处理请求的 KeeperTCPHandler。
- 实例化 keeper_storage_dispatcher,并且调用
KeeperStorageDispatcher➝initialize()。该函数主要作用是以下几个:- 实例化类图中的几个 Threads,以及相关的 ThreadSafeQueue,保证不同线程间同步数据。
- 实例化 KeeperServer 对象,该对象是核心数据结构,是整个 Raft 的最重要部分。KeeperServer 主要由 state_machine,state_manager,raft_instance,log_store(间接)组合成,他们分别继承了 nuraft 库中的父类。一般来说,所有 raft based 应用均应该实现这几个类。
- 调用 KeeperServer::startup(),主要是初始化 state_machine,state_manager。启动过程中会调用 state_machine➝init(), state_manager
➝loadLogStore(…),分别进行 snapshot 和 log 的加载。从最新的 raft snapshot 中恢复到最新提交的 latest_log_index,并形成内存数据结构(最关键是Container 数据结构即KeeperStorage::SnapshotableHashTable),然后再继续加载 raft log 文件中的每一条记录至 logs (即数据结构 std::unordered_map),这两个粗体的唯二的数据结构,是整个 HouseKeeper 的核心,也是内存大户,后边会提及。
KeeperTCPHandler 主循环是读取 socket 请求,将请求 dispatcher➝putRequest(req)
交给 requests_queue,然后通过 responses.tryPop(res)从中读到 response,
最终写 socket 将 response 返回给客户端。主要经历以下几个步骤:- 确认整个集群是否有 leader,如果有,sendHandshake。注意:HouseKeeper利用了 naraft 的 auto_forwarding 选项,所以如果接受请求的是非 leader,会承担 proxy 的作用,将请求 forward 到 leader,读写请求都会经过 proxy。
- 获得请求的 session_id。新来的 connection 获取 session_id 的过程是服务端 keeper_dispatcher➝internal_session_id_counter 自增的过程。
- keeper_dispatcher➝registerSession
(session_id,response_callback),将对应的 session_id 和回调函数绑定。 - 将请求keeper_dispatcher➝putRequest(req)交给requests_queue。
- 通过循环 responses.tryPop(res) 从中读到 response,最终写 socket 将 response 返回给客户端。
处理请求的线程模型
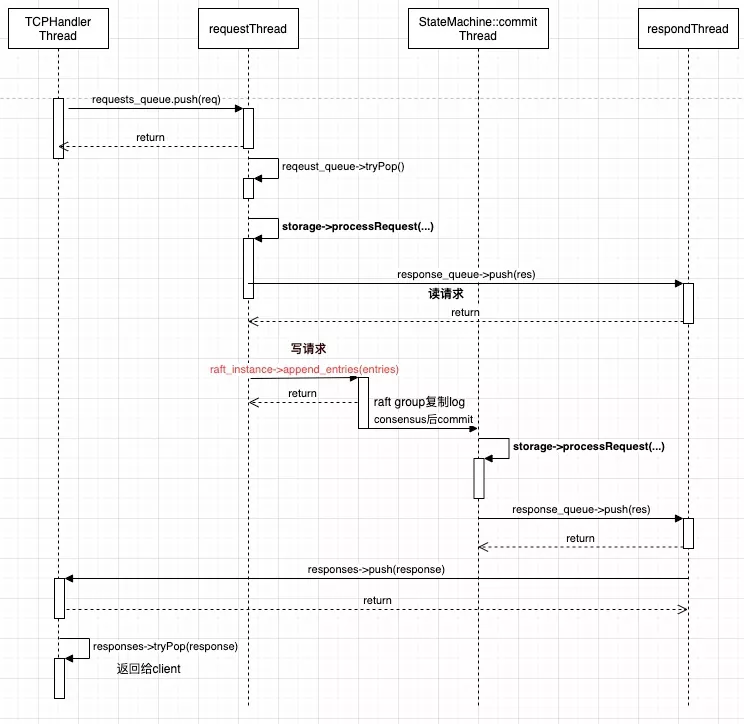
从 TCPHandler 线程开始经历顺序图中的不同线程调用,完成全链路的请求处理。
- 读请求直接由 requests_thread 调用 state_machine➝processReadRequest 处理,在该函数中,调用 storage➝processRequest(…) 接口。
- 写请求通过 raft_instance➝
append_entries(entries) 这个 nuraft 库的 User API 进行 log 写入。达成 consensus 之后,通过 nuraft 库内部线程调用 commit 接口,执行 storage➝processRequest(…) 接口。 - Nuraft 库的 normal log replication 处理流程如下图:

- Nuraft 库内部维护两个核心线程(或线程池),分别是:
- raft_server::append_entries_in_bg,leader 角色负责查看 log_store 中是否有新的 entries,对 follower 进行 replication。
- raft_server::commit_in_bg,所有角色(role,follower)查看自己的状态机 sm_commit_index 是否落后于 leader 的 leader_commit_index,如果是,则 apply_entries 到状态机中。
内部代码流程梳理
总体上 nuraft 实现了一个编程框架,需要对类图中标红的几个 class 进行实现。
LogStore 与 Snapshot
- LogStore 负责持久化 logs,继承自 nuraft::log_store,这一系列接口中比较重要的是:
- 写:包括
顺序写 KeeperLogStore::append(entry),
覆盖写(截断写)
KeeperLogStore::write_at(index, entry),
批量写
KeeperLogStore::apply_pack(index, pack)等。 - 读:last_entry(),entry_at(index) 等。
- 合并后清理:KeeperLogStore::compact(lastlog_index),主要会在 snapshot 之后进行调用。当 KeeperStateMachine::create_snapshot(last_log_idx) 调用时,当所有的 snapshot 将数据序列化到磁盘后,会调用 log_store➝compact(compactupto),
其中 compact_upto=new_snp➝
get_last_log_idx()-params➝
reserved_log_items。这是一个小坑, compact 的 compact_upto index 不是已经做过 snapshot 的最新 index,需要有一部分的保留,对应的配置是 reserved_log_items。
- 写:包括
- ChangeLog 是 LogStore 的 pimpl,提供了所有的 LogStore/nuraft::log_store 的接口。ChangeLog 主要是由 current_wirter(log file writer)和 logs(内存std::unordered_map数据结构)组成。
- 每插入一条 log,会将 log 序列化到 file buffer 中,并且插入到内存 logs 中。所以可以确定,在未做 snapshot 之前,logs 占用内存会一直增加。
- 当做完 snaphost 之后,会把已经序列化磁盘中的 compact_upto 的 index 从内存 logs 中 erase 掉。所以,我们需要 trade off 两个配置项 snapshot_distance 和 reserved_log_items。目前两个配置项缺省值都是10w条,容易大量占用内存,推荐值是:
- 10000
- 5000
- KeeperSnapshotManager 提供了一系列 ser/deser 的接口:
- KeeperStorageSnapshot 主要是提供了 KeeperStorage 和 file buffer 互相 ser/deser 的操作。
- 初始化时,直接通过 Snapshot 文件进行 deser 操作,恢复到文件指示的 index(如 snapshot_200000.bin,指示的 index 为200000)所对应的 KeeperStorage 数据结构。
- KeeperStateMachine::create_snapshot 时,根据提供的 snapshot 元数据(index,term等),执行 ser 操作,将 KeeperStorage 数据结构序列化到磁盘。
- Nuraft 库中提供的 snapshot transmission:当新加入的 follower 节点或者 follower 节点的日志落后很多(已经落后于最新一次 log compaction upto_index),leader 会主动发起 InstallSnapshot 流程,如下图:

Nuraft 库针对 InstallSnapshot 流程提供了几个接口。KeeperStateMachine 对此进行了简单的实现:
最核心的数据结构是 Zookeeper 的 Znode 存储:
using Container = SnapshotableHashTable
由 std::unordered_map 和 std::list 组合来实现一种无锁数据结构。key 为 Zookeeper path,value 为 Zookeeper Znode(包括存储 Znode 的 stat 元数据),Node 定义为:struct Node{String data;uint64_t acl_id = 0; /// 0 -- no ACL by defaultbool is_sequental = false;Coordination::Stat stat{};int32_t seq_num = 0;ChildrenSet children{};};
SnapshotableHashTable 结构中的 map 总是保存最新的数据结构,用来满足读需求。list 提供两段数据结构,保障新插入的数据不影响正在做 snapshot 的数据。实现很简单,
见:https://github.com/ClickHouse/ClickHouse/blob/v21.8.12.29-lts/src/Coordination/SnapshotableHashTable.h
- 提供了 ephemerals,sessions_and_watchers,session_and_timeout,acl_map,watches 等数据结构,实现都很简单,就不一一介绍了。
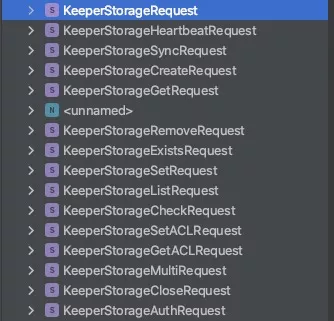
所有的 Request 都实现自 KeeperStorageRequest 父类,包括下图的所有子类,每一个 Request 实现了纯虚函数,用来对 KeeperStorage 的内存数据结构进行操作。
virtual std::pair<Coordination::ZooKeeperResponsePtr, Undo> process(KeeperStorage & storage, int64_t zxid, int64_t session_id) const = 0;
Nuraft 关键配置排坑阿里云 EMR ECS 机器对应的操作系统版本比较老(新版本已经解决),对于 ipv6 支持不好,server 启动不了。workaround 方法是先将 nuraft 库 hard coding 的 tcp port 改成 ipv4。
- 做5轮 zookeeper 压测,发现内存一直上涨,现象接近内存泄露。结论是:不是内存泄露,需要调整参数,使 logs 内存数据结构不占用过多内存。
- 每一轮先创建500w个 Znode,每个 Znode 数据是256,再删除500w Znode。具体过程是:利用 ZookeeperClient 的 multi 模式,每一轮发起5000次请求,每个请求 transaction 创建1000个 Znode,达到500w个 Znode 后,再发起5000次请求,每个请求删除1000个 Znode,这样保证每一轮所有的 Znode 全部删除。这样即每一轮插入10000条 logEntry。
- 过程中发现每一轮内存都会上涨,经过5轮之后内存上涨到20G以上,怀疑是内存泄露。
- 加入代码 profile 打印 showStatus 之后,发现每一轮 ChangeLog::logs 数据结构一直增长,而 KeeperStorage::Container 数据结构会随着 Znode 数量而周期变化,最终回归0。结论是:由于 snapshot_distance 默认配置是10w条,所以,一直没有发生 create_snapshot,也即没有发生 compact logs,ChangeLog::logs 内存占用会越来越多。所以建议配置为:
- 10000
- 5000
- 通过配置 auto_forwarding,可以让 leader 把请求转发给 follower,对 ZookeeperClient 是透明实现。但是这个配置 nuraft 不推荐,后续版本应该会改善该做法。
结论
- 去掉 Zookeeper 依赖会让 ClickHouse 不再依赖外部组件,无论从稳定性和性能都向前迈进了一大步,为逐渐走向云原生化提供了前提。
- 基于该 codebase,后续将会逐步衍生出基于 Raft 的 MetaServer,为支持存算分离、支持分布式 Join 的 MPP 架构等方向提供了前提。

若有收获,就点个赞吧
0 人点赞
