
思想:根据特征来划分:
Decision Tree
大数据思维:利用更多的信息消除不确定性,避免做决策时没有依据,实质是提供有价值的信息降低信息熵
熵度量了事物的不确定性,越不确定的事物,它的熵就越大。具体的,随机变量X的熵的表达式如下: 
联合熵 
条件熵类似于条件概率,它度量了我们在知道Y以后X剩下的不确定性。表达式:**
信息增益:全部熵-条件熵
 度量了
度量了 的不确定性 .条件熵
的不确定性 .条件熵 度量了我们在知道
度量了我们在知道 以后
以后 剩下的不确定性,
剩下的不确定性, 呢?它度量了
呢?它度量了 在知道
在知道 以后不确定性减少程度,这个度量我们在信息论中称为互信息,记为
以后不确定性减少程度,这个度量我们在信息论中称为互信息,记为 。
。
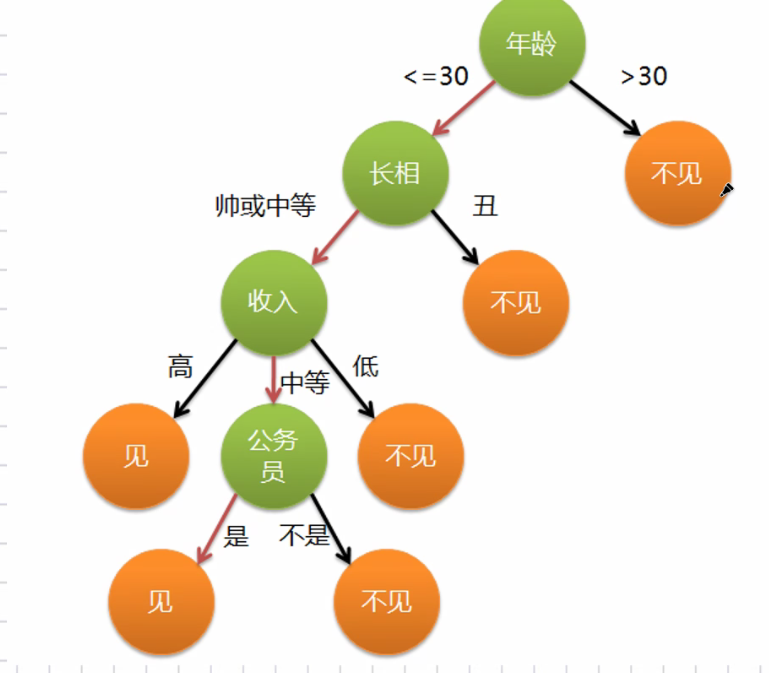
线性UI鬼,逻辑回归,神经网络是参数模型,
决策树是分类

信息增益:
表示由于得知特征A后的数据集D的分类不确定性减少的程度,定义为
Gain(D,A) = H(D) – H(D|A)
1.理解:
即集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(H|A)之差。
选择划分后信息增益大的作为划分特征,说明使用该特征后划分得到的子集纯度越高,即不确定性越小。因此我们总是选择当前使得信息增益最大的特征来划分数据集。
2.缺点:
信息增益偏向取值较多的特征(原因:当特征的取值较多时,根据此特征划分更容易得到纯度更高的子集,因此划分后的熵更低,即不确定性更低,因此信息增益更大)
决策树算法:
ID3算法:
Gain(D,A) = H(D) – H(D|A)

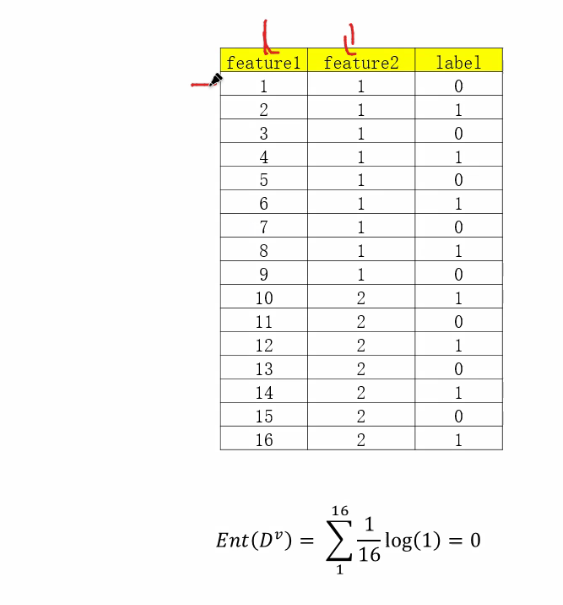
ID3案例:






ID3缺点:
ID3没有考虑连续特征,比如长度,密度都是连续值,无法在ID3运用,
ID3采用信息增益大的特征优先建立决策树的节点,在相同条件下,对取值比较多的 信息增益大,其实他们都是完全不确定的变量,但是取三个值的比取俩个值的信息增益大.
ID3算法对于缺失值的情况没有做考虑
没有考虑过拟合的情况
划分的特征分支越多,条件熵越小,信息增益越大,不适合多分类问题

C4.5算法:弥补ID3缺点
当一个特征分支较多时,以信息增益为准则划分 对 取值数目较多的属性有偏好,为了减少这种偏好的不利 ,采取增益率来选择
Iv(A) 分支数越多,LV(a)越大, 由因此把信息增益除以一个与特征分支数目相关的数减少这种不利影响.
公式:
实践中,先选取信息增益高于平均水平的属性,在从中选择增益率高的属性**
CART算法(分类和回归数)

基尼系数:CART分类树算法 基尼系数代替信息增益比,基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好.与信息增益比是相反的,解决了太多的对数运算.
分类问题: 假设有K个实例,第K个类别的概率是Pk,则基尼系数为:
二分类问题:
对于 给定的样本D,假设有V个类别,第V个类别的数量是Dv,则样本D的基尼系数为
对于样本D,如果根据特征A的某个值a,把D分为D1和D2部分, 则在特征A的条件下,D的基尼系数为:


决策树损失函数


CART树的正则化:
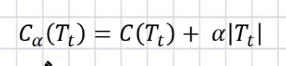
α越大,剪支 越厉害
C(Tt)是训练数据的预测误差,分类树是基尼系数度量
|Tt|是子树T的叶子节点的数量

案例: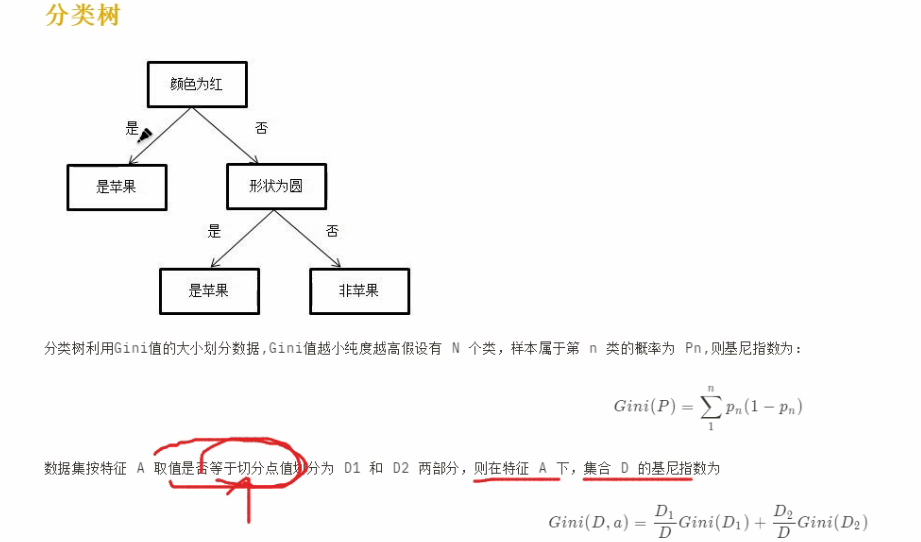






若有收获,就点个赞吧
0 人点赞
