三 Key-Value
聚合操作
18.reduceByKey()
函数签名 def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] // V:代表的是value的类型,已经定死 � 作用 相同的Key的数据进行value数据的聚合操作 聚合操作都是两两聚合
⚠️注意 如果key的数据只有一个,是不会参与运算的
例子
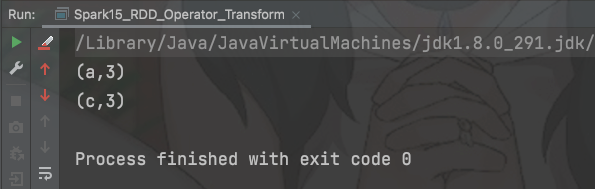
val sc = new SparkContext(conf)val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("c", 3)))val reduceRDD: RDD[(String, Int)] = rdd.reduceByKey((a, b) => a + b)reduceRDD.collect().foreach(println)
19.groupByKey()
函数签名 def groupByKey( ) : RDD[ (K, V) ] � 作用 相同的Key的数据进行分组
例子
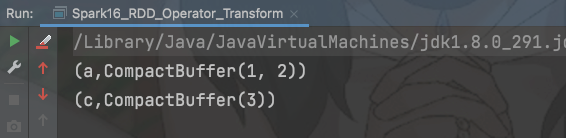
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("c",4)))val value: RDD[(String, Iterable[Int])] = rdd.groupByKey()value.collect().foreach(println)
🤔 思考:groupByKey() 和 reduceByKey() 的区别?
groupByKey( )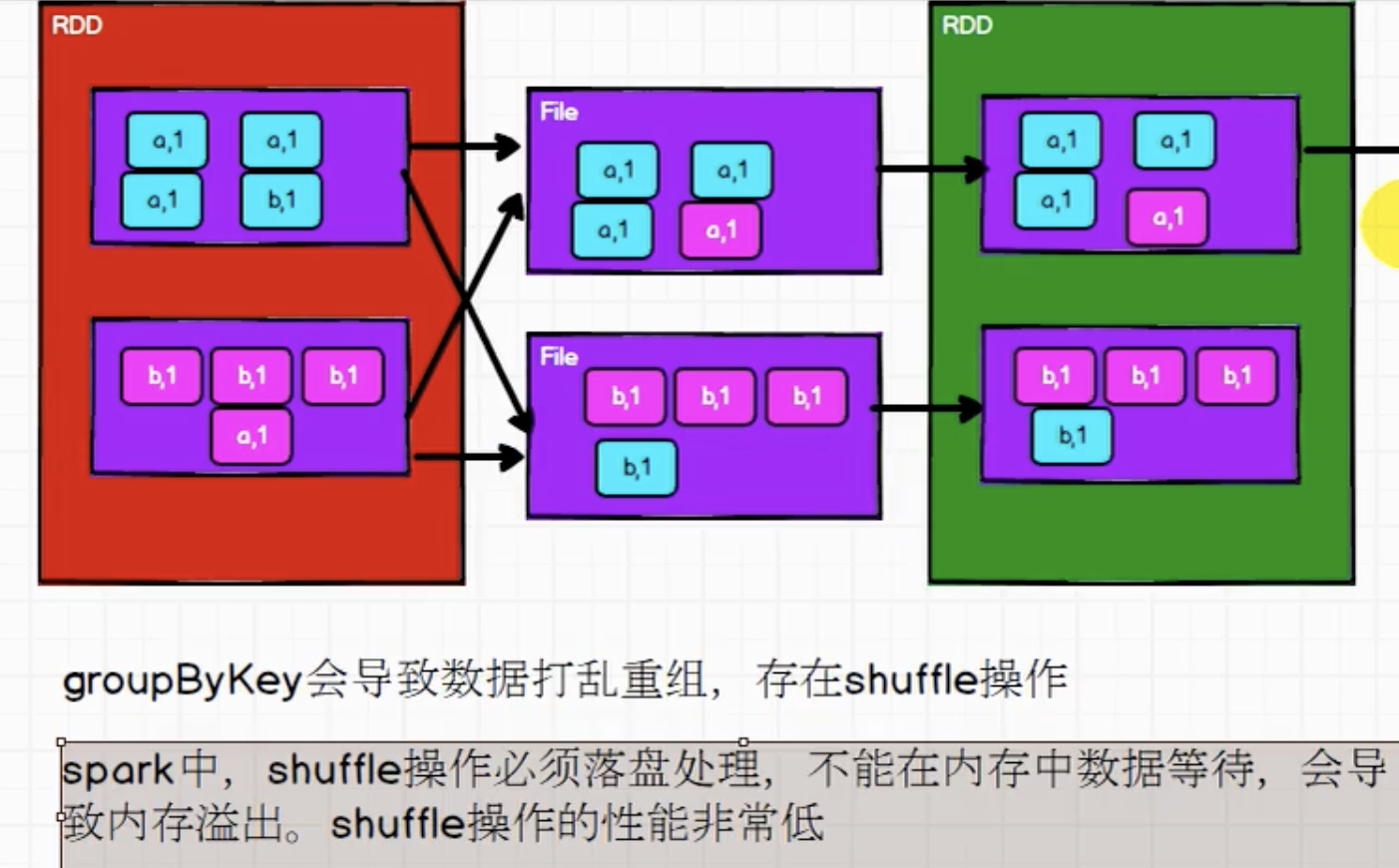
reduceByKey( )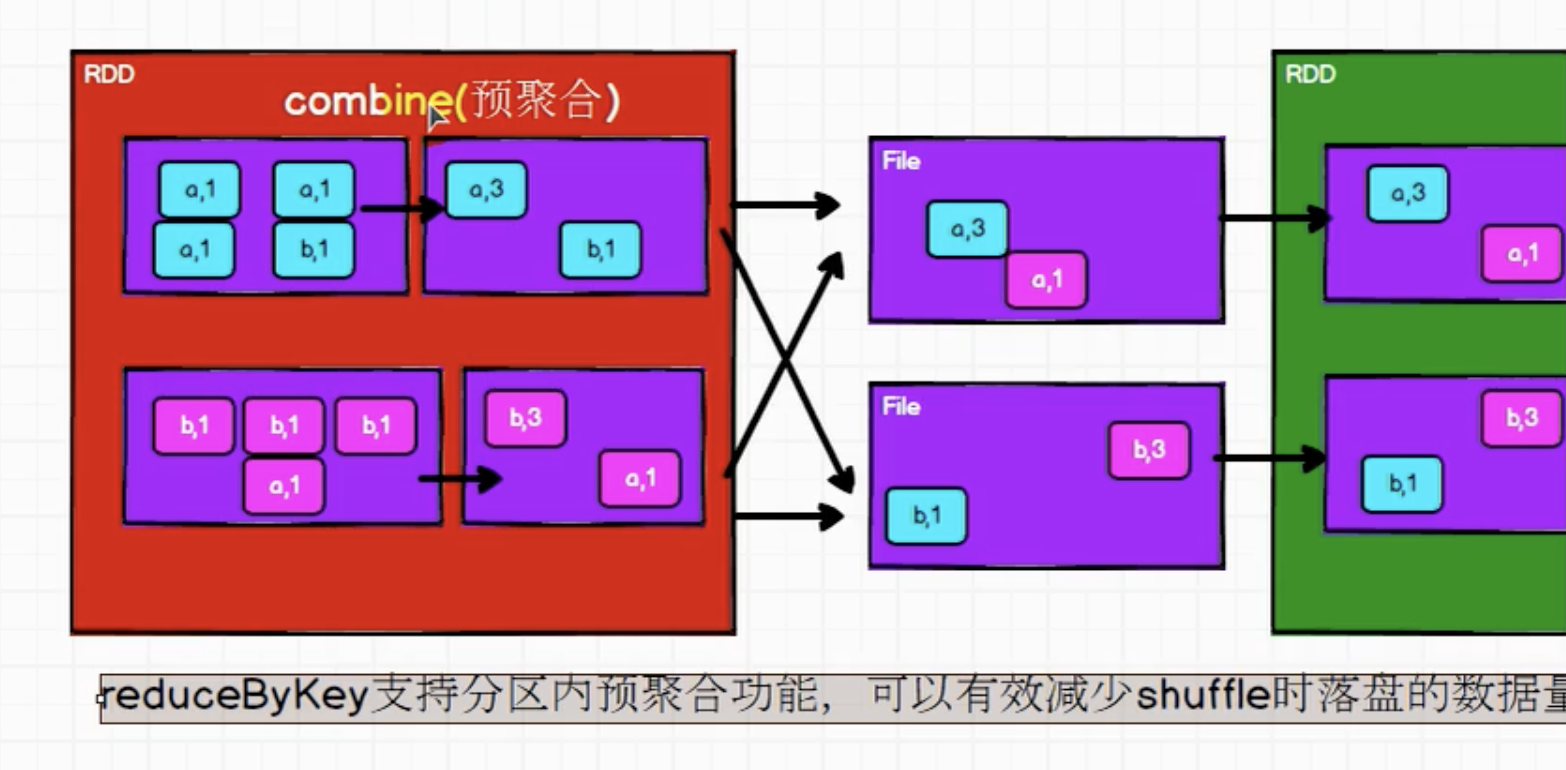
总结
20. aggregateByKey( )
函数签名 def aggregateByKey[U: ClassTag] ( zeroValue: U , partitioner: Partitioner ) ( seqOp: (U, V) => U, //分区内
combOp: (U, U) => U) : RDD[(K, U)] // 分区间 � 作用 分区内 相同的Key一个操作 分区间 相同的Key另一个操作⚠️注意 看数据如何分区,决定最后的结果
例子: 选出分区间最大的 K-V ,随后做出聚合
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("c",4), ("c",4), ("b",4), ("q",4), ("q",4), ("e",4), ("r",4), ("t",4), ("t",4), ("y",4), ("y",4), ("u",4), ("u",4)))val aggregateRDD: RDD[(String, Int)] = rdd.aggregateByKey(0)((a, b) => math.max(a, b),(a, b) => a + b)aggregateRDD.collect().foreach(println)

例子:计算出出现次数的平均值
val aggRDD: RDD[(String, (Int, Int))] = rdd.aggregateByKey((0, 0))((tup, item) => (tup._1 + item, tup._2 + 1),(a, b) => (a._1 + b._1, a._2 + b._2))val resRDD: RDD[(String, Int)] = aggRDD.mapValues(item => (item._1 / item._2))

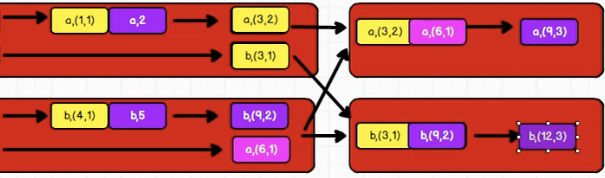
21. flodByKey()
函数签名 def foldByKey(
zeroValue: V,
partitioner: Partitioner) (func: (V, V) => V): RDD[(K, V)] � � 作用 分区内 和 分区间 计算相同
22.combineByKey()
函数签名 def combineByKeyC => C, // 分区内的计算
mergeCombiners: (C, C) => C, // 分区间的计算
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null): RDD[(K, C)] � � 作用
val comRDD: RDD[(String, (Int, Int))] = rdd.combineByKey(v=>(v, 1), //能够将value的结构进行转换(vs: (Int, Int), v) => (vs._1 + v, vs._2 + 1),(vs1: (Int, Int), vs2: (Int, Int)) => (vs1._1 + vs2._1, vs2._2 + vs2._2))val resRDD: RDD[(String, Int)] = comRDD.mapValues(item => item._1 / item._2)resRDD.collect().foreach(println)
连接操作
15. zip()
函数签名 def zipU: ClassTag : RDD[(T, U)]
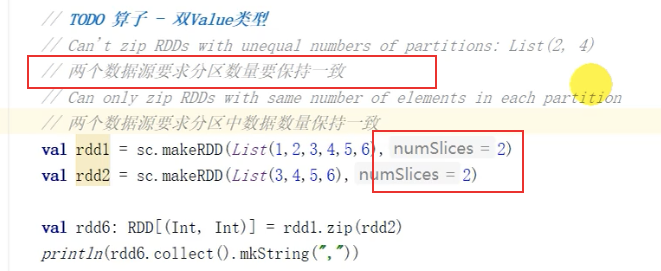
object Test {def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder.appName("1").getOrCreateval sc = spark.sparkContextval value1 = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)val value2 = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)val value = value1.zip(value2)println(value.collect().mkString(","))}}

23.join()
作用: 两个不同数据源的数据,相同的key的value会连接在一起形成元组 跟SQL的内联一样,笛卡尔积的效果
源[("a",1),("b",2),("c",3)] [("a",2),("b",3)]连接后[("a",(1,2)),("b",(2,3))]
24.leftOuterJoin()
作用: 两个不同数据源的数据,相同的key的value会连接在一起形成元组 保留调用方的没有匹配上的key-value 跟SQl的左外连接一样
源[("a",1),("b",2),("c",3)] [("a",2),("b",3)]连接后[("a",(1,2)),("b",(2,3)),("c",3)]
25.cogroup()
作用: 两个不同数据源的数据,group — join (⚠️:只连接最开始分区的数据源,最后两个不同数据源形成元组)
[("a",1),("b",2)] [("a",4),("b",5),("c",6),("c",7)]


若有收获,就点个赞吧
0 人点赞
