1 简介
Protocol Buffers(简写为protobuf) 是一种与语言无关,平台无关的可扩展机制,用于序列化结构化数据。
它是一种类似于json, XML的结构化数据格式, 是Google出口的一种轻量, 高效的结构化数据存储格式
protobuf有pb2和pb3两个版本, pb3比pb2简化了很多, 是目前的主流版本
gRPC也是基于Protocol Buffers。
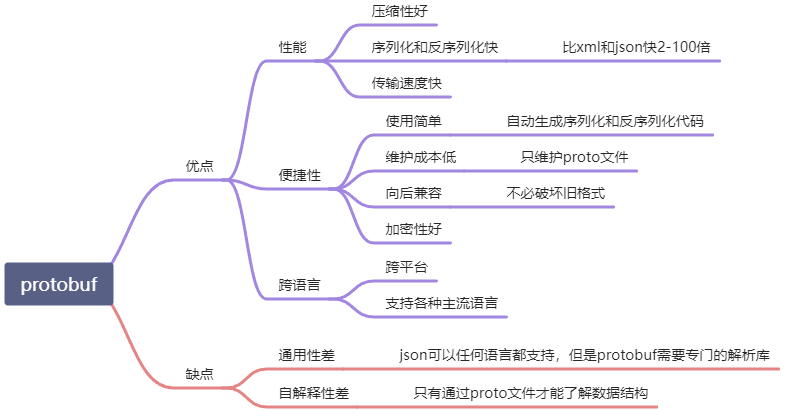
2 文档结构
(1) protobuf版本
protobuf文档的第一行非注释行,为版本申明,不填写的话默认为版本2。
syntax = "proto3";或者syntax = "proto2";
(2) Package包
Protocol Buffers 可以声明package,来防止命名冲突。 Packages是可选的。
package foo;message Open { ... }
使用的时候,也要加上命名空间
message Foo {...foo.Open open = 1;...}
注意:对于Python而言,package会被忽略处理,因为Python中的包是以文件目录来定义的。
(3) 导入
Protocol Buffers 中可以导入其它文件消息等,与Python的import类似。
import “myproject/other_protos.proto”;
(4) 消息和服务
messge是用来定义复合数据类型的,类似于结构体
service是用来定义服务的。
3 数据类型
(1) 基本数据类型
| .proto | 说明 |
|---|---|
| double | |
| float | |
| int32 | 使用变长编码,对负数编码效率低, 如果你的变量可能是负数,可以使用sint32 |
| int64 | 使用变长编码,对负数编码效率低,如果你的变量可能是负数,可以使用sint64 |
| uint32 | 使用变长编码 |
| uint64 | 使用变长编码 |
| bool | |
| string | 必须包含utf-8编码或者7-bit ASCII text |
| bytes | 任意的字节序列 |
(2) 枚举
message SearchRequest {enum Corpus {UNIVERSAL = 0;WEB = 1;IMAGES = 2;LOCAL = 3;NEWS = 4;PRODUCTS = 5;VIDEO = 6;}string query = 1;int32 page_number = 2;int32 result_per_page = 3;Corpus corpus = 4;}
枚举定义在一个消息内部或消息外部都是可以的,如果枚举是 定义在 message 内部,而其他 message 又想使用,那么可以通过 MessageType.EnumType 的方式引用。
4 自定义数据类型
使用message定义消息数据。在Protocol Buffers中使用的数据都是通过message消息数据封装基本类型数据或其他消息数据,对应Python中的类。
message SearchRequest {string query = 1;int32 page_number = 2;int32 result_per_page = 3;}
(1) 字段编号
消息定义中的每个字段都有唯一的编号。这些字段编号用于以消息二进制格式标识字段,并且在使用消息类型后不应更改。 请注意,1到15范围内的字段编号需要一个字节进行编码,包括字段编号和字段类型。16到2047范围内的字段编号占用两个字节。因此,您应该为非常频繁出现的消息元素保留数字1到15。请记住为将来可能添加的常用元素留出一些空间。
最小的标识号可以从1开始,最大到2^29 - 1,或 536,870,911。不可以使用其中的[19000-19999]的标识号, Protobuf协议实现中对这些进行了预留。如果非要在.proto文件中使用这些预留标识号,编译时就会报警。同样你也不能使用早期保留的标识号。
(2) 指定字段规则
消息字段可以是以下之一:
- singular:格式良好的消息可以包含该字段中的零个或一个(但不超过一个)。
- repeated:此字段可以在格式良好的消息中重复任意次数(包括零)。将保留重复值的顺序。对应Python的列表。
message Result {string url = 1;string title = 2;repeated string snippets = 3;}
proto3”仅仅支持repeated字段修饰, 如果使用required,optional编译会报错。
(4) 保留字段
保留变量不被使用
如果通过完全删除字段或将其注释来更新消息类型,则未来用户可以在对类型进行自己的更新时重用字段编号。如果以后加载相同的旧版本,这可能会导致严重问题,包括数据损坏,隐私错误等。确保不会发生这种情况的一种方法是指定已删除字段的字段编号(或名称)reserved。如果将来的任何用户尝试使用这些字段标识符,protobuf编译器将会报错。
enum Foo {reserved 2, 15, 9 to 11, 40 to max;reserved "FOO", "BAR";}
(5) 默认值
解析消息时,如果编码消息不包含特定的单数元素,则解析对象中的相应字段将设置为该字段的默认值。这些默认值是特定于类型的:
- 对于字符串,默认值为空字符串。
- 对于字节,默认值为空字节。
- 对于bools,默认值为false。
- 对于数字类型,默认值为零。
- 对于枚举,默认值是第一个定义的枚举值,该值必须为0。
- 对于消息字段,未设置该字段。它的确切值取决于语言。
-
(6) 嵌套类型
message SearchResponse {message Result {string url = 1;string title = 2;repeated string snippets = 3;}repeated Result results = 1;}
5 map映射
如果要在数据定义中创建关联映射,Protocol Buffers提供了一种方便的语法:
map<key_type, value_type> map_field = N ;
其中key_type可以是任何整数或字符串类型。请注意,枚举不是有效的key_type。value_type可以是除map映射类型外的任何类型。
例如,如果要创建项目映射,其中每条Project消息都与字符串键相关联,则可以像下面这样定义它:map<string, Project> projects = 3 ;
map的字段可以是repeated。
- 序列化后的顺序和map迭代器的顺序是不确定的,所以你不要期望以固定顺序处理map
- 当为.proto文件产生生成文本格式的时候,map会按照key 的顺序排序,数值化的key会按照数值排序。
- 从序列化中解析或者融合时,如果有重复的key则后一个key不会被使用,当从文本格式中解析map时,如果存在重复的key,则解析可能会失败。
- 如果为映射字段提供键但没有值,则字段序列化时的行为取决于语言。在Python中,使用类型的默认值。
6 oneof
如果你的消息中有很多可选字段, 并且同时至多一个字段会被设置, 你可以加强这个行为,使用oneof特性节省内存。
为了在.proto定义oneof字段, 你需要在名字前面加上oneof关键字, 比如下面例子的test_oneof:
message SampleMessage {oneof test_oneof {string name = 4;SubMessage sub_message = 9;}}
7 定义服务
protobuf使用service定义RPC服务
message HelloRequest {string greeting = 1;}message HelloResponse {string reply = 1;}service HelloService {rpc SayHello (HelloRequest) returns (HelloResponse);}

若有收获,就点个赞吧
0 人点赞
