1 redo log的作用
当对数据库进行 写操作 (插入, 删除, 更新) 时, 如果直接进行磁盘读写, 效率很低
为了提高效率,
当一条记录需要更新时, 会先把记录写到redo log buffer中, 然后更新内存,
等到适当的时候(比如 事务提交时), 再把这块内存缓冲区刷到磁盘中
按照默认的设置, 这个适当的时候就是
有了redo log, Innodb就可以保证即使数据库发生异常重启, 之前提交事务的记录都不会丢失
注: redo log是Innodb引擎特有的日志
2 redo log的原理
InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,
那么这块“粉板”总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写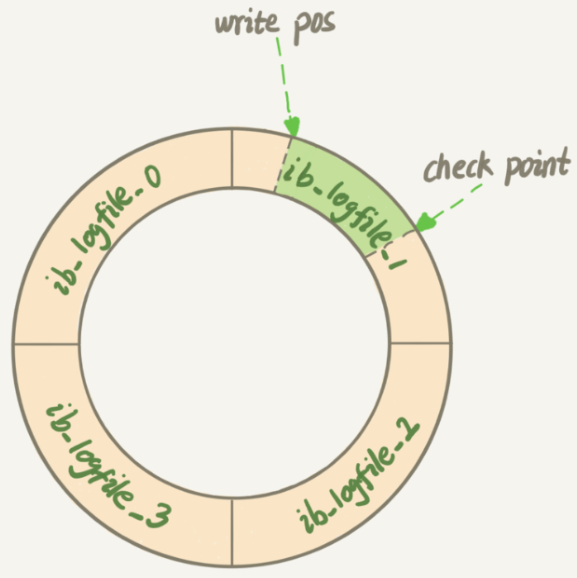
write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头。
checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件。
write pos 和 checkpoint 之间的是“粉板”上还空着的部分,可以用来记录新的操作。
如果 write pos 追上 checkpoint,表示“粉板”满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint 推进一下。
MySQL支持用户自定义在commit时如何将log buffer中的日志刷log file中。这种控制通过变量 innodb_flush_log_at_trx_commit 的值来决定。该变量有3种值:0、1、2,
默认为1。但注意,这个变量只是控制commit动作是否刷新log buffer到磁盘。
当设置为0的时候,事务提交时不会将log buffer中日志写入到os buffer,而是每秒写入os buffer并调用fsync()写入到log file on disk中。也就是说设置为0时是(大约)每秒刷新写入到磁盘中的,当系统崩溃,会丢失1秒钟的数据。
当设置为1的时候,事务每次提交都会将log buffer中的日志写入os buffer并调用fsync()刷到log file on disk中。这种方式即使系统崩溃也不会丢失任何数据,但是因为每次提交都写入磁盘,IO的性能较差。
当设置为2的时候,每次提交都仅写入到os buffer,然后是每秒调用fsync()将os buffer中的日志写入到log file on disk。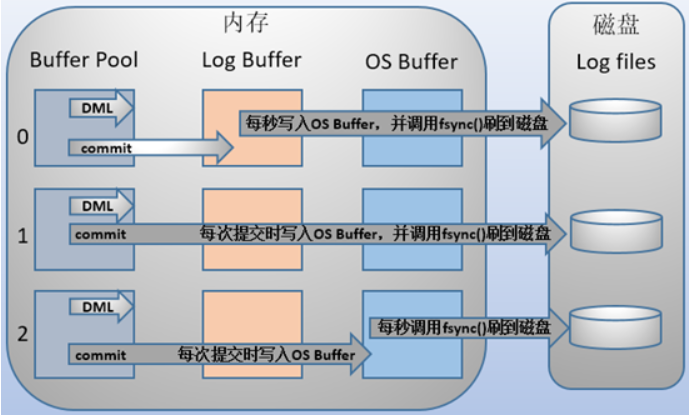

若有收获,就点个赞吧
0 人点赞
