1.SparkSQL 是什么
Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。
2.Hive and SparkSQL
Hive 是早期唯一运行在 Hadoop 上的 SQL-on-Hadoop 工具。但是 MapReduce 计算过程中大量的中间磁盘落地过程消耗了大量的 I/O,降低的运行效率,为了提高SQL-on-Hadoop 的效率,大量的 SQL-on-Hadoop 工具开始产生
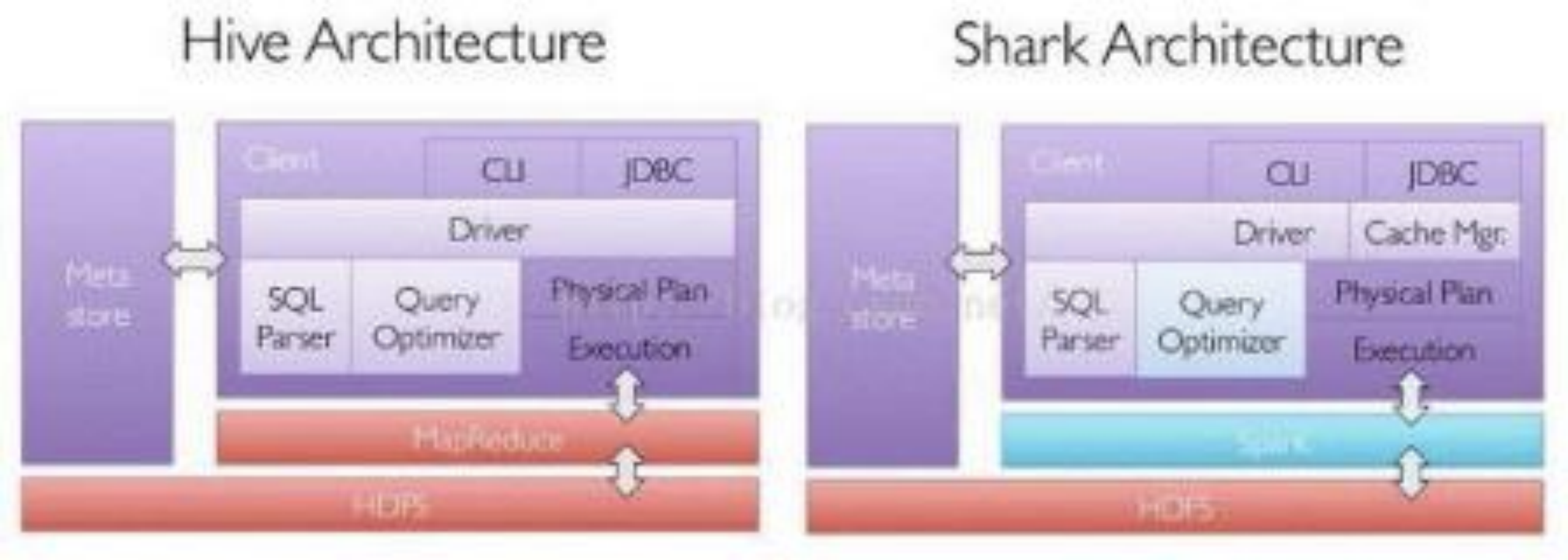
其中 Shark 是伯克利实验室Spark 生态环境的组件之一, 是基于Hive 所开发的工具,它修改了下图所示的右下角的内存管理、物理计划、执行三个模块,并使之能运行在Spark 引擎
上。
2014 年 6 月 1 日 Shark 项目和 SparkSQL 项目的主持人 Reynold Xin 宣布: 停止对 Shark 的 开发, 团队将所有资源放SparkSQL 项目上,至此, Shark 的发展画上了句话, 但也因此发
展出两个支线: SparkSQL 和 Hive on Spark。
其中SparkSQL 作为Spark 生态的一员继续发展,而不再受限于Hive,只是兼容Hive;而Hive on Spark 是一个Hive 的发展计划, 该计划将Spark 作为Hive 的底层引擎之一, 也就是说, Hive 将不再受限于一个引擎,可以采用Map-Reduce 、Tez、Spark 等引擎。
对于开发人员来讲, SparkSQL 可以简化 RDD 的开发,提高开发效率, 且执行效率非常快, 所以实际工作中, 基本上采用的就是 SparkSQL 。Spark SQL 为了简化RDD 的开发, 提高开发效率, 提供了2 个编程抽象,类似Spark Core 中的RDD
- DataFrame
- DataSet

若有收获,就点个赞吧
0 人点赞
