下面介绍Kubernetes中重要的资源对象:
一、Master
Kubernetes里的Master指的是集群控制节点,在每个Kubernetes集群 里都需要有一个Master来负责整个集群的管理和控制,基本上 Kubernetes的所有控制命令都发给它,它负责具体的执行过程,我们后 面执行的所有命令基本都是在Master上运行的。Master通常会占据一个 独立的服务器(高可用部署建议用3台服务器),主要原因是它太重要了,是整个集群的“首脑”,如果它宕机或者不可用,那么对集群内容器 应用的管理都将失效。
在Master上运行着以下关键进程:
- Kubernetes API Server(kube-apiserver):提供了HTTP Rest接 口的关键服务进程,是Kubernetes里所有资源的增、删、改、查等操作 的唯一入口,也是集群控制的入口进程。
- Kubernetes Controller Manager(kube-controller-manager):Kubernetes里所有资源对象的自动化控制中心,可以将其理解为资源对 象的“大总管”。
- Kubernetes Scheduler(kube-scheduler):负责资源调度(Pod 调度)的进程,相当于公交公司的“调度室”。
另外,在Master上通常还需要部署etcd服务,因为Kubernetes里的所有资源对象的数据都被保存在etcd中。
二、Node
除了Master,Kubernetes集群中的其他机器被称为Node,在较早的版本中也被称为Minion。与Master一样,Node可以是一台物理主机,也可以是一台虚拟机。Node是Kubernetes集群中的工作节点,每个Node都会被Master分配一些工作负载(Docker容器),当某个Node宕机 时,其上的工作负载会被Master自动转移到其他节点上。
在每个Node上都运行着以下关键进程。
- kubelet:负责Pod对应的容器的创建、启停等任务,同时与Master密切协作,实现集群管理的基本功能。
- kube-proxy:实现Kubernetes Service的通信与负载均衡机制的重要组件。
- Docker Engine(docker):Docker引擎,负责本机的容器创建和管理工作。
Node可以在运行期间动态增加到Kubernetes集群中,前提是在这个节点上已经正确安装、配置和启动了上述关键进程,在默认情况下 kubelet会向Master注册自己,这也是Kubernetes推荐的Node管理方式。 一旦Node被纳入集群管理范围,kubelet进程就会定时向Master汇报自身的情报,例如操作系统、Docker版本、机器的CPU和内存情况,以及当前有哪些Pod在运行等,这样Master就可以获知每个Node的资源使用情 况,并实现高效均衡的资源调度策略。而某个Node在超过指定时间不上报信息时,会被Master判定为“失联”,Node的状态被标记为不可用 (Not Ready),随后Master会触发“工作负载大转移”的自动流程。
查看集群中的Node:
kubectl get nodes
查看某个node的详细信息
kubectl describe node [node_name]
Node详细信息中包括:
- Node的基本信息:名称、标签、创建时间等。
- Node当前的运行状态:Node启动后会做一系列的自检工作, 比如磁盘空间是否不足(DiskPressure)、内存是否不足 (MemoryPressure)、网络是否正常(NetworkUnavailable)、PID资源 是否充足(PIDPressure)。在一切正常时设置Node为Ready状态 (Ready=True),该状态表示Node处于健康状态,Master将可以在其上 调度新的任务了(如启动Pod)。
- Node的主机地址与主机名。
- Node上的资源数量:描述Node可用的系统资源,包括CPU、内存数量、最大可调度Pod数量等。
- Node可分配的资源量:描述Node当前可用于分配的资源量。
- 主机系统信息:包括主机ID、系统UUID、Linux kernel版本 号、操作系统类型与版本、Docker版本号、kubelet与kube-proxy的版本 号等。
- 当前运行的Pod列表概要信息。
- 已分配的资源使用概要信息,例如资源申请的最低、最大允许 使用量占系统总量的百分比。
三、Pod
3.1、Pod组成
Pod是Kubernetes最重要的基本概念,如下图所示是Pod的组成示意图,我们看到每个Pod都有一个特殊的被称为“根容器”的Pause容器。 Pause容器对应的镜像属于Kubernetes平台的一部分,除了Pause容器, 每个Pod还包含一个或多个紧密相关的用户业务容器。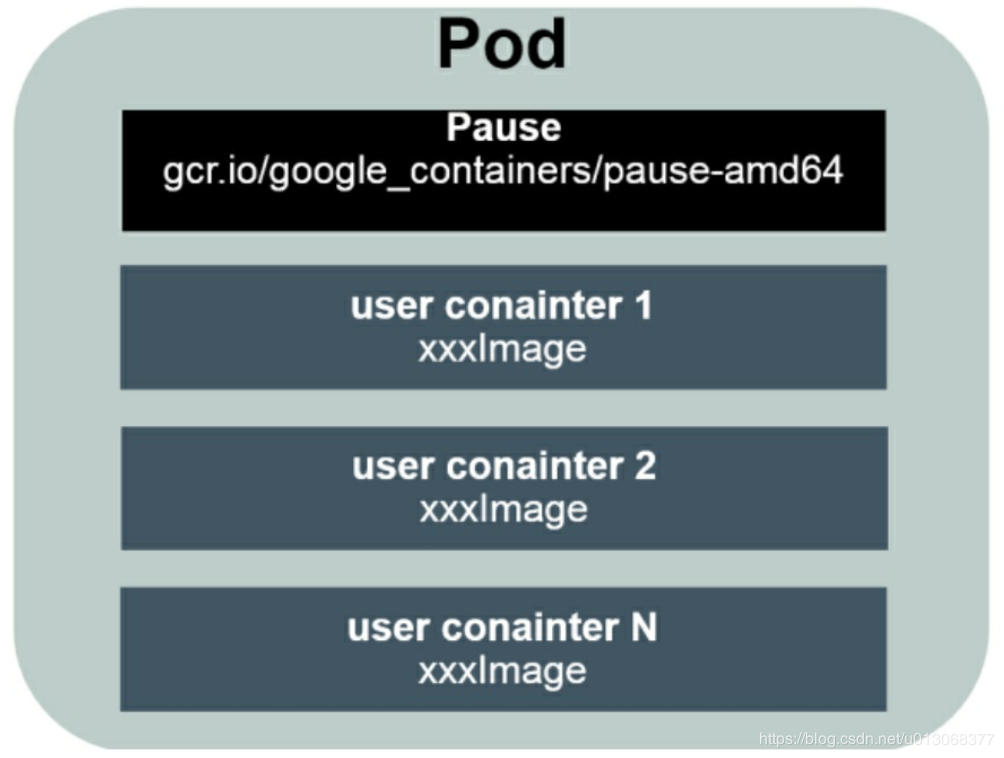
Q:为什么Kubernetes会设计出一个全新的Pod的概念并且Pod有Pause容器这样特殊的组成结构?
A:
- 原因之一:在一组容器作为一个单元的情况下,我们难以简单地 对“整体”进行判断及有效地行动。比如,一个容器死亡了,此时算是整体死亡么?是N/M的死亡率么?引入业务无关并且不易死亡的Pause容器作为Pod的根容器,以它的状态代表整个容器组的状态,就简单、巧妙地解决了这个难题。
- 原因之二:Pod里的多个业务容器共享Pause容器的IP,共享Pause容器挂载的V olume,这样既简化了密切关联的业务容器之间的通信问题,也很好地解决了它们之间的文件共享问题。
Kubernetes为每个Pod都分配了唯一的IP地址,称之为Pod IP,一个 Pod里的多个容器共享Pod IP地址。Kubernetes要求底层网络支持集群内任意两个Pod之间的TCP/IP直接通信,这通常采用虚拟二层网络技术来 实现,例如Flannel、Open vSwitch等,因此我们需要牢记一点:在 Kubernetes里,一个Pod里的容器与另外主机上的Pod容器能够直接通信。
Pod其实有两种类型:普通的Pod及静态Pod(Static Pod)。后者比较特殊,它并没被存放在Kubernetes的etcd存储里,而是被存放在某个具体的Node上的一个具体文件中,并且只在此Node上启动、运行。而普通的Pod一旦被创建,就会被放入etcd中存储,随后会被Kubernetes Master调度到某个具体的Node上并进行绑定(Binding),随后该Pod被对应的Node上的kubelet进程实例化成一组相关的Docker容器并启动。在默认情况下,当Pod里的某个容器停止时,Kubernetes会自动检测到这个问题并且重新启动这个Pod(重启Pod里的所有容器),如果Pod所在的 Node 宕机,就会将这个Node上的所有Pod重新调度到其他节点上。 Pod、容器与Node的关系如下图所示: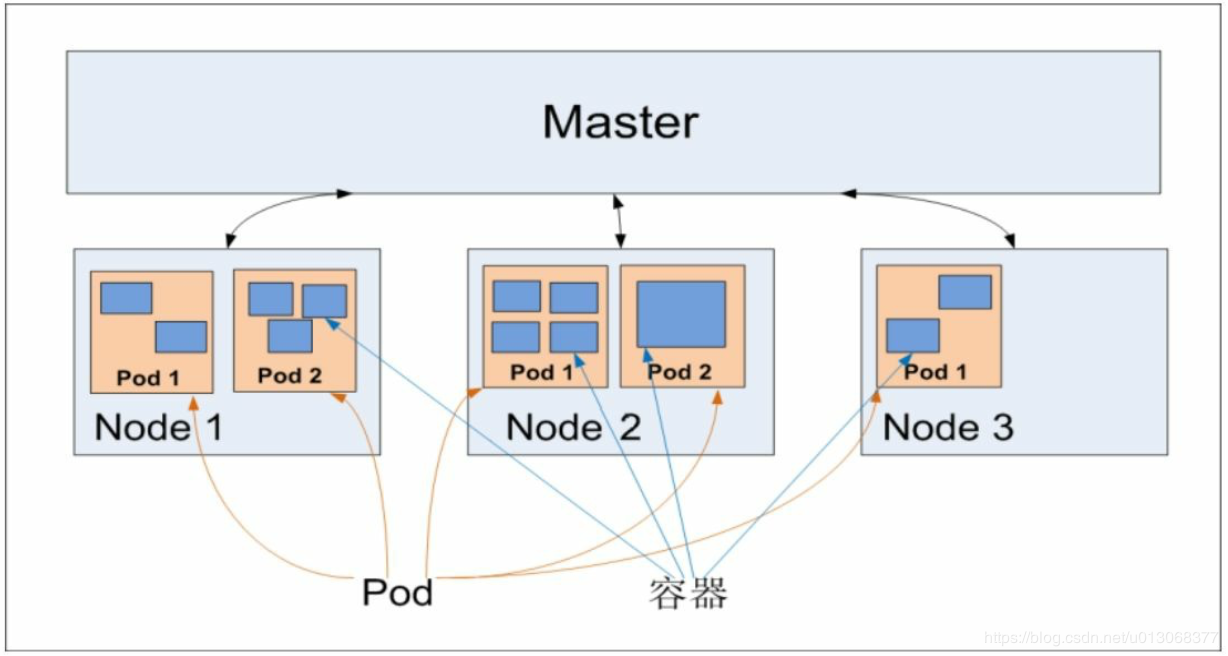
3.2、Pod YAML
Kubernetes里的所有资源对象都可以采用Y AML或者JSON格式的文件来定义或描述。例如: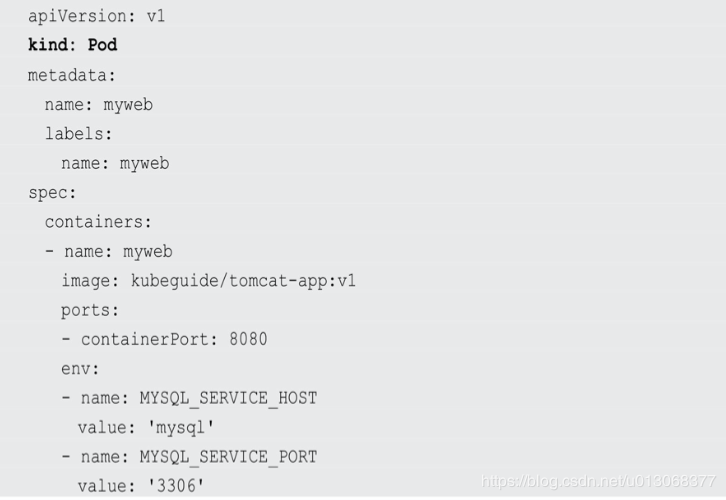
- Kind为Pod表明这是一个Pod的定义。
- metadata里的name属性为 Pod 的名称,在metadata里还能定义资源对象的标签,这里声明myweb拥有 一个name=myweb的标签。
- 在Pod里所包含的容器组的定义则在spec一节 中声明,这里定义了一个名为myweb、对应镜像为kubeguide/tomcat- app:v1的容器,该容器注入了名为MYSQL_SERVICE_HOST=’mysql’和 MYSQL_SERVICE_PORT=’3306’的环境变量(env关键字),并且在 8080端口(containerPort)启动容器进程。
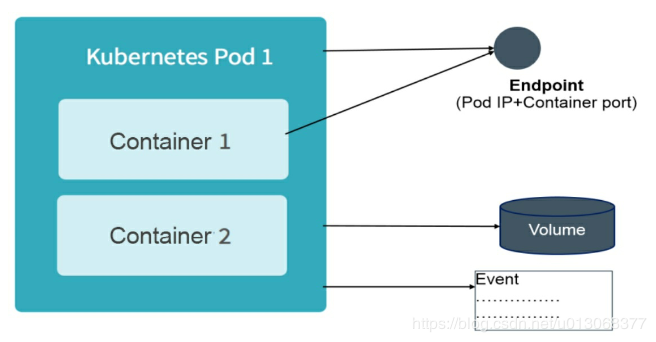
- EndPoint:Pod的IP加上这里的容器端口 (containerPort),组成了一个新的概念—Endpoint,它代表此Pod里的一个服务进程的对外通信地址。一个Pod也存在具有多个Endpoint的情 况,比如当我们把Tomcat定义为一个Pod时,可以对外暴露管理端口与服务端口这两个Endpoint。
- Volume:我们所熟悉的Docker Volume在Kubernetes里也有对应的概念—Pod Volume,后者有一些扩展,比如可以用分布式文件系统GlusterFS实现后端存储功能;Pod Volume是被定义在Pod上,然后被各个容器挂载到自己的文件系统中的。
- Events:Event是一个事件的记 录,记录了事件的最早产生时间、最后重现时间、重复次数、发起者、 类型,以及导致此事件的原因等众多信息。Event通常会被关联到某个 具体的资源对象上,是排查故障的重要参考信息,之前我们看到Node的 描述信息包括了Event,而Pod同样有Event记录,当我们发现某个Pod迟 迟无法创建时,可以用kubectl describe pod xxxx来查看它的描述信息, 以定位问题的成因
3.3、Pod资源配置
每个Pod都可以对其能使用的服务器上的计算资源设置限额,当前可以设置限额的计算资源有CPU与Memory两种,其中CPU的资源单位 为CPU(Core)的数量,是一个绝对值而非相对值。
对于绝大多数容器来说,一个CPU的资源配额相当大,所以在 Kubernetes里通常以千分之一的CPU配额为最小单位,用m来表示。通常一个容器的CPU配额被定义为100~300m,即占用0.1~0.3个CPU。由于CPU配额是一个绝对值,所以无论在拥有一个Core的机器上,还是在 拥有48个Core的机器上,100m这个配额所代表的CPU的使用量都是一样的。与CPU配额类似,Memory配额也是一个绝对值,它的单位是内存字节数。
在Kubernetes里,一个计算资源进行配额限定时需要设定以下两个参数。
- Requests:该资源的最小申请量,系统必须满足要求。
- Limits:该资源最大允许使用的量,不能被突破,当容器试图使用超过这个量的资源时,可能会被Kubernetes“杀掉”并重启。
通常,我们会把Requests设置为一个较小的数值,符合容器平时的工作负载情况下的资源需求,而把Limit设置为峰值负载情况下资源占用的最大量。
下面这段定义表明MySQL容器申请最少0.25个CPU及 64MiB内存,在运行过程中MySQL容器所能使用的资源配额为0.5个 CPU及128MiB内存:
四、Label
Label(标签)是Kubernetes系统中另外一个核心概念。一个Label是一个key=value的键值对,其中key与value由用户自己指定。Label可以被 附加到各种资源对象上,例如Node、Pod、Service、RC等,一个资源对 象可以定义任意数量的Label,同一个Label也可以被添加到任意数量的 资源对象上。Label通常在资源对象定义时确定,也可以在对象创建后 动态添加或者删除。
我们可以通过给指定的资源对象捆绑一个或多个不同的Label来实 现多维度的资源分组管理功能,以便灵活、方便地进行资源分配、调 度、配置、部署等管理工作。例如,部署不同版本的应用到不同的环境 中;监控和分析应用(日志记录、监控、告警)等。一些常用的Label 示例如下:
- 版本标签:”release”:”stable”、”release”:”canary”。
- 环境标 签:”environment”:”dev”、”environment”:”qa”、”environment”:”production”。
- 架构标 签:”tier”:”frontend”、”tier”:”backend”、”tier”:”middleware”。
- 分区标签:”partition”:”customerA”、”partition”:”customerB”。
- 质量管控标签:”track”:”daily”、”track”:”weekly”。
Label相当于我们熟悉的“标签”。给某个资源对象定义一个Label, 就相当于给它打了一个标签,随后可以通过Label Selector(标签选择 器)查询和筛选拥有某些Label的资源对象,Kubernetes通过这种方式实 现了类似SQL的简单又通用的对象查询机制。
Label Selector可以被类比为SQL语句中的where查询条件, 例如, name=redis-slave这个Label Selector作用于Pod时,可以被类比为select * from pod where pod’s name =‘redis-slave’这样的语句。当前有两种Label Selector表达式:基于等式的(Equality-based)和基于集合的(Set- based),前者采用等式类表达式匹配标签,下面是一些具体的例子:
- name=redis-slave:匹配所有具有标签name=redis-slave的资源对象。
- env!=production:匹配所有不具有标签env=production的资源对象,比如env=test就是满足此条件的标签之一。
后者则使用集合操作类表达式匹配标签,下面是一些具体的例子:
- name in(redis-master, redis-slave):匹配所有具有标签name=redis-master或者name=redis-slave的资源对象。
- name not in(php-frontend):匹配所有不具有标签name=php-frontend的资源对象。
也可以通过多个Label Selector表达式的组合实现复杂的条件选择,多个表达式之间用“,”进行分隔即可,几个条件之间是“AND”的关系,即 同时满足多个条件。
五、资源控制器
资源控制器个人理解是:Kubernetes针对不同的应用场景提炼出来的Pod的类型;
5.1、Replication Controller
Replication Controller(简称RC,中文名:副本控制器)是Kubernetes系统中的核心概念之一,简单来说,它其实定义了 一个期望的场景,即声明某种Pod的副本数量在任意时刻都符合某个预期值,所以RC的定义包括如下几个部分:
- Pod期待的副本数量。
- 用于筛选目标Pod的Label Selector。
- 当Pod的副本数量小于预期数量时,用于创建新Pod的Pod模板 (template)。
在我们定义了一个RC并将其提交到Kubernetes集群中后,Master上 的Controller Manager组件就得到通知,定期巡检系统中当前存活的目标 Pod,并确保目标Pod实例的数量刚好等于此RC的期望值,如果有过多 的Pod副本在运行,系统就会停掉一些Pod,否则系统会再自动创建一些 Pod。可以说,通过RC,Kubernetes实现了用户应用集群的高可用性, 并且大大减少了系统管理员在传统IT环境中需要完成的许多手工运维工 作(如主机监控脚本、应用监控脚本、故障恢复脚本等)。
Replication Controller由于与Kubernetes代码中的模块ReplicationController同名,同时“Replication Controller”无法准确表达它的本意,所 以在Kubernetes 1.2中,升级为另外一个新概念—Replica Set,官方解释 其为“下一代的RC”。Replica Set与RC当前的唯一区别是,Replica Sets支 持基于集合的Label selector(Set-based selector),而RC只支持基于等 式的Label Selector(equality-based selector),这使得Replica Set的功能更强。
最后总结一下RC(Replica Set)的一些特性与作用:
- 在大多数情况下,我们通过定义一个RC实现Pod的创建及副本数量的自动控制。
- 在RC里包括完整的Pod定义模板。
- RC通过Label Selector机制实现对Pod副本的自动控制。
- 通过改变RC里的Pod副本数量,可以实现Pod的扩容或缩容。
- 通过改变RC里Pod模板中的镜像版本,可以实现Pod的滚动升级。
5.2、Deployment
Deployment是Kubernetes在1.2版本中引入的新概念,用于更好地解决Pod的编排问题。为此,Deployment在内部使用了Replica Set来实现目的,无论从Deployment的作用与目的、YAML定义,还是从它的具体命令行操作来看,我们都可以把它看作RC的一次升级,两者的相似度超过90%。
Deployment相对于RC的一个最大升级是我们可以随时知道当前 Pod“部署”的进度。实际上由于一个Pod的创建、调度、绑定节点及在目标Node上启动对应的容器这一完整过程需要一定的时间,所以我们期待系统启动N个Pod副本的目标状态,实际上是一个连续变化的“部署过程”导致的最终状态。
Deployment的典型使用场景有以下几个:
- 创建一个Deployment对象来生成对应的Replica Set并完成Pod副本的创建。
- 检查Deployment的状态来看部署动作是否完成(Pod副本数量 是否达到预期的值)。
- 滚动升级和回滚:更新Deployment以创建新的Pod(比如镜像升级);如果当前Deployment不稳定,则回滚到一个早先的Deployment 版本。
- 暂停和继续 :暂停Deployment以便于一次性修改多个PodTemplateSpec的配置项,之后再恢复Deployment,进行新的发布。
- 扩容和缩容 :扩展Deployment以应对高负载。
- 查看Deployment的状态,以此作为发布是否成功的指标。
- 清理不再需要的旧版本ReplicaSets。
通过如下命令创建deployment:
kubectl create -f deployment.yaml
查看运行的deployment信息:
kubectl get deployment

对上述输出中涉及的数量解释如下:
- DESIRED:Pod副本数量的期望值,即在Deployment里定义的Replica。
- CURRENT:当前Replica的值,实际上是Deployment创建的 Replica Set里的Replica值,这个值不断增加,直到达到DESIRED为止, 表明整个部署过程完成。
- UP-TO-DATE:最新版本的Pod的副本数量,用于指示在滚动升级的过程中,有多少个Pod副本已经成功升级。
- AVAILABLE:当前集群中可用的Pod副本数量,即集群中当前存活的Pod数量。
运行下述命令查看对应的Replica Set,我们看到它的命名与Deployment的名称有关系:
运行下述命令查看创建的Pod,我们发现Pod的命名以Deployment对应的Replica Set的名称为前缀,这种命名很清晰地表明了一个Replica Set 创建了哪些Pod,对于Pod滚动升级这种复杂的过程来说,很容易排查错误:
Pod的管理对象,除了RC和Deployment,还包括ReplicaSet、 DaemonSet、StatefulSet、Job等,分别用于不同的应用场景中,将在后续进行详细介绍。
5.3、Horizontal Pod Autoscaler(Pod横向自动扩容,HPA)
Kubernetes从1.6版本开始,增强了根据应用自定义的指标进行自动扩容和缩容的功能,API版本为autoscaling/v2alpha1,并不断演进。
HPA与之前的RC、Deployment一样,也属于一种Kubernetes资源对象。通过追踪分析指定RC控制的所有目标Pod的负载变化情况,来确定是否需要有针对性地调整目标Pod的副本数量,这是HPA的实现原理。 当前,HPA有以下两种方式作为Pod负载的度量指标:
- CPUUtilizationPercentage。
- 应用程序自定义的度量指标,比如服务在每秒内的相应请求数(TPS或QPS)。
CPUUtilizationPercentage是一个算术平均值,即目标Pod所有副本自 身的CPU利用率的平均值。一个Pod自身的CPU利用率是该Pod当前CPU 的使用量除以它的Pod Request的值,比如定义一个Pod的Pod Request为 0.4,而当前Pod的CPU使用量为0.2,则它的CPU使用率为50%,这样就 可以算出一个RC控制的所有Pod副本的CPU利用率的算术平均值了。如 果某一时刻CPUUtilizationPercentage的值超过80%,则意味着当前Pod副 本数量很可能不足以支撑接下来更多的请求,需要进行动态扩容,而在 请求高峰时段过去后,Pod的CPU利用率又会降下来,此时对应的Pod副 本数应该自动减少到一个合理的水平。如果目标Pod没有定义Pod Request的值,则无法使用CPUUtilizationPercentage实现Pod横向自动扩容。
要计算CPU利用率的话,需要一个采集监控框架,现在Kubernetes支持有Heapster、Kubernetes Monitoring Architecture
下面是HPA定义的一个具体例子: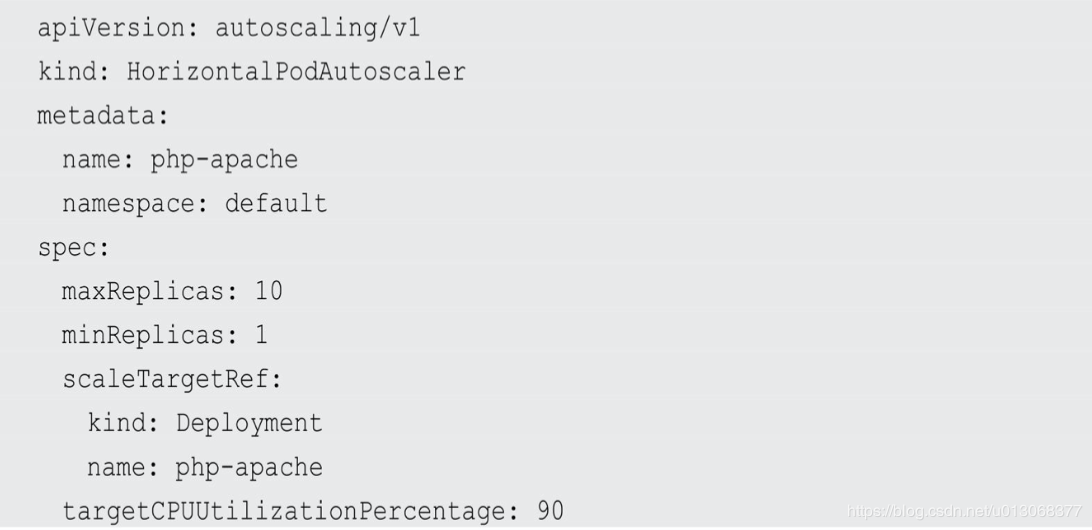
根据上面的定义,我们可以知道这个HPA控制的目标对象为一个名 为php-apache的Deployment里的Pod副本,当这些Pod副本的 CPUUtilizationPercentage的值超过90%时会触发自动动态扩容行为,在 扩容或缩容时必须满足的一个约束条件是Pod的副本数为1~10。
5.4、StatefulSet
在Kubernetes系统中,Pod的管理对象RC、Deployment、DaemonSet 和Job都面向无状态的服务。但现实中有很多服务是有状态的,特别是 一些复杂的中间件集群,例如MySQL集群、MongoDB集群、Akka集 群、ZooKeeper集群等,这些应用集群有4个共同点:
- 每个节点都有固定的身份ID,通过这个ID,集群中的成员可 以相互发现并通信。
- 集群的规模是比较固定的,集群规模不能随意变动。
- 集群中的每个节点都是有状态的,通常会持久化数据到永久存储中。
- 如果磁盘损坏,则集群里的某个节点无法正常运行,集群功能受损。
如果通过RC或Deployment控制Pod副本数量来实现上述有状态的集 群,就会发现第1点是无法满足的,因为Pod的名称是随机产生的,Pod 的IP地址也是在运行期才确定且可能有变动的,我们事先无法为每个 Pod都确定唯一不变的ID。另外,为了能够在其他节点上恢复某个失败 的节点,这种集群中的Pod需要挂接某种共享存储,为了解决这个问 题,Kubernetes从1.4版本开始引入了PetSet这个新的资源对象,并且在 1.5版本时更名为StatefulSet,StatefulSet从本质上来说,可以看作 Deployment/RC的一个特殊变种,它有如下特性:
- 稳定的网络标志:StatefulSet里的每个Pod都有稳定、唯一的网络标识,可以用来发现集群内的其他成员。假设StatefulSet的名称为kafka,那么第1个Pod 叫kafka-0,第2个叫kafka-1,以此类推。
- 有序部署:StatefulSet控制的Pod副本的启停顺序是受控的,操作第n个Pod 时,前n-1个Pod已经是运行且准备好的状态。
- 稳定的持久化存储:StatefulSet里的Pod采用稳定的持久化存储卷,通过 PV或PVC来 实现,删除Pod时默认不会删除与StatefulSet相关的存储卷(为了保证数据的安全)。
StatefulSet除了要与PV卷捆绑使用以存储Pod的状态数据,还要与 Headless Service 配合使用,即在每个StatefulSet定义中都要声明它属于哪个Headless Service。Headless Service与普通Service的关键区别在于,它没有Cluster IP,如果解析Headless Service的DNS域名,则返回的是该 Service对应的全部Pod的Endpoint列表。StatefulSet在Headless Service的 基础上又为StatefulSet控制的每个Pod实例都创建了一个DNS域名,这个 域名的格式为:
${podname}.${headless service name}
比如一个3节点的Kafka的StatefulSet集群对应的Headless Service的名称为kafka,StatefulSet的名称为kafka,则StatefulSet里的3个Pod的DNS 名称分别为kafka-0.kafka、kafka-1.kafka、kafka-3.kafka,这些DNS名称可以直接在集群的配置文件中固定下来。
5.5、DaemonSet
DaemonSet确保全部(或者一些)Node上运行一个Pod副本,当有Node加入集群时,也会为他们新增一个Pod。当有Node从集群移除时,这些Pod也会被回收。删除DaemonSet将会删除它创建的Pod;
典型应用场景:
- 运行集群存储Daemon,例如:在每个Node上运行 glusted、ceph
- 在每个Node上运行日志收集Daemon,例如:fluentd、logstash
- 在每个Node上运行监控Daemon,例如:Prometheus
5.6、Job
批处理任务通常并行(或者串行)启动多个计算进程去处理一批工作项(work item),在处理完成后,整个批处理任务结束。
与RC、 Deployment、ReplicaSet、DaemonSet类似,Job也控制一组Pod容器。从 这个角度来看,Job也是一种特殊的Pod副本自动控制器,同时Job控制 Pod副本与RC等控制器的工作机制有以下重要差别:
- 仅运行一次: Job所控制的Pod副本是短暂运行的,可以将其视为一组 Docker容器,其中的每个Docker容器都仅仅运行一次。当Job控制的所有Pod副本都运行结束时,对应的Job也就结束了。Job在实现方式上与 RC等副本控制器不同,Job生成的Pod副本是不能自动重启的,对应Pod 副本的RestartPoliy都被设置为Never。因此,当对应的Pod副本都执行完成时,相应的Job也就完成了控制使命,即Job生成的Pod在Kubernetes中 是短暂存在的。
- 并行运算: Job所控制的Pod副本的工作模式能够多实例并行计算,以 TensorFlow框架为例,可以将一个机器学习的计算任务分布到10台机器 上,在每台机器上都运行一个worker执行计算任务,这很适合通过Job 生成10个Pod副本同时启动运算。
5.7、CronJob
与Job类似,最大的不同点在于:周期性的运行
参考:
《Kubernetes权威指南: 第四版》

若有收获,就点个赞吧
0 人点赞
