区别
Spark是基于内存,MR是基于硬盘。
Spark多个作业之间数据通信是基于内存,而Hadoop是基于磁盘
分布式计算模拟
网络IO模拟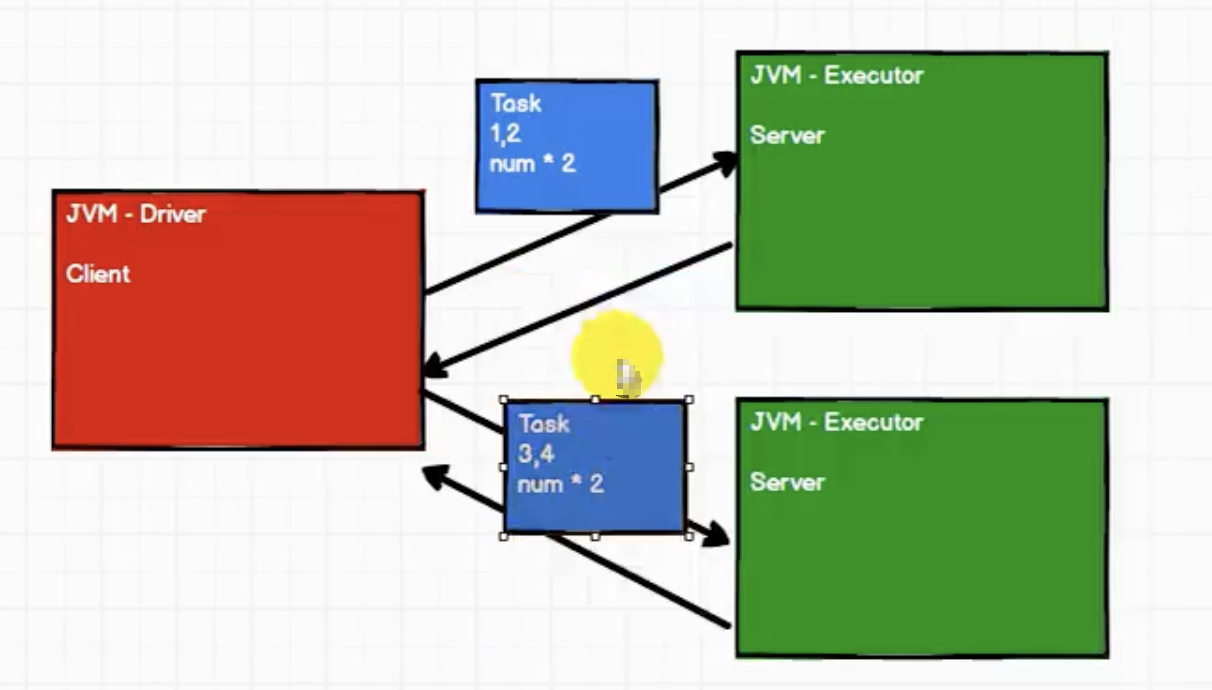
Task
class Task extends Serializable {val datas = List(1,2,3,4) //数据源//val logic = ( num:Int )=>{ num * 2 }val logic : (Int)=>Int = _ * 2 // 算子}
class SubTask extends Serializable {var datas : List[Int] = _var logic : (Int)=>Int = _// 计算def compute() = {datas.map(logic)}}
Driver
object Driver {def main(args: Array[String]): Unit = {// 连接服务器val client1 = new Socket("localhost", 9999)val client2 = new Socket("localhost", 8888)val task = new Task()val out1: OutputStream = client1.getOutputStreamval objOut1 = new ObjectOutputStream(out1)val subTask = new SubTask()subTask.logic = task.logic //算子subTask.datas = task.datas.take(2) //分区objOut1.writeObject(subTask)objOut1.flush()objOut1.close()client1.close()val out2: OutputStream = client2.getOutputStreamval objOut2 = new ObjectOutputStream(out2)val subTask1 = new SubTask()subTask1.logic = task.logicsubTask1.datas = task.datas.takeRight(2)objOut2.writeObject(subTask1)objOut2.flush()objOut2.close()client2.close()println("客户端数据发送完毕")}}
Executor
object Executor {def main(args: Array[String]): Unit = {// 启动服务器,接收数据val server = new ServerSocket(9999)println("服务器启动,等待接收数据")// 等待客户端的连接val client: Socket = server.accept()val in: InputStream = client.getInputStreamval objIn = new ObjectInputStream(in)val task: SubTask = objIn.readObject().asInstanceOf[SubTask]val ints: List[Int] = task.compute()println("计算节点[9999]计算的结果为:" + ints)objIn.close()client.close()server.close()}}
object Executor2 {def main(args: Array[String]): Unit = {// 启动服务器,接收数据val server = new ServerSocket(8888)println("服务器启动,等待接收数据")// 等待客户端的连接val client: Socket = server.accept()val in: InputStream = client.getInputStreamval objIn = new ObjectInputStream(in)val task: SubTask = objIn.readObject().asInstanceOf[SubTask]val ints: List[Int] = task.compute()println("计算节点[8888]计算的结果为:" + ints)objIn.close()client.close()server.close()}}

若有收获,就点个赞吧
0 人点赞
