一 学习流程的常规闭环
按此常规闭环, 可对我们有学习计划并已添加至 SuperMemo 软件的学习材料进行常规闭环学习.
流程为: 步骤 1-> 步骤 2-> 步骤 3-> 步骤 1
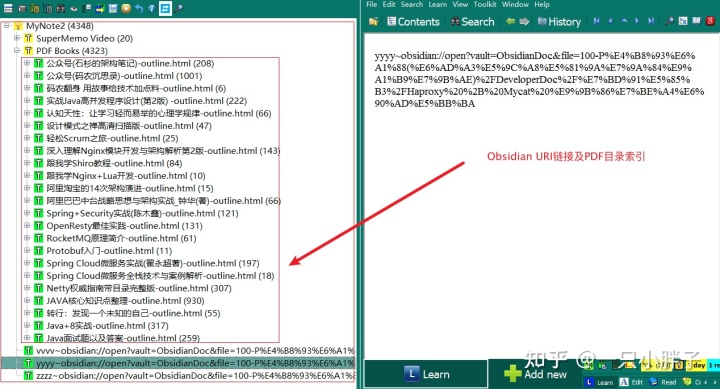
引用形式管理学习材料
步骤 1.SuperMemo 添加索引
在 SuperMemo 中放置学习材料, 如 PDF 目录索引 / 视频文件链接 / 网页内容及链接 / Obsidian 笔记链接, 通过 SuperMemo 来检索资料, 设置优先级, 安排学习计划.
步骤 2. 开始学习不同的材料
在 SuperMemo 外使用对应的软件来学习, 如 PDF 阅读器读 PDF,PotPlayer 看音视频, Edge 浏览器看网页资料, Obsidian 软件上做各种内容摘录或重点复习笔记.
步骤 3. 划出重点及添加复习
使用 PDF 阅读器备注 / 高亮提取重点, PotPlayer 书签提取重点视频, Edge 浏览器上的标注插件标注网页重点内容, Obsidian 作笔记. 对标出内容按需通过索引或者制卡的形式添加SuperMemo.
二 学习流程的整体闭环
上面的步骤 1 至步骤 3 的流程完成了在SuperMemo 中索引内容从学习至复习的整体闭环, 但未在 SuperMemo 中索引内容则默认被排除在外了, 所以在步骤 1 - 步骤 3 的基础上, 我们使用 Obsidian 来进一步闭环. 通过 Obsidian 建立已有知识节点与新知识节点的关系. 通过扩展已有节点的内容, 关联孤立的内容, 或添加新的节点内容. 即通过不停的织网来扩充新的学习材料, 并建立新学习索引.最终整体流程就成了:
步骤 1-> 步骤 2-> 步骤 3->[挖掘 Obsidian 图谱中已有或新增节点关联 -> 重点或新索引]-> 步骤 1
Obsidian 挖掘新知识点并在 SM 中索引
三 番茄钟进行时间管理
使用小蕃茄软件及ManicTime 软件进行时间跟踪及蕃茄钟管理. 软件的使用及安装在专栏文章中可以参考, 因此这里不再详细说明.

ManicTime 时间跟踪管理
小蕃茄时间管理应用
四 补充相关的操作脚本
1. 生成学习索引并导入 SM 软件
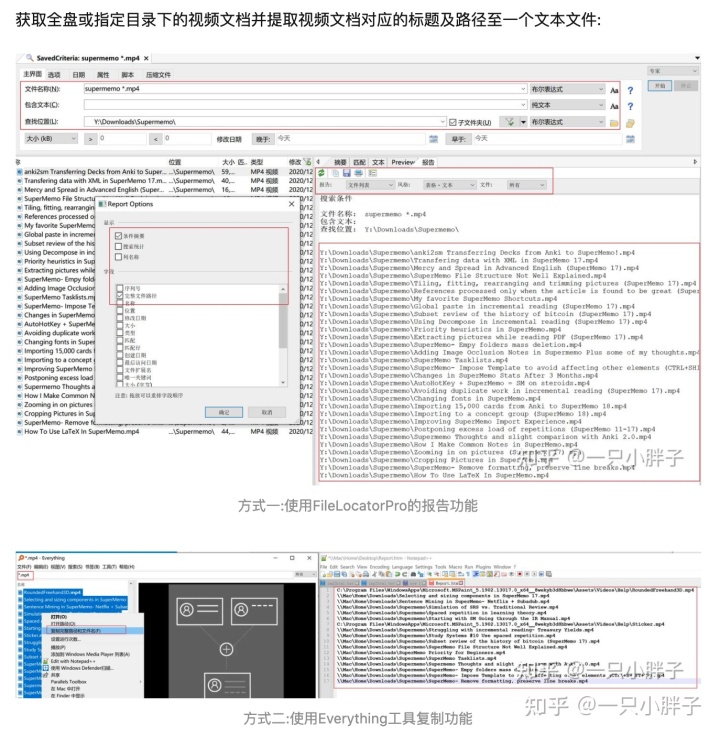
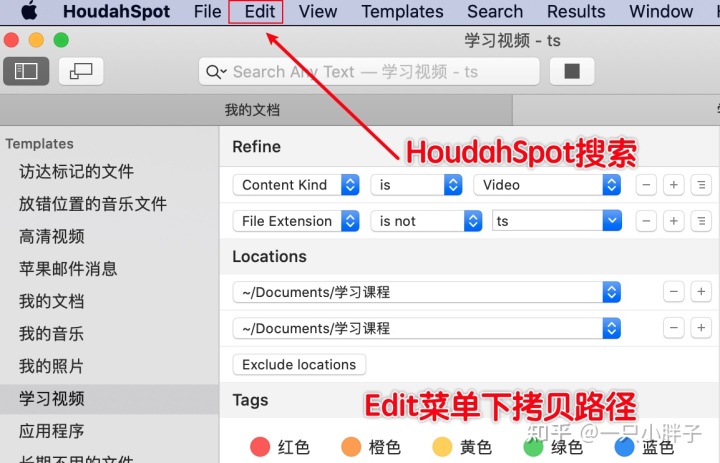
在 Windows 或 MacOS 系统上通过如上的工具或者其它你方便的方式来生成下面的待处理文件:
pdf-files.txt
/Users/Likey/Documents/电子书籍/公众号(码农沉思录)_1.pdf/Users/Likey/Documents/电子书籍/公众号(码农沉思录)_2.pdf/Users/Likey/Documents/电子书籍/公众号(码农沉思录)_3.pdf/Users/Likey/Documents/电子书籍/公众号(石杉的架构笔记)_1.pdf/Users/Likey/Documents/电子书籍/公众号(石杉的架构笔记)_2.pdf
md-files.txt
/Users/Likey/Documents/ObsidianDoc/000-MOC-内容地图索引/1-project.md/Users/Likey/Documents/ObsidianDoc/000-MOC-内容地图索引/2-areas.md/Users/Likey/Documents/ObsidianDoc/000-MOC-内容地图索引/3-resources.md/Users/Likey/Documents/ObsidianDoc/000-MOC-内容地图索引/4-archives.md/Users/Likey/Documents/ObsidianDoc/000-MOC-内容地图索引/5-helps.md
mv-files.txt
/Users/Likey/Documents/学习课程/亿级流量电商详情页系统实战(第二版):缓存架构+高可用服务架构+微服务架构/用所选项目新建的文件夹/181_商品详情页动态渲染系统:在CentOS 6安装和部署Docker/视频/课程视频.avi/Users/Likey/Documents/学习课程/亿级流量电商详情页系统实战(第二版):缓存架构+高可用服务架构+微服务架构/用所选项目新建的文件夹/182_商品详情页动态渲染系统:在CentOS 6安装maven、git以及推送github/视频/课程视频.avi
git-files.txt
https://www.runoob.com/python/python-files-io.htmlhttps://www.runoob.com/sitemap
提取 PDF 章节信息 - 生成网页
#!/usr/bin/python3# 提取PDF章节信息import fitz # = PyMuPDFwith open("../pdf/list/pdf-files.txt") as f1:pdfShortNameArr = [] # duplicate removefor pdfLongName in f1.readlines():pdfLongName = pdfLongName.rstrip("\n") # strip()if pdfLongName.endswith("pdf"):try:pdfNameList = pdfLongName.split("/")pdfShortName = pdfNameList[len(pdfNameList) - 1]if pdfShortName in pdfShortNameArr:print(pdfShortName + " is exits, so skip !")continueif pdfShortName.find("-") > -1:print(pdfShortName + " contains '-' , so skip !")continuepdfShortNameArr.append(pdfShortName)doc = fitz.open(pdfLongName) # open PDFtoc = doc.getToC() # get current table of contentsif len(toc) == 0:print(pdfLongName + "\t未获取到TOC")continueelse:print(pdfLongName)outHtmlName = "../pdf/" + pdfShortName.removesuffix(".pdf") + "-outline.html"with open(outHtmlName, mode="w", encoding="utf-8") as f:chapterInfoCnt = "<html>\r\n<head>\r\n<meta http-equiv=\"Content-Type\" content=\"text/html; " \"charset=UTF-8\"/>\r\n</head>\r\n<body>"for t in toc:t[2] = pdfShortName + "-" + str(t[2]) # show what we have so far# print(t[2])if str(t[2]).endswith("--1"):continuechapterInfo = "{}{}-{}{}".format("\r\n<p>", str(t[1]).strip("\n"), str(t[2]).strip("\n"), "</p>")chapterInfoCnt += chapterInfochapterInfoCnt += "\r\n</body>\r\n</html>"f.write(chapterInfoCnt)except RuntimeError:print("RuntimeError...")
提取 Obsidian URI 信息 - 生成网页
#!/usr/bin/python3# 提取 Obsidian URI 信息from urllib.parse import quote, unquotewith open("../md/list/md-files.txt") as f1:mdShortNameArr = [] # duplicate removechapterInfoCnt = "<html>\r\n<head>\r\n<meta http-equiv=\"Content-Type\" content=\"text/html; " \"charset=UTF-8\"/>\r\n</head>\r\n<body>"for mdLongName in f1.readlines():mdLongName = mdLongName.rstrip("\n") # strip()if mdLongName.endswith("md"):try:mdNameList = mdLongName.split("/")mdShortName = mdNameList[len(mdNameList) - 1]if mdShortName in mdShortNameArr:print(mdShortName + " is exits, so skip !")continue# if mdShortName.find("-") > -1:# print(mdShortName + " contains '-' , so skip !")# continuemdShortNameArr.append(mdShortName)mdLongName = mdLongName.replace("/Users/Likey/Documents/ObsidianDoc/", "")prefixStr = "obsidian://open?vault=ObsidianDoc&file="obsidianURL = prefixStr + quote(mdLongName, 'utf-8')chapterInfo = "{}{}::{}{}".format("\r\n<p>", mdShortName, obsidianURL, "</p>")chapterInfoCnt += chapterInfoexcept RuntimeError:print("RuntimeError...")chapterInfoCnt += "\r\n</body>\r\n</html>"outHtmlName = "../md/mdList-outline.html"with open(outHtmlName, mode="w", encoding="utf-8") as f:f.write(chapterInfoCnt)
提取 Video URI 信息 - 生成网页
#!/usr/bin/python3# 提取 Video URI 信息with open("../mv/list/mv-files.txt") as f1:mvShortNameArr = [] # duplicate removechapterInfoCnt = "<html>\r\n<head>\r\n<meta http-equiv=\"Content-Type\" content=\"text/html; " \"charset=UTF-8\"/>\r\n</head>\r\n<body>"for mvLongName in f1.readlines():mvLongName = mvLongName.rstrip("\n") # strip()mvSuffix = mvLongName.rsplit(".")[-1]if mvSuffix in ["mp4", "avi", "mpg", "mkv", "mp3"]:try:# mvNameList = mvLongName.split("/")# mvShortName = mvNameList[len(mvNameList) - 1]# if mvShortName in mvShortNameArr:# print(mvShortName + " is exits, so skip !")# continue# if mvShortName.find("-") > -1:# print(mvShortName + " contains '-' , so skip !")# continue# mvShortNameArr.append(mvShortName)chapterInfo = "{}{}{}".format("\r\n<p>", mvLongName, "</p>")chapterInfoCnt += chapterInfoexcept RuntimeError:print("RuntimeError...")chapterInfoCnt += "\r\n</body>\r\n</html>"outHtmlName = "../mv/mvList-outline.html"with open(outHtmlName, mode="w", encoding="utf-8") as f:f.write(chapterInfoCnt)
提取 GitBook URI 信息 - 生成网页
#!/usr/bin/env python3# -*- coding:utf-8 -*-# from calibre.web.feeds.recipes import BasicNewsRecipe # 引入 Recipe 基础类from bs4 import BeautifulSoupimport requestsimport refrom concurrent.futures import ThreadPoolExecutor, as_completed, wait, FIRST_COMPLETEDfrom concurrent.futures import Futurefrom multiprocessing import Pool# 写入有效的网址链接def write_html(article_obj):chapterInfoCnt = "<html>\r\n<head>\r\n<meta http-equiv=\"Content-Type\" content=\"text/html; " \"charset=UTF-8\"/>\r\n</head>\r\n<body>"article_Title = "".join(re.findall("[^\x00-\xff]|[A-Za-z0-9_]", article_obj['title']))# print(article_obj['title'])print(article_Title)href_obj_array = article_obj['href_obj_array']for href_obj in href_obj_array:linkHrefStr = str(href_obj.get('href'))try:# respCode = requests.get(linkHrefStr).status_codeif linkHrefStr.startswith("http"):chapterInfo = "{}{}{}".format("\r\n<p>", href_obj, "</p>")chapterInfoCnt += chapterInfoexcept RuntimeError:print("RuntimeError...")chapterInfoCnt += "\r\n</body>\r\n</html>"outHtmlName = "../git/gitBooks-" + article_Title + "-outline.html"with open(outHtmlName, mode="w", encoding="utf-8") as f:f.write(chapterInfoCnt)# 获取所有的子链接def get_links(url_site):href_obj_array = [] # 定义链接内容数组siteUrls = re.findall(r"(?i)(^https?://(?:\w+\.)*?\w*\.(?:com|club\.cn|com|net|me|xyz|info|org)[\/]*)", url_site)if siteUrls:siteDomain = siteUrls[0]# 解析列表页返回 BeautifulSoup 对象 #.txt .content .urlsoup = BeautifulSoup(requests.get(url_site).content, 'html.parser', from_encoding="utf-8")links = soup.findAll("a")# links = soup.findAll("li",{"class":"list-group-item title"}) # 获取所有文章链接# siteUrls = re.findall(r"(?i)((^https?://(?:\w+\.)*?)(\w*\.(?:com|club\.cn|com|net|me|xyz|info))[\/]*)", site)title = soup.find("title").get_text()for link in links: # 循环处理所有文章链接if link.string:hrefText = str(link.get_text()).strip("\n").strip("\t").lstrip(" ").rstrip(" ")link.string.replace_with(hrefText)link.string = hrefTexthrefLink = str(link.get('href'))sliceReverseIdx = 1 # 值为0或1时正向截取,大于1时则反向截取siteDomain = siteDomain.replace(".com/", ".com")# in current siteif hrefLink.startswith("../"):if hrefLink.count("/") > 1:sliceReverseIdx = - hrefLink.count("/")siteContent = url_site.removeprefix(siteDomain)middlePathArr = siteContent.split("/")[slice(sliceReverseIdx)]# remove null objmiddlePathArr = [arrStr for arrStr in middlePathArr if arrStr != '']siteMiddlePath = "/" + "/".join(middlePathArr) + "/"hrefLink_ = siteDomain + siteMiddlePath + hrefLink.replace("../", "")link['href'] = hrefLink_elif hrefLink.startswith("/"):hrefLink_ = siteDomain + hrefLinklink['href'] = hrefLink_# link to another site# else:# # print(link)# 1 == 1# return href 's text and urlhref_obj_array.append(link)# 多线程测试链接并写网页# thread.start_new_thread(write_html(article_links))# task2 = executor.submit(write_html, article_links)# wait([task2], return_when=FIRST_COMPLETED) # as_completedwrite_html({'title': title, 'href_obj_array': href_obj_array})# 抓取页面内容设置def read_Files():with open("../git/list/git-files.txt") as f1:siteArr = [] # duplicate removeexecutor = ThreadPoolExecutor(max_workers=3)for site in f1.readlines():try:site = site.rstrip("\n") # strip()if site in siteArr:print(site + " is exits, so skip !")continuesiteArr.append(site)# 获取链接地址get_links(site)except RuntimeError:print("RuntimeError...")# 获取各个网址的链接# thread.start_new_thread(get_links(site))# all_task = [executor.submit(get_links, url) for url in siteArr]# wait(all_task, return_when=FIRST_COMPLETED)if __name__ == '__main__':# print(__doc__)read_Files()
以上生成的网页索引文件使用 IE 打开, 导入 SuperMemo 后, 可按具体情况进行 Split Article 处理.
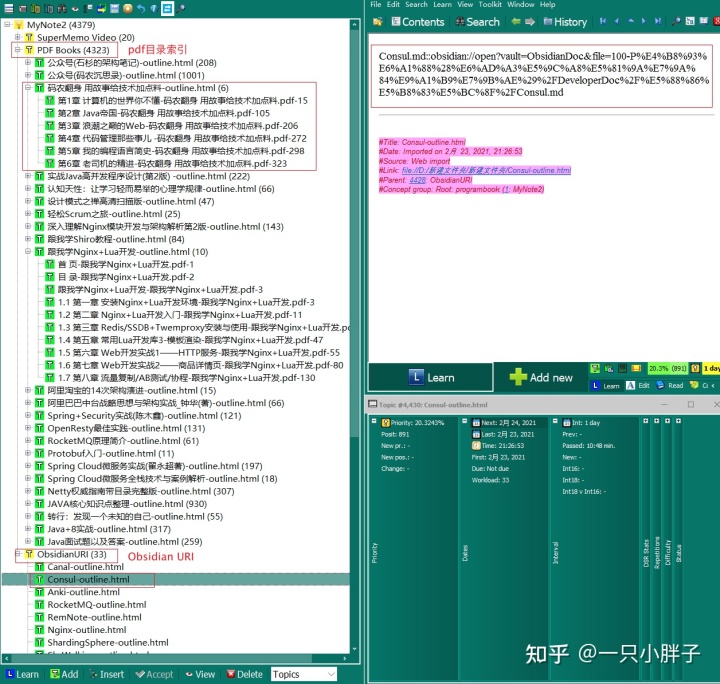
PDF 文件及 Obsidian 笔记导入
另外, 我们浏览器所有的收藏网址也可以批量导出后放入 SuperMemo 软件中增量, 如下图所示:
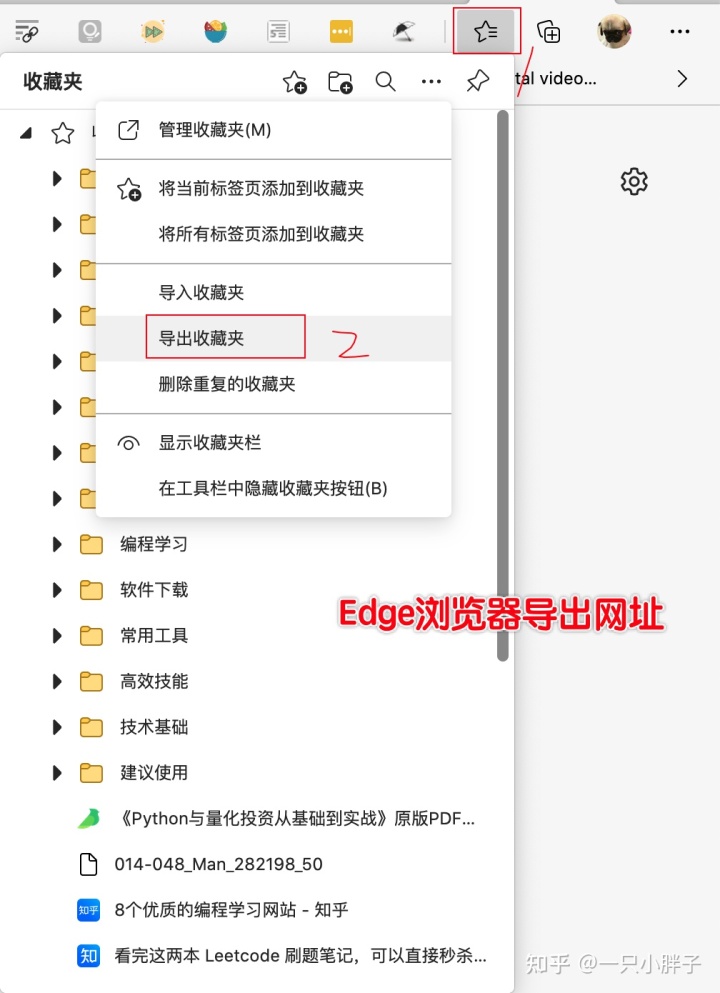
导出生成一个 favorites_2021_2_24.html
IE 浏览器打开导出的网页并按常规流程导入 SuperMemo 中, 接下来按标签 Split 分割成多个条目.
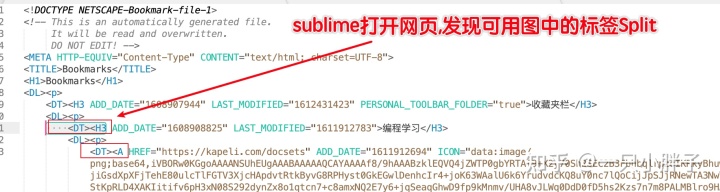
IE 打开导出网页再导入 SM 并按标签 Split
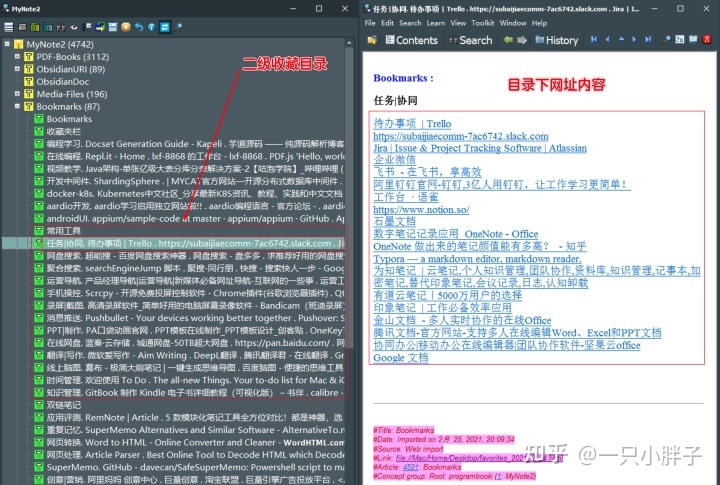
收藏夹的网址在 SM 中分割后的效果
2. 使用 Keyboard Maestro 脚本学习 SM 中的材料
如下为 SuperMemo 跳转至外部软件进行材料学习的相关脚本, 因为我使用的系统为 MacOS, 所以用的是 Keyboard Maestro 软件来实现的, Win 系统你可以自己用 AHK 或者 Quicker 脚本来实现.
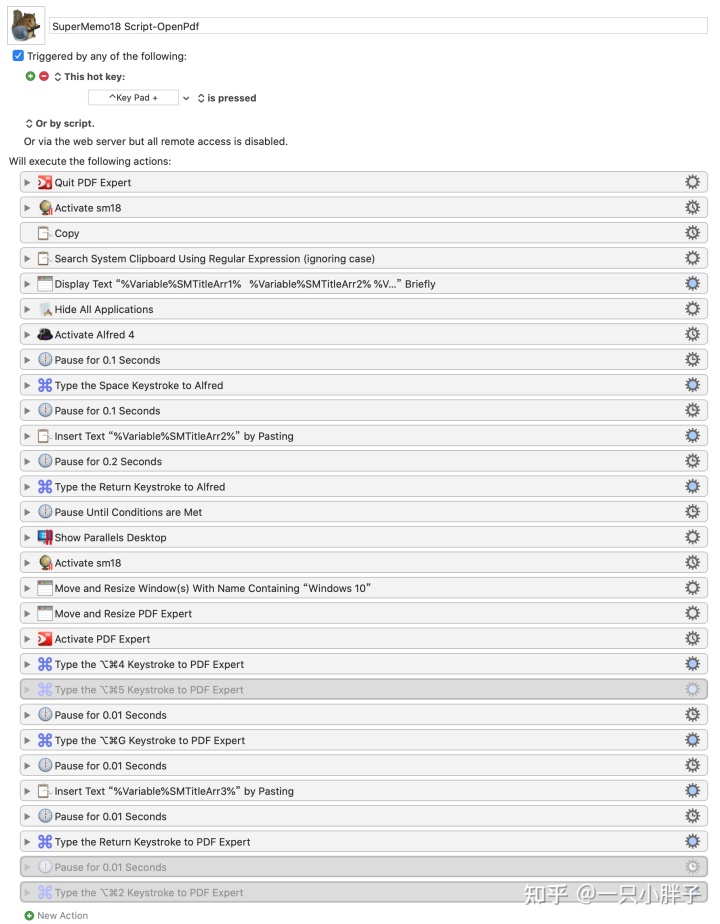
SM 软件跳转至 PDF 阅读器
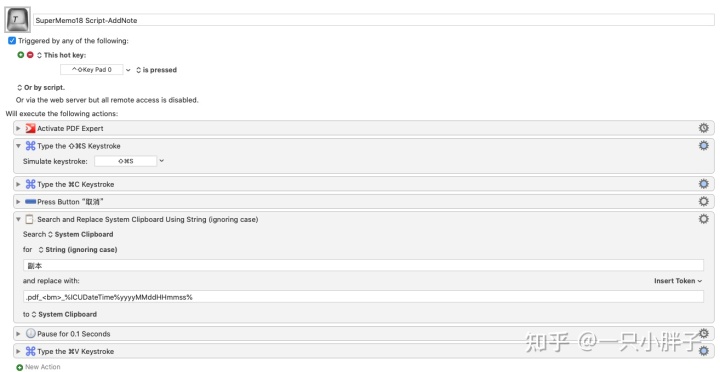
PDF 阅读器中添加时间戳
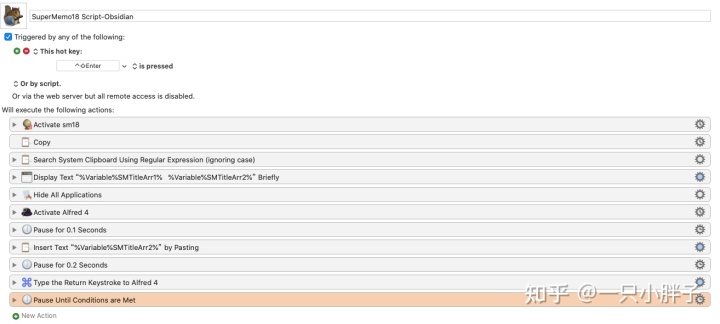
SM 软件跳至 Obsidian 笔记
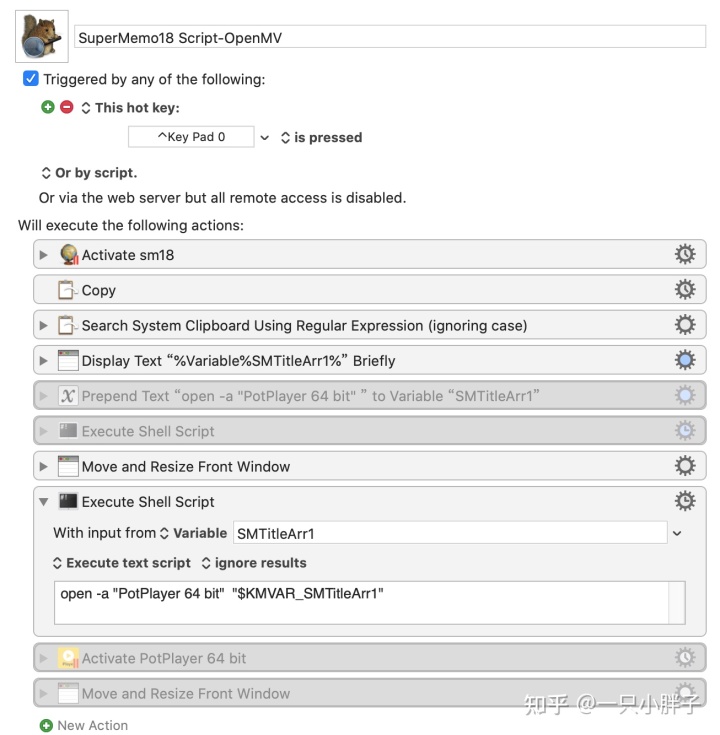
SM 软件跳至 PotPlayer 软件
网页链接类内容可直接复用 Obsidian 的脚本, 或者直接在 SuperMemo 软件内部打开就可以的.
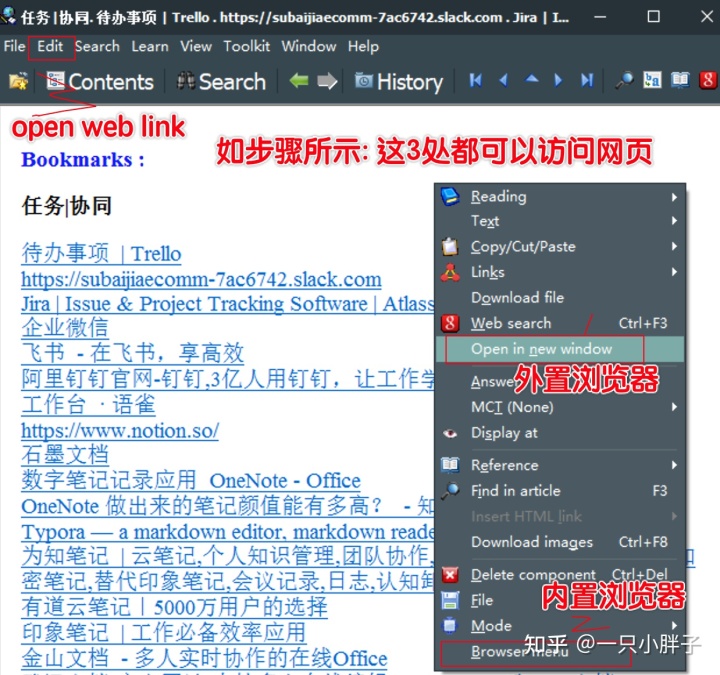
收藏夹的网址直接在 SM 中打开也行
结尾:
脚本内容我放置在网盘了, 我会尽量保持更新,你可以在本文评论区发现链接。 如脚本内容与文中有些许差异,一般不会影响运行,当然你也可稍微自行调整来适应自己个性化的需求。
我是一只热爱学习的小胖子, 如果你也热爱学习, 并且对 SuperMemo 感兴趣, 欢迎转发和评论!

若有收获,就点个赞吧
0 人点赞
