一、Init Container(初始化容器)
在很多应用场景中,应用在启动之前都需要进行如下初始化操作:
- 等待其他关联组件正确运行(例如数据库或某个后台服务)。
- 基于环境变量或配置模板生成配置文件。
- 从远程数据库获取本地所需配置,或者将自身注册到某个中央数据库中。
- 下载相关依赖包,或者对系统进行一些预配置操作。
Kubernetes 1.3引入了一个Alpha版本的新特性init container(初始化容器,在Kubernetes 1.5时被更新为Beta版本),用于在启动应用容器 (app container)之前启动一个或多个初始化容器,完成应用容器所需的预置条件。init container与应用容器在本质上是一样的,但它们是仅运行一次就结束的任务,并且必须在成功执行完成后, 系统才能继续执行下一个容器。根据Pod的重启策略(RestartPolicy), 当init container执行失败,而且设置了RestartPolicy=Never时,Pod将会启动失败;而设置RestartPolicy=Always时,Pod将会被系统自动重启。
二、Pod的升级和回滚
当集群中的某个服务需要升级时,我们需要停止目前与该服务相关 的所有Pod,然后下载新版本镜像并创建新的Pod。如果集群规模比较 大,则这个工作变成了一个挑战,而且先全部停止然后逐步升级的方式 会导致较长时间的服务不可用。Kubernetes提供了滚动升级功能来解决 上述问题。
如果Pod是通过Deployment创建的,则用户可以在运行时修改 Deployment的Pod定义(spec.template)或镜像名称,并应用到 Deployment对象上,系统即可完成Deployment的自动更新操作。如果在 更新过程中发生了错误,则还可以通过回滚操作恢复Pod的版本。
2.1、滚动升级
# 第1种升级镜像版本方式$ kubectl set image deployment/<deployment-name> <image-name>=<image-version># 第二种升级镜像版本方式$ kubectl edit deployemtn <deployment-name># 在升级过程中,查看滚动升级状态$ kubectl rollout status
Deployment是如何完成Pod更新的呢?
我们可以使用kubectl describe deployments/nginx-deployment命令仔 细观察Deployment的更新过程。初始创建Deployment时,系统创建了一 个ReplicaSet(nginx-deployment-4087004473),并按用户的需求创建了 3个Pod副本。当更新Deployment时,系统创建了一个新的 ReplicaSet(nginx-deployment-3599678771),并将其副本数量扩展到 1,然后将旧的ReplicaSet缩减为2。之后,系统继续按照相同的更新策 略对新旧两个ReplicaSet进行逐个调整。最后,新的ReplicaSet运行了3个 新版本Pod副本,旧的ReplicaSet副本数量则缩减为0。如下图: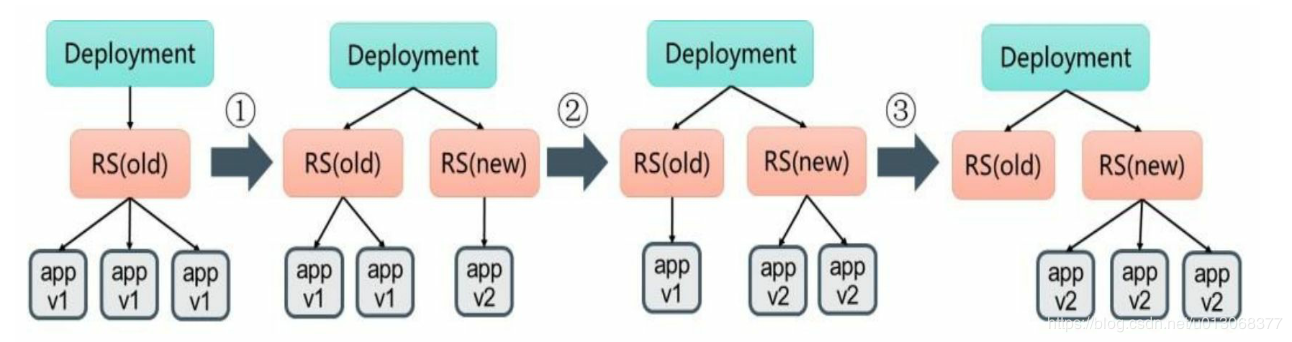
对更新策略的说明如下:
在Deployment的定义中,可以通过spec.strategy指定Pod更新的策 略,目前支持两种策略:Recreate(重建)和RollingUpdate(滚动更 新),默认值为RollingUpdate。在前面的例子中使用的就是 RollingUpdate策略。
- Recreate:设置spec.strategy.type=Recreate,表示Deployment在 更新Pod时,会先杀掉所有正在运行的Pod,然后创建新的Pod。
- RollingUpdate:设置spec.strategy.type=RollingUpdate,表示 Deployment会以滚动更新的方式来逐个更新Pod。同时,可以通过设置 spec.strategy.rollingUpdate下的两个参数(maxUnavailable和maxSurge) 来控制滚动更新的过程。
2.2、Deployment的回滚
有时(例如新的Deployment不稳定时)我们可能需要将Deployment 回滚到旧版本。在默认情况下,所有Deployment的发布历史记录都被保 留在系统中,以便于我们随时进行回滚(可以配置历史记录数量)。
2.3、暂停和恢复Deployment的部署操作
对于一次复杂的Deployment配置修改,为了避免频繁触发 Deployment的更新操作,可以先暂停Deployment的更新操作,然后进行 配置修改,再恢复Deployment,一次性触发完整的更新操作,就可以避 免不必要的Deployment更新操作了。
# 暂停Deployment的更新操作$ kubectl rollout pause deployment/<deployment-name># 对Deployment做任意次修改,都不会导致镜像部署# 恢复Deployment的更新操作$ kubectl rollout resume deployment/<deployment-name>
2.4、使用kubectl rolling-update命令完成RC的 滚动升级
对于RC的滚动升级,Kubernetes还提供了一个kubectl rolling-update 命令进行实现。该命令创建了一个新的RC,然后自动控制旧的RC中的 Pod副本数量逐渐减少到0,同时新的RC中的Pod副本数量从0逐步增加 到目标值,来完成Pod的升级。需要注意的是,系统要求新的RC与旧的 RC都在相同的命名空间内。
方法一操作步骤:
- 需要新写一个yaml文件用于滚动升级
- 新的RC的名字(name)不能与旧RC的名字相同
- 在selector中应至少有一个Label与旧RC的Label不同,以标识其为新RC。
$ kubectl rolling-update <old-deployment-name> -f <yaml-name>
方法二:
$ kubectl rolling-update <old-deployment-name> --image=<image-name>:<version>
与使用配置文件的方式不同,执行的结果是旧RC被删除,新RC仍 将使用旧RC的名称。
三、Pod的扩缩容
在实际生产系统中,我们经常会遇到某个服务需要扩容的场景,也 可能会遇到由于资源紧张或者工作负载降低而需要减少服务实例数量的 场景。此时可以利用Deployment/RC的Scale机制来完成这些工作。
Kubernetes对Pod的扩缩容操作提供了手动和自动两种模式,手动模 式通过执行kubectl scale命令或通过RESTful API对一个Deployment/RC进 行Pod副本数量的设置,即可一键完成。自动模式则需要用户根据某个 性能指标或者自定义业务指标,并指定Pod副本数量的范围,系统将自 动在这个范围内根据性能指标的变化进行调整。
3.1、手动扩缩容机制
命令:
$ kubectl scale deployment <deployment-name> --replicas <number>
3.2、自动扩缩容机制
Kubernetes从1.1版本开始,新增了名为Horizontal Pod Autoscaler(HPA)的控制器,用于实现基于CPU使用率进行自动Pod扩 缩容的功能。HPA控制器基于Master的kube-controller-manager服务启动 参数—horizontal-pod-autoscaler-sync-period定义的探测周期(默认值为 15s),周期性地监测目标Pod的资源性能指标,并与HPA资源对象中的 扩缩容条件进行对比,在满足条件时对Pod副本数量进行调整。
3.2.1、HPA的工作原理
Kubernetes中的某个Metrics Server(Heapster或自定义Metrics Server)持续采集所有Pod副本的指标数据。HPA控制器通过Metrics Server的API(Heapster的API或聚合API)获取这些数据,基于用户定义 的扩缩容规则进行计算,得到目标Pod副本数量。当目标Pod副本数量与 当前副本数量不同时,HPA控制器就向Pod的副本控制器 (Deployment、RC或ReplicaSet)发起scale操作,调整Pod的副本数量, 完成扩缩容操作。下图描述了HPA体系中的关键组件和工作流程: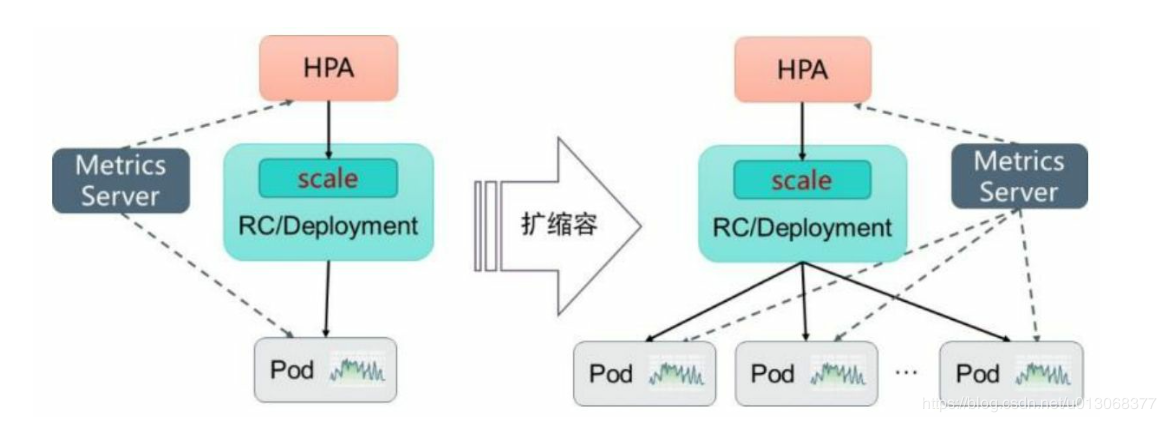
3.2.2、指标的类型
Master的kube-controller-manager服务持续监测目标Pod的某种性能 指标,以计算是否需要调整副本数量。目前Kubernetes支持的指标类型 如下。
- Pod资源使用率:Pod级别的性能指标,通常是一个比率值,例如:CPU使用率。
- Pod自定义指标:Pod级别的性能指标,通常是一个数值,例如:接收的请求数量。
- Object自定义指标或外部自定义指标:通常是一个数值,需要容器应用以某种方式提供,例如通过HTTP URL“/metrics”提供,或者使 用外部服务提供的指标采集URL。
3.2.3、扩缩容算法详解
Autoscaler控制器从聚合API获取到Pod性能指标数据之后,基于下 面的算法计算出目标Pod副本数量,与当前运行的Pod副本数量进行对 比,决定是否需要进行扩缩容操作:
即当前副本数×(当前指标值/期望的指标值),将结果向上取整。
当计算结果与1非常接近时,可以设置一个容忍度让系统不做扩缩 容操作。容忍度通过kube-controller-manager服务的启动参数—horizontal- pod-autoscaler-tolerance进行设置,默认值为0.1(即10%),表示基于上 述算法得到的结果在[-10%-+10%]区间内,即[0.9-1.1],控制器都不会进行扩缩容操作。
也可以将期望指标值(desiredMetricV alue)设置为指标的平均值类 型,例如targetAverageValue或targetAverageUtilization,此时当前指标值 (currentMetricV alue)的算法为所有Pod副本当前指标值的总和除以Pod 副本数量得到的平均值。
此外,存在几种Pod异常的情况,如下所述:
- Pod正在被删除(设置了删除时间戳):将不会计入目标Pod副本数量。
- Pod的当前指标值无法获得:本次探测不会将这个Pod纳入目标Pod副本数量,后续的探测会被重新纳入计算范围。
- 如果指标类型是CPU使用率,则对于正在启动但是还未达到 Ready状态的Pod,也暂时不会纳入目标副本数量范围。可以通过kube- controller-manager服务的启动参数—horizontal-pod-autoscaler-initial- readiness-delay设置首次探测Pod是否Ready的延时时间,默认值为30s。 另一个启动参数—horizontal-pod-autoscaler-cpuinitialization-period设置首次采集Pod的CPU使用率的延时时间。
如果在HorizontalPodAutoscaler中设置了多个指标,系统就会对每个 指标都执行上面的算法,在全部结果中以期望副本数的最大值为最终结 果。如果这些指标中的任意一个都无法转换为期望的副本数(例如无法 获取指标的值),系统就会跳过扩缩容操作。
3.2.4、HorizontalPodAutoscaler配置详解
Kubernetes将HorizontalPodAutoscaler资源对象提供给用户来定义扩缩容的规则。
HorizontalPodAutoscaler资源对象处于Kubernetes的API 组“autoscaling”中,目前包括v1和v2两个版本。其中autoscaling/v1仅支 持基于CPU使用率的自动扩缩容,autoscaling/v2则用于支持基于任意指 标的自动扩缩容配置,包括基于资源使用率、Pod指标、其他指标等类 型的指标数据,当前版本为autoscaling/v2beta2。
可以根据CPU、Mem、QPS等的值来对Pod进行扩缩容,前提是需要有指标采集服务
常见指标示例
略
自定义指标
基于自定义指标进行自动扩缩容时,需要预先部署自定义Metrics Server,目前可以使用基于Prometheus、Microsoft Azure、DatadogCluster等系统的Adapter实现自定义Metrics Server,未来还将提供基于Google Stackdriver的实现自定义Metrics Server。
基于Prometheus的HPA架构图如下: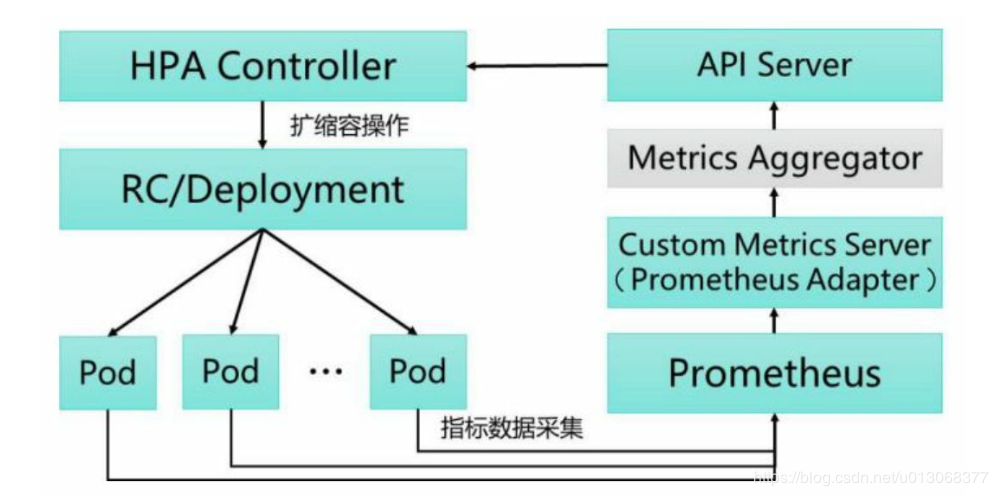
关键组件包括如下。
- Prometheus:定期采集各Pod的性能指标数据。
- Custom Metrics Server:自定义Metrics Server,用Prometheus Adapter进行具体实现。它从Prometheus服务采集性能指标数据,通过 Kubernetes的Metrics Aggregation层将自定义指标API注册到Master的API Server中,以/apis/custom.metrics.k8s.io路径提供指标数据。
- HPA Controller:Kubernetes的HPA控制器,基于用户定义的 HorizontalPodAutoscaler进行自动扩缩容操作。
四、使用StatefulSet
这个是有状态的Pod,一般用于:MongDB集群、Mysql集群等的搭建
参考
《Kubernetes权威指南: 第四版》

若有收获,就点个赞吧
0 人点赞
