1 为什么Partition需要Replication(复制)?
在没有Replication的情况下,一旦某机器宕机或者某个Broker停止工作, 则其上所有的Partition数据都不可被消费, 整个系统的可用性降低。随着集群规模的增加,整个集群中出现该类异常的几率大大增加,因此对于生产系统而言Replication机制的引入非常重要。
所以, kafka中一个topic可以分为多个Partition,每个partition又有多个副本
实现副本的目的仅仅是数据备份,所有的读写请求都是由leader副本进行处理的
2 为什么需要Leader Election?
引入Replication之后,同一个Partition可能会有多个Replica(副本),而这时需要在这些Replica中选出一个Leader,Producer和Consumer只与这个Leader交互,其它Replica作为Follower从Leader中复制数据。
因为需要保证同一个Partition的多个Replica之间的数据一致性(其中一个宕机后其它Replica必须要能继续服务并且即不能造成数据重复也不能造成数据丢失)。如果没有一个Leader,所有Replica都可同时读/写数据,那就需要保证多个Replica之间互相(N×N条通路)同步数据,数据的一致性和有序性非常难保证,大大增加了Replication实现的复杂性,同时也增加了出现异常的几率。而引入Leader后,只有Leader负责数据读写,Follower只向Leader顺序Fetch数据(N条通路),系统更加简单且高效
3 如何将所有Replica均匀分布到整个集群?
为了更好的做负载均衡,Kafka尽量将所有的Partition均匀分配到整个集群上。一个典型的部署方式是一个Topic的Partition数量大于Broker的数量。同时为了提高Kafka的容错能力,也需要将同一个Partition的Replica尽量分散到不同的机器。实际上,如果所有的Replica都在同一个Broker上,那一旦该Broker宕机,该Partition的所有Replica都无法工作,也就达不到HA的效果。同时,如果某个Broker宕机了,需要保证它上面的负载可以被均匀的分配到其它幸存的所有Broker上。
Kafka分配Replica的算法如下:
- 将所有Broker(假设共n个Broker)和待分配的Partition排序
- 将第i个Partition分配到第(i mod n)个Broker上
- 将第i个Partition的第j个Replica分配到第((i + j) mod n)个Broker上
4 如何实现Replica间的数据复制?
(1) 如何传递消息?
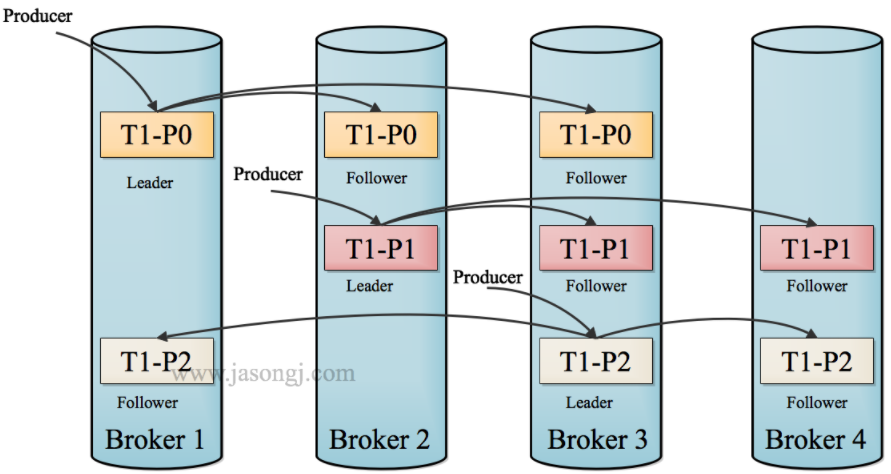
- Producer在发布消息到某个Partition时,先通过 Metadata (通过 Broker 获取并且缓存在 Producer 内) 找到该 Partition 的Leader, 并将消息发给该Leader, Leader收到消息后写入本地Log
- 每个Follower都从Leader Pull数据, Follower收到消息后, 向Leader发送ACK, 再写入本地Log
- 一旦Leader收到所有Replica的ACK, 该消息就被认为已经commit了, Leader将增加HW并向Producer发送ACK
Leader会跟踪与其保持同步的Replica列表,该列表称为ISR(即in-sync Replica) 如果一个Follower宕机,或者落后太多,Leader将把它从ISR中移除。 Follower可以批量的从Leader复制数据,这样极大的提高复制性能(批量写磁盘)
(2) Leader Election算法
Kafka在Zookeeper中动态维护了一个ISR(in-sync replicas),这个ISR里的所有Replica都跟上了leader,只有ISR里的成员才有被选为Leader的可能。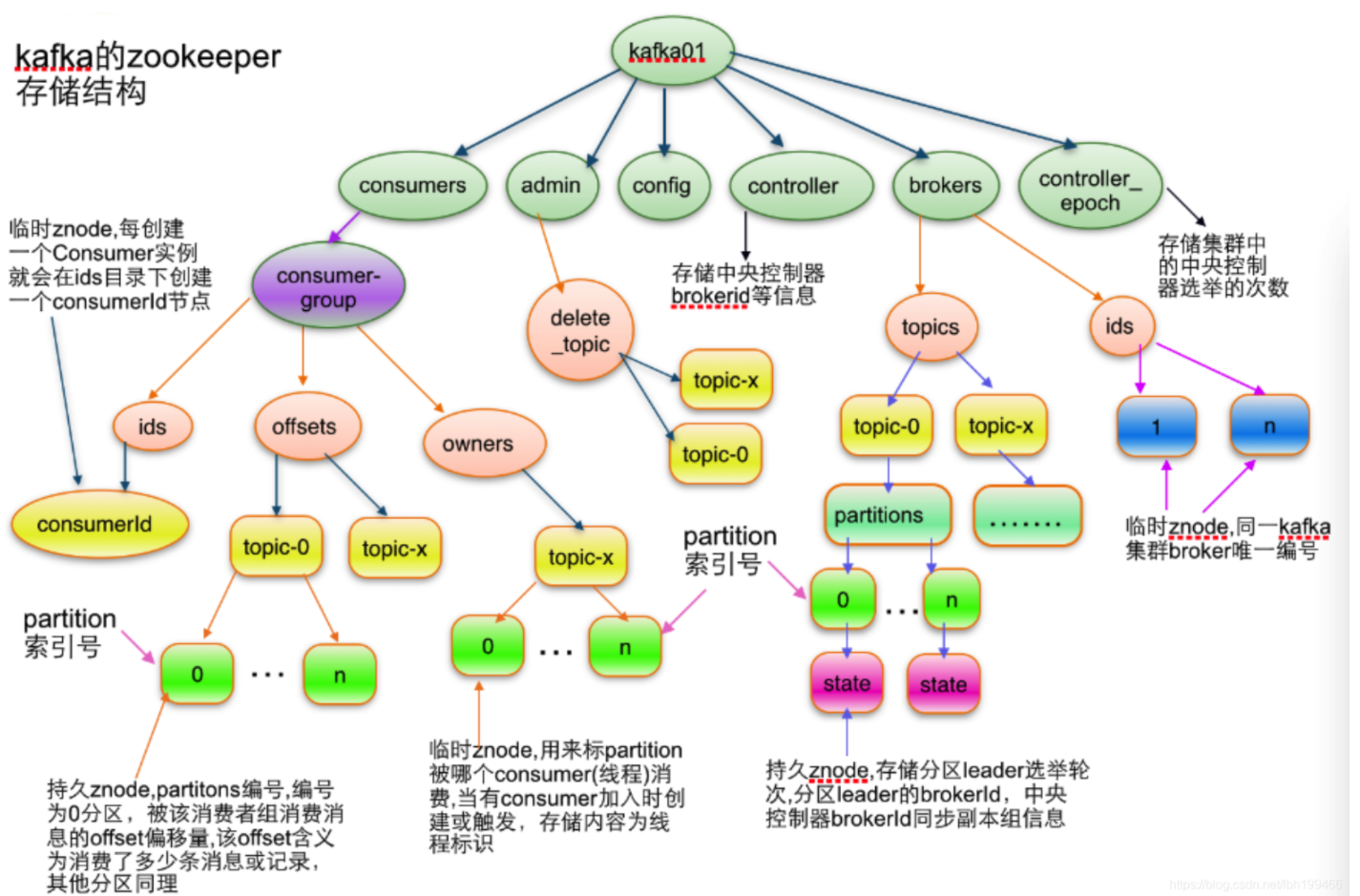

若有收获,就点个赞吧
0 人点赞
