| 模型 | 原理 | 作用 | ||
|---|---|---|---|---|
| 线性回归 | 建立自变量X和观测变量Y之间的映射关系,且二者关系可用线性关系表示称为线性回归分析假设函数为 ,损失函数为平方损失.利用梯度下降法最优化损失函数得到参数,得到的模型可以对新数据进行预测。 ,损失函数为平方损失.利用梯度下降法最优化损失函数得到参数,得到的模型可以对新数据进行预测。 |
解决的就是通过已知的数据得到未知的结果。例如:对房价的预测、判断信用评价、电影票房预估等。 | 思想简单,实现容易。建模迅速,对于小数据量、简单的关系很有效 线性回归模型十分容易理解,结果具有很好的可解释性,有利于决策分析。 |
对于非线性数据或者数据特征间具有相关性多项式回归难以建模.
难以很好地表达高度复杂的数据。 | |
| 逻辑回归 | | | | |
| | | | | |
监督学习
1.回归算法:
用来建立自变量X和观测变量Y之间的映射关系,如果观测变量是离散的,则称其为分类Classification;如果观测变量是连续的,则称其为回归Regression。
回归算法的目的
是寻找假设函数hypothesis来最好的拟合给定的数据集。常用的回归算法有:线性回归(Linear Regression)、逻辑回归(Logistic Regression)、多项式回归(Polynomial Regression)、岭回归(Ridge Regression)、LASSO回归(Least Absolute Shrinkage and Selection Operator)、弹性网络(Elastic Net estimators)、逐步回归(Stepwise Regression)等。
1.线性回归:LinearRegression 平方损失
单变量线性回归:只包括一个自变量和一个因变量,且二者关系可用一条直线近似表示,称为一元线性回归分析
多变量线性回归:回归分析中包括两个或两个以上的自变量,且因变量和自变量是线性关系,则称为多元线性回归分析。
原理:
线性回归模型试图学得一个线性模型以尽可能准确地预测实值X的输出标记Y。在这个模型中,因变量Y是连续的,自变量X可以是连续或离散的。
作用:
对大量的观测数据进行处理,从而得到比较符合事物内部规律的数学表达式。也就是说寻找到数据与数据之间的规律所在,从而就可以模拟出结果,也就是对结果进行预测。解决的就是通过已知的数据得到未知的结果。例如:对房价的预测、判断信用评价、电影票房预估等。
算法优缺点
优点:
(1)思想简单,实现容易。建模迅速,对于小数据量、简单的关系很有效;
(2)是许多强大的非线性模型的基础。
(3)线性回归模型十分容易理解,结果具有很好的可解释性,有利于决策分析。
(4)蕴含机器学习中的很多重要思想。
(5)能解决回归问题。
缺点:
(1)对于非线性数据或者数据特征间具有相关性多项式回归难以建模.
(2)难以很好地表达高度复杂的数据。
假设函数:
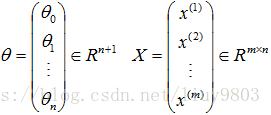
m:输入数据的条数;<br />n:每条数据的特征个数<br /> 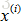:第i个样本,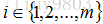<br /> 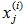:第i个样本的第j个特征
损失函数|目标函数:
最小二乘法
主要是通过最小化误差的平方以及最合适数据的匹配函数。
梯度下降更新参数θ(小批量):


过拟合:
在训练集上表现良好,但是遇到新数据 后就没有那么出色
出现过拟合的原因
1. 训练集的数量级和模型的复杂度不匹配。训练集的数量级要小于模型的复杂度;
2. 训练集和测试集特征分布不一致;
3. 样本里的噪音数据干扰过大,大到模型过分记住了噪音特征,反而忽略了真实的输入输出间的关系;
4. 权值学习迭代次数足够多(Overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征。
5.训练数据中存在噪音或者训练数据太少
解决方法:
1. simpler model structure
调小模型复杂度,使其适合自己训练集的数量级(缩小宽度和减小深度)
2. data augmentation
训练集越多,过拟合的概率越小。在计算机视觉领域中,增广的方式是对图像旋转,缩放,剪切,添加噪声等。
3. regularization
参数太多,会导致我们的模型复杂度上升,容易过拟合,也就是我们的训练误差会很小。 正则化是指通过引入额外新信息来解决机器学习中过拟合问题的一种方法。这种额外信息通常的形式是模型复杂性带来的惩罚度。 正则化可以保持模型简单,另外,规则项的使用还可以约束我们的模型的特性。
4,添加正则项。L1正则更加容易产生稀疏解、L2正则倾向于让参数w趋向于0.
正则惩罚:
1.减少特征(L1)
2.缩小权重(L2)
L1正则: 特征稀疏
L2正则:(岭回归)Ridge ,RidgeCV
应用场景:线性回归过拟合偏差大,当使用L2正则惩罚后可以使权重w接近于0,但不等于0,
逻辑回归(logisticRegression)
原理:
逻辑回归是在线性回归的基础上加了一个 Sigmoid 函数(非线形)映射,本质上来说,两者都属于广义线性模型,但他们两个要解决的问题不一样,逻辑回归解决的是分类问题,输出的是离散值,线性回归解决的是回归问题,输出的连续值。
也就是把Y的结果带入一个非线性变换的Sigmoid函数中,即可得到[0,1]之间取值范围的数S,S可以把它看成是一个概率值,如果我们设置概率阈值为0.5,那么S大于0.5可以看成是正样本,小于0.5看成是负样本,就可以进行分类了。
Sigmoid函数
逻辑回归假设函数:

| X | 特征向量 |
|---|---|
| θ | 参数 |
| g函数 | S形函数: g(z)=1/(1+e^-z) |
损失函数:负对数似然函数


5.逻辑回归有什么优点
- LR能以概率的形式输出结果,而非只是0,1判定。
- LR的可解释性强,可控度高(你要给老板讲的嘛…)。
- 训练快,feature engineering之后效果赞。
-
6. 逻辑回归有哪些应用
某搜索引擎厂的广告CTR预估基线版是LR。
- 某电商搜索排序/广告CTR预估基线版是LR。
- 某电商的购物搭配推荐用了大量LR。
- 某现在一天广告赚1000w+的新闻app排序基线是LR。
神经网络:

若有收获,就点个赞吧
0 人点赞
