一 读取数据源
基于内存
object Spark01_RDD_Memory {def main(args: Array[String]): Unit = {val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")val sc: SparkContext = new SparkContext(sparkConf)/*** 基于内存 当作数据源*/val seq: Seq[Int] = Seq(1, 2, 3)val rdd: RDD[Int] = sc.makeRDD(seq)rdd.collect().foreach(print)sc.stop()}}
基于文件
textFile: 以行 为单位来读取数据,读取的数据都是字符串
object Spark02_RDD_File {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD1")val sc: SparkContext = new SparkContext(sparkConf)// 1 绝对路径/相对路径// 2 指定文件// 3 指定目录(选中所有目录下所有文件)val rdd: RDD[String] = sc.textFile("datas")rdd.collect().foreach(println)// 4 通配符 * 模糊匹配 如 "datas/1.*.txt"// 5 可以是分布式存储系统路径:HDFSsc.stop()}}
wholeTextFiles:以文件为单位读取数据
object Spark02_RDD_File1 {def main(args: Array[String]): Unit = {val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD3")val sc: SparkContext = new SparkContext(sparkConf)// 读取的结果表示为元组,第一个元素表示文件路径,第二个元素表示文件内容val rdd: RDD[(String, String)] = sc.wholeTextFiles("datas")rdd.collect().foreach(println)sc.stop()}}
并行度和分区
- Driver能够将一个作业切分成多个任务后,发送给Executor节点并行计算
- 能并行计算的任务数叫并行度,这个数量能在构建RDD时指定
- RDD的计算一个分区内的数据是一个一个执行逻辑,只有一个执行完才会执行下一个
1.基于内存
1.1 分区设定
makeRDD方法可以传递第二个参数,这个参数表示分区的数量
//TODO 准备环境val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD4")val sc: SparkContext = new SparkContext(sparkConf)//TODO 创建RDD// 第二个参数不传递会采用默认值 :defaultParallelism// scheduler.conf.getInt("spark.default.parallelism", totalCores)// 如果获取不到,那么就使用totalCores属性:为当前环境的最大可用核数// 设置分区 1. spark.default.parallelism 2. makeRDD(list,n)val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3),2)//将处理的数据保存成分区文件rdd.saveAsTextFile("output")//TODO 关闭sc.stop()
源码


1.2 分区数据的分配
集合长度 分区数量
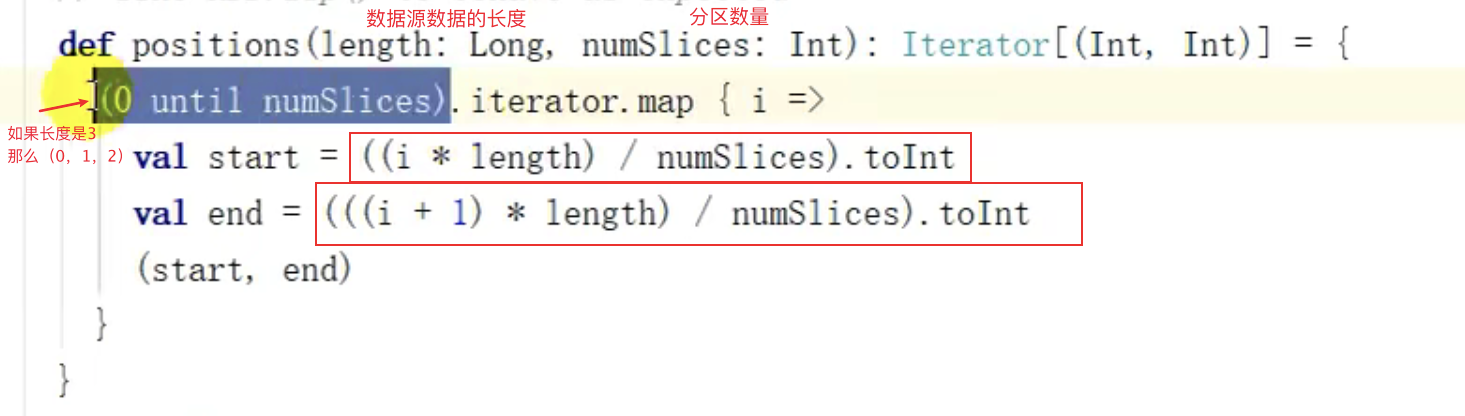
如果数据源是 List(1,2,3,4,5) 分区数量 3那么计算得出 (0,1)(1,3)(3,5)前闭后开分区1: 1分区2: 2 3分区3: 4 5
2. 基于文件
2.1 分区设定
- textFile第二个参数指定分区数
- minPartitions:真正的分区数量可能比 设定/默认 的数量大
//TODO 准备环境val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD4")val sc: SparkContext = new SparkContext(sparkConf)//TODO 创建RDD// 1.textFile可以将文件作为数据处理的数据源,第二个参数指定分区数// minPartitions:最小分区数// math.min(defaultParallelism,2) // 8,2// 2.如果不实用默认,也可以直接指定// 分区数的计算方式:// 文件总字节大小 = size// 平均每个分区存放 = size / minPartitions// (size % 平均大小 )> 0.1 ==> 分区 + 1val rdd: RDD[String] = sc.textFile("datas/3.txt")rdd.saveAsTextFile("output")//TODO 关闭sc.stop()
总字节 / 分区数量 = 分区平均字节量总字节 /分区平均字节量 = 分区数量
2.2 分区数据的 分配
- 读取文件和hadoop一样,是一行一行的读取
- 读取之后进行分区时用到了字节
- 如果数据源是多个文件,那么计算分区时是以文件为单位进行分区
例子:
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("app")val sc = new SparkContext(sparkConf)val rdd = sc.textFile("datas/1.txt",2)

最终:会有两个文件(两个分区)

若有收获,就点个赞吧
0 人点赞
