我们这次 Spark-sql 操作中所有的数据均来自Hive,首先在Hive 中创建表,,并导入数据。
一共有3 张表: 1 张用户行为表,1 张城市表,1 张产品表
需求:各区域热门商品 Top3
这里的热门商品是从点击量的维度来看的,计算各个区域前三大热门商品,并备注上每
个商品在主要城市中的分布比例,超过两个城市用其他显示。
例如: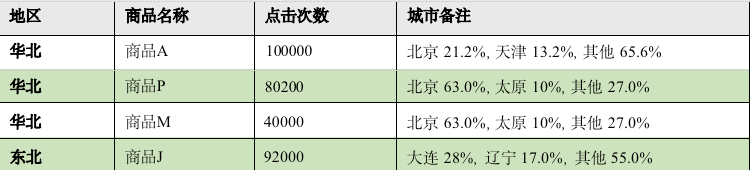
需求分析
➢查询出来所有的点击记录,并与city_info 表连接得到每个城市所在的地区 与Product_info 表连接得到产品名称
➢按照 地区和商品id 分组,统计出每个商品在每个地区的总点击次数
➢ 每个地区内按照点击次数降序排列
➢只取前三名
➢城市备注需要自定义 UDAF 函数
功能实现
➢ 连接三张表的数据,获取完整的数据(只有点击)
➢ 将数据根据地区,商品名称分组
➢ 统计商品点击次数总和,取 Top3
➢ 实现自定义聚合函数显示备注
代码
创建表
package com.yang.bigdata.spark.sqlimport org.apache.spark.sql._/*** @author :ywb* @date :Created in 2022/1/23 6:10 下午* @description:toDo*/object Spark06_SparkSQK_createTable {def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder().master("local[*]").appName("sqlTest").enableHiveSupport().getOrCreate()//spark.sql("create database yang")spark.sql("use yang")//准备数据spark.sql("""|CREATE TABLE `user_visit_action`(|`date` string,|`user_id` bigint,|`session_id` string,|`page_id` bigint,|`action_time` string,|`search_keyword` string,|`click_category_id` bigint,|`click_product_id` bigint,|`order_category_ids` string,|`order_product_ids` string,|`pay_category_ids` string,|`pay_product_ids` string,|`city_id` bigint)|row format delimited fields terminated by '\t'""".stripMargin)spark.sql("""|load data local inpath 'datas/user_visit_action.txt' into table yang.user_visit_action|""".stripMargin)spark.sql("""|CREATE TABLE `product_info`(|`product_id` bigint,|`product_name` string,|`extend_info` string)|row format delimited fields terminated by '\t'|""".stripMargin)spark.sql("""|load data local inpath 'datas/product_info.txt' into table yang.product_info|""".stripMargin)spark.sql("""|CREATE TABLE `city_info`(|`city_id` bigint,|`city_name` string,|`area` string)|row format delimited fields terminated by '\t'|""".stripMargin)spark.sql("""|load data local inpath 'datas/city_info.txt' into table yang.city_info|""".stripMargin)spark.sql("""select * from city_info""").show()spark.close()}}
object Spark06_SparkSQK_TODO1 {def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder().master("local[*]").appName("sqlTest").enableHiveSupport().getOrCreate()spark.sql("use yang")spark.sql("""|select| *|from (| select| *,| rank() over(partition by area order by clickCount desc) as rank| from (| select| area,| product_name,| count(*) as clickCount| from (| select| u.*,| p.product_name,| c.area,| c.city_name| from user_visit_action u| join product_info p on u.click_product_id = p.product_id| join city_info c on u.city_id = c.city_id| where u.click_product_id > -1| ) t1 group by area,product_name| ) t2|) t3 where rank <= 3|""".stripMargin).show()spark.close()}}
package com.yang.bigdata.spark.sqlimport org.apache.commons.lang.mutable.Mutableimport org.apache.spark.sql._import org.apache.spark.sql.expressions.Aggregatorimport scala.collection.mutableimport scala.collection.mutable.ListBuffer/*** @author :ywb* @date :Created in 2022/1/23 6:10 下午* @description:toDo*/object Spark06_SparkSQK_TODO2 {def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder().master("local[*]").appName("sqlTest2").enableHiveSupport().getOrCreate()spark.sql("use yang")spark.sql("""|select| a.*,| p.product_name,| c.area,| c.city_name|from user_visit_action a|join product_info p on a.click_product_id = p.product_id|join city_info c on a.city_id = c.city_id|where a.click_product_id > -1|""".stripMargin).createOrReplaceTempView("t1")spark.udf.register("dsc", functions.udaf(new DescAgg))spark.sql("""|select| area,| product_name,| count(*) as click_count,| dsc(city_name)|from t1|group by area,product_name|""".stripMargin).createOrReplaceTempView("t2")spark.sql("""|select| *,| rank() over(partition by area order by click_count desc) as rank|from t2|""".stripMargin).createOrReplaceTempView("t3")spark.sql("""|select| *|from t3|where rank <= 3|""".stripMargin).show()spark.close()}// countSum ==》 [(cityName,count),(cityName,count) ...... ]case class Buff( var sum : Long , var map : mutable.Map[String,Long] )class DescAgg extends Aggregator[String,Buff,String]{//初始化override def zero: Buff = {Buff( 0L , mutable.Map[String,Long]())}//聚合override def reduce(buff: Buff, cityName: String): Buff = {buff.sum += 1Lval count: Long = buff.map.getOrElse(cityName, 0L) + 1buff.map.update(cityName,count)buff}//合并override def merge(b1: Buff, b2: Buff): Buff = {val buffMap1: mutable.Map[String, Long] = b1.mapval buffMap2: mutable.Map[String, Long] = b2.mapbuffMap2.foreach({case (k,v) => {val count: Long = buffMap1.getOrElse(k, 0L) + vbuffMap1.update(k,count)}})b1.sum += b2.sumb1.map = buffMap1b1}// 最终值override def finish(temp: Buff): String = {val resList: ListBuffer[String] = ListBuffer[String]()val sum: Long = temp.sumval map: mutable.Map[String, Long] = temp.mapval list: List[(String, Long)] = map.toListval hasMore: Boolean = list.size > 2val res: List[(String, Long)] = list.sortBy(_._2).take(2)var percentage: Long = 0Lres.foreach({case (k,v) => {var p: Long = v * 100 / sumpercentage += presList.append(s"$k $p%")}})if (hasMore){resList.append(s"其他 ${100-percentage}%")}resList.mkString(",")}override def bufferEncoder: Encoder[Buff] = Encoders.productoverride def outputEncoder: Encoder[String] = Encoders.STRING}}

若有收获,就点个赞吧
0 人点赞
