Pod详解中,我们深入探索Pod的应用、配置、调度、升级及扩缩容
一、Pod Yaml文件定义



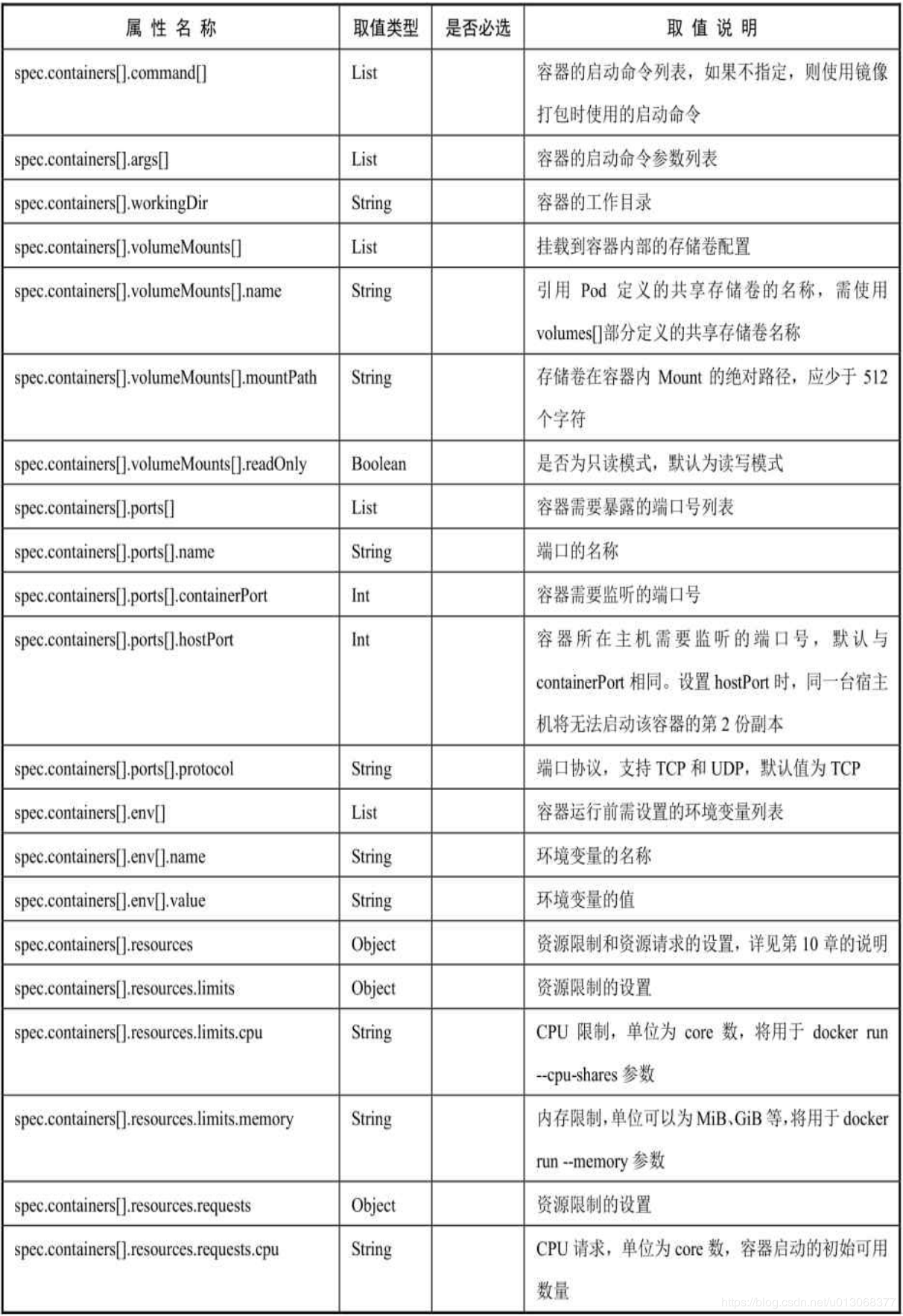
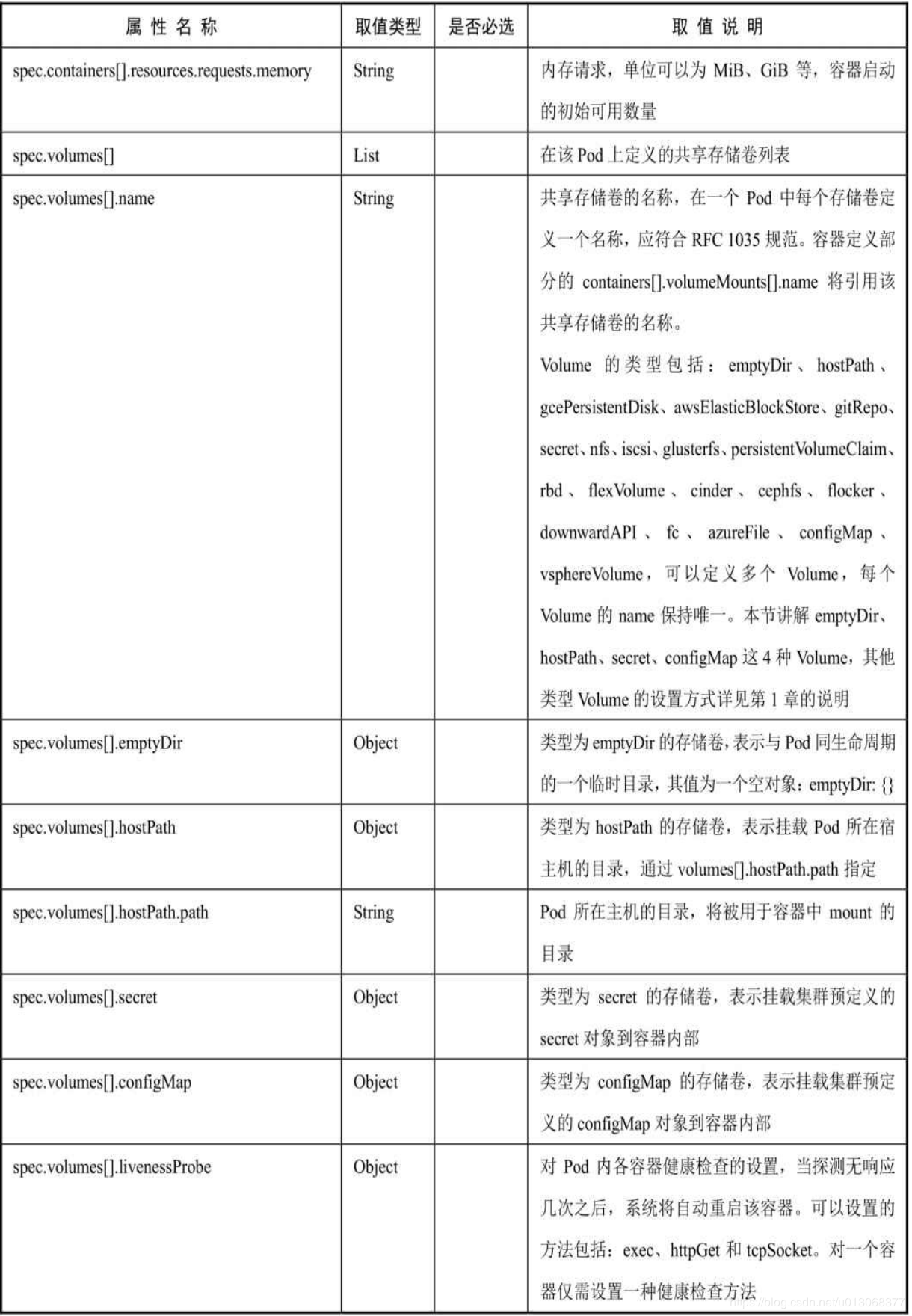
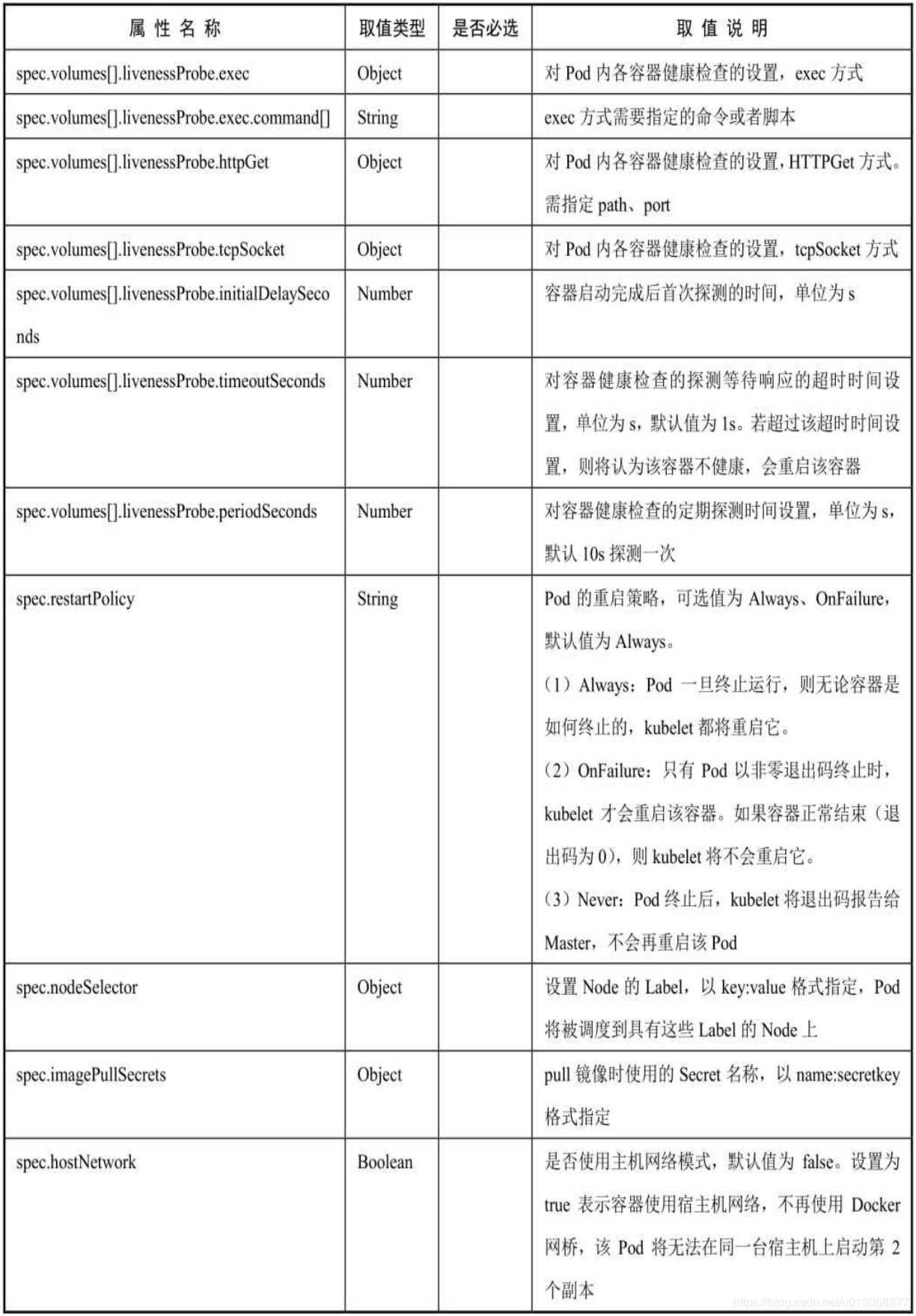
对各属性的详细说明如下表所示: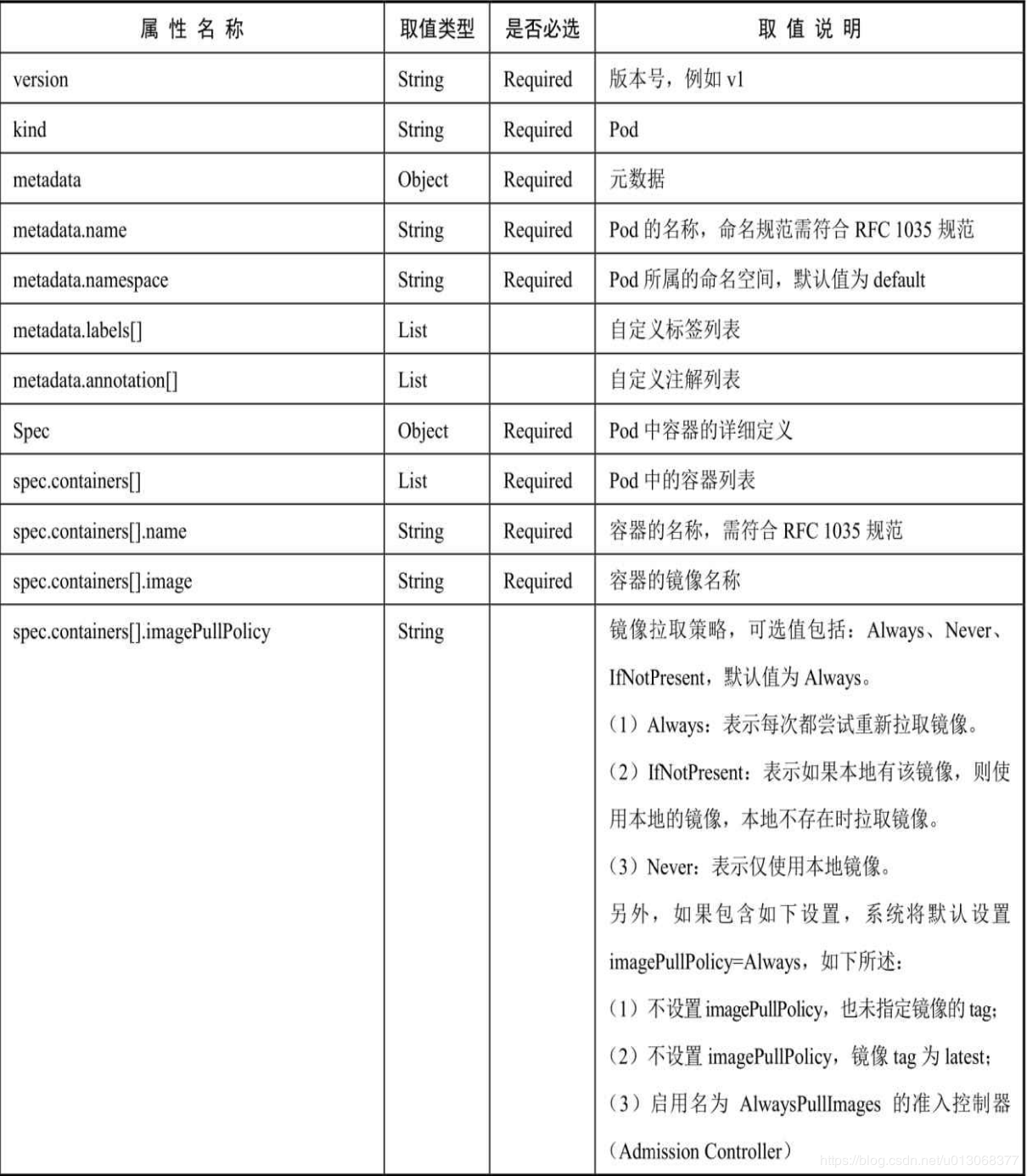
二、Pod的启动
在使用Docker时,可以使用docker run命令创建并启动一个容器。而在Kubernetes系统中对长时间运行容器的要求是:其主程序需要一直在前台执行。如果我们创建的Docker镜像的启动命令是后台执行程序, 例如Linux脚本:
nohup start.sh &
则在kubelet创建包含这个容器的Pod之后运行完该命令,即认为Pod 执行结束,将立刻销毁该Pod。如果为该Pod定义了 ReplicationController,则系统会监控到该Pod已经终止,之后根据RC定 义中Pod的replicas副本数量生成一个新的Pod。一旦创建新的Pod,就在 执行完启动命令后陷入无限循环的过程中。这就是Kubernetes需要我们 自己创建的Docker镜像并以一个前台命令作为启动命令的原因。
对于无法改造为前台执行的应用,也可以使用开源工具Supervisor 辅助进行前台运行的功能。Supervisor提供了一种可以同时启动多个后 台应用,并保持Supervisor自身在前台执行的机制,可以满足Kubernetes 对容器的启动要求。
三、静态Pod
静态Pod是由kubelet进行管理的仅存在于特定Node上的Pod。它们不能通过API Server进行管理,无法与ReplicationController、Deployment 或者DaemonSet进行关联,并且kubelet无法对它们进行健康检查。静态 Pod总是由kubelet创建的,并且总在kubelet所在的Node上运行。
创建静态Pod有两种方式,配置文件方式和HTTP方式:
- 配置文件方式
需要设置kubelet的启动参数“—config”,指定kubelet需要监控 的配置文件所在的目录,kubelet会定期扫描该目录,并根据该目录下 的.yaml或.json文件进行创建操作。 - HTTP方式
通过设置kubelet的启动参数“—manifest-url”,kubelet将会定期从该URL地址下载Pod的定义文件,并以.yaml或.json文件的格式进行解析, 然后创建Pod。其实现方式与配置文件方式是一致的。
应用场景:
四、Pod容器共享Volume
同一个Pod中的多个容器能够共享Pod级别的存储卷Volume。Volume可以被定义为各种类型,多个容器各自进行挂载操作,将一个 Volume挂载为容器内部需要的目录,如下图: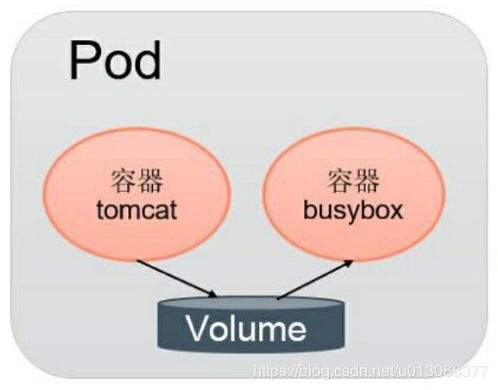
yaml定义: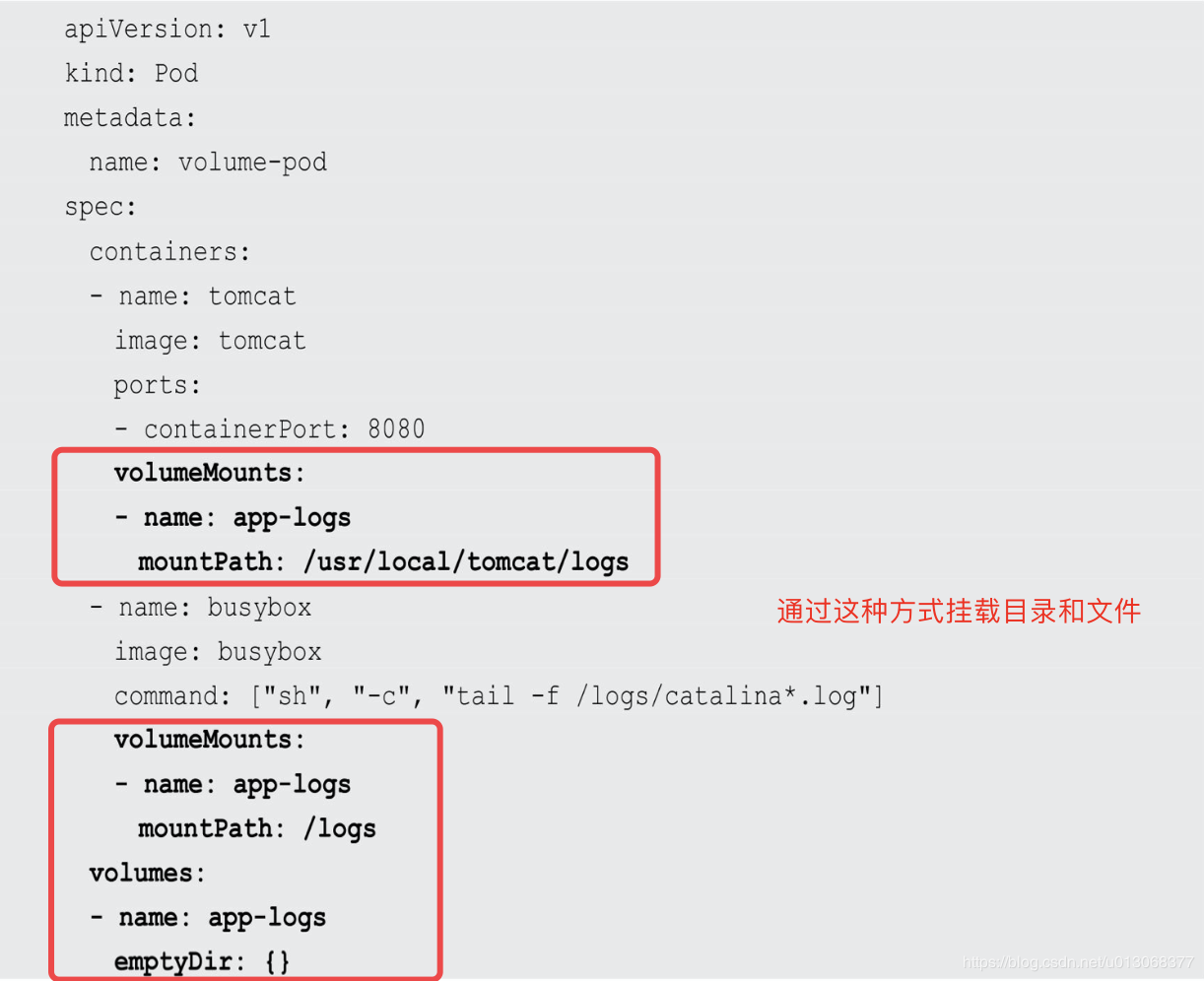
五、Pod的配置管理(ConfigMap)
应用部署的一个最佳实践是将应用所需的配置信息与程序进行分 离,这样可以使应用程序被更好地复用,通过不同的配置也能实现更灵 活的功能。将应用打包为容器镜像后,可以通过环境变量或者外挂文件 的方式在创建容器时进行配置注入,但在大规模容器集群的环境中,对 多个容器进行不同的配置将变得非常复杂。从Kubernetes 1.2开始提供了 一种统一的应用配置管理方案—ConfigMap。
5.1、概述
ConfigMap供容器使用的典型用法如下:
- 生成为容器内的环境变量。
- 设置容器启动命令的启动参数(需设置为环境变量)。
- 以Volume的形式挂载为容器内部的文件或目录。
ConfigMap以一个或多个key:value的形式保存在Kubernetes系统中供应用使用:
- 既可以用于表示一个变量的值(例如apploglevel=info)
- 也可以用于表示一个完整配置文件的内容(例如:server.xml=<?xml…>…)
可以通过YAML配置文件或者直接使用kubectl create configmap命令行的方式来创建ConfigMap。
5.2、创建ConfigMap
通过Yaml配置文件创建
# 创建configMap$ kubectl create -f configmap.yaml# 查看configMap$ kubectl get configmap# 查看具体描述$ kubectl describe configmap configmapName# 得到具体的yaml$ kubectl get configmap configMap -o yaml
通过命令行创建
不使用Y AML文件,直接通过kubectl create configmap也可以创建 ConfigMap,可以使用参数—from-file或—from-literal指定内容,并且可以在一行命令中指定多个参数。
- 通过—from-file参数从文件中进行创建,可以指定key的名 称,也可以在一个命令行中创建包含多个key的ConfigMap,语法为:
$ kubectl create configmap --from-file=[key=]source
- 通过—from-file参数从目录中进行创建,该目录下的每个配置文件名被设置为key,文件的内容被设置为value,语法为:
$ kubectl create configmap --from-file=config-file-dir
- 使用—from-literal时会从文本中进行创建,直接将指定的 key#=value#创建为ConfigMap的内容,语法为:
$ kubectl create configmap --from-literal=k1=v1 --from-literal=k2=v2
5.3、在容器中使用ConfigMap
容器应用对ConfigMap的使用有以下两种方法:
- 通过环境变量获取ConfigMap中的内容:一般用来操作键值对配置
- 通过Volume挂载的方式将ConfigMap中的内容挂载为容器内部的文件或目录:一般用来操作配置文件、日志配置文件等
5.4、使用ConfigMap的限制条件
使用ConfigMap的限制条件如下:
- ConfigMap必须在Pod之前创建:可以通过initContainer实现
- ConfigMap受Namespace限制,只有处于相同Namespace中的 Pod才可以引用它。
- ConfigMap中的配额管理还未能实现。
- kubelet只支持可以被API Server管理的Pod使用ConfigMap。 kubelet在本Node上通过 —manifest-url或—config自动创建的静态Pod将无 法引用ConfigMap。
- 在Pod对ConfigMap进行挂载(volumeMount)操作时,在容器 内部只能挂载为“目录”,无法挂载为“文件”。在挂载到容器内部后,在 目录下将包含ConfigMap定义的每个item,如果在该目录下原来还有其 他文件,则容器内的该目录将被挂载的ConfigMap覆盖。如果应用程序 需要保留原来的其他文件,则需要进行额外的处理。可以将ConfigMap 挂载到容器内部的临时目录,再通过启动脚本将配置文件复制或者链接 到(cp或link命令)应用所用的实际配置目录下。
六、在容器内获取Pod信息(Downward API)
我们知道,每个Pod在被成功创建出来之后,都会被系统分配唯一的名字、IP地址,并且处于某个Namespace中,那么我们如何在Pod的容器内获取Pod的重要信息或者容器资源信息呢?答案就是使用Downward API。
Downward API可以通过以下两种方式将Pod信息注入容器内部:
- 环境变量:用于单个变量,可以将Pod信息和Container信息注入容器内部,目前Downward API 提供了以下变量:
- metadata.name:Pod的名称,当Pod通过RS生成时,其名称是RS随机产生的唯一名称。
- status.podIP:Pod的IP地址,之所以叫作status.podIP而非 metadata.IP,是因为Pod的IP属于状态数据,而非元数据。
- metadata.namespace:Pod所在的Namespace。
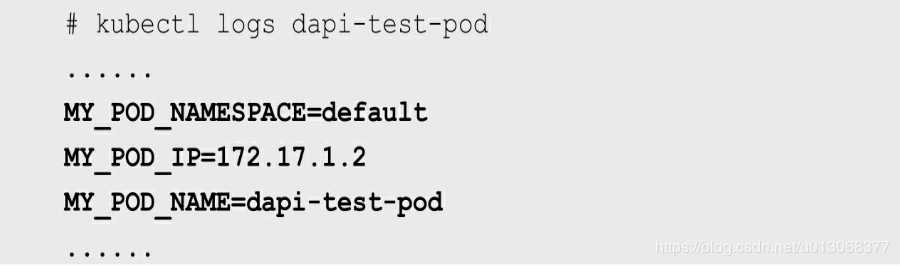
此外还提供了容器资源信息:
- Volume挂载:将数组类信息生成为文件并挂载到容器内部。
应用场景:
在某些集群中,集群中的每个节点都需要将自身的标识(ID)及进程绑定的IP地址等信息事先写入配置文件中,进程在启动时会读取这些 信息,然后将这些信息发布到某个类似服务注册中心的地方,以实现集 群节点的自动发现功能。此时Downward API就可以派上用场了,具体做法是先编写一个预启动脚本或Init Container,通过环境变量或文件方式获取Pod自身的名称、IP地址等信息,然后将这些信息写入主程序的配置文件中,最后启动主程序。
七、Pod生命周期和重启策略
7.1、Pod状态表
Pod在整个生命周期中被系统定义为各种状态,熟悉Pod的各种状态对于理解如何设置Pod的调度策略、重启策略是很有必要的。Pod状态表如下: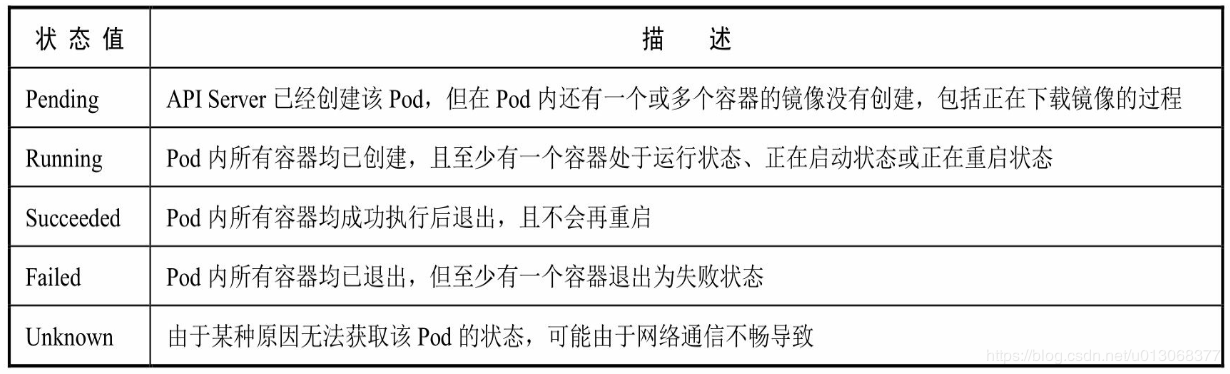
7.2、Pod重启策略
Pod的重启策略(RestartPolicy)应用于Pod内的所有容器,并且仅在Pod所处的Node上由kubelet进行判断和重启操作。当某个容器异常退出或者健康检查失败时,kubelet将根据RestartPolicy的设置来进行相应的操作。
Pod的重启策略包括Always、OnFailure和Never,默认值为Always。
- Always:当容器失效时,由kubelet自动重启该容器。
- OnFailure:当容器终止运行且退出码不为0时,由kubelet自动重启该容器。
- Never:不论容器运行状态如何,kubelet都不会重启该容器。
kubelet重启失效容器的时间间隔以sync-frequency乘以2n来计算,例如1、2、4、8倍等,最长延时5min,并且在成功重启后的10min后重置该时间。
Pod的重启策略与控制方式息息相关,当前可用于管理Pod的控制器包括ReplicationController、Job、DaemonSet及静态Pod(直接通过kubelet管理)。每种控制器对Pod的重启策略要求如下:
- RC和DaemonSet:必须设置为Always,需要保证该容器持续运行。
- Job:OnFailure或Never,确保容器执行完成后不再重启。
- 静态Pod:在Pod失效时自动重启它,不论将RestartPolicy设置为什么值,也不会对Pod进行健康检查。
结合Pod的状态和重启策略,下表列出一些常见的状态转换场景: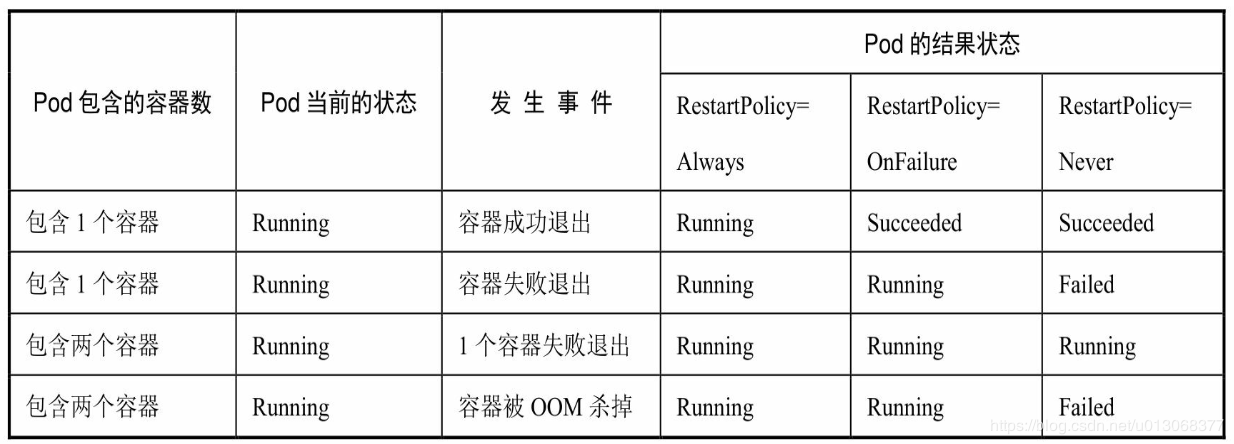
八、Pod健康检查和服务可用性检查
Kubernetes 对 Pod 的健康状态可以通过两类探针来检查: LivenessProbe 和ReadinessProbe,kubelet定期执行这两类探针来诊断容器的健康状况。
- LivenessProbe探针(Pod健康检查):用于判断容器是否存活(Running状态),如果LivenessProbe探针探测到容器不健康,则kubelet将杀掉该容器,并根据容器的重启策略做相应的处理。如果一个容器不包含 LivenessProbe探针,那么kubelet认为该容器的LivenessProbe探针返回的值永远是Success。
- ReadinessProbe探针(服务可用性检查):用于判断容器服务是否可用(Ready状 态),达到Ready状态的Pod才可以接收请求。对于被Service管理的 Pod,Service与Pod Endpoint的关联关系也将基于Pod是否Ready进行设置。如果在运行过程中Ready状态变为False,则系统自动将其从Service 的后端Endpoint列表中隔离出去,后续再把恢复到Ready状态的Pod加回后端Endpoint列表。这样就能保证客户端在访问Service时不会被转发到服务不可用的Pod实例上。
LivenessProbe和ReadinessProbe均可配置以下三种实现方式。
- ExecAction:在容器内部执行一个命令,如果该命令的返回码为0,则表明容器健康。
- TCPSocketAction:通过容器的IP地址和端口号执行TCP检 查,如果能够建立TCP连接,则表明容器健康。
- HTTPGetAction:通过容器的IP地址、端口号及路径调用 HTTP Get方法,如果响应的状态码大于等于200且小于400,则认为容器健康。
对于每种探测方式,都需要设置initialDelaySeconds和 timeoutSeconds两个参数,它们的含义分别如下:
- initialDelaySeconds:启动容器后进行首次健康检查的等待时间,单位为s。
- timeoutSeconds:健康检查发送请求后等待响应的超时时间, 单位为s。当超时发生时,kubelet会认为容器已经无法提供服务,将会重启该容器。
九、玩转Pod调度
应用场景
- 我们希望Deployment创建的Pod副本被成功调度 到集群中的任何一个可用节点,而不关心具体会调度到哪个节点。但 是,在真实的生产环境中的确也存在一种需求:希望某种Pod的副本全 部在指定的一个或者一些节点上运行,比如希望将MySQL数据库调度 到一个具有SSD磁盘的目标节点上,此时Pod模板中的NodeSelector属性 就开始发挥作用了
- 不同Pod之间的亲和性(Affinity)。比如MySQL数据库与 Redis中间件不能被调度到同一个目标节点上,或者两种不同的Pod必须 被调度到同一个Node上,以实现本地文件共享或本地网络通信等特殊需 求,这就是PodAffinity要解决的问题。
- 有状态集群的调度。对于ZooKeeper、Elasticsearch、 MongoDB、Kafka等有状态集群,虽然集群中的每个Worker节点看起来 都是相同的,但每个Worker节点都必须有明确的、不变的唯一ID(主机 名或IP地址),这些节点的启动和停止次序通常有严格的顺序。此外, 由于集群需要持久化保存状态数据,所以集群中的Worker节点对应的 Pod不管在哪个Node上恢复,都需要挂载原来的V olume,因此这些Pod 还需要捆绑具体的PV。针对这种复杂的需求,Kubernetes提供了 StatefulSet这种特殊的副本控制器来解决问题,在Kubernetes 1.9版本发 布后,StatefulSet才可用于正式生产环境中。
- 在每个Node上调度并且仅仅创建一个Pod副本。这种调度通 常用于系统监控相关的Pod,比如主机上的日志采集、主机性能采集等 进程需要被部署到集群中的每个节点,并且只能部署一个副本,这就是 DaemonSet这种特殊Pod副本控制器所解决的问题。
- 对于批处理作业,需要创建多个Pod副本来协同工作,当这些 Pod副本都完成自己的任务时,整个批处理作业就结束了。这种Pod运行 且仅运行一次的特殊调度,用常规的RC或者Deployment都无法解决, 所以Kubernates引入了新的Pod调度控制器Job来解决问题,并继续延伸 了定时作业的调度控制器CronJob。
9.1、Deployment或RC:全自动调度
Deployment或RC的主要功能之一就是自动部署一个容器应用的多 份副本,以及持续监控副本的数量,在集群内始终维持用户指定的副本数量。
从调度策略上来说,这3个Nginx Pod由系统全自动完成调度。它们 各自最终运行在哪个节点上,完全由Master的Scheduler经过一系列算法 计算得出,用户无法干预调度过程和结果。
9.2、NodeSelector:定向调度
Kubernetes Master上的Scheduler服务(kube-scheduler进程)负责实 现Pod的调度,整个调度过程通过执行一系列复杂的算法,最终为每个 Pod都计算出一个最佳的目标节点,这一过程是自动完成的,通常我们无法知道Pod最终会被调度到哪个节点上。在实际情况下,也可能需要 将Pod调度到指定的一些Node上,可以通过Node的标签(Label)和Pod 的nodeSelector属性相匹配,来达到上述目的。
# 给指定Node打上标签$ kubectl label node <node-name> <label-key>=<label-value># 在 Deployment yaml中增加 NodeSelector
如果我们给多个Node都定义了相同的标签(例如zone=north),则 scheduler会根据调度算法从这组Node中挑选一个可用的Node进行Pod调度。
需要注意的是,如果我们指定了Pod的nodeSelector条件,且在集群 中不存在包含相应标签的Node,则即使在集群中还有其他可供使用的 Node,这个Pod也无法被成功调度。
除了用户可以自行给Node添加标签,Kubernetes也会给Node预定义 一些标签,包括:
- kubernetes.io/hostname
- beta.kubernetes.io/os(从1.14版本开始更新为稳定版,到1.18版本删除)
- beta.kubernetes.io/arch(从1.14版本开始更新为稳定版,到1.18 版本删除)
- kubernetes.io/os(从1.14版本开始启用)
- kubernetes.io/arch(从1.14版本开始启用) 用户也可以使用这些系统标签进行Pod的定向调度。
9.3、NodeAffinity:Node亲和性调度
NodeSelector通过标签的方式,简单实现了限制Pod所在节点的方 法。亲和性调度机制则极大扩展了Pod的调度能力,主要的增强功能如下:
- 更具表达力(不仅仅是“符合全部”的简单情况)。
- 可以使用软限制、优先采用等限制方式,代替之前的硬限制, 这样调度器在无法满足优先需求的情况下,会退而求其次,继续运行该 Pod。
- 可以依据节点上正在运行的其他Pod的标签来进行限制,而非 节点本身的标签。这样就可以定义一种规则来描述Pod之间的亲和或互 斥关系。
亲和性调度功能包括节点亲和性(NodeAffinity)和Pod亲和性 (PodAffinity)两个维度的设置。节点亲和性与NodeSelector类似,增 强了上述前两点优势;Pod的亲和与互斥限制则通过Pod标签而不是节点 标签来实现,也就是上面第4点内容所陈述的方式,同时具有前两点提 到的优点。
9.4、PodAffinity:Pod亲和与互斥调度策略
Pod间的亲和与互斥从Kubernetes 1.4版本开始引入。这一功能让用 户从另一个角度来限制Pod所能运行的节点:根据在节点上正在运行的 Pod的标签而不是节点的标签进行判断和调度,要求对节点和Pod两个条 件进行匹配。这种规则可以描述为:如果在具有标签X的Node上运行了 一个或者多个符合条件Y的Pod,那么Pod应该(如果是互斥的情况,那么就变成拒绝)运行在这个Node上。
真正使用时,可参考:《Kubernetes权威指南》
9.5、Taints和Tolerations(污点和容忍)
前面介绍的NodeAffinity节点亲和性,是在Pod上定义的一种属性, 使得Pod能够被调度到某些Node上运行(优先选择或强制要求)。Taint 则正好相反,它让Node拒绝Pod的运行。
Taint需要和Toleration配合使用,让Pod避开那些不合适的Node。在 Node上设置一个或多个Taint之后,除非Pod明确声明能够容忍这些污 点,否则无法在这些Node上运行。Toleration是Pod的属性,让Pod能够 (注意,只是能够,而非必须)运行在标注了Taint的Node上。
9.6、Pod Priority Preemption:Pod优先级调度
对于运行各种负载(如Service、Job)的中等规模或者大规模的集 群来说,出于各种原因,我们需要尽可能提高集群的资源利用率。而提 高资源利用率的常规做法是采用优先级方案,即不同类型的负载对应不 同的优先级,同时允许集群中的所有负载所需的资源总量超过集群可提 供的资源,在这种情况下,当发生资源不足的情况时,系统可以选择释 放一些不重要的负载(优先级最低的),保障最重要的负载能够获取足够的资源稳定运行。
9.7、DaemonSet:在每个Node上都调度一个Pod
DaemonSet是Kubernetes 1.2版本新增的一种资源对象,用于管理在 集群中每个Node上仅运行一份Pod的副本实例;
这种用法适合有这种需求的应用。
- 在每个Node上都运行一个GlusterFS存储或者Ceph存储的 Daemon进程。
- 在每个Node上都运行一个日志采集程序,例如Fluentd或者 Logstach。
- 在每个Node上都运行一个性能监控程序,采集该Node的运行性能数据,例如Prometheus Node Exporter、collectd、New Relic agent或 者Ganglia gmond等。
DaemonSet的Pod调度策略与RC类似,除了使用系统内置的算法在 每个Node上进行调度,也可以在Pod的定义中使用NodeSelector或 NodeAffinity来指定满足条件的Node范围进行调度。
9.8、Job:批处理调度
Kubernetes从1.2版本开始支持批处理类型的应用,我们可以通过 Kubernetes Job资源对象来定义并启动一个批处理任务。批处理任务通常 并行(或者串行)启动多个计算进程去处理一批工作项(work item), 处理完成后,整个批处理任务结束。
9.9、Cronjob:定时任务
Kubernetes从1.5版本开始增加了一种新类型的Job,即类似Linux Cron的定时任务Cron Job。
9.10、自定义调度器
如果Kubernetes调度器的众多特性还无法满足我们的独特调度需求,则还可以用自己开发的调度器进行调度。
参考
《Kubernetes权威指南:第四版》

若有收获,就点个赞吧
0 人点赞
