

均方根误差越
from sklearn.metrics import mean_squared_errorfrom math import sqrtprint('alpha为{}时,模型的参数为{}'.format(lambd,ridge.coef_))# 均方根误差越小越好print('训练现:',np.sqrt(mean_squared_error(y_train_pred,y_train)))print('测试集现:',np.sqrt(mean_squared_error(y_test_pred,y_test)))# 评分越高越好print(ridge.score(x_test,y_test))
from sklearn.metrics import roc_auc_score,recall_score,precision_score,confusion_matrix,classification_report
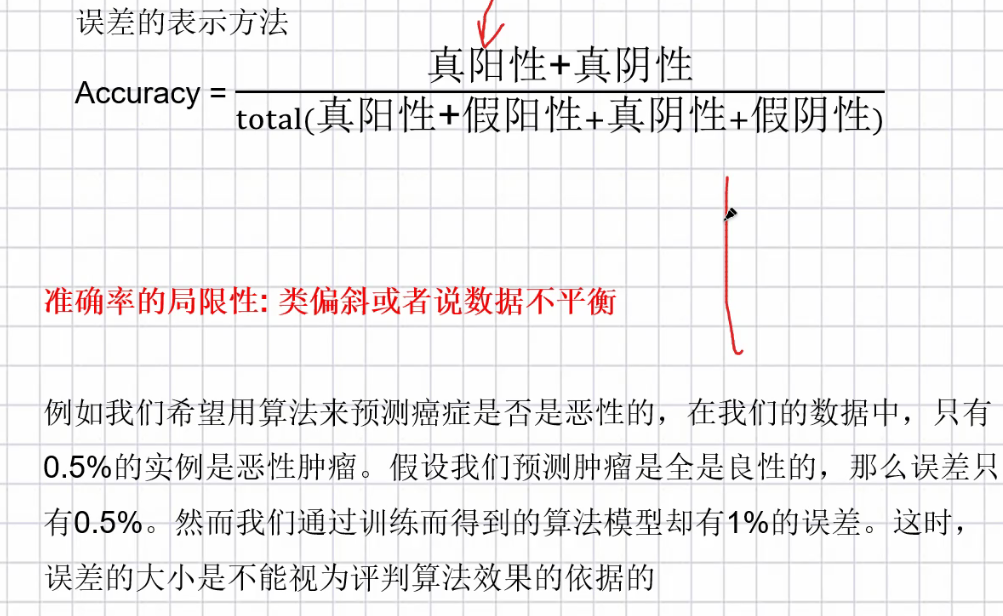<br />真:预测正确<br />假:预测失误<br />准确率的局限性:类偏斜或者数据不平衡(预测肿瘤良性)<br />结论:数据不平衡时,不能只看准确率<br />![G8DA%FX%T0R@5~%{)~P%]KM.png](/uploads/projects/u2282626@myv5i6/648b545fece8e1b19c768e79b6387689.png)
假阴,图片


![CS)Z7JDDA2(R]~E75)35GAR.png](/uploads/projects/u2282626@myv5i6/3088ae3c8469d6c3aaa4547dd6feed1b.png)

若有收获,就点个赞吧
0 人点赞
