交叉验证方法
- 留一法(leave one out):即每次保留一条数据最为测试集,其余最为训练集,并不断更换测试集数据,直到每条数据都没循环到。这种方法咋数据量大的时候需要大量时间。
- k折法(k-fold):将数据集分成k组,每组轮流作为测试集,其余的作为训练集,得到多个结果,取结果的平均值。
- bootstraping(自助采样法):可重复抽样m个样本组成新的训练集,原数据集中大概36.8%的样本不会出现。这样会使数据分布产生偏差,因此不是很常用。
- 留出法(hold out):直接按百分比将数据集分为三部分
这些方法的区别:
- 优点:每一回合几乎所有的样本都参与训练,因此这样得到的评估可靠。并且整个过程可以重复。
缺点:计算成本高,除非可以使用并行运算减少计算时间。 - k折法:
优点:每个数据即作为训练集也作为测试集,有效避免了过拟合和欠拟合
缺点:k值得选择需要人为设定。 - 留出法:
优点:处理比以上都简单
缺点:数据集分割后通常不再能够代表母体样本的分布,训练的模型有局限性。
RIdge:岭模型 l2正则化import pandas as pdimport numpy as npfrom math import sqrtimport matplotlib.pyplot as pltfrom sklearn.linear_model import Ridge,RidgeCV #选择alphafrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import mean_squared_error
导入均方根误差包:from sklearn.metrics import mean_squared_error
# 构造不同的lambda值 :lambdas=np.logspace(-4,0,5)
# 构造空列表,存储权重:ridge_theta=[]
Rdgecv,不需要循环找合适的参数,直接直接寻找最好的alpha:from sklearn.metrics import mean_squared_error# from sklearn import metrics# from math import sqrt# 构造不同的lambda值 np.logspace(-1,2,7)lambdas=np.logspace(-4,0,5)print(lambdas)# 构造空列表,存储权重ridge_theta=[]# 循环迭代不同的lambda值for lambd in lambdas:ridge=Ridge(alpha=la`mbd,normalize=True)# alpha越大,正则化力度越大,θ越小ridge.fit(x_train,y_train)y_test_pred=ridge.predict(x_test)y_train_pred=ridge.predict(x_train)# coef_斜率ridge_theta.append(ridge.coef_)print('alpha为{}时,模型的参数为{}'.format(lambd,ridge.coef_))# 均方根误差越小越好print('训练集表现:',np.sqrt(mean_squared_error(y_train_pred,y_train)))print('测试集表现:',np.sqrt(mean_squared_error(y_test_pred,y_test)))# 评分越高越好print(ridge.score(x_test,y_test))
ridgeCV自动选择好的模型参数scoring=’neg_mean_squared_error’评分方法
交叉验证# 林回归模型的交叉验证# 设置交叉验证的参数,对于每一个的lambda值,都执行10折交叉验证ridge_cv=RidgeCV(alphas=lambdas,normalize=True,scoring='neg_mean_squared_error',cv=10)# 模型拟合:ridge_cv.fit(x_train,y_train)# 返回最佳的lambda值 alpha_正则化项系数ridge_best_lambda=ridge_cv.alpha_ridge_best_lambda
lasso L1正则化
from sklearn.linear_model import Lasso,LassoCVlasso_cofficients=[]for lambd in lambdas:# max_iter=10000迭代次数坐标上升lasso=Lasso(alpha=lambd, normalize=True, max_iter=10000)lasso.fit(x_train,y_train)lasso_cofficients.append(lasso.coef_)# y_train_prdict=lasso.predicts(x_train)y_test_prdict=lasso.predict(x_test)lasso_cofficients.append(lasso.coef_)print('Rmse',np.sqrt(mean_squared_error(y_test_prdict,y_test)))print('score:',lasso.score(x_test,y_test))

lassonCV
直接选定0.1# 林回归模型的交叉验证,先切分2/8,在把8份做10折模型,一份做验证集,剩下的九份做训练集,做十次,每条数据都做验证# 设置交叉验证的参数,对于每一个的lambda值,都执行10折交叉验证Lasso_cv=LassoCV(alphas=lambdas,normalize=True,cv=10)# 模型拟合:Lasso_cv.fit(x_train,y_train)# 返回最佳的lambda值 alpha_正则化项系数Lasso_best_lambda=ridge_cv.alpha_Lasso_best_lambda
学习曲线-多项式回归
存储图片函数:root='.'model_id='all_images'def save_fig(name):path=os.path.join(root,'image',model_id)if not os.path.exists(path):os.makedirs(path)#目录# 创建文件.pngpath=os.path.join(path,name)print("Saving figure",name)plt.savefig(path,format="png",dpi=300)
多项式:
np.random.seed(42)m = 100# 创建数据集的特征部分X = 6 * np.random.rand(m, 1) - 3y = X**2 + 2*X +3 + np.random.randn(m, 1) #创建数据集的标签部分多项式
- 导包
- degree include-BINS
- 拟合并转化数据 二次项
- 线性回归对象
- lr.fit(x,y)
- lr.coef_
- x_new=linspace()
- 多项式转化:pf.transform(x_new)
- y_predict=lr.predict(x_new)
- plt.plot(x-new,y_predict)
初始化多项式特征对象,转化原始特征为多项式:from sklearn.preprocessing import PolynomialFeatures#从预处理包中导入多项式处理模块from sklearn.linear_model import LinearRegression# 从线性模型里导入线性分类器
画图,拟合多项式数据:# interaction_only 参数为交互poly_features=PolynomialFeatures(degree=2,include_bias=False)#初始化多项式特征对象X_poly=poly_features.fit_transform(X)#转化原始特征为多项式特征poly_features
X_new=np.linspace(-3,3,100).reshape(100,1)X_new_poly=poly_features.fit_transform(X_new)y_predict=lr.predict(X_new_poly)plt.plot(X,y,'b.')plt.plot(X_new,y_predict,'r-',label='predicts')

流水线:
from sklearn.preprocessing import StandardScaler,MinMaxScaler
from sklearn.pipeline import Pipeline #流水线 ```sql from sklearn.preprocessing import StandardScaler,MinMaxScaler from sklearn.pipeline import Pipeline #流水线
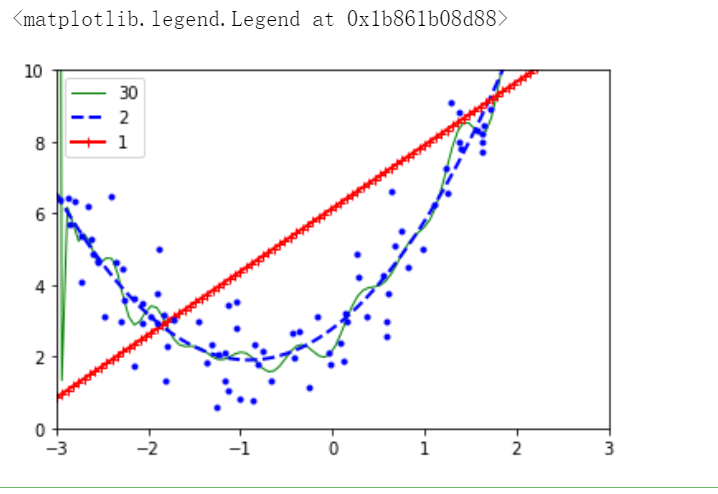
for style,width,degree in[(‘g-‘,1,30),(‘b—‘,2,2),(‘r-+’,2,1)]: polybig_features=PolynomialFeatures(degree=degree,include_bias=False) std_scaler=StandardScaler() lr=LinearRegression() min_max=MinMaxScaler() pipe=Pipeline([(‘poly_features’,polybig_features), (‘std_scaler’,std_scaler), (‘lr’,lr)]) pipe.fit(X,y)
yp=pipe.predict(X_new)plt.plot(X_new,yp,style,label=str(degree),linewidth=width)
plt.plot(X,y,’b.’,linewidth=3) plt.axis([-3,3,0,10]) plt.legend(loc=’upper left’)
<br />学习曲线:```sqldef plot_learn_curves(model,X,y):# 切分数plot_learn_curves据集,训练集,验证集,指定随机种子X_train,X_val,y_train,y_val = train_test_split(X,y,test_size=0.2,random_state=10)# 收集训练误差train_errors = []# 收集验证误差val_errors = []# 遍历训练集数据for m in range(1,len(X_train)):# 拟合数据model.fit(X_train[:m],y_train[:m])# 预测训练集的值y_train_predict = model.predict(X_train[:m])# 预测验证集的值y_val_predict = model.predict(X_val)# 计算真实值和训练集预测值之间的均方误差并收集train_errors.append(mean_squared_error(y_train[:m],y_train_predict))# 计算真实值和验证集预测值之间的均方误差并收集val_errors.append(mean_squared_error(y_val,y_val_predict))plt.plot(np.sqrt(train_errors),'r-+',linewidth=2,label='train')plt.plot(np.sqrt(val_errors),'b-',linewidth=2,label='val')plt.legend(loc='upper right',fontsize=14)plt.xlabel('Train set size',fontsize=14)plt.ylabel('RMSE',fontsize=14)
lin_reg = LinearRegression() #初始化线性回归器model_line(lin_reg, X, y) #调用函数plt.axis([0, 80, 0, 10])# save_fig("study_plot")# plt.show()

流水线多数据学习曲线:
def plot_learn_three(model,X,y,style):X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=10)train_errors = []test_errors = []for m in range(1,len(X_train)):model.fit(X_train[:m],y_train[:m])pre_train = model.predict(X_train[:m])train_error = np.sqrt(mean_squared_error(y_train[:m],pre_train))pre_test = model.predict(X_test)test_error = np.sqrt(mean_squared_error(y_test,pre_test))train_errors.append(train_error)test_errors.append(test_error)plt.plot(train_errors,style,label=degree)plt.plot(test_errors,style)plt.legend()
for style,degree,width in [('b-',20,1),('r--',1,2),('g-+',2,2)]:std = StandardScaler()poly_features = PolynomialFeatures(degree=degree,include_bias=False)lr = LinearRegression()poly_regression = Pipeline([('std_scaler',std),('poly_features',poly_features),('lin_reg',lr)])poly_regression.fit(X,y)plot_learn_three(poly_regression,X,y,style)plt.axis([0,80,0,5])


若有收获,就点个赞吧
0 人点赞
